中国农业银行(Agricultural Bank of China, ABC)作为我国资产规模位居前列的大型国有商业银行,始终坚守"面向'三农'、服务城乡、回报股东、成就员工"的使命,致力于为个人客户、企业客户、涉农主体及政府机构提供全面、稳健、高效的综合金融服务。依托"物理网点+数字金融"双轮驱动的发展战略,农业银行已构建起覆盖全国城乡、贯通县域乡村、辐射海外的庞大服务网络,形成了以总分行统筹管理为核心、县域及乡镇网点为基础、惠农通服务点与线上平台为延伸的多层次、广覆盖、深扎根的金融服务体系。
营业网点作为中国农业银行线下服务的关键载体,不仅是办理存取款、贷款、理财、结算、社保代缴等基础金融业务的重要窗口,更是服务乡村振兴、支持普惠金融、推广"三农"特色产品、开展金融知识普及与客户综合服务的前沿阵地。各营业网点严格执行统一的服务标准与品牌形象规范,注重服务环境的便民性、安全性与智能化升级,积极布设智能柜台、远程视频柜员机(VTM)、惠农终端等设备,尤其在县域和乡镇地区强化基础金融服务能力,持续提升客户体验与运营效率。
本文将探讨如何通过程序化方式,利用 POST 请求调用农业银行官方移动应用或相关服务平台的公开接口,获取其营业网点分布数据。通过 Python 的 requests 库发送 HTTP 请求,解析返回的 JSON 结构化数据,提取网点名称、所属省市区县、详细地址、联系电话、地理坐标(经纬度)、营业时间、是否支持24小时自助服务、网点等级等关键字段,实现对网点信息的自动化采集。该数据可广泛应用于分析农业银行在城乡尤其是县域和农村地区的渠道布局策略、普惠金融服务覆盖密度、金融资源下沉成效及区域协调发展水平,为乡村振兴战略研究、银行网点优化配置、数字乡村建设及智慧金融生态构建提供坚实的数据支撑。
中国农业银行网点查询网址:营业机构查询_中国农业银行
首先,我们找到网点数据的存储位置,然后看3个关键部分标头、 负载、 预览;
**标头:**通常包括URL的连接,也就是目标资源的位置;
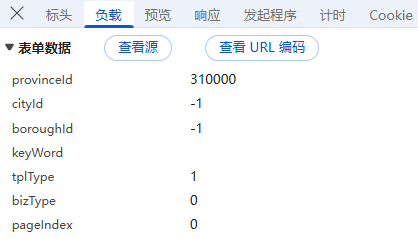
**负载:**对于POST请求:负载通常包含了传递的参数,因为所有参数都通过URL传递,这里我们可以看到省份行政区的编码,页面码等标签,没有进行加密;
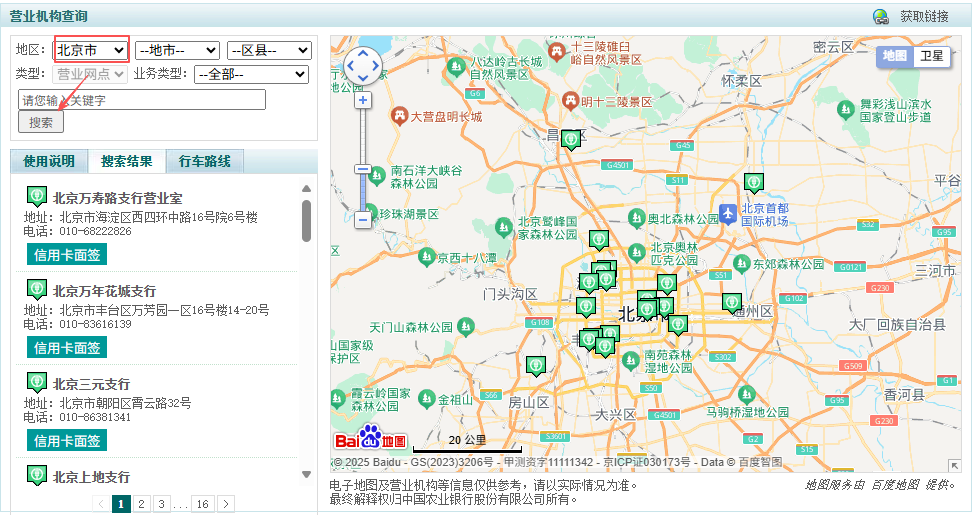
**预览:**指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据在listSearchResultCollectionVo里,这次的网页数据嵌套层级比较深;
python
{
"data": {
"respCode": "...",
"respMessage": "...",
"responseBody": {
"respCode": "...",
"respMessage": "...",
"responseBody": null,
"listSearchResultCollectionVo": [ // ← 数据在这一层级!
