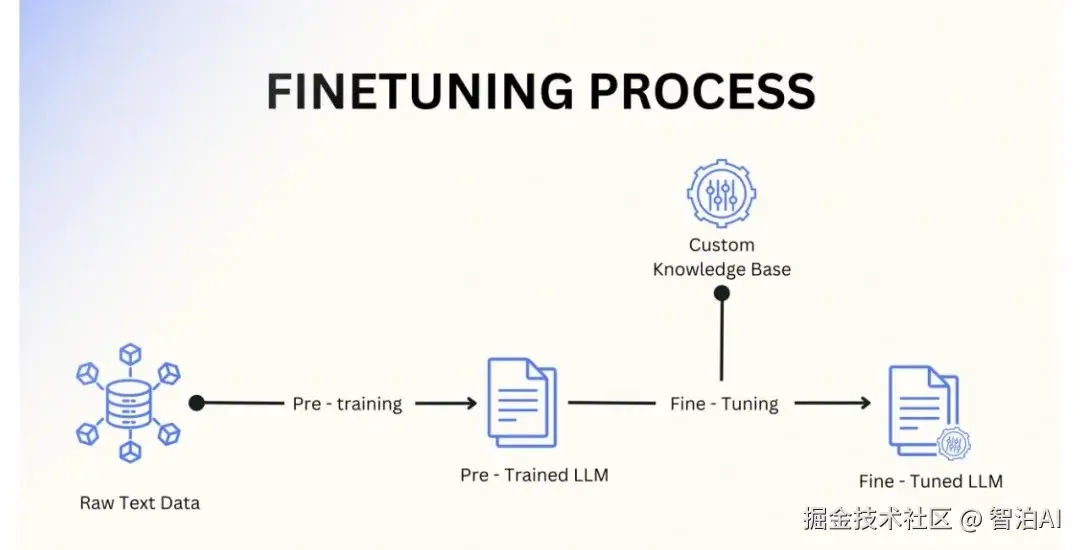
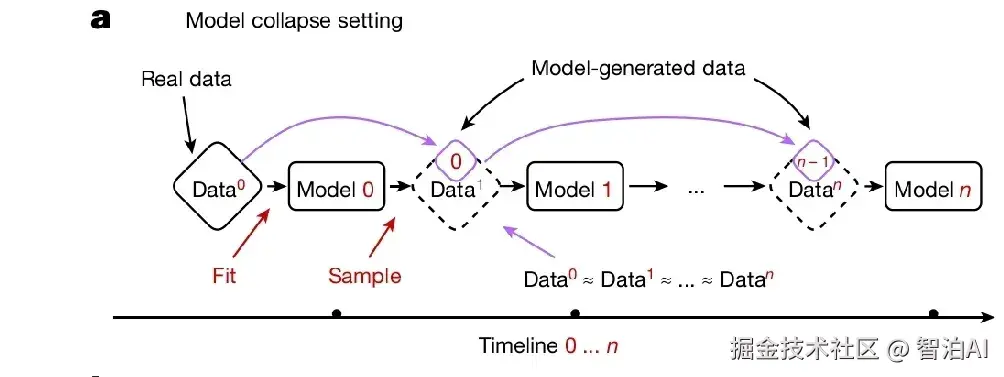
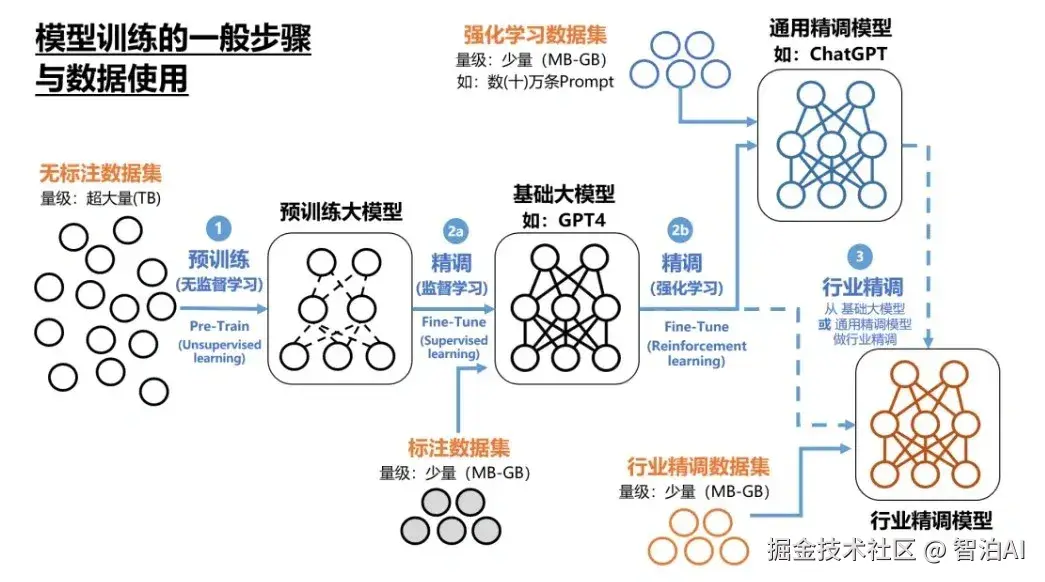
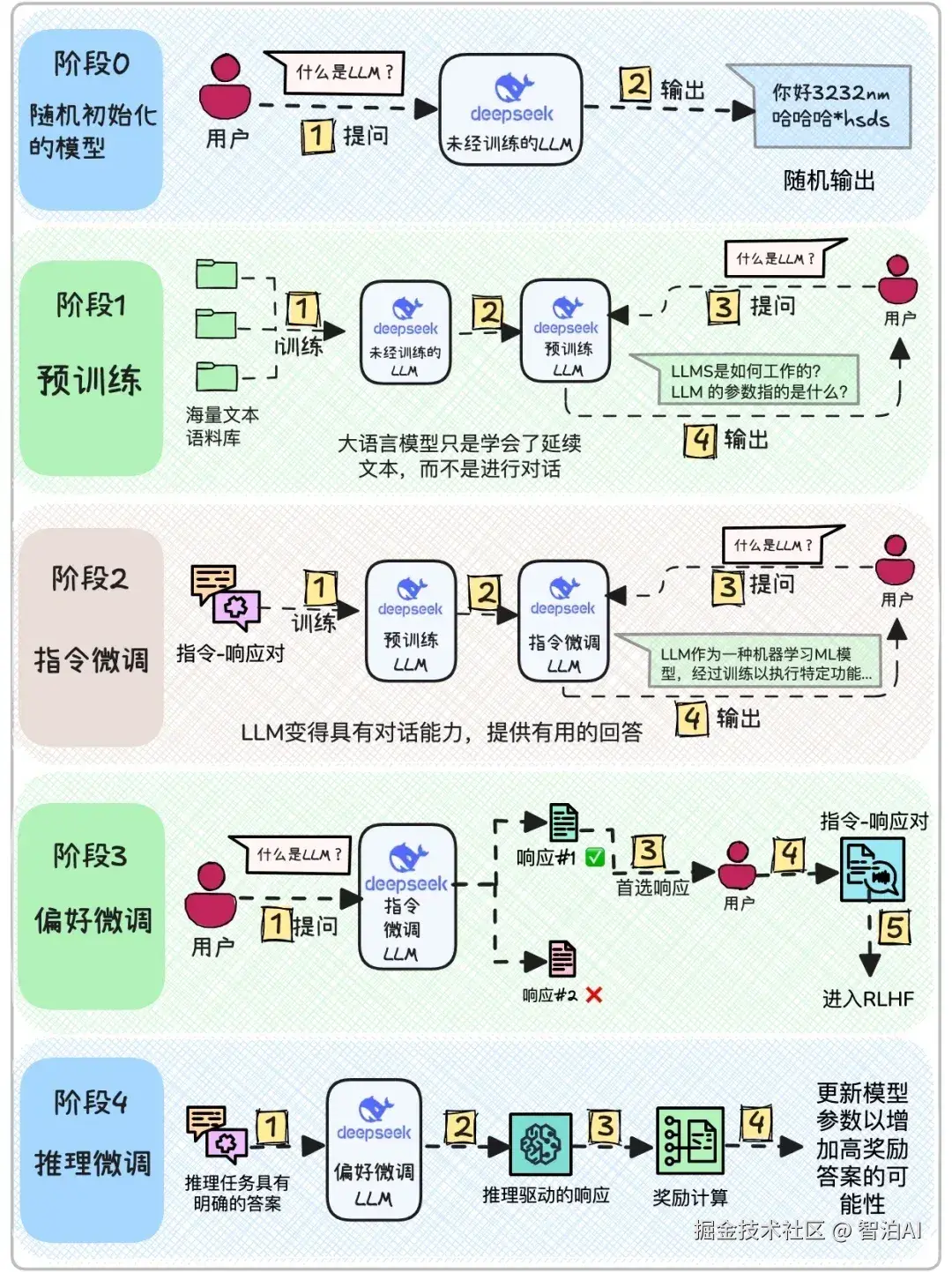
大模型训练过程: 准备 训练 测试 调优 实践
1.准备阶段
在准备阶段,主要工作集中在数据收集、数据清洗以及模型设计上。
数据收集:
收集大量的文本数据作为训练材料。这些数据可以来自互联网、图书、新闻、社交媒体等多种来源。数据量通常非常庞大,以确保模型能够学习到足够丰富的语言模式。
数据清洗:
清洗数据是为了去除噪声和无关信息,提高数据质量。
具体操作包括去除重复数据、过滤掉非文本内容(如HTML标签)、纠正拼写错误等。可能还需要进行一些预处理,例如分词、标记化等,以便模型能够更好地理解和处理文本。
模型设计:
