本章介绍将"学习"引入智能体系统的多种方法与集成技巧。让智能体具备随时间学习与改进的能力非常有用,但在设计智能体时并非绝对必要。实现学习能力需要额外的设计、评估与监控工作,是否值得投入取决于具体应用。这里所说的"学习",是指智能体系统通过与环境交互来提升其性能的过程。这个过程使智能体能够适应变化的条件,优化策略,并整体提升效能。
**非参数学习(Nonparametric learning)**指在不改变所用模型参数的前提下,自动改变与提升系统表现的技术。相对地,参数学习(Parametric learning)指通过专门训练或微调基础模型的参数来改进性能的技术。我们将先从非参数学习技术开始,随后讨论参数化的微调方法,包括 有监督微调(SFT)与直接偏好优化(DPO) ,以针对性地调整模型权重实现改进。
非参数学习
实现非参数学习的技术有很多,本章将探讨几种常见且实用的方式。
非参数的示例学习(Exemplar Learning)
其中最简单的一种是示例学习 。在这种方式中,智能体执行任务的同时会获得质量度量,这些样例随后用于提升未来表现。它们通常作为**少样本(few-shot)示例出现在上下文学习(in-context learning)**中。在最简单的"固定少样本"版本里,这些示例被硬编码到提示词中且不会变化(见图 7-1 左侧)。
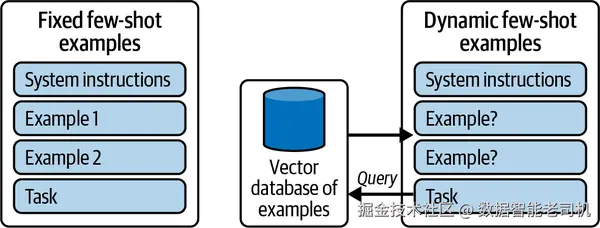
**图 7-1 固定 vs 动态的少样本选择。**左侧:在系统提示中使用静态少样本集合。右侧:动态少样本选择会在运行时从向量数据库检索最相关的示例,使提示更具自适应性与上下文相关性。
如果我们有更多示例,可以继续把它们塞进提示里,但这会增加成本与时延;而且并非所有示例对每个输入都有效。一个常见做法是动态选择 与当前输入最相关的示例加入提示(见图 7-1 右侧)。这些"经验"作为示例,需要以便于将来检索的方式进行持久化保存。通常会构建一个记忆库(memory bank) ,把每次交互的细节------如上下文、采取的行动、结果以及收到的反馈------存储起来。这个数据库就像人的记忆:过去的经历塑造理解并引导未来行动。每段经验都为智能体在遇到相似情境时提供可参考的数据点,从而帮助它做出更好的决策。借此,智能体可以逐步累积一个可复用的知识库,用以提升表现。
当面对新问题时,智能体会从这套过往案例数据库中检索信息。每个存档案例包含问题描述、所用解法以及其效果。当遇到新情境,智能体会检索相似案例,分析曾采用的解决方案,并在必要时做出调整以适配新情况。这种方法灵活度高:智能体可依据"什么有效/无效"来调整做法,不断打磨其问题求解策略。
当成功样例被保存并在后续作为示例注入提示中时,许多任务的性能都会显著提升。这一结论在多个领域已被反复验证。实践中,这给了我们一种简单、透明、轻量 的手段来快速提高智能体在特定任务上的表现。随着成功样例数量的增长,最好按类型、文本检索或语义检索的方式,只取最相关 的成功样例。需注意,该技术既可用于智能体的整体任务执行 ,也可以针对任务的子步骤独立实施。
Reflexion
Reflexion 为智能体配备了一种基于语言的自我批判习惯:每次尝试失败后,智能体会用简短文字反思"哪里出了问题、下一次应如何改进"。随着时间推移,这些反思会与先前的动作与观察一起保存在"记忆缓冲区"中。每次新尝试前,智能体会重读最近的反思,从而在无需重新训练模型的情况下调整策略。
高层流程如下:
- 执行一次动作序列:智能体按常规的"由提示驱动的规划"与环境交互。
- 记录试验:将每一步(采取的动作、收到的观察、成功/失败)附加写入持久化日志(如 JSON 文件或数据库)。
- 生成反思:若试验失败,智能体构造一个"反思提示",包含近期交互历史与一段模板性问题("我遗漏了什么策略?下次该怎么做?"),由 LLM 生成简明计划。
- 更新记忆 :辅助函数
update_memory读取试验日志、用反思提示调用 LLM,并把新的反思写回智能体的记忆结构。 - 在下一轮注入反思:当智能体再次尝试相同或相似任务时,会把最近的反思预置到提示前部,引导模型采用改进后的策略。
Reflexion 非常轻量:不触碰模型权重,只是让基础模型"自我教练"。它既能容纳数值型反馈(如成功标志),也能接纳自由文本评论,已被证明可提升从代码调试到多步推理在内的多类任务表现。见图 7-2。
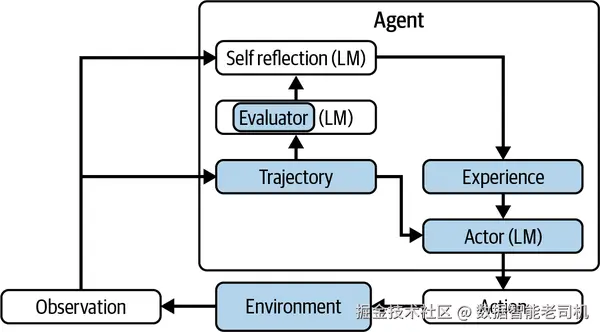
图 7-2 Reflexion 智能体。
(以下代码保留)
ini
from typing import Annotated, List, Dict
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START
from langchain_core.messages import HumanMessage
llm = ChatOpenAI(model="gpt-5")
reflections = []
def call_model(state: MessagesState):
response = llm.invoke(state["messages"])
return {"messages": response}
reflexion_prompt = f"""You will be given the history of a past experience in
...
