通过本节学习,你将掌握:
- 机器学习/深度学习任务的整体流程。
- 各个阶段在任务中的作用与实现方式。
- 深度学习与传统机器学习在实现上的关键差异。
- PyTorch 如何支持深度学习任务的模块化实现。
二、机器学习任务的标准流程
| 步骤 | 内容说明 |
|---|---|
| 1. 数据预处理 | - 统一数据格式 - 清除异常值 - 进行必要的数据变换(如归一化、标准化) - 划分数据集:训练集、验证集、测试集 - 常见方法:按比例随机划分、KFold 交叉验证 - 工具支持:sklearn.model_selection.train_test_split, KFold |
| 2. 模型选择与配置 | - 选择合适的模型(如线性回归、随机森林、SVM等) - 设定损失函数(Loss Function) - 选择优化器(Optimizer) - 设置超参数(如学习率、正则化系数等) - 可使用 sklearn 等库的默认实现 |
| 3. 模型训练与评估 | - 使用训练集拟合模型 - 在验证集/测试集上评估模型性能 - 根据指标调整模型或超参数 |
三、深度学习任务流程(与机器学习的异同)
相同点:
- 整体流程一致:数据处理 → 模型构建 → 训练 → 评估。
不同点:
| 模块 | 深度学习的特点与实现差异 |
|---|---|
| 1. 数据加载 | - 数据量大,无法一次性加载到内存 - 采用 批处理(Batch Training) 策略 - 每次加载固定数量样本(一个 batch)送入模型 - 需要专门的数据加载设计(如 DataLoader) |
| 2. 模型构建 | - 神经网络层数多,结构复杂 - 包含专用层:卷积层、池化层、批正则化层、LSTM 等 - 采用 "逐层搭建" 或 模块化组装 方式 - 强调灵活性与可定制性 - 对代码实现要求更高 |
| 3. 损失函数与优化器 | - 原理与机器学习类似 - 关键要求:支持在 自定义网络结构 上自动反向传播 - 需确保梯度能正确回传至所有可训练参数 |
| 4. 训练设备(GPU)配置 | - 默认运行在 CPU,需显式将模型和数据"放到"GPU - 操作包括: - .to(device) 将模型、数据、损失函数、优化器移至 GPU - 多 GPU 训练时需考虑模型并行或数据并行 - 评估指标计算时常需将张量从 GPU "移回"CPU |
| 5. 训练与验证过程 | - 按批次(batch-by-batch)进行 - 流程: 1. 读取一个 batch 的数据 2. 送入 GPU 进行前向传播 3. 计算损失 4. 反向传播更新参数(使用优化器) - 涉及多个模块协同工作(数据、模型、损失、优化器、设备) - 训练后需根据预设指标(如准确率、F1)评估模型表现 |
目录
1.基本配置
对于一个PyTorch项目,我们需要导入一些Python常用的包来帮助我们快速实现功能。常见的包有os、numpy等,此外还需要调用PyTorch自身一些模块便于灵活使用,比如torch、torch.nn、torch.utils.data.Dataset、torch.utils.data.DataLoader、torch.optimizer等等。
经过本节的学习,你将收获:
-
在深度学习/机器学习中常用到的包
-
GPU的配置
首先导入必须的包。注意这里只是建议导入的包导入的方式,可以采用不同的方案,比如涉及到表格信息的读入很可能用到pandas,对于不同的项目可能还需要导入一些更上层的包如cv2等。如果涉及可视化还会用到matplotlib、seaborn等。涉及到下游分析和指标计算也常用到sklearn。
python
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer根据前面我们对深度学习任务的梳理,有如下几个超参数可以统一设置,方便后续调试时修改:
-
batch size
-
初始学习率(初始)
-
训练次数(max_epochs)
-
GPU配置
python
batch_size = 16
# 批次的大小
lr = 1e-4
# 优化器的学习率
max_epochs = 100我们的数据和模型如果没有经过显式指明设备,默认会存储在CPU上,为了加速模型的训练,我们需要显式调用GPU,一般情况下GPU的设置有两种常见的方式:
python
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号
# 方案二:使用"device",后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号2.数据读入
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,
Dataset定义好数据的格式和数据变换形式,
DataLoader用iterative的方式不断读入批次数据。
我们可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
-
__init__: 用于向类中传入外部参数,同时定义样本集 -
__getitem__: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据 -
__len__: 用于返回数据集的样本数
2.1.构建Dataset
下面以cifar10数据集为例给出构建Dataset类的方式:
python
import os
import torch
from torchvision import datasets, transforms
# 定义训练集和验证集路径
train_path = "./train"
val_path = "./val"
# 定义图像预处理方式
data_transform = transforms.Compose([
transforms.Resize(256), # 调整图像大小为256x256
transforms.CenterCrop(224), # 中心裁剪成224x224,这是很多预训练模型默认输入尺寸
transforms.ToTensor(), # 将PIL图像或numpy.ndarray转为tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 加载带有转换的数据集
train_data = datasets.ImageFolder(train_path, transform=data_transform)
val_data = datasets.ImageFolder(val_path, transform=data_transform)
# 现在train_data和val_data可以用来创建DataLoader对象,以便迭代访问这里使用了PyTorch自带的ImageFolder类的用于读取按一定结构存储的图片数据(path对应图片存放的目录,目录下包含若干子目录,每个子目录对应属于同一个类的图片)。
其中data_transform可以对图像进行一定的变换,如翻转、裁剪等操作,可自己定义。
2.2.定制Dataset
python
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset # 注意:你代码中漏了导入 Dataset 类
class MyDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
"""
自定义数据集类,用于加载图像和对应的标签。
Args:
annotations_file (str): 包含图像文件名和标签的 CSV 文件路径。
假设 CSV 第一列为图像文件名(如 'cat1.jpg'),第二列为标签。
img_dir (str): 存放所有图像文件的目录路径。
transform (callable, optional): 可选的图像变换函数(如标准化、数据增强等),
将在返回前应用于图像。
target_transform (callable, optional): 可选的标签变换函数,
将在返回前应用于标签。
"""
# 读取 CSV 文件,存储图像名和标签
self.img_labels = pd.read_csv(annotations_file)
# 图像文件所在的目录
self.img_dir = img_dir
# 图像的预处理变换(如 ToTensor、Resize 等)
self.transform = transform
# 标签的预处理变换(如标签编码等)
self.target_transform = target_transform
def __len__(self):
"""
返回数据集的总样本数量。
Returns:
int: 数据集中图像-标签对的总数。
"""
return len(self.img_labels)
def __getitem__(self, idx):
"""
根据索引 idx 获取单个样本(图像和标签)。
Args:
idx (int): 样本的索引。
Returns:
tuple: (image, label),其中 image 是张量形式的图像,label 是对应的标签。
"""
# 拼接图像的完整路径:img_dir + 图像文件名(来自 CSV 第一列)
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
# 使用 torchvision 读取图像,返回的是 torch.Tensor 类型
image = read_image(img_path)
# 获取对应的标签(来自 CSV 第二列)
label = self.img_labels.iloc[idx, 1]
# 如果定义了图像变换,则应用到图像上
if self.transform:
image = self.transform(image)
# 如果定义了标签变换,则应用到标签上
if self.target_transform:
label = self.target_transform(label)
# 返回处理后的图像和标签
return image, label其中,我们的标签类似于以下的形式:
image1.jpg, 0
image2.jpg, 1
......
