OpenAI Whisper 模型简介
Whisper 是 OpenAI 开发的一款通用语音识别模型,采用大规模弱监督训练方法,支持多语言语音转录和翻译任务。该模型基于 Transformer 架构,具有高准确性和鲁棒性,适用于多种场景下的语音处理需求。OpenAI Whisper作为基于Transformer架构的端到端语音识别模型,其核心设计天然支持多语言处理。
官网:https://openai.com/zh-Hans-CN/index/whisper/
github:https://github.com/openai/whisper

核心特点
- 多语言支持
Whisper 支持包括英语、中文、西班牙语等在内的多种语言,能够识别并转录不同语言的语音内容,部分语言还支持翻译到英语。
- 端到端训练
模型采用端到端训练方式,直接从原始音频数据映射到文本输出,无需额外的中间处理步骤,简化了流程并提高了效率。
- 鲁棒性强
Whisper 在噪声环境、口音差异和跨领域语音数据中表现优异,能够处理多种复杂场景下的语音识别任务。
- 开源模型
OpenAI 开源了 Whisper 的代码和预训练模型,用户可以根据需求下载并使用不同规模的模型(如 tiny、base、small、medium 和 large)。
技术架构
Whisper 基于 Transformer 的编码器-解码器结构:
- 编码器:将输入的音频信号转换为高维特征表示。
- 解码器:根据编码器输出生成对应的文本序列。
训练数据来源于 68 万小时的多样化音频-文本对,涵盖多语言、多领域内容,确保模型的泛化能力。
典型应用场景
- 语音转文字:会议记录、实时字幕生成、播客转录。
- 多语言翻译:将非英语语音实时翻译为英语文本。
- 辅助工具:为听障人士提供实时语音转换服务。
使用方法示例
通过 Python 调用 Whisper 模型实现语音转录的示例代码:
python
import whisper
# 加载预训练模型(例如 'base' 或 'large')
model = whisper.load_model("base")
# 转录音频文件
result = model.transcribe("audio.mp3")
print(result["text"])性能与模型选择
不同规模的模型在准确性和计算资源消耗上有所权衡:
tiny和base:轻量级,适合低延迟场景。small和medium:平衡精度与速度。large:最高精度,但需要更多计算资源。
用户可根据实际需求选择合适的模型版本。
PySide6与Whisper结合
实际项目中,可使用PySide实现基础UI,然后调用Whisper模型实现音频文件的转写功能。
以下是一个基础的UI交互与实际效果:
导入文件进行转写:
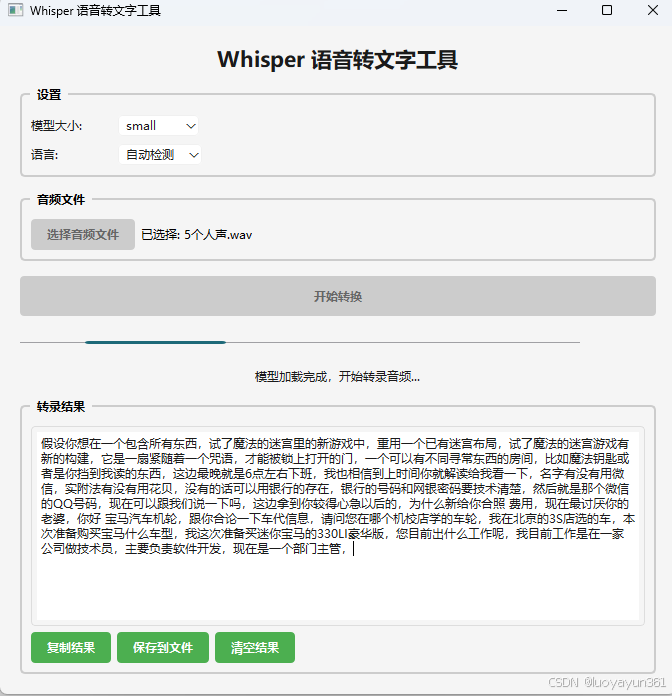
Whisper转写默认是将语音转成对应语言的文本,如中文语音转成中文文本,英文语音转成英文文本,但是部分语音还支持直接将其他语音转成英文文本,如中文语音转成英文文本。不过目前只支持翻译成英文。如果你的应用场景包含这种情况,Whisper将是一个好的选择。
以上示例中,通过Whisper模型转写出来的文本是不带标点符号的,标点是我在后期加上的。而且每段语音会全部转写完成后才会一整段文本完整输出,在当前实例中实现了流式输出,转写一部分就在UI上显示一部分,这样让用户感知不会等太久都没有输出结果。
部分代码
部分代码如下,一个worker类,在线程中执行,我捕获了控制台输出的转写过程内容,实现动态展示转写结果。
如果需要翻译输出结果,在model.transcribe(self.audio_file, **transcribe_options)中添加参数task="translate",就会默认将结束翻译成英文。
bash
class WhisperWorker(QThread):
"""Whisper模型处理工作线程"""
progress_updated = Signal(str)
transcription_completed = Signal(str)
error_occurred = Signal(str)
segment_received = Signal(str) # 新增:实时片段信号
def __init__(self, audio_file, model_size, language):
super().__init__()
self.audio_file = audio_file
self.model_size = model_size
self.language = language
def run(self):
try:
self.progress_updated.emit("正在加载Whisper模型...")
# 检测设备和设置精度
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型,对于CPU使用FP32避免警告
model = whisper.load_model(self.model_size, device=device)
self.progress_updated.emit("模型加载完成,开始转录音频...")