{ "BranchBankVo": { ... } },
...
]
}
}
}
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,并手动生成一个省级行政区编码表用于后续进行遍历;
- 我们通过requests库发送HTTP请求,通过遍历省级行政区编码表来获取全国网点的标签数据;
- 地理编码→地址转经纬度,再通过coord-convert库实现BD09转WGS84;
经过测试发现,我们只要选择到省级行政区,就会加载全部的门店网点数据,那么我们直接修改负载中的行政区编码,即可遍历全国农业银行网点数据;
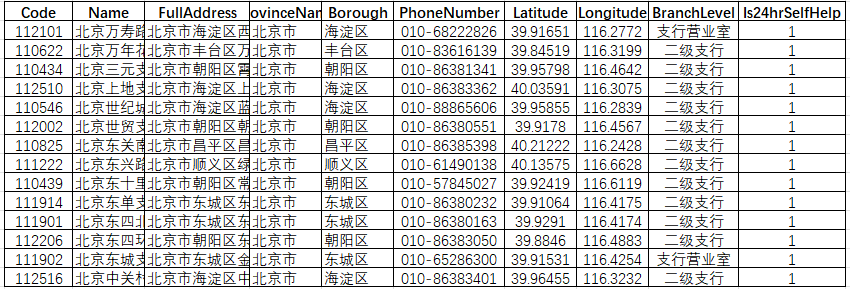
首先,我们观察到它的查询方式是通过不同省级行政区编码进行网点查询,那我们直接在"Fetch/XHR"先找到对应数据存储位置, 我们可以看到响应请求包含省级行政区编码、页码等对应内容的响应请求,另外,根据上面负载的内容,我们可以知道,数据是直接通过行政区编码进行传递的,那我们直接手动生成一个34个省市自治区编码表,因为,它的编码方式与国家的编码一致,所以直接写到脚本进行遍历即可,也不多;
python
provinces = [
("北京市", "110000"),
("天津市", "120000"),
("河北省", "130000"),
("山西省", "140000"),
("内蒙古自治区", "150000"),
("辽宁省", "210000"),
("吉林省", "220000"),
("黑龙江省", "230000"),
("上海市", "310000"),
("江苏省", "320000"),
("浙江省", "330000"),
("安徽省", "340000"),
("福建省", "350000"),
("江西省", "360000"),
("山东省", "370000"),
("河南省", "410000"),
("湖北省", "420000"),
("湖南省", "430000"),
("广东省", "440000"),
("广西壮族自治区", "450000"),
("海南省", "460000"),
("重庆市", "500000"),
("四川省", "510000"),
("贵州省", "520000"),
("云南省", "530000"),
("西藏自治区", "540000"),
("陕西省", "610000"),
("甘肃省", "620000"),
("青海省", "630000"),
("宁夏回族自治区", "640000"),
("新疆维吾尔自治区", "650000"),
]**第一步:**利用requests库发送HTTP请求遍历34个省市自治区的行政区编码并获取所有中国农业银行网点数据,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
python
import requests
import csv
import time
import math
PROVINCES = {
"北京市": "110000", "天津市": "120000", "河北省": "130000", "山西省": "140000",
"内蒙古自治区": "150000", "辽宁省": "210000", "吉林省": "220000", "黑龙江省": "230000",
"上海市": "310000", "江苏省": "320000", "浙江省": "330000", "安徽省": "340000",
"福建省": "350000", "江西省": "360000", "山东省": "370000", "河南省": "410000",
"湖北省": "420000", "湖南省": "430000", "广东省": "440000", "广西壮族自治区": "450000",
"海南省": "460000", "重庆市": "500000", "四川省": "510000", "贵州省": "520000",
"云南省": "530000", "西藏自治区": "540000", "陕西省": "610000", "甘肃省": "620000",
"青海省": "630000", "宁夏回族自治区": "640000", "新疆维吾尔自治区": "650000",
"台湾省": "710000", "香港特别行政区": "810000", "澳门特别行政区": "820000"
}
url = "https://app.abchina.com.cn/branch/Branch"
headers = {
"User-Agent": "ABC/8.6.0 (iPhone; iOS 17.5; Scale/3.00)",
"Content-Type": "application/x-www-form-urlencoded"
}
all_branches = []
for name, pid in PROVINCES.items():
print(f"\n抓取 {name} ({pid})...")