Plan:
"""
...上述提示由三部分构成,把模型变成自己的教练:首先用一段简短框架指令告知模型"你这次失败了------别复述环境,专注于策略失误,并在'Plan'之后输出精炼的改进计划",以保证输出简洁、便于解析。接着在"Instruction:"下重申原始目标(例如"找到 30 美元以下的无奶苹果口味薯片拼装包"),让反思锚定真实任务。最后附上失败运行的完整"动作/观察"记录------每次搜索、点击与内部思考,最终以 STATUS: FAIL 收尾------为模型提供具体证据。以"Plan:"作为收尾提示,让模型从"诊断"转向"处方",产出聚焦的下一步建议。下方 Python 实现展示了如何搭建这份"三段式教练提示"------框架指令、在"Instruction:"下重述目标、完整动作/观察抄本------并以"Plan:"收束:
python
def get_completion(prompt: str) -> str:
...
def _generate_reflection_query(trial_log: str, recent_reflections: List[str]):
...
def update_memory(trial_log_path: str, env_configs: List[Dict[str, Any]]):
...
builder = StateGraph(MessagesState)
...
update_memory(trial_log_path, env_configs)这个示例围绕少量核心思想,用不到 20 行关键代码串起:首先将所有 LLM 调用封装在 call_model(state) 中,使图节点职责单一且可复用;其次,精心设计一条多行"反思提示",要求模型:承认失败、聚焦错过的关键步骤,并在"Plan"后给出简短计划 ;然后把每次试验的完整日志落盘,在失败后调用 update_memory(...) 读取日志、引入最近几条反思(限制上下文长度),并让 LLM 生成新的自我批注,追加回内存列表。最后,在状态图中加入一个"reflexion"节点(自 START 连入),让每次运行都自动调用该提示,并把最新的"Plan: ..."写入状态。多次迭代后,模型等于成了自己的教练------无须改权重也能持续打磨策略。
体验式学习(Experiential Learning)
体验式学习在非参数学习基础上更进一步。智能体同样把自身经验收集到数据库,但会跨经验聚合洞见 ,以改进未来的策略(policy)。这对反思过去失败并总结可迁移的方法尤其有价值。智能体从经验库中提炼洞见,并长期维护 这份洞见清单;它会动态调整这些洞见:提升最有价值的、下调价值较低的,并依据新经验进行修订。
这一思路在 Reflexion 之上,引入跨任务学习 流程,使智能体在切换任务时也能提升表现,并识别可迁移的"好做法"。在这种方法中,ExpeL 维护一份从过往经验中提取的洞见列表。随着时间推进,可以新增洞见,也能对既有洞见进行编辑、上/下调或移除(见图 7-3)。
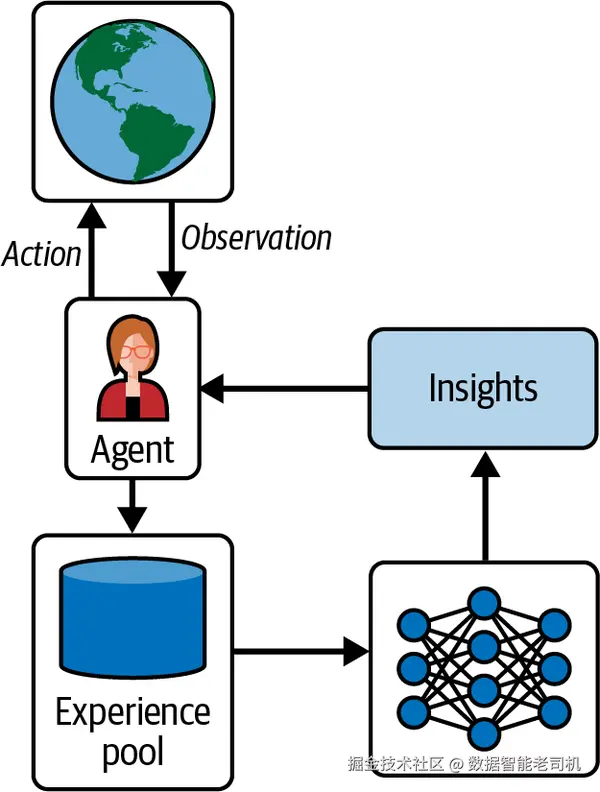
图 7-3 体验式学习智能体。
这个过程从一项简单步骤开始:让基础模型围绕来自环境的观察进行反思,目标是在未来任务中产生更好的表现所需的洞见:
python
from typing import Annotated
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START
from langchain_core.messages import HumanMessage
# Initialize the LLM
llm = ChatOpenAI(model="gpt-5")
...