image9.jpg, 92.3.批次读入数据
构建好Dataset后,就可以使用DataLoader来按批次读入数据了,实现代码如下:
python
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)其中:
-
batch_size:样本是按"批"读入的,batch_size就是每次读入的样本数
-
num_workers:有多少个进程用于读取数据,Windows下该参数设置为0,Linux下常见的为4或者8,根据自己的电脑配置来设置
-
shuffle:是否将读入的数据打乱,一般在训练集中设置为True,验证集中设置为False
-
drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
这里可以看一下我们的加载的数据。PyTorch中的DataLoader的读取可以使用next和iter来完成
python
import matplotlib.pyplot as plt
images, labels = next(iter(val_loader))
print(images.shape)
plt.imshow(images[0].transpose(1,2,0))
plt.show()3.模型构建
人工智能的第三次浪潮受益于卷积神经网络的出现和BP反向传播算法的实现,随着深度学习的发展,研究人员研究出了许许多多的模型,PyTorch中神经网络构造一般是基于**nn.Module**类的模型来完成的,它让模型构造更加灵活。
3.1.神经网络的构造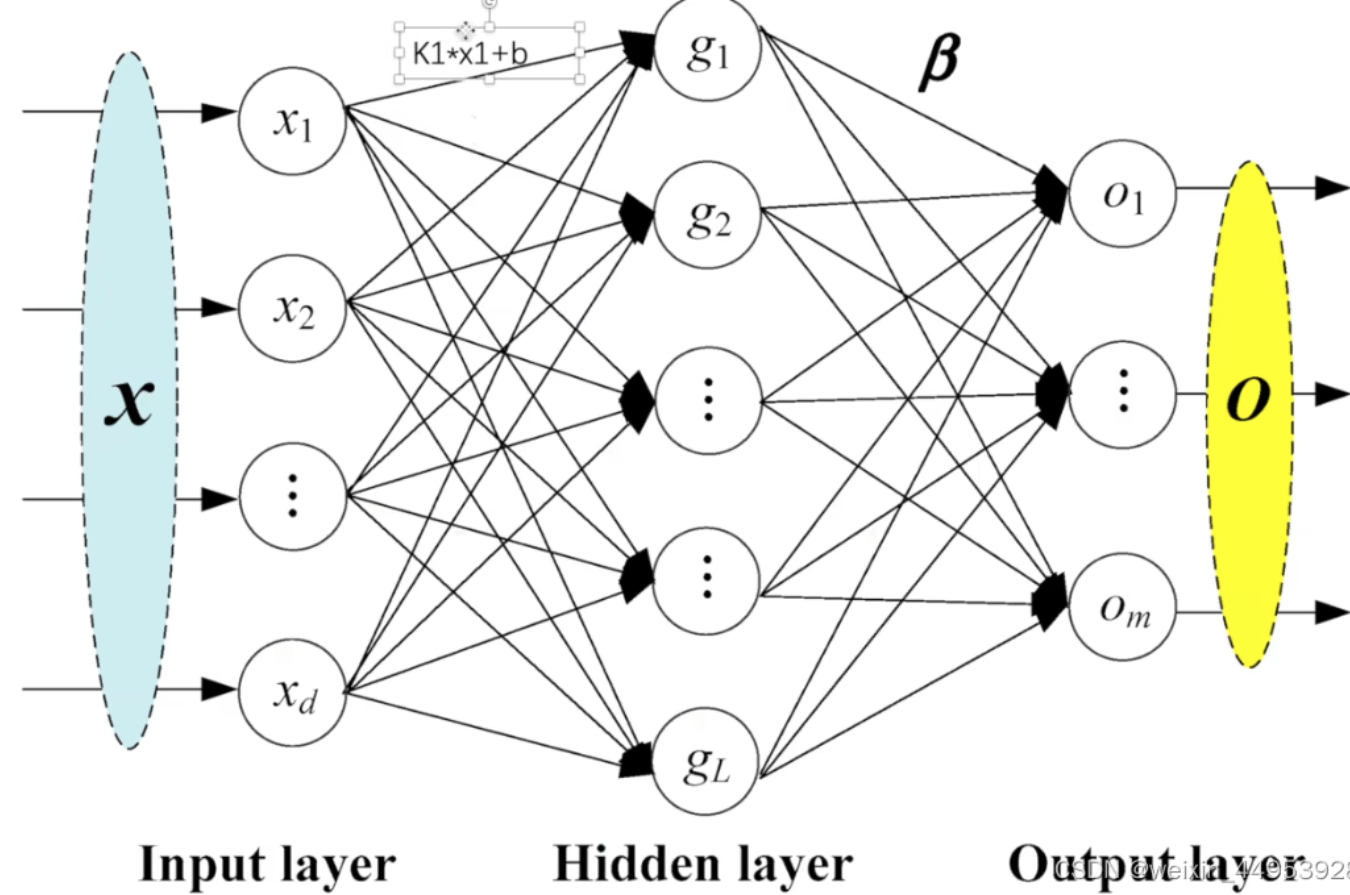
Module 类是 torch.nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型。
下面继承 Module 类构造多层感知机。这里定义的 MLP 类重载了 Module 类的 __init__ 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算(正向传播)。
下面的 MLP 类定义了一个具有两个隐藏层的多层感知机。
python
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