# 捕获器:拦截verbose输出的每一行
class _LineCatcher:
def __init__(self, emit_func):
self._buf = ""
self._emit = emit_func
def write(self, data):
self._buf += data
while "\n" in self._buf:
line, self._buf = self._buf.split("\n", 1)
text = self._extract_text(line)
if text:
self._emit(text)
def flush(self):
pass
def _extract_text(self, line: str):
# 形如:[00:00.000 --> 00:03.800] 内容
if line.startswith("[") and "]" in line:
return line.split("]", 1)[1].strip()
return None
catcher = _LineCatcher(lambda t: self.segment_received.emit(t))
# 转录音频,设置合适的参数
transcribe_options = {
"fp16": device == "cuda", # 只在GPU上使用FP16
"verbose": True # 启用详细日志,Whisper会实时在控制台输出片段
}
with redirect_stdout(catcher):
if self.language == "自动检测":
# 加上task="translate"会默认将语音内容转换成英语,目前只支持英语。不设置的话默认是输出原始的语言
result = model.transcribe(self.audio_file, **transcribe_options)
else:
# 将中文语言名称转换为Whisper支持的语言代码
language_map = {
"中文": "zh",
"英语": "en",
"日语": "ja",
"韩语": "ko",
"法语": "fr",
"德语": "de",
"西班牙语": "es",
"俄语": "ru",
"阿拉伯语": "ar",
"意大利语": "it"
}
lang_code = language_map.get(self.language, "en")
transcribe_options["language"] = lang_code
result = model.transcribe(self.audio_file, **transcribe_options)
self.progress_updated.emit("转录完成!")
logging.info(f"All Result={result['text']}")
self.transcription_completed.emit(result["text"])
except Exception as e:
self.error_occurred.emit(f"转录过程中发生错误: {str(e)}")槽函数处理,添加标点符号:
bash
def on_transcription_completed(self, text):
"""转录完成处理"""
# 如果之前已经实时追加了片段,则不覆盖,保留实时内容
if not self.result_text.toPlainText().strip():
# 没有任何实时片段(如verbose关闭或捕获失败)时,填充完整文本
self.result_text.setPlainText(text)
else:
# 已有实时片段时:将末尾逗号替换为句号,或在缺少终止标点时补句号
current = self.result_text.toPlainText().rstrip()
if current:
last = current[-1]
end_punct = set('。!?!?...')
comma_punct = set(',,')
if last in comma_punct:
# 将末尾逗号替换为句号(按中英文选择)
period = self._choose_period(current)
current = current[:-1] + period
self.result_text.setPlainText(current)
elif last not in end_punct:
# 无终止标点则补句号
period = self._choose_period(current)
self.result_text.setPlainText(current + period)
self.status_label.setText("转录完成!")
logging.info("转录完成,结果已显示在界面")
# 隐藏进度条
self.progress_bar.setVisible(False)
# 重新启用按钮
self.convert_btn.setEnabled(True)
self.select_file_btn.setEnabled(True)
self.copy_btn.setEnabled(True)
self.save_btn.setEnabled(True)
# 不在此处清理worker,避免线程未完全结束就被销毁
# self.worker = None
def on_error(self, error_message):
"""错误处理"""
QMessageBox.critical(self, "错误", error_message)
self.status_label.setText("转录失败")
logging.error(error_message)
# 隐藏进度条
self.progress_bar.setVisible(False)
# 重新启用按钮
self.convert_btn.setEnabled(True)
self.select_file_btn.setEnabled(True)
# 不在此处清理worker,改由finished信号统一处理
# self.worker = None
def on_segment_received(self, text_segment: str):
"""实时接收片段并连接到同一行(不换行)"""
if not text_segment:
return
# 基于分句拼接:默认每个片段末尾补逗号,最后在完成时改为句号
segment = text_segment.strip()
if not segment:
return
current_text = self.result_text.toPlainText()
prefix = ""
if current_text:
prev = current_text[-1]
first = segment[0]
starts_with_punct_or_space = first.isspace() or (first in '([{"\',。!?;:,.!?;:...]')
# 规则1:英文/数字相接且前一个非空白/标点 -> 加空格(中文不加)
if not starts_with_punct_or_space:
if (prev.isalnum() and first.isalnum()) and (not prev.isspace()) and (prev not in '([{"\',。!?;:,.!?;:...]'):
prefix = " "
# 规则2:若上一个字符是英文逗号','且下一段是英文/数字,补一个空格;中文逗号不加空格
if prefix == "" and prev == ',':
if not starts_with_punct_or_space and first.isalnum():
prefix = " "
# 若片段已带终止/逗号标点,则不再补逗号
end_or_comma = set('。!?!?...,,')
to_append = segment
if segment[-1] not in end_or_comma:
to_append += self._choose_comma(segment)
cursor = self.result_text.textCursor()
cursor.movePosition(QTextCursor.End)
cursor.insertText(prefix + to_append)
self.result_text.setTextCursor(cursor)
self.result_text.ensureCursorVisible()
# 首次接收到片段时允许复制/保存
if not self.copy_btn.isEnabled():
self.copy_btn.setEnabled(True)
if not self.save_btn.isEnabled():
self.save_btn.setEnabled(True)
logging.info(f"片段: {segment}")Demo中我默认使用了small 尺寸的模型,速度和转写结果都还不错,而且占用内存不算大,官方提供的对比:

使用本地模型能保护用户隐私,是个不错的选择。如果电脑性能足够好,可以选择更好的模型,结果会更完整和精确。
更多信息可参考官网。