class InsightAgent:
...
def generate_insight(self, observation):
...当样例较少时,这可能工作良好;若样例很多,则需要一种简单有效的管理方式:定期重评这些洞见,并相对其他规则调整其重要性。例如,可以使用如下示例提示,对过往行动进行反思,生成能改进未来试验表现的新规则:
通过与成功试验进行对照,并结合现有规则清单,你可以进行以下操作:添加、编辑、移除或同意 ,以确保新的规则清单能对失败试验或拟议的思路给出一般性且高层次的批评,从而可在面对不同问题时复用,避免类似失败。强调如何改进**思考(Thought)与行动(Action)**的方式。(ExpeL)
随后会定期重评与调序这些学到的规则,相对其他经验规则调整其重要性。评估与改进既有规则的方法如下:
可用操作:AGREE (若该规则与当前任务强相关)、REMOVE (若该规则与其他规则矛盾或重复)、EDIT (若该规则不够通用或可增强)、ADD(引入不同于既有规则且对其他任务也相关的新规则)。请严格使用如下格式(任何未被编辑/同意/移除的既有规则视为"保留"):
AGREE <EXISTING RULE NUMBER>: <EXISTING RULE>REMOVE <EXISTING RULE NUMBER>: <EXISTING RULE>EDIT <EXISTING RULE NUMBER>: <NEW MODIFIED RULE>ADD <NEW RULE NUMBER>: <NEW RULE>
这一流程稍复杂,但逻辑仍可控:它让有用的洞见在后续经验中得到动态改进 。图 7-4 展示了该过程:模型从成功/失败对 中提炼洞见,并在时间维度上对洞见进行提升与下调 ,最终蒸馏出一小组用来指导决策与提升表现的通用高层规则。
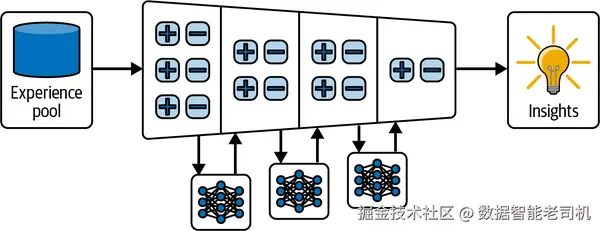
**图 7-4 通过提炼与蒸馏洞见实现的体验式学习。**智能体先将经验汇入经验池;随后多次模型评估从这些经验中提取洞见,并聚合蒸馏成简洁的通用高层批评与规则。蒸馏后的洞见指导后续决策,使智能体能随时间在跨任务场景中提升表现。
下文展示了这些规则如何被创建、上调、修改与移除,从而使智能体能随时间提升任务表现:
ruby
def promote_insight(self, insight):
...
def demote_insight(self, insight):
...
def edit_insight(self, old_insight, new_insight):
...
def show_insights(self):
...
def reflect(self, reflexion_prompt):
...在有足够反馈的前提下,这一过程提供了一条高效 的路径,让智能体从环境交互中学习并随时间改进。一个额外优势是:它有助于智能体逐步适应非平稳环境。因此,如果你的智能体需要随着环境变化调整策略,这种方法能有效支撑。以下是一个使用示例:
ini
agent = InsightAgent()
reports = [
("Website traffic rose by 15%, but bounce rate jumped from 40% to 55%.", False),
("Email open rates improved to 25%, exceeding our 20% goal.", True),
("Cart abandonment increased from 60% to 68%, missing the 50% target.", False),
("Average order value climbed 8%, surpassing our 5% uplift target.", True),
("New subscription sign-ups dipped by 5%, just below our 10% growth goal.", False),
]
for text, hit_target in reports:
insight = agent.generate_insight(text)
if hit_target:
agent.promote_insight(insight)
else:
agent.demote_insight(insight)
if agent.promoted_insights:
original = agent.promoted_insights[0]
agent.edit_insight(original, f'''Refined: {original} Investigate
landing-page UX changes to reduce bounce.''')
