批量处理数据的时候需要提取文件名的器件编号。
通常器件编号具有一定的规则。
可以通过正则表达式来提取
正则表达式的函数及其用法。
正则表达式是一种用于匹配和操作文本的强大工具,它由普通字符和特殊字符(称为"元字符")组成,用于描述要匹配的文本模式。
正则表达式可以在文本中查找、替换、提取和验证特定的模式。
例如:
-
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1 次或多次)尝试一下 >>。
-
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0 次、或 1 次、或多次)尝试一下 >>。
-
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0 次或 1 次)
1正则表达式
re库有正则表达式
Import re
re.compile 函数-编译正则表达式
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,可以给 match() 、 search() 以及 findall 等函数使用。
语法格式为:
re.compile(pattern, flags)
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
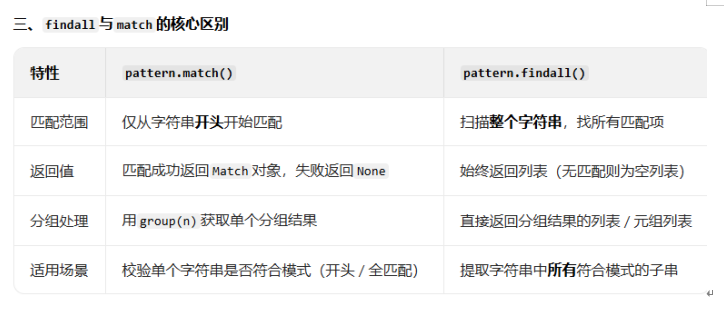
findall函数,找到正则表达式所匹配的所有子串,并返回一个列表
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次,findall 是匹配所有。
语法格式为:
findall(string, pos\[, endpos])
参数:
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
|------------|------------------------------------------------------------------------------------------------------------|
| 普通字符 | 描述 |
| ABC | 匹配 ... 中列出的所有字符。例如 aeiou 匹配字符串 "google runoob taobao" 中所有的 e、o、u、a 字母。 |
| \^ABC | 匹配除了 ... 中字符以外的所有字符。例如 \^aeiou 匹配字符串 "google runoob taobao" 中除了 e、o、u、a 字母以外的所有字符。 |
| A-Z | A-Z 表示一个区间,匹配所有大写字母;a-z 匹配所有小写字母;0-9 匹配所有数字。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,等价于 \^\\n\\r。 |
| \\s\\S | 匹配所有字符(包括换行符)。\s 匹配所有空白符(包括换行),\S 匹配所有非空白符(不包括换行),两者合并即可匹配任意字符。 |
| \w | 匹配字母、数字、下划线,等价于 A-Za-z0-9_。 |
| 非打印字符 | |
| \cx | 匹配由 x 指明的控制字符。例如,\cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一,否则将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符,等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符,等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符,等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等,等价于 \\f\\n\\r\\t\\v。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符,等价于 \^ \\f\\n\\r\\t\\v。 |
| \t | 匹配一个制表符,等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符,等价于 \x0b 和 \cK。 |
| \cx | 匹配由 x 指明的控制字符。例如,\cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一,否则将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符,等价于 \x0c 和 \cL。 |
| 特殊字符 | |
| | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 也匹配 '\n' 或 '\r'。要匹配 字符本身,请使用 \\。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符本身,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符本身,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . 本身,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符本身,请使用 \?。 |
| \ | 将下一个字符标记为特殊字符、原义字符、向后引用或八进制转义符。例如,'n' 匹配字符 'n','\n' 匹配换行符,'\\' 匹配 "\",'\(' 匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。在方括号表达式中使用时,表示不接受方括号内的字符集合(取反)。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
| 限定符 | 限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。共有 *、+、?、{n}、{n,}、{n,m} 共 6 种。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 和 "does",但不能匹配 "dog"。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数,匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数,至少匹配 n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+,o{0,} 等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。注意:逗号和两个数之间不能有空格。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 和 "does",但不能匹配 "dog"。? 等价于 {0,1}。 |
元组解包
device_id, voltage, direction_char = match_list0#match_list实际内总('1A-2', '1V', 'F') # 列表里只有1个元组,元组里有3个元素
元组解包(Tuple Unpacking) 特性:
等号左边的变量数量必须和等号右边元组的元素数量一致(这里都是 3 个)