x= self.hidden(x)
x= self.act(x)
x= self.output(x)
return x
X = torch.rand(2,784) # 设置一个随机的输入张量
net = MLP() # 实例化模型
print(net) # 打印模型
net(X) # 前向计算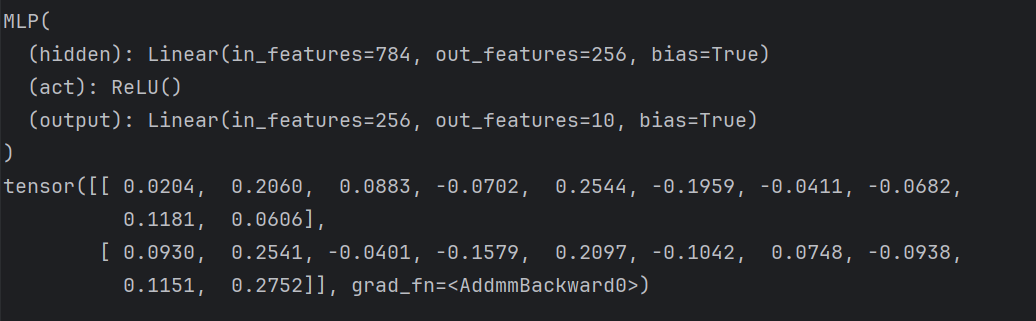
-
__init__方法 :模型构建,传超参- 必须首先调用
super(MyModel, self).__init__()。这会初始化Module基类,确保内部的参数注册机制正常工作。(这里传入的类一定要是类名) - 在
__init__中定义的任何nn.Module实例(如nn.Linear,nn.Conv2d)或nn.Parameter都会被自动注册为该模型的子模块或参数。这意味着 PyTorch 可以追踪这些参数,并在调用model.parameters()时返回它们,以便优化器进行更新。
- 必须首先调用
-
forward方法 :前向传播,传参x- 这是必须重写的方法,它定义了数据通过网络时的计算流程(前向传播)。
- 当你调用
model(input)时,PyTorch 实际上会调用model.forward(input)。 - 你应该在这里使用在
__init__中定义的层来处理输入x并返回输出。
3.2.神经网络常见的层
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层、卷积层、池化层与循环层等等。虽然PyTorch提供了⼤量常用的层,但有时候我们依然希望⾃定义层。这里我们会介绍如何使用 Module 来自定义层,从而可以被反复调用。
3.2.1.不含模型的层
下⾯构造的 MyLayer 类通过继承 Module 类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了 forward 函数里。这个层里不含模型参数。
python
import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
layer = MyLayer()
out = layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))
print(out)
3.2.1.包含模型的层
torch.mm(mat1, mat2)计算两个二维张量(矩阵)之间的矩阵乘法。⚠️ 仅支持 二维张量(即矩阵),不支持批量操作或多维张量。
Parameter 类其实是 Tensor 的子类,如果一个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表里 。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter ,除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典。
python
import torch
from torch import nn
class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i])
return x
net = MyListDense()
print(net)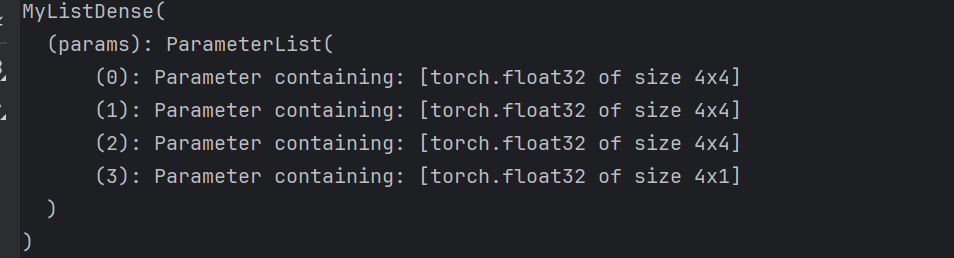
3.3.卷积层
1d卷积示意图
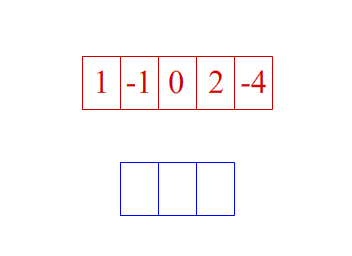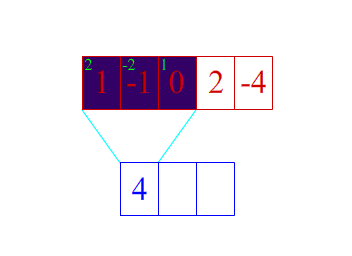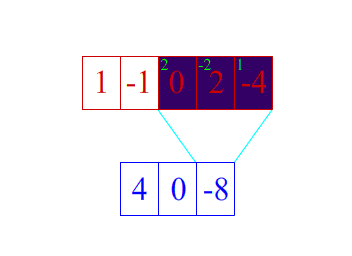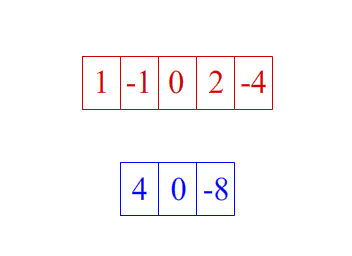
2d卷积示意图
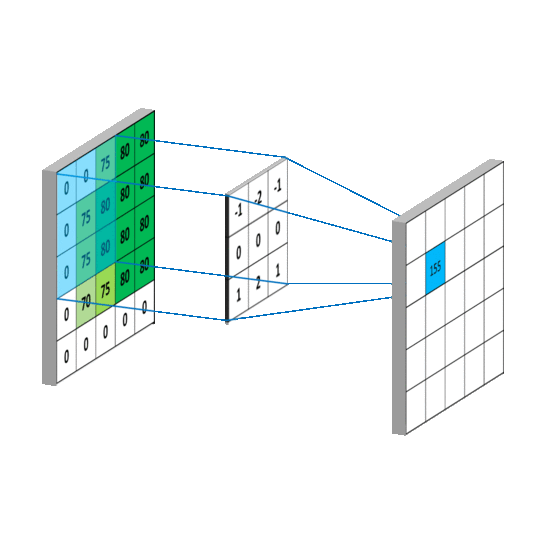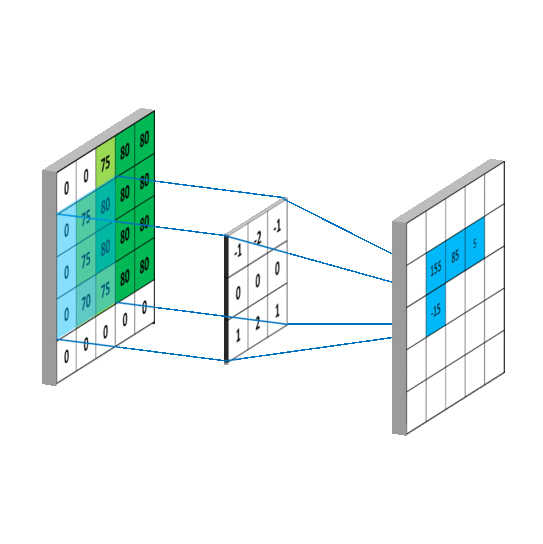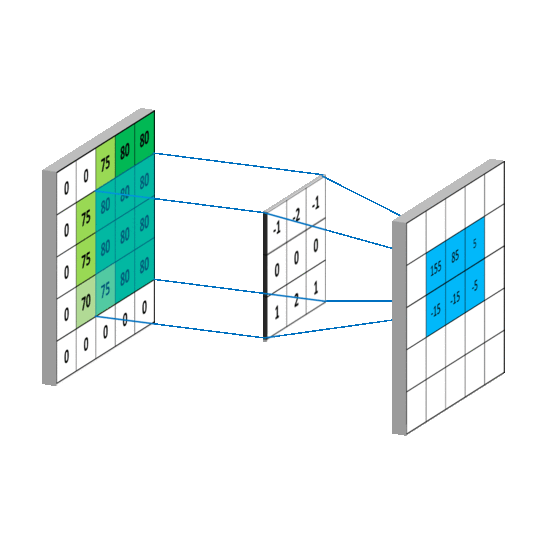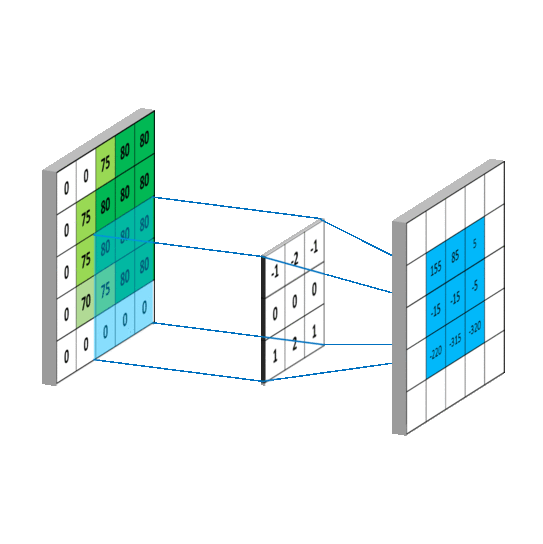
3d卷积示意图
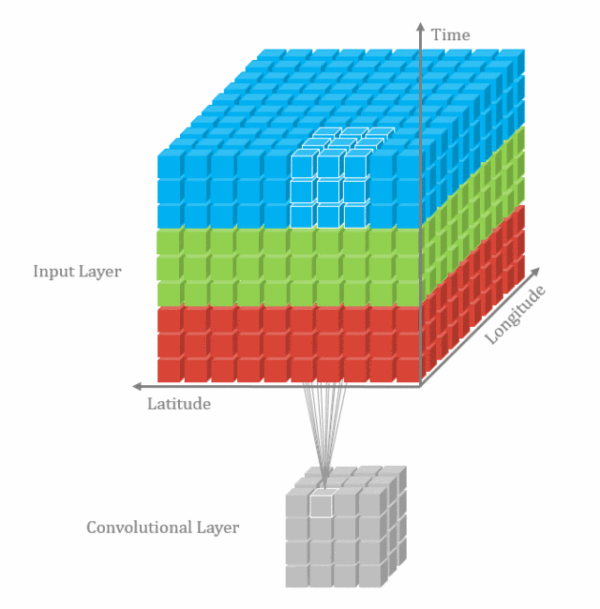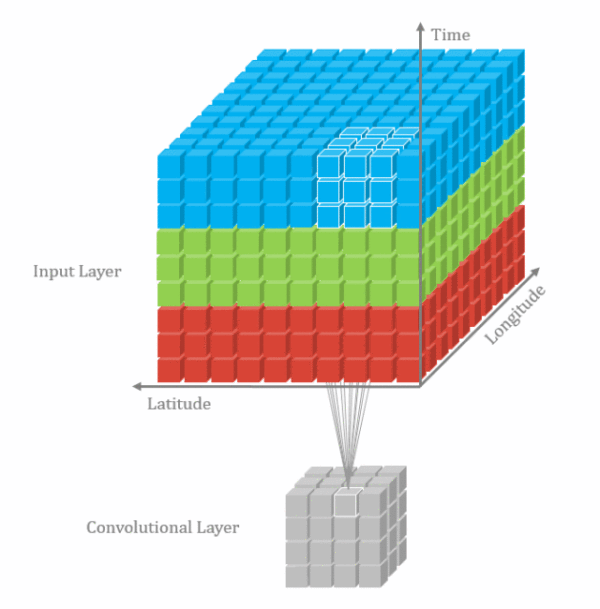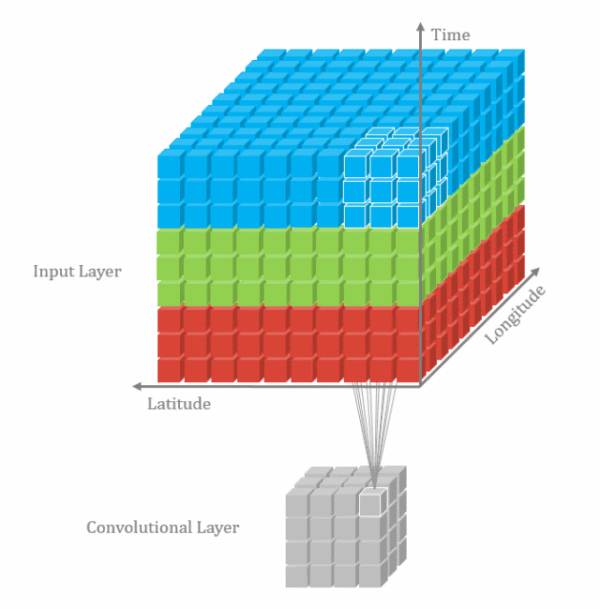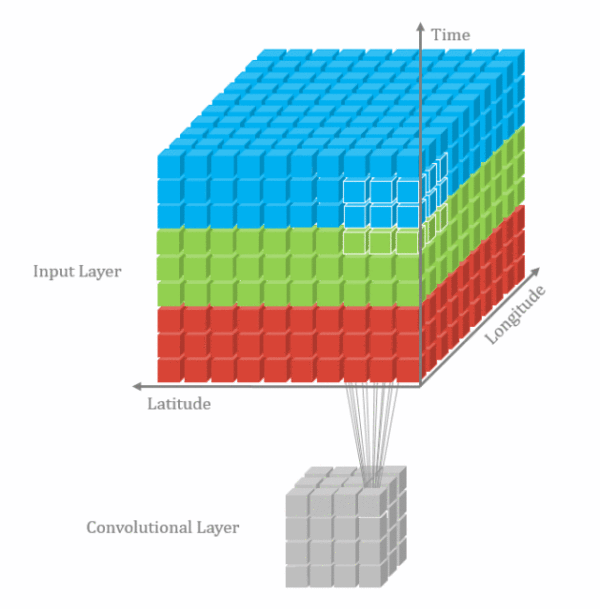