agent.show_insights()
reflection_prompt = (
"Based on our promoted insights, suggest one high-impact experiment we can
run next quarter:"
f"\n{agent.promoted_insights}"
)
agent.reflect(reflection_prompt)如你所见,即便只有很少的代码,也能让智能体持续从经验中学习 ,并在特定任务上不断提升。这些方法务实、经济、易实现 ,并能带来持续的自适应改进。当然,在某些情况下,尤其是当你拥有大量样本 可供学习时,转而考虑微调也可能更合适。
参数学习:微调(Parametric Learning: Fine-Tuning)
参数学习 指通过调整既定模型的参数来提升其在特定任务上的表现。当我们拥有评测数据时,可以利用它来改进系统表现。实践中,通常先从非参数 方法入手,因为实现更简单、见效更快。不过,将示例与洞见不断加入提示词也会消耗时间与算力;当积累了足够多的样本后,值得考虑对模型进行微调,以进一步提升智能体在目标任务上的表现。**微调(fine-tuning)**是常见做法:在大规模预训练模型的基础上,针对新任务或新数据集对其参数做小幅适配。
微调大型基础模型(Fine-Tuning Large Foundation Models)
多数开发者在搭建智能体系统时,会选用通用的大型基础模型,如 GPT-5、Claude Opus、Gemini 等,因为它们在多类任务上具有卓越的通用能力。这些模型基于覆盖面广的通用数据集进行预训练,具备丰富的语言与概念知识;厂商也会在此基础上投入大量后训练 (post-training)工作。对这类模型进行微调,就是对其参数做有针对性的调整 ,以贴合特定任务或领域。这样既能把模型的广博知识迁移到专业场景中,提升在特定任务上的相关性与有效性,又能保留其通用能力。图 7-5展示了通用微调流程:在大规模预训练之后,使用经策划的领域数据集执行任务定制化的微调。
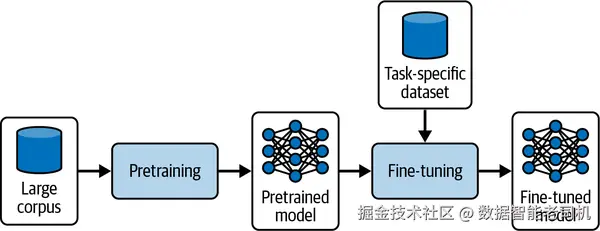
**图 7-5 微调工作流。**语言模型先在广泛语料上预训练以形成通用能力,再用规模较小的任务数据集做微调,得到与领域需求对齐的专用模型。
是否投入微调取决于你的具体需求、资源状况与后续维护计划。以下情形可重点考虑微调:
- 领域专精至关重要
你需要模型说"行话"、严格遵循风格规范,或以极低容错处理敏感内容。通用模型常在窄域场景下吃力;**有监督微调(SFT)或直接偏好优化(DPO)**可将专业能力"固化"进模型。 - 语气与格式必须高度一致
若每次输出都要严格贴合模板(如财务披露、法律声明),微调能在无需复杂提示工程的情况下,稳定产出正确结构。 - 工具与 API 调用必须精确
当智能体频繁调用外部函数/服务(如医疗剂量、交易 API),函数调用能力的微调能显著减少误调用,并比纯提示更好地处理边界情况。 - 你有充足的高质量数据与预算
微调大模型需要成百上千条精炼样例、专家评审(用于强化式微调 RFT )以及 GPU 资源。若数据或算力不足,Reflexion、示例检索等非参数方法往往更具投入产出比。 - 可接受的重训频率
微调后的模型需要版本管理、重训节奏与兼容性检查。若领域变化频繁,维护成本可能抵消性能收益。
暂缓微调的情形:
- 处于快速原型期或低量使用
早期用非参数学习或提示工程即可零重训迭代。待用例与数据管线稳定后再决定是否微调。 - 基础模型演进可能"推翻"你的成果
商业 LLM 常推新底模。一次 GPT-5 的更新可能就超越你微调的 GPT-4,抵消数月投入。务必将微调投资与上游迭代速度权衡。 - 资源受限
若 GPU 稀缺、标注昂贵或推理时延是关键目标,可优先考虑 RAG 等非参数策略,以更低成本获得相近收益,并显著降低初始与持续维护负担。
简言之,仅当性能目标、数据可得性与运维能力三者匹配时再微调 ,并预先规划好随下一代底模到来时的重训或迁移路线 。还需注意,预训练 (从零在万亿级 token 上训练)仅适用于拥有海量算力与数据的大型实验室。对绝大多数团队而言,最佳路径是从高质量、开源且许可合规 的模型起步;很多开源模型已包含贴近任务的指令对齐 或后训练,往往能免去微调 ,或将其缩减为极小范围的定向更新。投入微调之前,先评估是否能通过提示工程、非参数学习或轻量适配 达到需求。拿不准时,就先别微调 ;通常有更低成本、杠杆更高的产品改进措施可优先推进。表 7-1总结了语言模型微调的主要方法。
表 7-1 语言模型微调的主要方法
| 方法 | 工作原理 | 最适用场景 |
|---|---|---|
| 有监督微调(SFT) | 提供(提示,理想回答)成对样例作为"真值",调用微调 API 调整权重 | 分类、结构化输出、修正指令跟随失败 |
| 视觉微调(Vision fine-tuning) | 提供图像-标注对进行监督训练,增强视觉理解与多模态指令跟随 | 图像分类、多模态鲁棒性 |
| 直接偏好优化(DPO) | 对同一提示给出"好/坏"成对响应并标记偏好,模型学习偏好高质量输出 | 摘要取向、语气/文风控制 |
| 强化式微调(RFT) | 生成候选输出,由专家打分;用类似策略梯度的更新强化高分"思维链" | 复杂推理、法律/医疗等高风险领域 |
微调提供四个主要"调节杆"以适配你的需求:
- SFT:用精选(Prompt, Response)对示范期望行为,适合分类、结构化输出或修复指令跟随缺陷。
- 视觉微调:引入图像标注对,强化多模态理解与视觉输入的可靠处理。
- DPO:基于成对"好 vs 坏"回答学习偏好高质量输出,尤其适合调语气、风格与摘要侧重点。
- RFT:依赖专家评分与策略梯度式更新,强化复杂推理链,适用于法律分析、医疗决策等高要求场景。
