LISA++: An Improved Baseline for Reasoning Segmentation with Large Language Model
摘要
LISA模型的缺点:
- 无法区分目标区域的不同实例
- 并且受限于预定义的文本响应格式。
LISA++对LISA的改进:
- 增强的分割能力: 增加了实例分割能力,在现有的多区域语义分割之外,提供了更细致的场景分析。
- 更自然的对话: 提升了多轮对话能力,能够将分割结果直接融入文本响应中,即"对话中的分割"(SiD)。
本文贡献:
架构不变,数据驱动: 这是最关键的一点。LISA++没有改动LISA的模型架构,而是通过重构指令调优数据来实现升级,表明对于大语言模型驱动的多模态模型而言,高质量、精心设计的训练数据(指令数据)是激发和塑造模型能力的关键。
3.1 An Improved Baseline
相较于LISA有两点改进
- 增强了推理实例分割能力
- 更灵活和自然的文本响应,具有对话分割(SiD)的能力。
实现一:
为了增强推理实例分割能力,利用带有实例分割注释的数据集作为指令调优的基础。具体来说,这些注释被合并到GPT-4V的提示中,使其能够生成反映注释中详细信息的深刻问题,具体如下:
方法的核心是利用已有的、带有实例标注的数据集(如 COCO)。这体现了工作的效率,无需从头标注数据。
关键创新 - 利用 GPT-4V 生成高质量指令数据
- 输入: 将一张图片和其实例级别的标注(即每个物体都有唯一 ID 的掩码)作为输入。
- 过程: 将这些信息精心设计成提示词,输入给强大的多模态大模型 GPT-4V。
- 输出: GPT-4V 根据这些详细的标注,自动生成与之对应的、描述复杂的自然语言问题
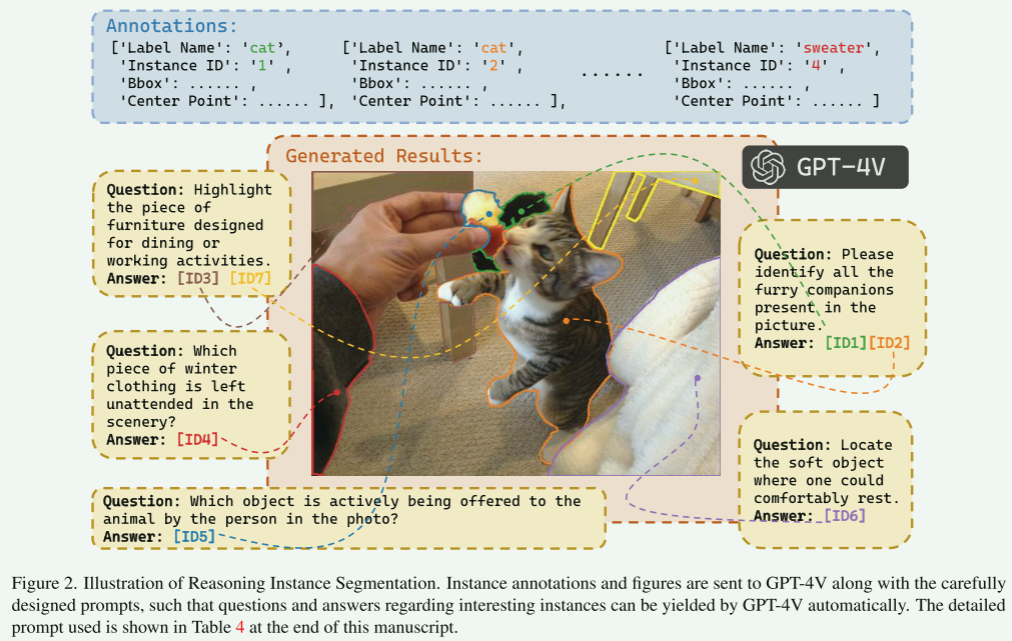
实现二:构建高质量的数据
利用分割标注(无论是实例分割与否),促使分割结果(表示为<SEG>)能够在对话中上下文合适的节点无缝融入 ,而不是将其限制在响应中一个预先确定的、静态的位置,主要有问答对话数据 和字幕对话数据两种,分别通过下面的提示词来生成训练数据
markdown
messages = [{
"role": "system",
"content": "你被要求生成**问答对话数据**。要求如下:(1) 构建一个通过自然且多样的问题和答案来生动描绘场景的对话,确保其逻辑性和吸引力。(2) 对话上下文应具有关联性。应包含涵盖物体识别、计数、动作、位置、物体间关系的交互,同时还需整合复杂的、探究物体背景信息和图像所描绘场景的查询。(3) 精心设计问题以避免歧义,并确保能基于图像标注自信地回答。避免在<人物>的提问中包含'<实例ID;标签名>'。不要在问答中直接提及'多边形'或'标注'。(4) 输出格式为:'<人物>: XXXX <机器人>: XXXX',其中<机器人>的回应需包含实例ID和标签名,例如'键盘 <34494; keyboard> <31264; keyboard>'。"
