
论文标题:VideoOrion: Tokenizing Object Dynamics in Videos
作者团队:Yicheng Feng, Yijiang Li, Wanpeng Zhang, Hao Luo,Zihao Yue, Sipeng Zheng, Zongqing Lu
作者机构:北京大学、加州大学圣地亚哥分校、中国人民大学、BeingBeyond
论文地址:https://arxiv.org/abs/2411.16156
前言
来自北京大学和加州大学圣地亚哥分校等机构的研究者们提出了一个名为VideoOrion的新型视频大语言模型(Video-LLM)。
我们知道,现在的大模型看懂图片已经不是什么难事了,但要真正理解视频,尤其是视频里各种物体是怎么动的、互相之间有什么交互,其实还挺难的。目前的很多模型为了计算效率,不得不丢掉视频中的大量信息,导致理解得比较"粗糙"。
而VideoOrion这个工作,就像是给大模型装上了一双"火眼金睛",专门用来"盯"住视频里的每一个重要物体。它的核心思想,就是把对整个视频的"全局理解"和对特定物体的"焦点关注"结合起来。
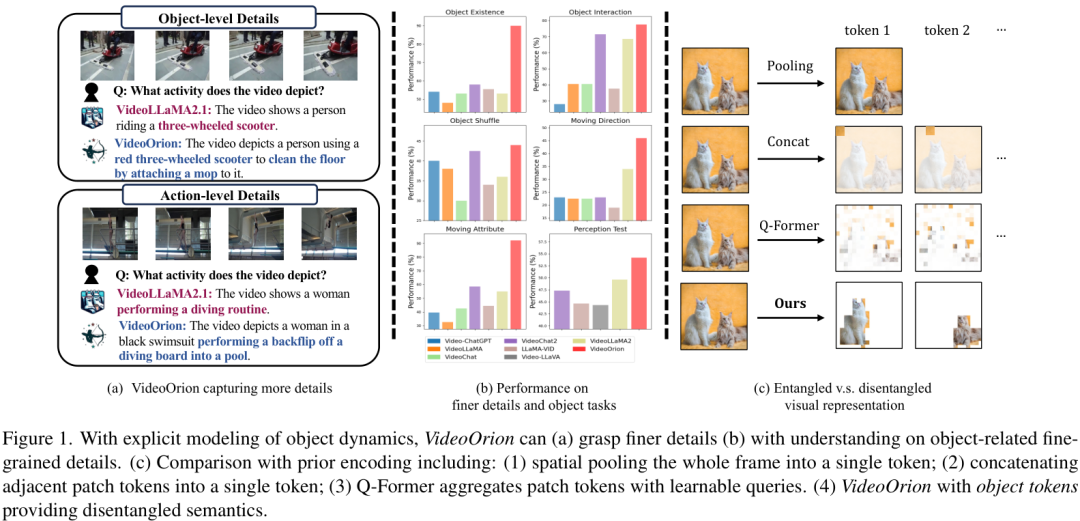
从上图的对比中我们能直观地看到,相较于之前的其他方法,VideoOrion能够捕捉到更精细的细节。
VideoOrion的核心架构
为了实现这种"全局"与"焦点"的结合,VideoOrion设计了一个非常巧妙的双分支架构。
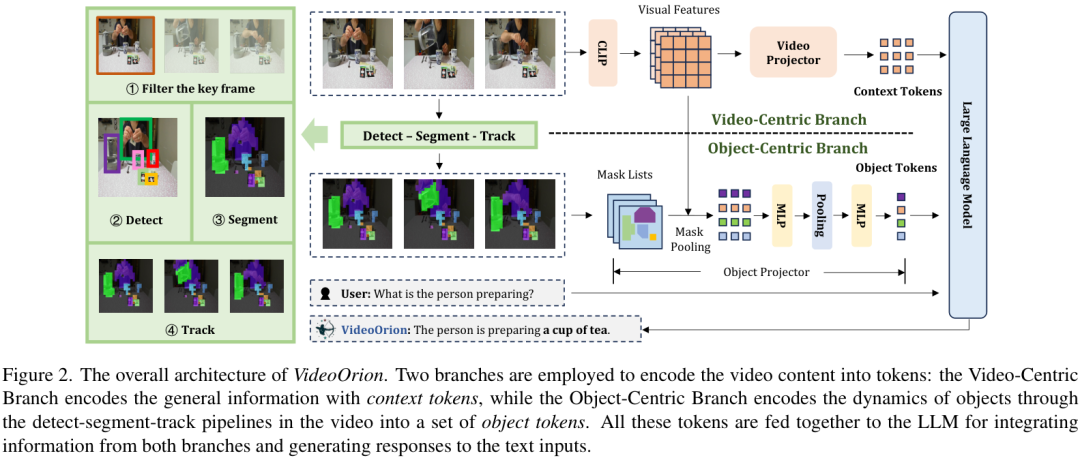
如上图所示,这个架构主要包含两个部分:
-
视频为中心的分支 (Video-Centric Branch) :这个分支负责"看全局",它会处理视频的整体信息,比如背景、场景氛围等,生成"上下文Token",给大模型一个关于视频的整体印象。
-
