介绍
Regex 是正则表达式(Regular Expression)的简称。它便于匹配、查找和管理文本。
什么是「正则表达式」?
正则表达式是表示搜索模式的字符串,常缩写成 Regex 或 Regexp。它常用于查找和替换文本中的字词。
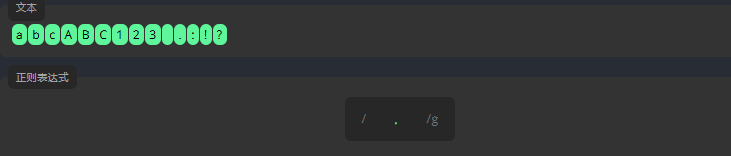
点 .:任何字符
. 允许匹配任何字符,包括特殊字符和空格。
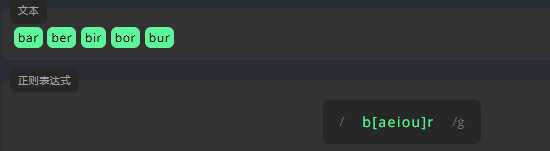
字符集 abc
如果一个词中的字符可以是各种字符,我们就将所有的可选字符写进中括号 \[\] 中。例如,为了查找文本中的所有单词,我们需要编写表达式,在 \[\] 中相邻地输入字符 a、e、i、o、u。
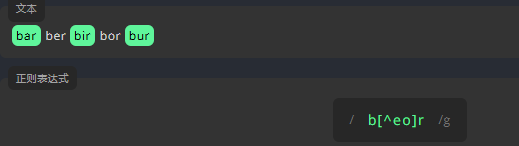
否定字符集 \^abc
为了查找下方文本的所有单词(ber 和 bor 除外),请在 \[\] 中的 ^ 后面并排输入 e 和 o。
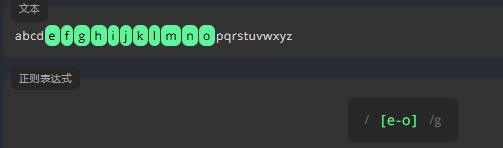
字母范围 a-z
为了查找指定范围的字母,我们需要将起始字母和结束字母写进 \[\] 中,中间用连字符 - 分隔。它区分大小写。请编写表达式,匹配 e 和 o 之间所有的小写字母,包括它们本身。
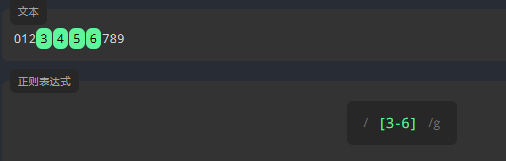
数字范围 0-9
为了查找指定范围的数字,我们需要在 \[\] 中输入起始和结束数字,中间用连字符 - 分隔。请编写表达式,匹配 3 到 6 之间的所有数字,包括它们本身。
重复
一些特殊字符用来指定一个字符在文本中重复的次数。它们分别是加号 +、星号 * 和问号 ?。
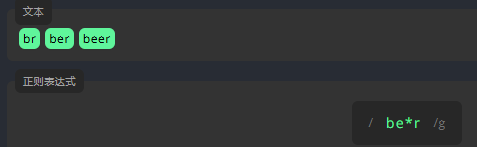
星号 *
我们在字符后面加上 *,表示一个字符完全不匹配或可以匹配多次。例如,表示字母 e 在下方文本中不出现,只出现 1 次或者并排出现多次。
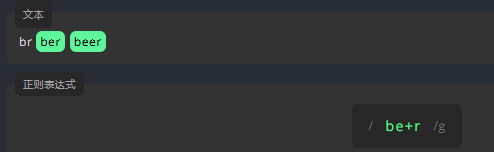
加号 +
为了表示一个字符可以出现一次或多次,我们将 + 放在它后面。例如,表示 e 在下方文本中出现一次或多次
问号 ?