大型基础模型善于吸收海量通识,但其真正威力在于面向领域数据的定制化微调 。例如,面向财务文档 的 GPT-5 不仅能准确解析术语,还能遵循你的报告规范;面向法律 的模型可在合适语气下提炼判例要点;客服场景 的微调可确保每条回复严格遵守企业准则。模型内部表征与真实业务语境的紧密对齐,使微调在关键任务中不可或缺。
话虽如此,微调大型模型也意味着可观的资源消耗:数十亿参数 对应重算力需求、长训练时长与不菲云成本。随着数据演化或为纠偏而重训,开销还会叠加;实时部署中,推理时延也可能上升。缺乏专门 ML 基建的团队,往往难以承受这些门槛。
同样重要的是高质量、任务专属的训练数据 。只有在见到足够多、具代表性的样本后,大模型才会真正"变得更懂你的领域"------通常需要上千级别样本。策划、标注与验证这些数据既耗时,又易在流程不严谨时引入偏差。若缺乏严格的数据治理与稳健的留出集测试,就可能把模型过拟合到陈旧或失真的样本上,损害泛化与公平。
尽管存在挑战,微调大型模型仍是强有力的路径------尤其当高性能是硬性目标 且你具备支撑这类模型的资源时。大型模型在针对性微调后,常能在特定任务上超越小模型 ,适用于医疗诊断、法律分析、复杂技术支持等对准确性、理解深度与语言细腻度要求极高的应用。
需要强调的是,微调 是一个庞大而复杂的领域,包含众多技术、架构与权衡。本节并非面面俱到,而是通过务实示例帮助你判断:是否值得在你的项目里对微调做更深入的投资。若这些方法与目标契合,社区中有大量优质资源、论文与开源工具可继续深入学习微调策略、可扩展优化与生产部署。
总之,大型基础模型为高准确度、强适应性与细腻理解 的应用提供了强劲方案。通过微调,开发者能在保留广泛预训练知识的同时,将性能优化到具体任务或领域 。尽管算力与数据要求不低,但在追求峰值表现与稳健理解 的应用中,这一投入往往物有所值------不过,它只建议用于少量关键用例。
小模型的潜力(The Promise of Small Models)
与大型基础模型相对,小模型 更节省资源,适合算力受限或响应时延敏感的场景。虽然其参数量更小、架构更简洁,但在针对性微调 后,小模型在特定任务上依然惊人有效。其简洁性带来更快的适配速度,也利于对不同训练配置进行快速试验。对于部署大型复杂模型成本高、不切实际或超出任务需求的情境,小模型尤为合适。
小模型的精简架构还带来透明性与可解释性 优势:层数与参数更少,更便于分析其决策过程与影响因素。在强调可解释性的应用(金融、医疗与合规监管等)中,这一点尤为重要------相关方需要清楚理解决策缘由。比如,面向医学影像分类 的小模型更容易调试与验证,从而让专业人士对其预测更有信心。在高风险应用中,可解释性提升了问责与信任。
小模型也有利于敏捷(Agile)开发:结构轻量、迭代更快,更利于快速获得洞见与调整。对处于敏捷环境或缺少高性能算力的团队,小模型提供了灵活、快速响应的方案。它们适合持续/增量学习 的任务,需要频繁用新数据更新以保持相关性;同时,它们可高效部署到实时系统(边缘设备、移动端、物联网),满足低时延要求,且不牺牲系统整体响应性。
另一个关键优势是可及性 ------包括成本与可获得性。许多表现出色的小模型开源且免费 (如 Llama、Phi 等),可按需改造,降低了对预算与基础设施的门槛。小模型让更多团队能在不承担高昂运维成本的前提下试验、创新与落地,推动更包容的 AI 生态。
在窄域、明确边界 的任务上,经微调的小模型可取得可与大模型比肩 的效果。比如,面向财报情感分析 的小模型,因专注识别该领域的特征模式,就可能达到很高准确度。此类任务容量明确、边界清晰,小模型能把有限容量集中到最相关的子空间,从而匹配甚至超越 大模型表现。对于高准确度要求但数据有限的应用,小模型尤具价值:既能定制有效,又不易过拟合。
此外,小模型更可持续 。训练与部署大模型消耗大量能源与算力,带来环境影响;小模型的训练与推理能耗显著更低,更适合关注资源消耗与绿色 AI的组织。
当需要高频更新或重训 时,小模型也优势明显。比如,社媒情感、实时风控、个性化推荐等数据分布快速变化的场景,小模型可以快速用新数据微调 以适应新模式,且重训成本低。它们也适合联邦学习 :在需隐私保护的分布式数据源上,模型可在边缘设备进行高效微调,支持端侧隐私友好方案。
小模型微调 是快速演进的领域------架构、规模与能力持续迭代,能以远低于大模型的算力与成本达到近 SOTA 表现。行业基准与榜单(如 Stanford HELM、Papers with Code、Hugging Face Evaluation、BigBench Leaderboard 等)不断刷新结果与对比。由于迭代极快,"今天最佳"的小模型家族(如 Llama 3、Qwen2.5 Turbo、DeepSeek 等)可能很快被新秀超越。为保持前沿,实践者应结合延迟/硬件/预算 等部署约束与任务需求,定期参考权威榜单选择合适的模型:
- <8B 参数:端侧/低成本推理的首选;
- 8B--70B:通用推理的"甜 spot";
- 70B+ 及商业巨型模型:高风险高精度场景仍占优。
通过周期性评估与榜单跟进,你可以在快速更迭中为智能体应用挑选最合适的小模型家族,同时充分认识到:等你读完本章,新的冠军或许已经出现了。
有监督微调(Supervised Fine-Tuning)
在参数化方法中,有监督微调(SFT)仍是奠基性技术,它通过精心策划的输入/输出示例精确塑造模型行为。SFT 的核心是:用明确示例教会智能体应当如何响应,从而精确地"驾驶"其行为。一个强力用例是教会智能体何时以及如何调用外部 API ------将函数调用 微调到不仅能正确构造调用格式,还能判断是否需要调用。这比标准托管式的 function calling 能提供更强的可控性与一致性,尤其在仅靠提示工程不够时。
尽管现成基础模型在生成函数调用方面持续进步,你仍可能遇到一些"顽固"场景:提示词愈发臃肿、参数屡被误解析,或准确率达不到严格的行业标准。此时(尤其是在高流量、每 1% 可靠性都很关键的业务里),用精选样例进行微调,往往既能提升性能 ,又能随着时间推移在每次调用成本 上优于高 token 开销的商用端点。简而言之,SFT 通过精心整理的 (prompt, response) 成对样例,让模型学习期望的输出风格、结构或行为 。同样的技术既可让智能体保持一致语气 与结构化输出 ,也可------如本例所示------实现精确的工具使用 。参见图 7-6。