确定模型的架构,例如选择使用Transformer架构,决定使用多少层、每层的宽度等。设计损失函数,定义评估标准。决定初始化参数的方式以及优化器的选择。
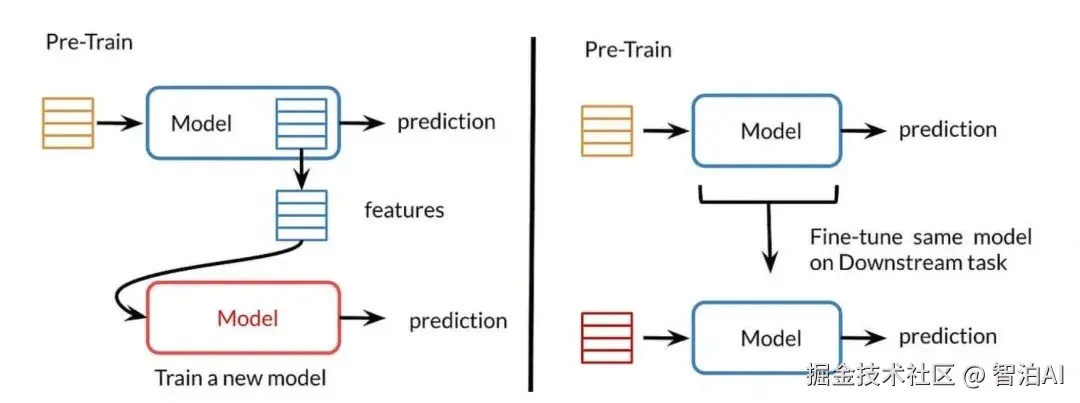
2.训练阶段
训练阶段是构建大型语言模型的核心部分,在这个阶段模型会根据给定的数据集不断调整自身参数。
初始化:
使用随机或特定策略初始化模型参数。设置超参数,比如学习率、批次大小等。
前向传播:
将数据送入模型进行前向传播,得到预测输出。比较预测输出与实际标签之间的差异,计算损失值。
反向传播:
利用损失值对模型参数进行梯度计算。使用优化算法(如Adam、SGD等)更新模型参数。
迭代训练:
在整个数据集上进行多轮训练(称为epoch),直到满足停止条件为止。
停止条件可能是达到预定的epoch数、验证集上的性能不再提升等。
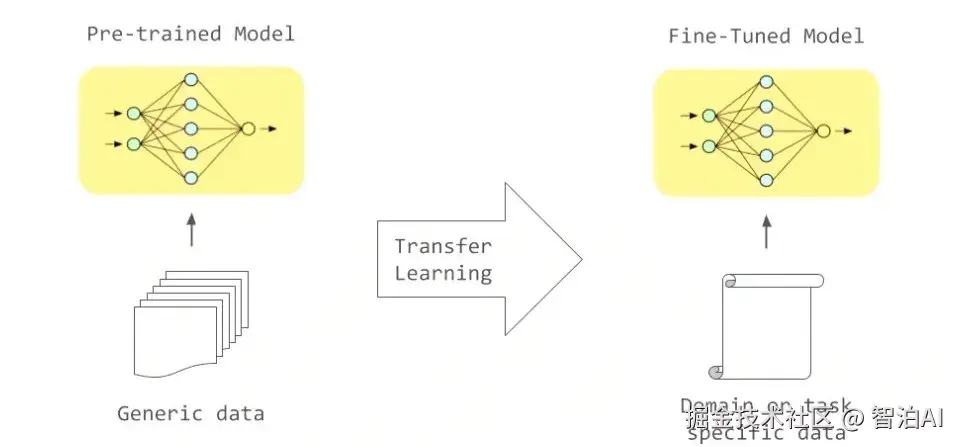