物体为中心的分支 (Object-Centric Branch) :这是VideoOrion的秘密武器。这个分支会动用一套"检测-分割-追踪"的流水线,把视频里一个个的物体给识别出来,并且追踪它们在整个视频里的运动轨迹。然后,它会把每个物体的时空动态信息压缩成专属的"物体Token"。
最后,这两类Token------代表全局上下文的"上下文Token"和代表每个物体动态的"物体Token"------会被一起喂给大语言模型。这样一来,LLM就能同时"看到"视频的整体画面和其中每个物体的具体行为,从而做出更精准、更深入的理解和回答。
这个设计的输入是视频,输出则是对视频内容的文本描述或问答。CV君觉得,这种解耦的设计非常高明,它让模型既不会丢失宏观信息,又能精准捕捉微观动态,解决了以往模型"看得见"但"看不清"的痛点。
方法细节
为了让"物体为中心的分支"能高效工作,作者采用了一套成熟的"检测-分割-追踪"流程。

具体来说,模型会先用像GroundingDINO这样的通用检测器来找到视频关键帧中的物体,然后用SAM(Segment Anything Model)进行精确分割,得到物体的轮廓(Mask)。最后,通过XMem这样的多物体追踪算法,把这些物体在不同帧之间的身份关联起来,形成完整的运动轨迹。

整个训练过程分为三个阶段:首先是视频为中心分支的预训练,然后是物体为中心分支的预训练,最后是在多种指令数据上进行多模态指令微调。这样的分步训练策略,保证了模型各个模块都能得到充分的学习。
实验效果怎么样?
VideoOrion在多个视频理解基准测试中都取得了非常亮眼的成绩。
主流Benchmark性能对比
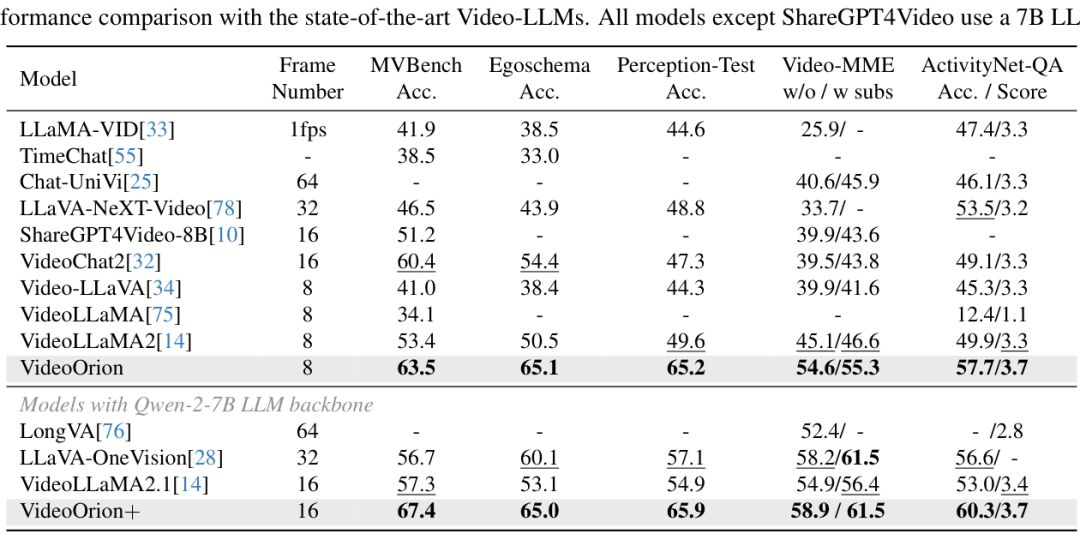
在上表中,作者将VideoOrion与当前最先进的(SOTA)Video-LLM进行了比较。结果显示,VideoOrion在MVBench、EgoSchema、Perception-Test等多个主流Benchmark上都取得了具有竞争力的性能,一致性地超越了次优方法。特别地,与拥有相同视频为中心分支的基线模型VideoLLaMA2相比,VideoOrion在各项指标上平均提升了超过10%,这充分证明了"物体为中心"分支的有效性。