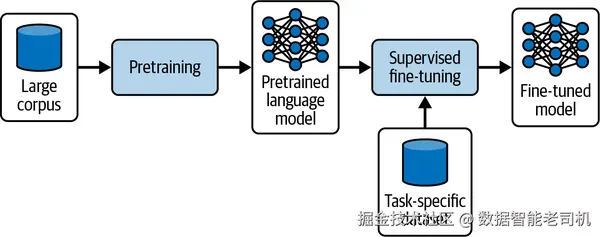
**图 7-6 SFT 工作流。**基础模型先在广泛语料上预训练获得通用能力,随后使用任务特定的有监督数据集进一步微调,使其适配专业应用。
为让函数调用 更稳健,通常需要为每个暴露的 API 明确定义模式(schema) ------函数名、有效参数、类型与返回格式。这样你的样例就能明确地"教授"模型必须遵守的契约。做法是:构建一套与真实 API schema 一致 的微调数据集(函数名、参数类型、返回格式齐备),促使模型内化你的工具契约。结果是模型不仅一次成型 地生成正确调用,还能在上下文中判断是否应该调用。
由于该方法需要额外的数据策划、算力与维护,建议先 用基础模型的内置 function calling 与运行时 schema 校验;只有当确认提示工程与标准 API 不足以满足需求时,再考虑这类更"重"的投入------理想情况下是在规模与精度要求足以支撑前期成本时。
具体做法是向模型呈现结构化示例:智能体需要决定是否调用函数 、准确填参 ,并妥善包装 结果。比如,用户问 "What's the weather in Boston?",一个调教良好的智能体应调用 get_weather(location="Boston"),再把结果融入回复;但若用户说 "Imagine it's snowing in Boston---what should I wear?",智能体应进行假设性推理 ,而不是触发真实调用。此类情境判断 通过定向样例来学习。
为确保微调后的智能体只产生结构良好且安全 的函数调用,必须为每个 API/工具定义并执行清晰的 schema。将函数名、参数类型与返回结构以机器可读 的方式编纂(如 JSON Schema 或 TypeScript/Zod ),即可为模型提供精确"契约"。在微调中,把这些 schema 与示例一并提供 ,使模型不仅知道"调用什么",还知道如何组织 JSON 负载 。在运行时,使用 Zod、Ajv 或 Pydantic 按同一 schema 校验每个拟调用;任何不匹配都能被及早拦截并更正/拒绝,防止畸形或恶意请求。端到端的 schema 纪律能显著降低错误率 、简化调试,并让系统更耐受异常输入。
微调还可帮助模型学会把用户输入解析为有效参数 、从缺参 等错误中恢复,并在调用失败时优雅降级 。使用特殊标记与格式(如用 <think>...</think> 包裹内部推理、用 <tool_call>...</tool_call> 包裹外部调用)能帮助模型区分对话、思考与行动。
下面给出一个最小可用 范式:结合 LoRA(低秩适配) 对函数调用 进行 SFT。流程包含:将对话预处理为统一模版、为 <think>/<tool_call> 段落附加特殊 token、用 LoRA 只适配目标层,并用 SFTTrainer 在你的(prompt, response)正确样例上训练。
数据预处理(结构化对话,生成可训练文本):
python
def build_preprocess_fn(tokenizer):
"""Returns a function that maps raw samples to tokenized prompts."""
def _preprocess(sample):
messages = sample["messages"].copy()
_merge_system_into_first_user(messages)
prompt = tokenizer.apply_chat_template(messages, tokenize=False)
return {"text": prompt}
return _preprocess分隔"思考/调用"与常规对话(附加特殊 token 与 chat 模版):
ini
def build_tokenizer(model_name: str):
tokenizer = AutoTokenizer.from_pretrained(
model_name,
pad_token=ChatmlSpecialTokens.pad_token.value,
additional_special_tokens=ChatmlSpecialTokens.list(),
)
tokenizer.chat_template = CHAT_TEMPLATE
return tokenizer
def build_model(model_name: str, tokenizer, load_4bit: bool = False):
kwargs = {
"attn_implementation": "eager",
"device_map": "auto",
}
kwargs["quantization_config"] = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(model_name, **kwargs)
model.resize_token_embeddings(len(tokenizer))
return model加载/切分数据并用 TRL 的 SFTTrainer 训练(结合 LoRA 提效) :
ini
def load_and_prepare_dataset(ds_name: str, tokenizer, max_train:
int, max_eval: int) -> DatasetDict:
"""Loads the dataset and applies preprocessing & train/test split."""