base_data = {
"provinceId": pid, "cityId": "-1", "boroughId": "-1",
"keyWord": "", "tplType": "1", "bizType": "0"
}
# 获取总数
try:
resp = requests.post(url, headers=headers, data={**base_data, "pageIndex": "0"}, timeout=10)
total = int(resp.json().get("data", {}).get("responseBody", {}).get("totalCount", 0))
except Exception as e:
print(f"获取总数失败: {e}")
continue
if total == 0:
print(f"无数据,跳过")
continue
pages = math.ceil(total / 20)
print(f"共 {total} 条,{pages} 页")
for i in range(pages):
try:
data = {**base_data, "pageIndex": str(i)}
resp = requests.post(url, headers=headers, data=data, timeout=10)
list_data = resp.json().get("data", {}).get("responseBody", {}).get("listSearchResultCollectionVo", [])
for item in list_data:
b = item.get("BranchBankVo", {})
all_branches.append({
"ProvinceName": name,
"ProvinceId": pid,
"Name": b.get("Name", ""),
"FullAddress": b.get("FullAddress", ""),
"PhoneNumber": b.get("PhoneNumber", ""),
"Latitude": b.get("Latitude", ""),
"Longitude": b.get("Longitude", ""),
"City": b.get("City", ""),
"Borough": b.get("Borough", ""),
"BranchLevel": b.get("BranchLevel", ""),
"Is24hrSelfHelp": b.get("Is24hrSelfHelp", ""),
"Code": b.get("Code", "")
})
print(f"第 {i + 1} 页:{len(list_data)} 条")
if i < pages - 1:
time.sleep(0.5)
except Exception as e:
print(f"页 {i} 错误: {e}")
continue
time.sleep(1)
# 保存
if all_branches:
with open("abc_branches.csv", "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=all_branches[0].keys())
writer.writeheader()
writer.writerows(all_branches)