为了表示一个字符是可选的,我们在它后面加一个 ?。例如,表示下方文本中的字母 u 是可选的。
大括号 - 1
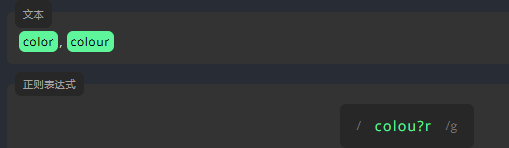
为了表示一个字符出现的确切次数,我们在该字符的末尾,将它出现的次数写进大括号 {} 中,如 {n}。例如,表示下方文本中的字母 e 只能出现 2 次。
大括号 - 2
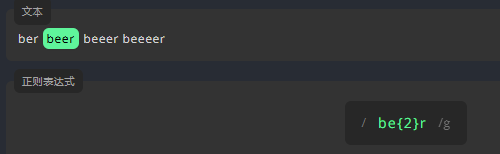
为了表示一个字符至少出现多少次,我们在该字符的末尾,将它至少应出现的次数写进大括号 {} 中,并在数字后面加上逗号 ,,如 {n, }。例如,表示下方文本中的字母 e 至少出现 3 次。
大括号 - 3
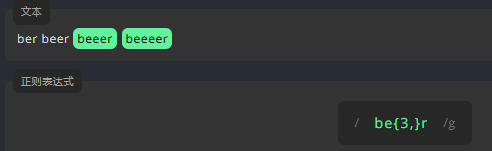
为了表示一些字符出现的次数在某个数字范围内,我们在该字符的末尾,将它至少和至多出现的次数写进大括号 {} 中,中间用逗号 , 分隔,如 {x,y}。例如,匹配下方文本中,字母 e 出现 1 至 3 次的单词。
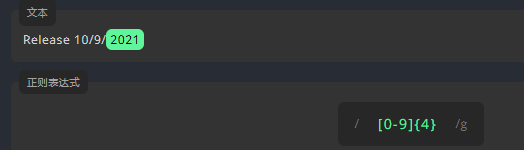
练习:大括号 - 1
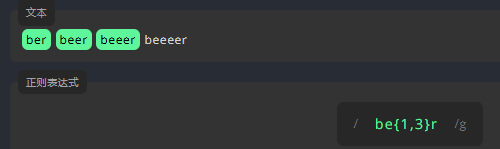
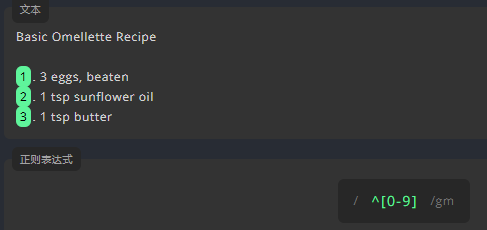
用 {} 编写表达式,匹配文本中,位数为 4 的阿拉伯数字。
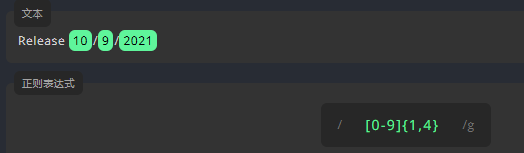
练习:大括号 - 3
用 {} 编写表达式,匹配文本中,位数为 1 至 4 的阿拉伯数字
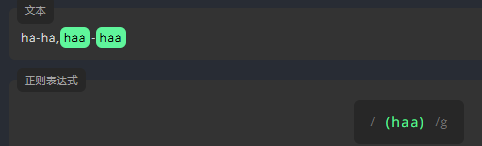
括号 ( ): 分组
我们可以对一个表达式进行分组,并用这些分组来引用或执行一些规则。为了给表达式分组,我们需要将文本包裹在 () 中。现在,请尝试为下方文本中的 haa 构造分组。
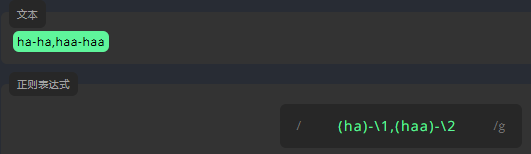
引用组
单词 ha 和 haa 分组如下。第一组用 \1(等价于第一个括号内容) 来避免重复书写。这里的 1 表示分组的顺序。请在表达式的末尾键入 \2 (等价于第二个括号内容)以引用第二组。
括号 (?: ): 非捕获分组
您可以对表达式进行分组,并确保它不被引用捕获。例如,下面有两个分组,但我们用 \1 引用的第一个组实际上是指向第二个组,因为第一个是未被捕获的分组。
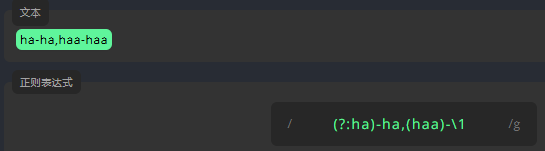
竖线 |
竖线允许一个表达式包含多个不同的分支。所有分支用 | 分隔。和在字符层面上运作的字符集 abc 不同,分支在表达式层面上运作。例如,下面的表达式同时匹配 cat 和 rat。请在末尾添加另一个 |,并输入 dog 以匹配所有单词。