raw = load_dataset(ds_name).rename_column("conversations", "messages")
processed = raw.map(build_preprocess_fn(tokenizer),
remove_columns="messages")
split = processed["train"].train_test_split(test_size=0.1, seed=42)
split["train"] = split["train"].select(range(max_train))
split["test"] = split["test"].select(range(max_eval))
return split
def train(
model,
tokenizer,
dataset: DatasetDict,
peft_cfg: LoraConfig,
output_dir: str,
epochs: int = 1,
lr: float = 1e-4,
batch_size: int = 1,
grad_accum: int = 4,
max_seq_len: int = 1500,
):
train_args = SFTConfig(
output_dir=output_dir,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
gradient_accumulation_steps=grad_accum,
save_strategy="no",
eval_strategy="epoch",
logging_steps=5,
learning_rate=lr,
num_train_epochs=epochs,
max_grad_norm=1.0,
warmup_ratio=0.1,
lr_scheduler_type="cosine",
report_to=None,
bf16=True,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
packing=True,
max_seq_length=max_seq_len,
)
trainer = SFTTrainer(
model=model,
args=train_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
processing_class=tokenizer,
peft_config=peft_cfg,
)
trainer.train()
trainer.save_model()
return trainer当智能体依赖可靠的工具使用 (查日历、下命令、查数据库等)时,SFT 能把这类调用的稳健性提升到远超提示工程的水平:降低错误率、学会何时不该调用 ,并通过减少重试与畸形调用来节省 token 成本 。它也引入一层决策推理 :模型可以选择不调用工具。比如用户说 "If it rains tomorrow, I'll stay in",智能体应判断无需 API 调用,直接回复即可。
随着智能体承担更多职责------尤其在自动化与决策 场景------结构化函数调用成为值得微调的基础能力,这将显著改善用户体验与系统可靠性。
直接偏好优化(Direct Preference Optimization)
在 SFT 之上,DPO 引入偏好学习 ,使输出更贴近人类的质量排序判断。DPO 通过成对排序 训练模型更偏好"更好"的输出。不同于只让模型复现"金标准"答案的 SFT,DPO 让模型内化偏好判断 ,从而在推理时更善于挑选与排序 高质量补全。见图 7-7。
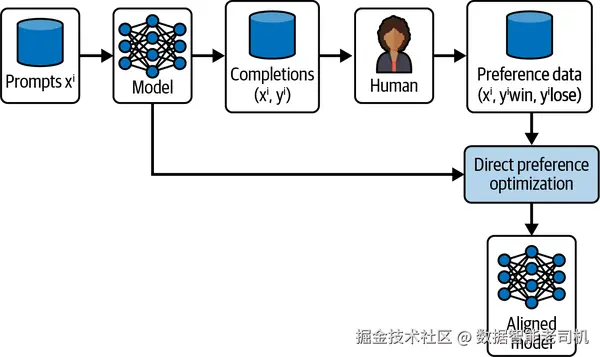
**图 7-7 DPO 工作流。**向模型喂入提示,生成多份补全;由人工评估产生偏好数据(y_win/y_lose)。训练过程中直接优化模型,使其更倾向被偏好的输出,得到与人类偏好更一致的模型。
下面是使用小型 Phi-3 模型微调服务台答复质量的最小示例(加载 LoRA、准备排序数据、用 DPOTrainer 训练):
ini
import torch, os
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments,
BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
from trl import DPOConfig, DPOTrainer
import logging
BASE_SFT_CKPT = "microsoft/Phi-3-mini-4k-instruct"
DPO_DATA = "training_data/dpo_it_help_desk_training_data.jsonl"
OUTPUT_DIR = "phi3-mini-helpdesk-dpo"
# 1️⃣ Model + tokenizer
tok = AutoTokenizer.from_pretrained(BASE_SFT_CKPT, padding_side="right",
trust_remote_code=True)
logger = logging.getLogger(__name__)
if not os.path.exists(BASE_SFT_CKPT):
logger.warning(f'''Local path not found; will
attempt to download {BASE_SFT_CKPT} from the Hub.''')