3.3.1.二维卷积--nn.Conv2d
功能: 对多个二维信号进行二维卷积
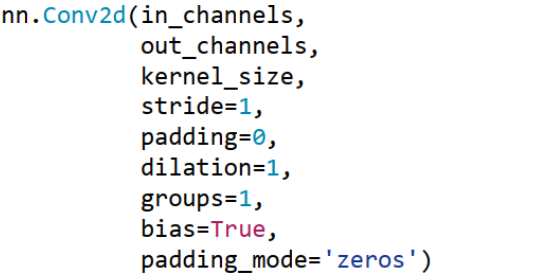
| 参数名 | 是否必需 | 含义说明 | 常见取值示例 |
|---|---|---|---|
in_channels |
✅ 是 | 输入特征图的通道数(如灰度图=1,RGB图=3) | 1, 3, 64 |
out_channels |
✅ 是 | 输出特征图的通道数(即卷积核个数) | 16, 32, 64 |
kernel_size |
✅ 是 | 卷积核的大小(高度, 宽度) | 3, (3,3), (5,1) |
stride |
❌ 否 | 卷积核滑动步长,控制输出尺寸 | 1, 2, (2,2) |
padding |
❌ 否 | 输入边缘填充大小,保持尺寸或防信息丢失 | 0, 1, 'same' |
dilation |
❌ 否 | 膨胀率(空洞卷积),控制感受野 | 1(普通), 2, 4 |
groups |
❌ 否 | 分组卷积的组数: • 1: 普通卷积 • in_channels: 深度可分离卷积 |
1, 2, 32 |
bias |
❌ 否 | 是否使用偏置项(每个输出通道一个偏置) | True, False |
padding_mode |
❌ 否 | 填充方式: • 'zeros': 零填充 • 'reflect': 镜像填充 • 'replicate': 复制边界 • 'circular': 循环填充 |
'zeros', 'reflect', 'replicate' |
https://blog.csdn.net/qq_58602552/article/details/148617896
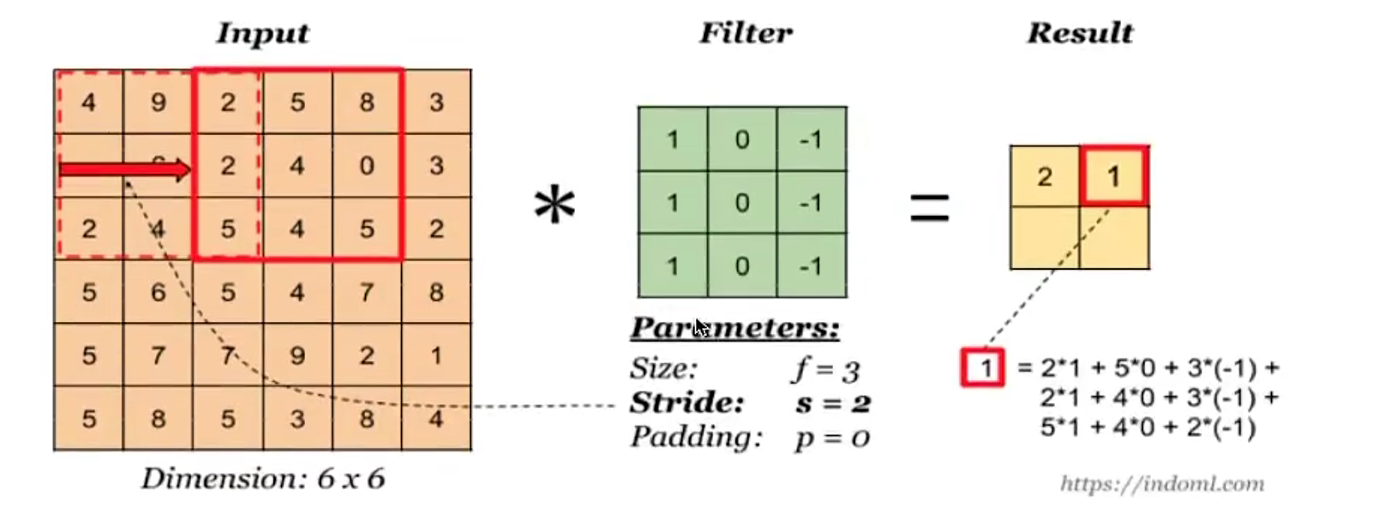
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差。
python
import torch
from torch import nn