3.测试阶段
测试阶段用于评估模型的性能,确保模型在未见过的数据上有良好的表现。
选择测试集:
从原始数据集中划分一部分作为独立的测试集,通常这部分数据不参与训练过程。
测试集应该具有代表性,包含各种类型的样本。
评估指标:
选择合适的评估指标来衡量模型的性能,常见的有准确率、BLEU分数、困惑度等。
对于不同的应用场景,可能还需要考虑其他的评价标准。
性能分析:
分析模型在测试集上的表现,识别可能存在的问题点,比如过拟合、欠拟合等。
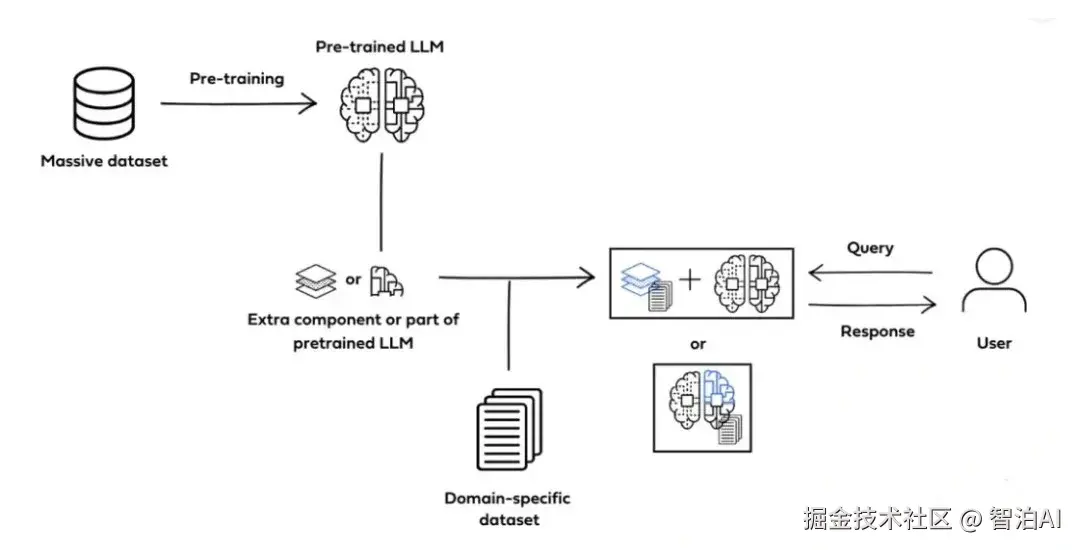
4.调优阶段
调优阶段是根据测试结果进一步改进模型的过程。
超参数调整:
调整学习率、批量大小、正则化系数等超参数。可以采用网格搜索、随机搜索或贝叶斯优化等方法寻找最优组合。
模型结构优化:
考虑增加或减少模型的层数、改变隐藏层的维度等。
引入新的组件或技术,比如注意力机制、残差连接等。
数据增强:
使用数据增强技术来扩大训练集的多样性,提高模型的泛化能力。
持续监控:
监控模型在新数据上的表现,必要时继续调整。
5.实践阶段
在模型经过充分的训练和调优之后,就可以将其部署到实际应用中了。
部署模型:
将训练好的模型部署到服务器上,供外部应用调用。
保证模型能够高效运行,考虑使用模型压缩、量化等技术减少资源消耗。
监控与维护:
实施实时监控,确保模型在生产环境中的稳定运行。
定期收集反馈,根据用户的使用情况对模型进行更新和优化。
应用场景扩展:
探索模型在更多场景下的应用可能性,比如文本生成、对话系统、情感分析等。
不断挖掘模型的潜力,拓展其功能和服务范围。
用户反馈:
收集用户反馈,了解模型的实际效果及存在的不足之处。
结语
大型语言模型的训练是一个持续迭代的过程,每个阶段都需要仔细规划和执行。
随着技术的进步,模型的训练方法也会不断发展和完善。
通过以上五个阶段的详细说明,希望能够帮助您更好地理解大型语言模型的训练流程,并为自己的项目提供有益的参考。