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
base = AutoModelForCausalLM.from_pretrained(
BASE_SFT_CKPT,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config
)
lora_cfg = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj",
"up_proj", "down_proj"],
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(base, lora_cfg)
print("✅ Phi-3 loaded:", model.config.hidden_size, "hidden dim")加载成对排序 数据(每条含 prompt、chosen、rejected):
ini
# Load DPO dataset with ranked pairs
# Each row should include: {"prompt": ..., "chosen": ..., "rejected": ...}
dataset = load_dataset("json",
data_files="training_data/dpo_it_help_desk_training_data.jsonl",
split="train")设定训练超参并配置 DPO(beta 控制偏好优化强度),然后训练与保存模型:
ini
# 4️⃣ Trainer
train_args = TrainingArguments(
output_dir = OUTPUT_DIR,
per_device_train_batch_size = 4,
gradient_accumulation_steps = 4,
learning_rate = 5e-6,
num_train_epochs= 3,
logging_steps = 10,
save_strategy = "epoch",
bf16 = True,
report_to = None,
)
dpo_args = DPOConfig(
output_dir = "phi3-mini-helpdesk-dpo",
per_device_train_batch_size = 4,
gradient_accumulation_steps = 4,
learning_rate = 5e-6,
num_train_epochs = 3.0,
bf16 = True,
logging_steps = 10,
save_strategy = "epoch",
report_to = None,
beta = 0.1,
loss_type = "sigmoid",
label_smoothing = 0.0,
max_prompt_length = 4096,
max_completion_length = 4096,
max_length = 8192,
padding_value = tok.pad_token_id,
label_pad_token_id = tok.pad_token_id,
truncation_mode = "keep_end",
generate_during_eval = False,
disable_dropout = False,
reference_free = True,
model_init_kwargs = None,
ref_model_init_kwargs = None,
)
trainer = DPOTrainer(
model,
ref_model=None,
args=dpo_args,
train_dataset=ds,
)
trainer.train()
trainer.save_model()
tok.save_pretrained(OUTPUT_DIR)概括来说,上述脚本:加载带 LoRA 适配的 Phi-3 基座,准备偏好排序样例 ,并用 DPOTrainer 进行微调。训练后,模型能比单纯 SFT 更稳定地输出与既定偏好一致的高质量结果。
当你的首要目标是塑形输出质量 而非仅复现示例时,DPO 尤其有用。它为 SFT 补上"偏好学习 "一环,帮助智能体产出不仅正确、且更贴合细腻的人类期望的答案。
具可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)
在基于偏好的微调之上,具可验证奖励的强化学习(RLVR)进一步引入了针对显式、可度量奖励函数的策略优化 。
与仅基于偏好的方法不同,RLVR 允许你接入几乎任意可构建的"打分器"------自动化指标、基于规则的校验器、外部评分模型,或人工评审------并直接朝这些奖励优化模型 。只要你能定义可验证的评估信号,几乎任何任务都能实现可规模化、定向的改进:无论是优化摘要质量、工具调用的正确性、检索事实的可信度,还是遵循安全约束,RLVR 都能把静态的偏好学习扩展为通用、可扩展的强化学习框架。
不同于直接优化成对偏好的 DPO ,RLVR 将偏好学习与强化学习 结合:模型不仅从观察到的排序中学习,还通过价值预测(value prediction)来泛化 并据此优化输出。图 7-8 展示了 RLVR 的工作流:模型从带评分的补全中学习,迭代提升目标任务上的表现,随后依据学得的策略更新,产出能最大化预测质量与效用的结果。
为便于阅读,这里不包含 RLVR 的完整代码实现;如需在实践中落地,可在配套仓库中查阅。
RLVR 的优势包括:可灵活 面向任意可度量信号进行优化;通过价值预测 超越已观测示例实现更强泛化 ;并且非常适合具备自动化评分 或可规模化人工评估 的任务。当你拥有偏好排序数据,或能构建可靠的输出评分函数 时,RLVR 尤其有效。它也非常适用于需要持续质量改进 的场景,特别是在奖励稀疏 或直接大规模人工标注过于昂贵的情况下。
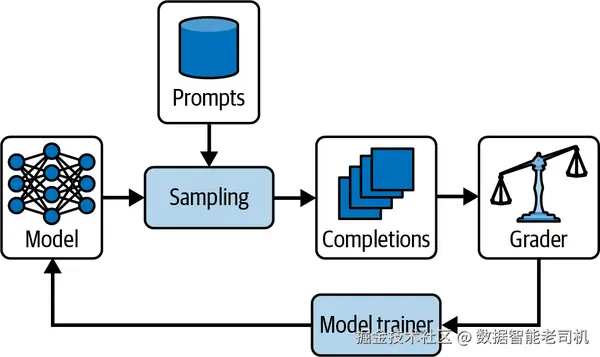
**图 7-8 具可验证奖励的强化式微调。**对提示进行采样以生成多份补全,由自动或人工"打分器"进行评估;这些奖励被送入训练器以更新策略,模型据此提升后续输出的质量。
总之,RLVR 通过把偏好学习 与基于价值的策略优化 结合,拓展了强化式微调(RFT)的可能性。模型不仅能模仿 偏好输出,更能预测并优化 对用户最有用、最准确或最契合 的结果------为自我改进、任务专精的基础模型铺平道路。
结语(Conclusion)
智能体系统中的学习涵盖多种路径,每种都为提升性能与适应性 提供了独特优势。非参数学习 强调在不改动模型参数 的前提下,从经验中动态学习 :它简单、快速、贴近实用场景。与之相对,参数学习 直接微调模型权重以实现更深的领域化 :既包括用于结构化输出与函数调用 的有监督微调(SFT) ,也包括按细腻的人类偏好 塑形输出质量的直接偏好优化(DPO) 。
将两者结合,能形成一套强大的工具箱:以非参数的敏捷性 应对变化,以参数化的定向适配 冲刺上限。开发者据此可以打造智能、稳健 的智能体,使其随任务与环境演进而进化------同时确保对"学习"的每一分投入,都与运营约束 与性能目标相匹配。