# 卷积运算(二维互相关)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
# 二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias"卷积窗口形状为 p×q 的,卷积层称为 p×q 卷积层。"
填充(padding)是指在输⼊高和宽的两侧填充元素(通常是0元素)。
下面的例子里我们创建一个⾼和宽为3的二维卷积层,然后设输⼊高和宽两侧的填充数分别为1。给定一个高和宽为8的输入,我们发现输出的高和宽也是8。
python
import torch
from torch import nn
# 定义一个函数来计算卷积层。它对输入和输出做相应的升维和降维
def comp_conv2d(conv2d, X):
# (1, 1)代表批量大小和通道数
X = X.view((1, 1) + X.shape)
Y = conv2d(X)
return Y.view(Y.shape[2:]) # 排除不关心的前两维:批量和通道
# 注意这里是两侧分别填充1⾏或列,所以在两侧一共填充2⾏或列
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3,padding=1)
X = torch.rand(8, 8)
output_shape = comp_conv2d(conv2d, X).shape
print(output_shape)3.3.2.转置卷积--nn.ConvTranspose
3.4.池化层
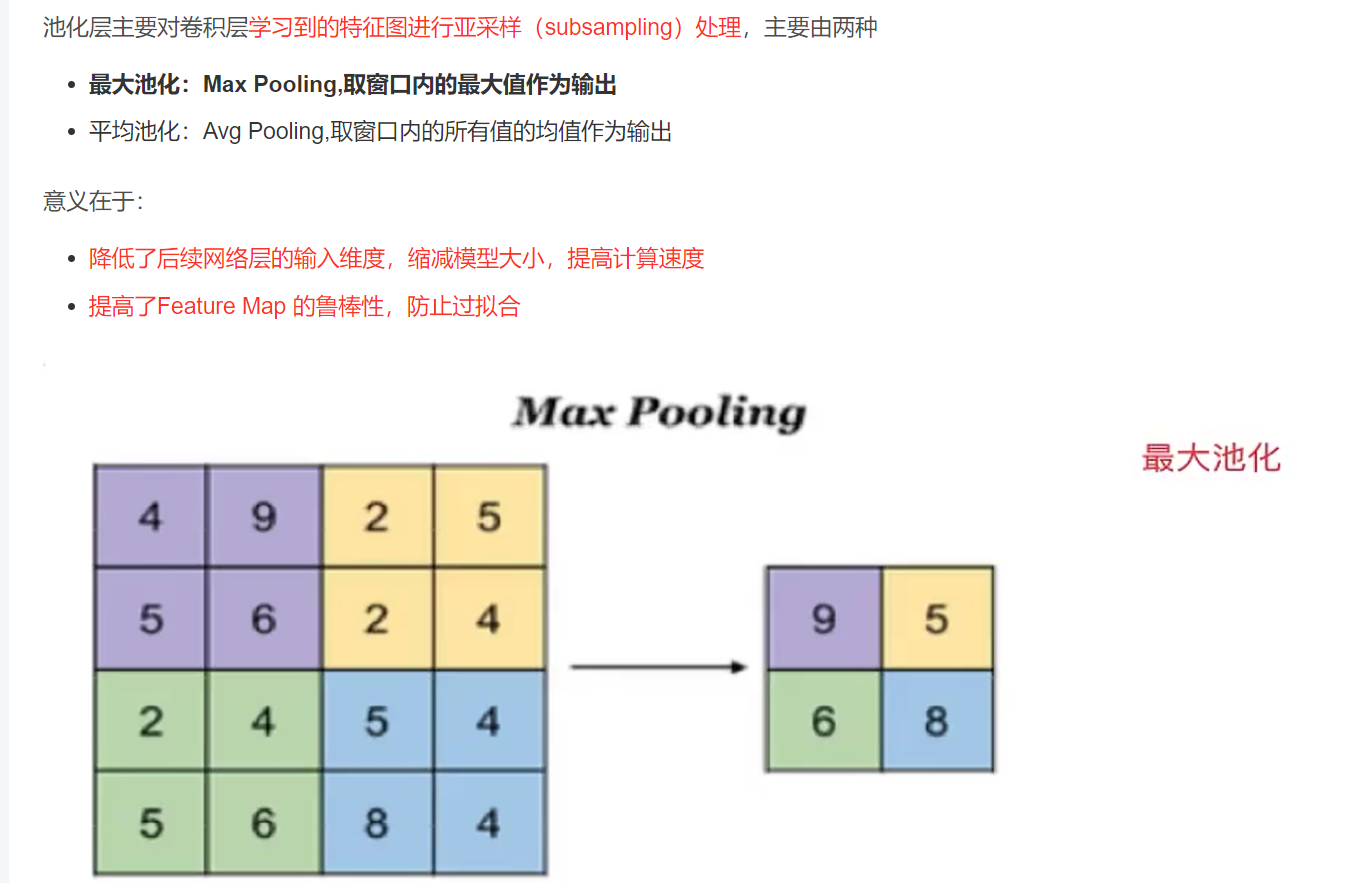
python
import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]], dtype=torch.float)
out = pool2d(X, (2, 2))
print(out)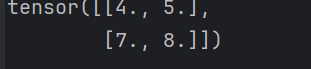
3.5.线性层
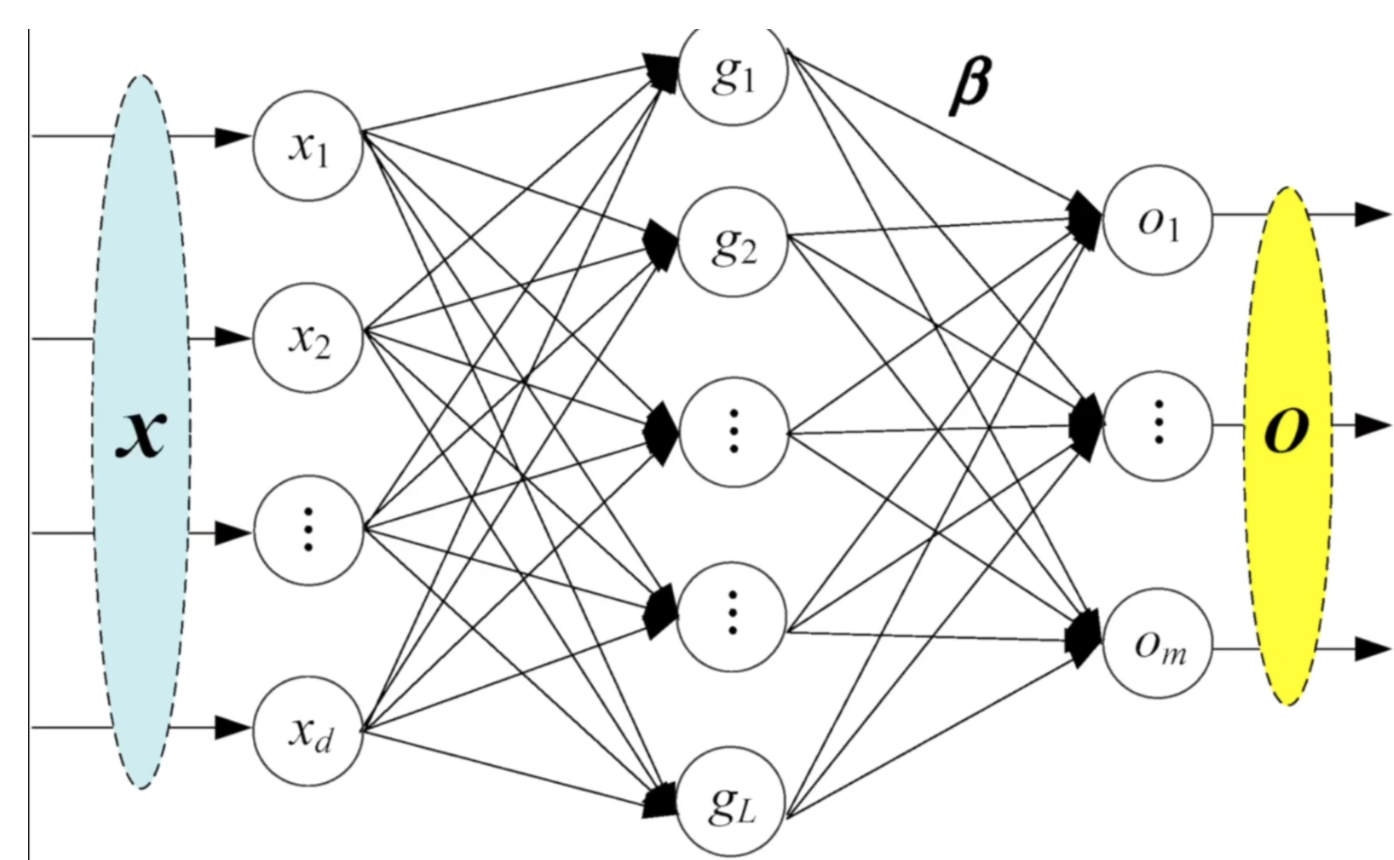
在 nn.Linear(10, 1) 中,输入维度(input dimension) 指的是该全连接层(线性层)期望接收的输入向量的特征数量,也就是输入张量最后一个维度的大小.