print(f"\n完成!共 {len(all_branches)} 条,已保存至 abc_branches.csv")获取数据标签如下:Code(网点id)、Name(网点名称)、ProvinceName(省级行政区)、Borough(地级行政区)、fulladdress(详细地址)、PhoneNumber(电话)、BranchLevel(网点类别)、Is24hrSelfHelp(是否有24小时自助服务1=是,0=否)、lat&lon(地理坐标),其他一些非关键标签,这里省略;
这里有二个tips:1、脚本查询速度不能特别快,不然就会封几分钟ip,这个时候就不能访问了就像下面这样,这里我设置的是,每页请求之间间隔 2 秒,每个省份抓取完成后间隔 1 分钟(60 秒),有需要修改的,可以自行调整time.sleep()值;
2、pageIndex(分页页码),是从0开始,即pageIndex=0 是第 1 页;
第二步: 坐标系转换,由于农业银行网点数据使用的是百度坐标系(BD-09),为了在ArcGIS上准确展示而不发生偏移,我们需要将网点的坐标从BD-09转换为WGS-84坐标系。我们可以利用coord-convert库中的bd2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的网点坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
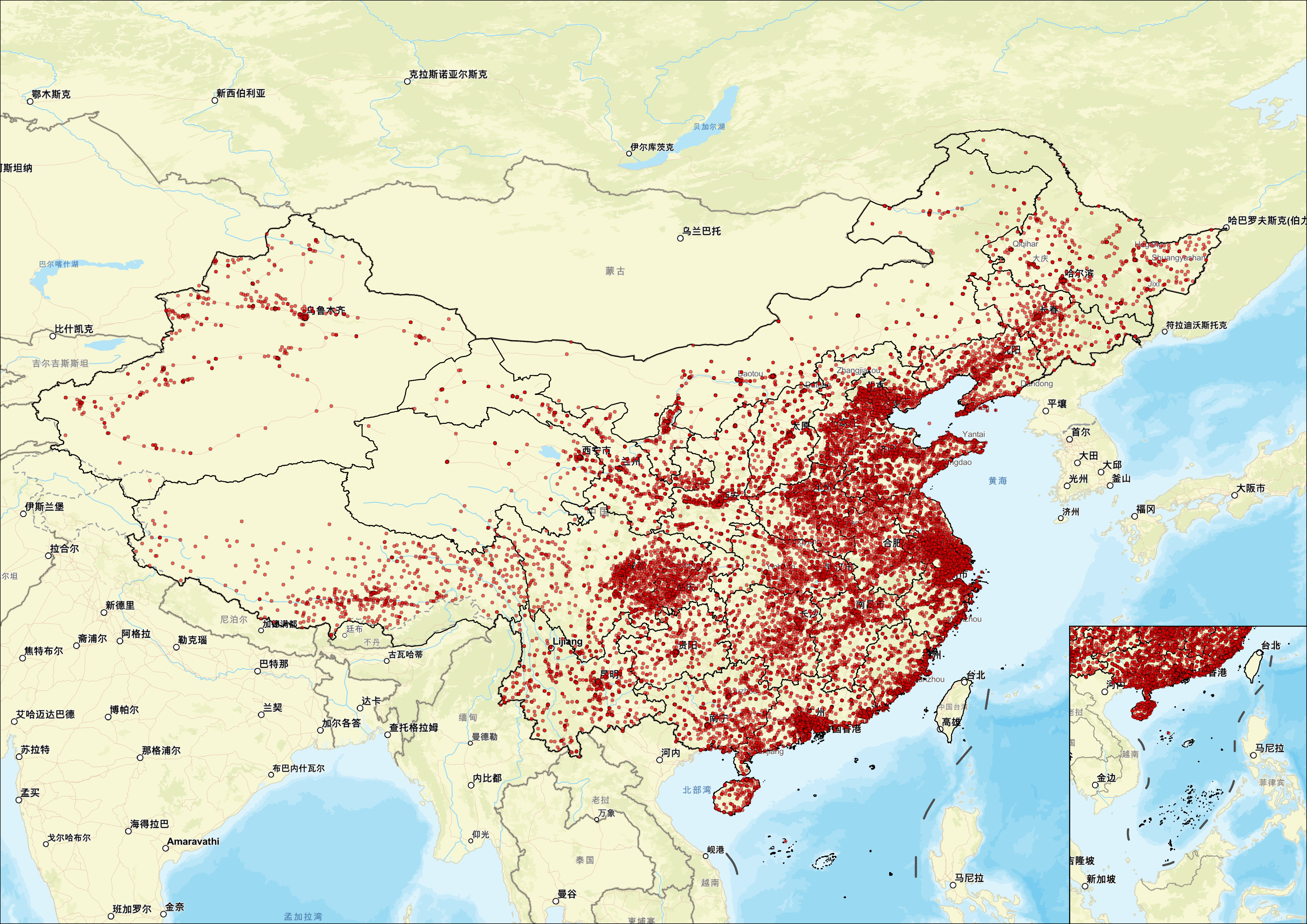
接下来,我们进行看图说话:
从中国农业银行网点分布图来看,其空间布局呈现出典型的"东密西疏、城乡联动、沿交通干线集聚、重点覆盖县域 "特征。东部沿海地区(如京津冀、长三角、珠三角)网点高度密集,形成连片的红色高密度区域。例如,仅上海市中心城区就分布有数十家网点,深圳、广州、杭州等城市也呈现类似格局。这不仅反映了这些区域旺盛的金融需求和高度城市化水平,也体现了农业银行在经济核心区的深度服务渗透能力。
在中西部地区 ,网点分布呈现"以中心城市为枢纽、向县域延伸"的梯度结构。河南、湖北、四川、湖南等农业与人口大省,不仅省会城市网点密集,地级市及多数县级行政区也设有农业银行分支机构。尤其在县域和乡镇,农业银行通过设立综合型网点或"惠农通"服务点,持续下沉服务资源,切实履行"服务"三农"、支持乡村振兴"的国家使命。这种布局有效支撑了普惠金融在广大农村地区的落地,凸显其作为国有大行的社会责任担当。
网点的空间分布还显著受交通基础设施 影响,呈现明显的"沿轴集聚"特征。京广线、陇海线、沪昆线、包茂高速、京港澳高速等国家级交通干道沿线,网点密度明显高于周边区域。这种"交通导向型"布局既提升了客户可达性,也优化了银行自身的运营效率和物流调度。同时,在新疆、西藏、青海、内蒙古等西部边远地区,网点虽整体稀疏,但基本覆盖所有地级市及部分重点县城,如乌鲁木齐、拉萨、西宁、呼伦贝尔等地,形成"点状支撑、辐射周边"的服务格局,努力克服地理与人口稀疏带来的服务难题。
总体而言,农业银行的网点体系是中国金融地理格局的缩影,高度契合国家区域协调发展战略与城乡融合发展导向。其布局既保障了东部发达地区高效率、多元化的金融供给,又通过县域覆盖和科技赋能,弥合了中西部尤其是农村地区的金融服务鸿沟。未来,随着数字化转型加速,农业银行可进一步依托手机银行、智能终端和远程服务,与物理网点形成"线上+线下"互补协同的立体化服务网络,持续提升全国范围内,特别是偏远地区的金融可得性与服务均等化水平。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。