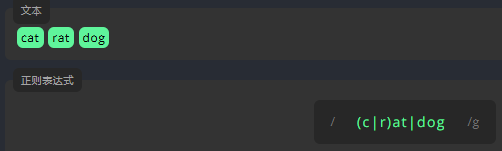
转义字符 \
在书写正则表达式时,我们会用到 { } / \ + * . $^ | ? 这些特殊字符 。为了匹配这些特殊字符本身,我们需要通过 \ 将它们转义。例如,要匹配文本中的 . 和 *,我们需要在它们前面添加一个 \。
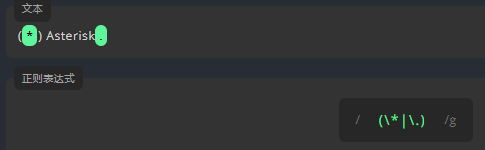
插入符 ^: 匹配字符串的开始
我们用 0-9 查找数字,若仅查找行首的数字,请在表达式前面加上 ^。
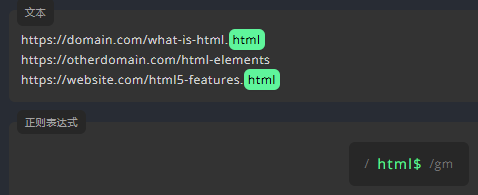
美元符号 $: 匹配字符串的结束
让我们在 html 的后面添加 $,来查找仅在行末出现的 html。
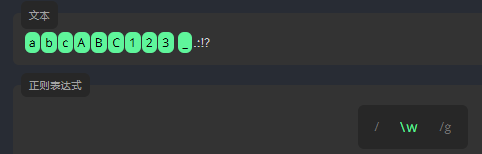
单词字符 \w: 字母、数字和下划线
表达式 \w 用于查找字母、数字和下划线。让我们用表达式 \w 来查找文本中的单词字符。
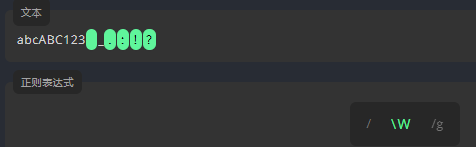
非单词字符 \W
\W 匹配除字母、数字和下划线之外的字符。
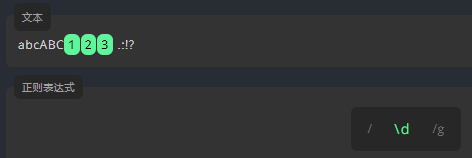
数字字符 \d
\d 仅用来匹配数字。
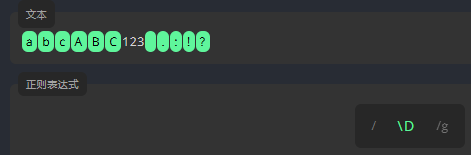
非数字字符 \D
\D 匹配除数字之外的字符。
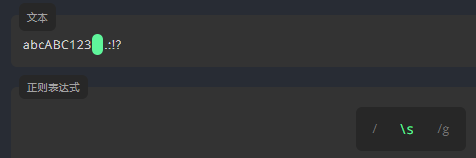
空白符 \s
\s 仅匹配空白字符。
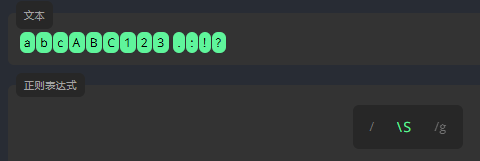
非空白符 \S
\S 匹配除空白符之外的字符。
零宽断言
如果我们希望正在写的词语出现在另一个词语之前或之后,我们需要使用「零宽断言」。请前往下一步骤,学习如何使用「零宽断言」。
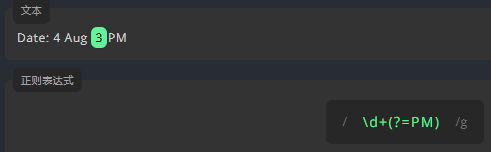
正向先行断言: (?=)
例如,我们要匹配文本中的小时值。为了只匹配后面有 PM 的数值,我们需要在表达式后面使用正向先行断言 (?=),并在括号内的 = 后面添加 PM。
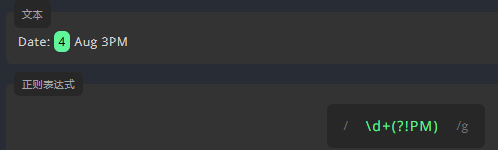
负向先行断言: (?!)
例如,我们要在文本中匹配除小时值以外的数字。我们需要在表达式后面使用负向先行断言 (?!),并在括号内的 ! 后面添加 PM,从而只匹配没有 PM 的数值。
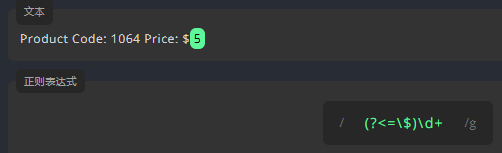
正向后行断言: (?<=)
例如,我们要匹配文本中的金额数。为了只匹配前面带有 的数字。我们要在表达式前面使用正向后行断言 (?\<=),并在括号内的 = 后面添加 \\。
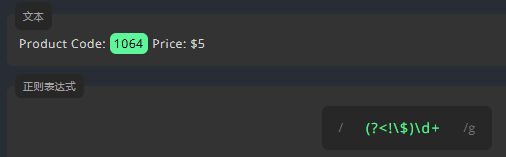
负向后行断言: (?<!)