}]
markdown
messages = [{
"role": "system",
"content": "你被要求生成**字幕对话数据**。请基于提供的图像(图像尺寸:{image_size})及其实例分割标注生成一个问答对。重点是根据标注中给出的实例,尽可能详细地描述(说明)整个图像,除了实例ID外,不要直接引用标注中的任何其他信息。确保答案指明了所涉及的具体实例。标注由结构体{'标签名', '实例ID', '边界框', '中心点'}组成,每个结构体对应图像中的一个唯一实例(分割掩码以边界框[左, 上, 右, 下]的形式给出,'中心点'是实例的中心)。x坐标从左到右递增。y坐标从上到下递增!实例越靠近上边缘,其y坐标值越小。请假设你处于一个空间,其中点1[0,0]位于点2[1,1]的左上,点2[1,1]位于点1[0,0]的右下。起点[0,0]位于给定图像的左上角。生成的问答应遵循以下格式:'Q1: <问题>. A1: <描述>'"
}]实现三:统一多种任务模式,使得语义分割(SemSeg)和实例分割(InstSeg)兼容
- 使得语义分割(SemSeg)和实例分割(InstSeg)兼容
由于LISA++执行实例分割,与处理多区域响应类似,会生成多个<SEG>标记,与LISA中不同的<SEG>标记代表不同类别 ,在LISA++中,<SEG>还可以代表同一类别中的不同个体 。在训练过程中,我们采用了二分图匹配方法,来为每个预测出的实例掩码寻找对应的真实标签。
- 转换为语义分割数据: 将同一类别的多个实例掩码合并成一个。
- 转换为纯对话数据: 直接移除答案中的
<SEG>标记。
- 统一多种任务模式:
- 只要分割不要对话
- 既要分割也要对话
- 区分实例
- 不要区分实例
解决方案:

将任务指令显式化、模板化,并作为提示词的一部分直接提供给模型
在实际使用时,系统会将用户的自然语言问题(如:"图片里有什么动物?")与表1中对应的任务模板(如:用于"SiD with SemSeg"的模板)拼接在一起,再输入给LISA++模型。模型通过阅读这个完整的提示词,就能清晰地理解用户的意图和所期望的输出格式。
3.2. Instance-level Evaluation for ReasonSeg
LISA文中的ReasonSeg基准评估在图像中精确定位目标区域的能力,以响应复杂的文本查询。然而,因为它只考虑每个图像查询对的单个目标区域,不适合评估实例分割,故构建了ReasonSeg-Inst数据集,该子集专门用于评估模型在实例识别方面的熟练程度。ReasonSeg-Inst数据集来自COCO和ADE20K数据库的样本。其中因为COCO和ADE20K中的低分辨率图像或微小对象实例可能会妨碍GPT-4V生成令人满意的指令调优数据的能力。故对其进行筛选。