Python 会按顺序将元组中的每个元素赋值给对应的变量:
元组第 1 个元素'1A-2' → 赋值给device_id
元组第 2 个元素'1V' → 赋值给voltage
元组第 3 个元素'F' → 赋值给direction_char
1.1提取器件编号-compile
我们把正则表达式拆分成带编号的分组,看左括号的顺序:
正则表达式片段 左括号(的顺序 对应分组编号
匹配内容示例(输入:1A-2-DrainV=1V-F)
(.+?) 第 1 个左括号 group(1) 1A-2(器件编号)
(\\d\\.+V) 第 2 个左括号 group(2) 1V(电压值部分)
(A-Z) 第 3 个左括号 group(3) F(扫描方向字符)
python
# 导入正则表达式模块,用于字符串的匹配和提取操作
import re
def extract_device_info(input_str):
"""
从输入字符串中提取器件编号、漏极电压和扫描方向
参数:
input_str (str): 输入字符串,格式如"1A-2-DrainV=1V-F"
返回:
dict: 包含器件编号、漏极电压、扫描方向的字典,提取失败时对应值为None
"""
# 编译正则表达式模式,使用分组捕获目标内容
# 正则表达式解析:
# ^:匹配字符串开头
# (.+?):非贪婪匹配,捕获分组1(器件编号,如1A-2)
# -DrainV=:匹配固定分隔符"-DrainV="
# ([\d\.]+V):捕获分组2(电压值,支持整数/小数+V,如1V、2.5V)
# -:匹配分隔符"-"
# ([A-Z]):捕获分组3(扫描方向的字符,如F、Z)
# $:匹配字符串结尾
pattern = re.compile(r'^(.+?)-DrainV=([\d\.]+V)-([A-Z])$')#编译正则表达式
# 使用编译后的正则表达式匹配输入字符串,返回匹配对象(成功)或None(失败)
match = pattern.match(input_str)
# 判断是否匹配成功
if match:
# 提取分组1的内容,作为器件编号
device_id = match.group(1)
# 拼接分组2的电压值,还原漏极电压的完整格式(如DrainV=1V)
drain_voltage = f"DrainV={match.group(2)}"
# 拼接分组3的字符,还原扫描方向的完整格式(如-F、-Z)
scan_direction = f"-{match.group(3)}"
# 返回包含提取结果的字典
return {
"器件编号": device_id,
"漏极电压": drain_voltage,
"扫描方向": scan_direction
}
else:
# 匹配失败时,返回各字段为None的字典
return {
"器件编号": None,
"漏极电压": None,
"扫描方向": None
}
# 主程序入口,仅在直接运行该脚本时执行以下测试代码
if __name__ == "__main__":
# 定义第一个测试用例:标准格式(整数电压+F方向)
test_str1 = "1A-2-DrainV=1V-F"
# 调用函数提取信息
result1 = extract_device_info(test_str1)
# 打印输入字符串
print(f"输入:{test_str1}")
# 打印提取结果
print(f"提取结果:{result1}\n")
# 定义第二个测试用例:小数电压+Z方向
test_str2 = "3B-5-DrainV=2.5V-Z"
# 调用函数提取信息
result2 = extract_device_info(test_str2)
# 打印输入字符串
print(f"输入:{test_str2}")
# 打印提取结果
print(f"提取结果:{result2}\n")
# 定义第三个测试用例:格式错误的字符串(用于验证异常处理)
test_str3 = "invalid_str"
# 调用函数提取信息
result3 = extract_device_info(test_str3)
# 打印输入字符串
print(f"输入:{test_str3}")
# 打印提取结果
print(f"提取结果:{result3}")1.2 示例
python
import os
import re
# --------------------------
# 方式1:从指定文件夹中自动读取所有csv文件
# --------------------------
def extract_device_ids_from_folder(folder_path):
device_ids = []
for filename in os.listdir(folder_path):
if filename.endswith('.csv'):
# 正则表达式提取NMOS-CS#后的编号
match = re.search(r'NMOS-CS#([^.]+)\.csv', filename)
if match:
device_ids.append(match.group(1))
# 去重并排序
unique_ids = sorted(list(set(device_ids)))
return unique_ids
# --------------------------
# 方式2:直接处理文件名列表(测试用)
# --------------------------
def extract_device_ids_from_filenames(file_names):
device_ids = []
for filename in file_names:
match = re.search(r'NMOS-CS#([^.]+)\.csv', filename)
if match:
device_ids.append(match.group(1))
unique_ids = sorted(list(set(device_ids)))
return unique_ids
# --------------------------
# 示例运行
# --------------------------
if __name__ == "__main__":
# 你可以替换为你的实际文件夹路径
# folder_path = "你的数据文件夹路径"
# ids = extract_device_ids_from_folder(folder_path)
# 测试用文件名列表
test_files = [
"NMOS-CS#25B-1-1-1.csv",
"NMOS-CS#25B-1-1-2.csv",
"NMOS-CS#25B-1-1-3.csv",
"NMOS-CS#25B-1-2-1.csv",
"NMOS-CS#25B-1-2-2.csv",
"NMOS-CS#25B-1-2-3.csv",
"NMOS-CS#25B-1-3-1.csv",
"NMOS-CS#25B-1-3-2.csv"
]
ids = extract_device_ids_from_filenames(test_files)
print("提取到的器件编号:")
for idx, dev_id in enumerate(ids, 1):
print(f"{idx}. {dev_id}")
# 保存到文本文件
with open("device_ids.txt", "w") as f:
for dev_id in ids:
f.write(dev_id + "\n")
print("\n已将编号保存到 device_ids.txt")