例如,我们要在文本中匹配除价格外的数字。为了只匹配前面没有 的数字,我们要在表达式前用负向后行断言 (?\。
标志
标志改变表达式的输出。这就是标志也称为 修饰符 的原因。标志决定表达式是否将文本视作单独的行处理,是否区分大小写,或者是否查找所有匹配项。请继续下一步步骤以学习标志。
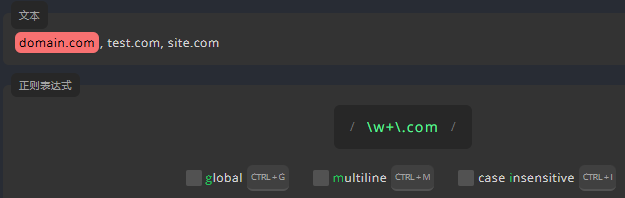
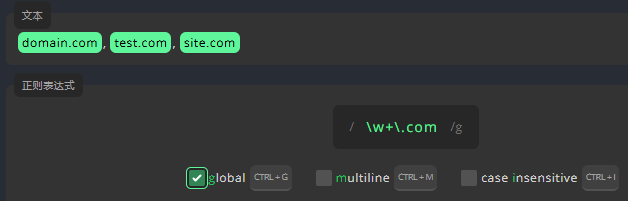
全局标志
全局标志使表达式选中所有匹配项,如果不启用全局标志,那么表达式只会匹配第一个匹配项。现在,请启用全局标志,以便匹配所有匹配项。
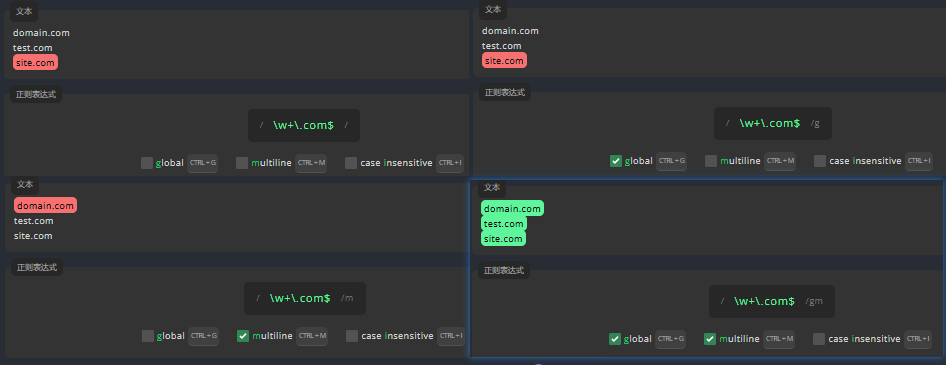
多行标志
正则表达式将所有文本视作一行。但如果我们使用了多行标志,它就会单独处理每一行。这次,我们将根据每一行行末的规律来写出表达式,现在,请启用多行标志来查找所有匹配项。
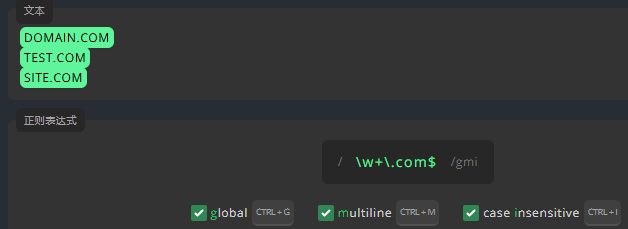
忽略大小写标志
为了使我们编写的表达式不再大小写敏感,我们必须启用 不区分大小写 标志。
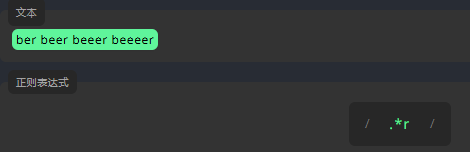
贪婪匹配
正则表达式默认执行贪婪匹配。这意味着匹配内容会尽可能长。请看下面的示例,它匹配任何以 r 结尾的字符串,以及前面带有该字符串的文本,但它不会在第一个 r 处停止匹配。
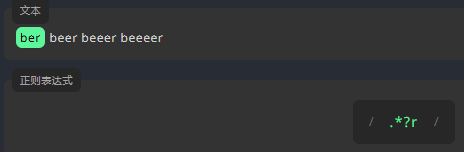
懒惰匹配
与贪婪匹配不同,懒惰匹配在第一次匹配时停止。下面的例子中,在 * 之后添加 ?,将查找以 r 结尾且前面带有任意字符的第一个匹配项。这意味着本次匹配将会在第一个字母 r 处停止。