10:输入维度 (in_features=10)→ 表示这个层期望每个样本有 10 个输入特征。1:输出维度 (out_features=1)→ 表示这个层会输出 1 个值(比如预测分数、类别得分等)。
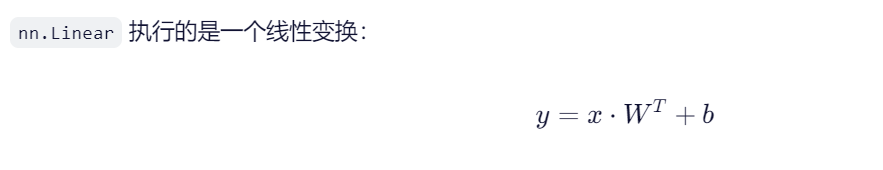
- x:输入,形状为
[*, 10](*表示任意数量的前导维度,如 batch_size) - W:权重矩阵,形状为
[1, 10](初始化:自动存储在linear.weight中) - b:偏置,形状为
[1](存储在linear.bias中) - y:输出,形状为
[*, 1]
*前一位都是表示数量
python
import torch
import torch.nn as nn
linear = nn.Linear(10, 1) # 输入10维,输出1维
# 假设有一个批次的输入:4 个样本,每个样本有 10 个特征
x = torch.randn(4, 10) # 形状: [batch_size=4, in_features=10]
output = linear(x) # 形状: [4, 1]
print(output.shape) # torch.Size([4, 1])
print(output)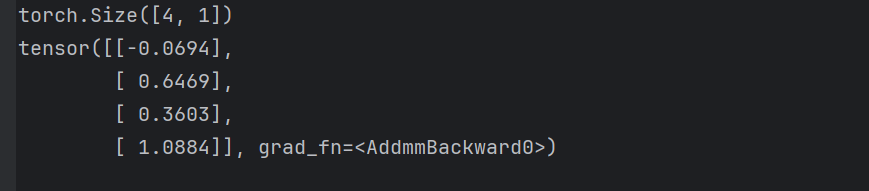
多层感知机(MLP) 是由多个全连接层(nn.Linear)堆叠而成的神经网络,至少包含一个隐藏层(hidden layer),能够学习输入和输出之间的非线性关系。
python
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, input_dim=784, hidden_dim=128, output_dim=10):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 输入层 → 隐藏层
self.fc2 = nn.Linear(hidden_dim, hidden_dim) # 隐藏层 → 隐藏层
self.fc3 = nn.Linear(hidden_dim, output_dim) # 隐藏层 → 输出层
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
x = self.relu(self.fc1(x)) # 线性 + 激活
x = self.relu(self.fc2(x))
x = self.fc3(x) # 输出层通常不加激活(或根据任务加 softmax/sigmoid)
return x
# 创建一个 MLP
mlp = MLP(input_dim=784, hidden_dim=128, output_dim=10)
# 输入:28x28 图像展平成 784 维向量
x = torch.randn(4, 784) # 4 个样本
output = mlp(x)
print(output.shape) # torch.Size([4, 10]) → 每个样本输出 10 个类别的得分3.6.激活层
4.模型实例
4.1.LeNet
LeNet是一种经典的卷积神经网络(Convolutional Neural Network, CNN),由被誉为"深度学习之父"的杨立昆(Yann LeCun)在1998年提出,其论文《Gradient-Based Learning Applied to Document Recognition》系统地介绍了这一模型。LeNet是最早成功应用于手写数字识别的深度神经网络之一,为现代深度学习的发展奠定了基础。
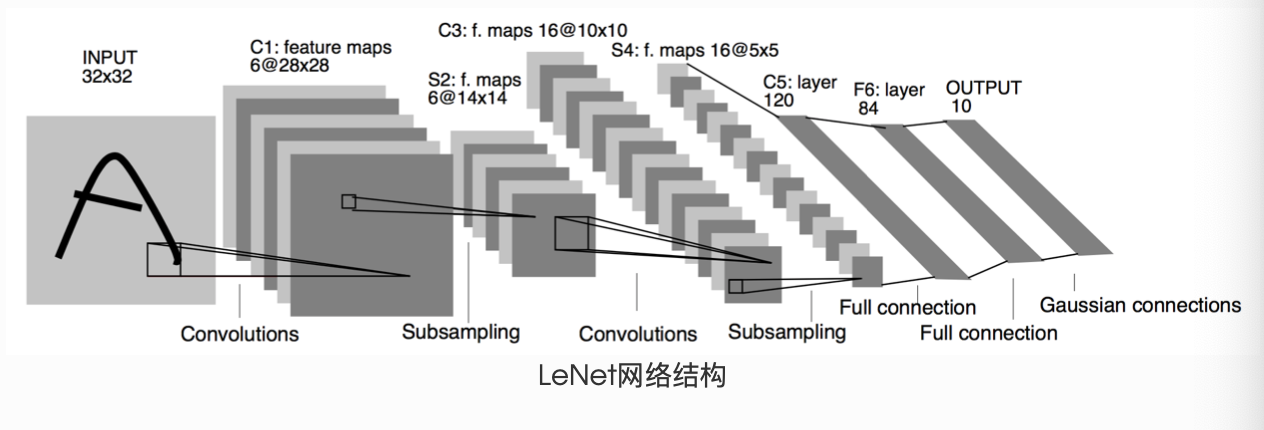
这是一个简单的前馈神经网络 (feed-forward network)(LeNet)。它接受一个输入,然后将它送入下一层,一层接一层的传递,最后给出输出。
一个神经网络的典型训练过程如下:
-
定义包含一些可学习参数(或者叫权重)的神经网络
-
在输入数据集上迭代
-
通过网络处理输入
-
计算 loss (输出和正确答案的距离)
-
将梯度反向传播给网络的参数
-
更新网络的权重,一般使用一个简单的规则:
weight = weight - learning_rate * gradient
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的其他所有维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1的权重
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)1表示Batch Size (批量大小):一次输入样本数量
1表示单通道:单通道的灰度图像。(3就是彩色RGB)
32+、2表示:高和宽
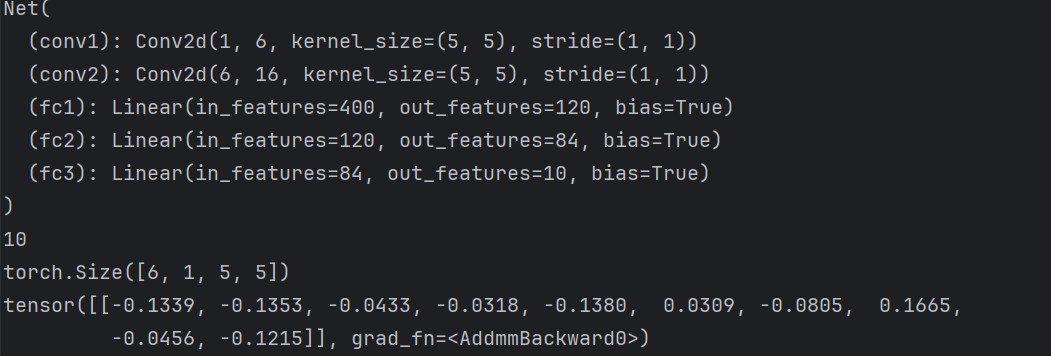
注意:torch.nn只支持小批量处理 (mini-batches)。整个 torch.nn 包只支持小批量样本的输入,不支持单个样本的输入。比如,nn.Conv2d 接受一个4维的张量,即nSamples x nChannels x Height x Width 如果是一个单独的样本,只需要使用input.unsqueeze(0) 来添加一个"假的"批大小维度。
-
torch.Tensor- 一个多维数组,支持诸如backward()等的自动求导操作,同时也保存了张量的梯度。 -
nn.Module- 神经网络模块。是一种方便封装参数的方式,具有将参数移动到GPU、导出、加载等功能。 -
nn.Parameter- 张量的一种,当它作为一个属性分配给一个Module时,它会被自动注册为一个参数。 -
autograd.Function- 实现了自动求导前向和反向传播的定义,每个Tensor至少创建一个Function节点,该节点连接到创建Tensor的函数并对其历史进行编码。
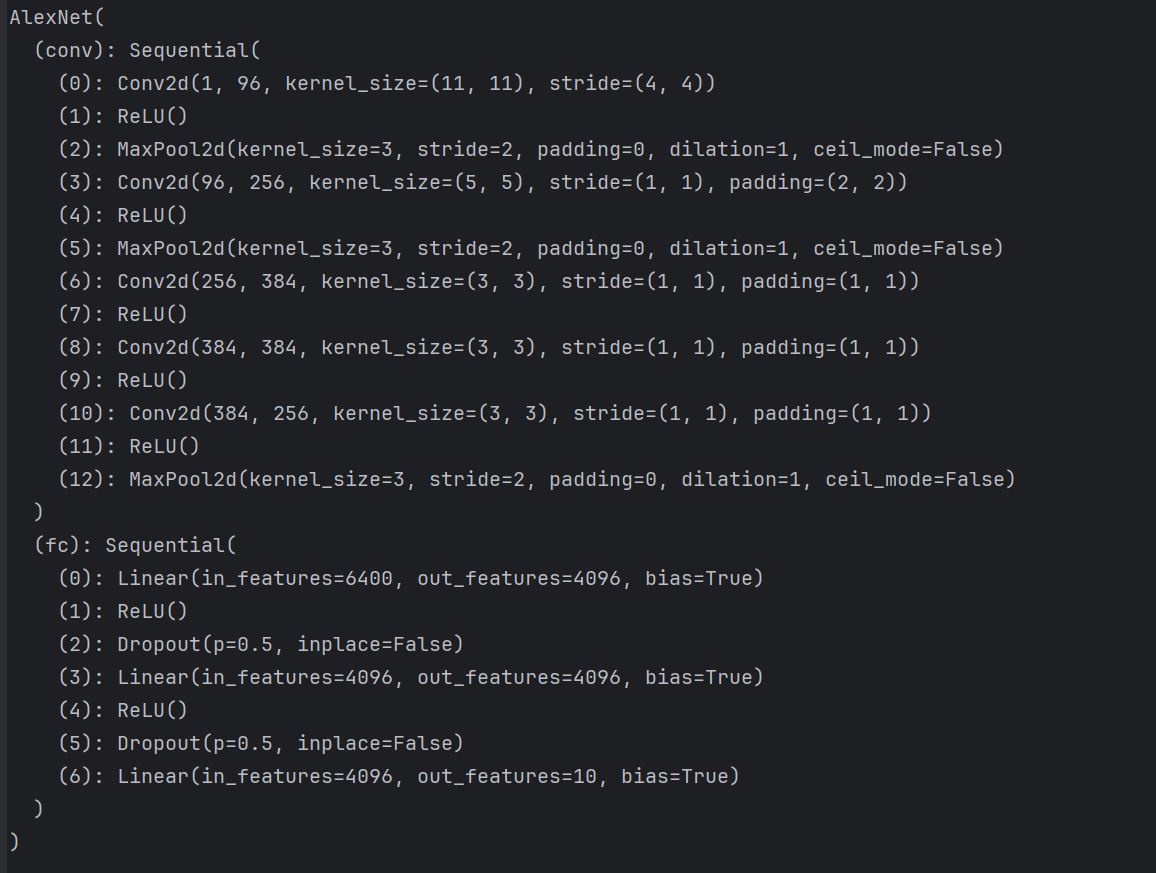
4.2.AlexNet
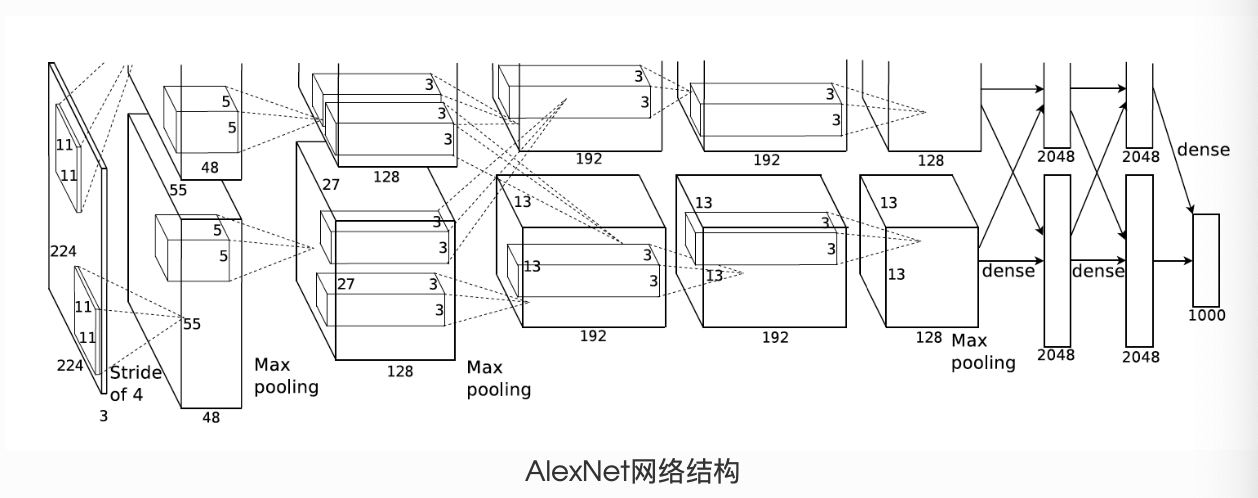

python
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),#激活函数
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
net = AlexNet()
print(net)