视频指代任务 (Video Referring Task) 表现
由于引入了显式的物体Token,VideoOrion天然就擅长处理需要"指代"视频中特定物体的任务。
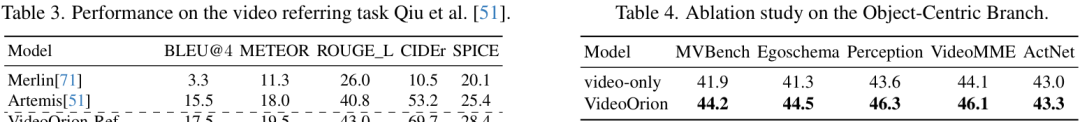
实验结果表明,无论是零样本(zero-shot)设置还是经过微调,VideoOrion在视频指代任务上的表现都远超此前的专用模型Artemis和Merlin,这说明物体Token确实能让模型精准地"理解"我们到底在问哪个物体。
消融实验
为了进一步验证各个模块的有效性,作者还进行了一系列消融研究。

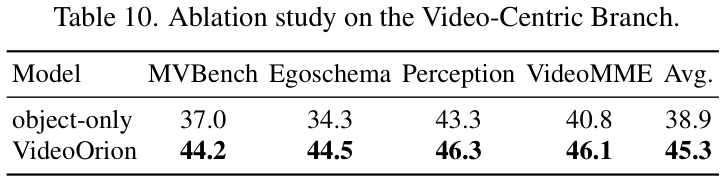
上表对比了仅使用视频分支(video-only)和完整VideoOrion模型的性能。结果很明显,加入了物体为中心分支后,模型在所有测试集上的性能都有了一致的提升。
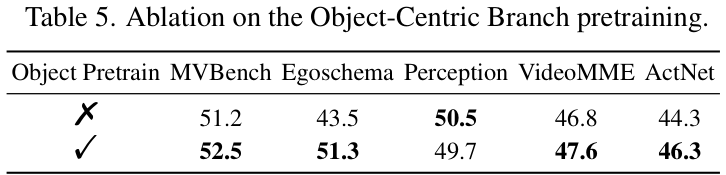
同时,对物体分支进行预训练也至关重要。与随机初始化的物体分支相比,经过预训练的分支能带来显著的性能改善,证明了预训练对于学习有效的物体表示是必不可少的。
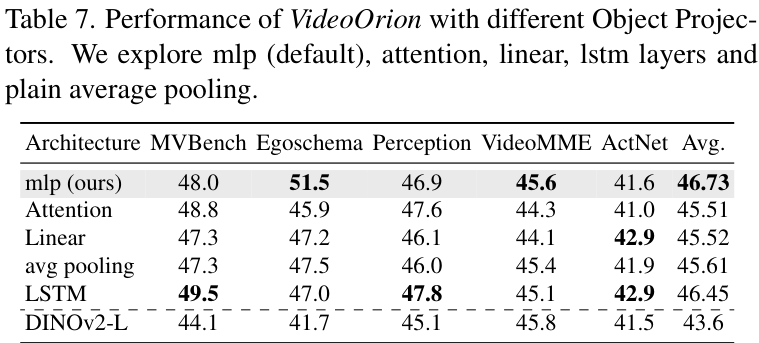
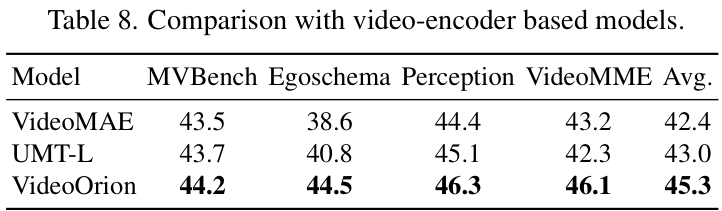
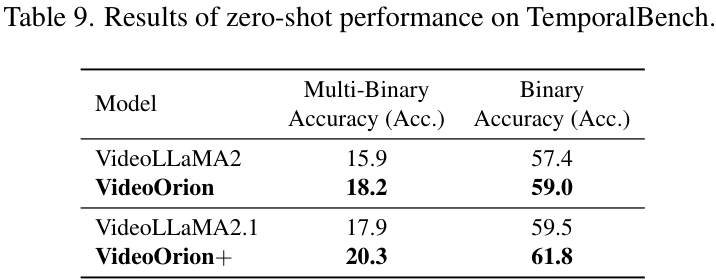
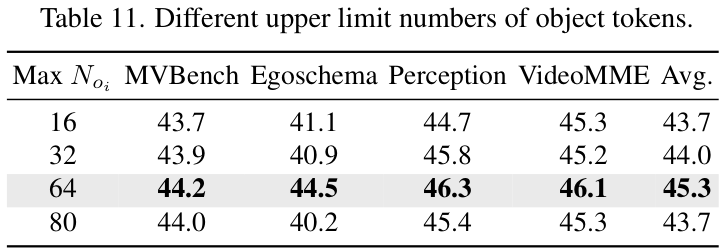
作者还探讨了不同的物体投影器设计、不同的检测-分割-追踪流程组件选择等,大量的实验都验证了当前设计的鲁棒性和有效性。
案例分析
光看数字可能不够直观,我们来看看具体的例子。
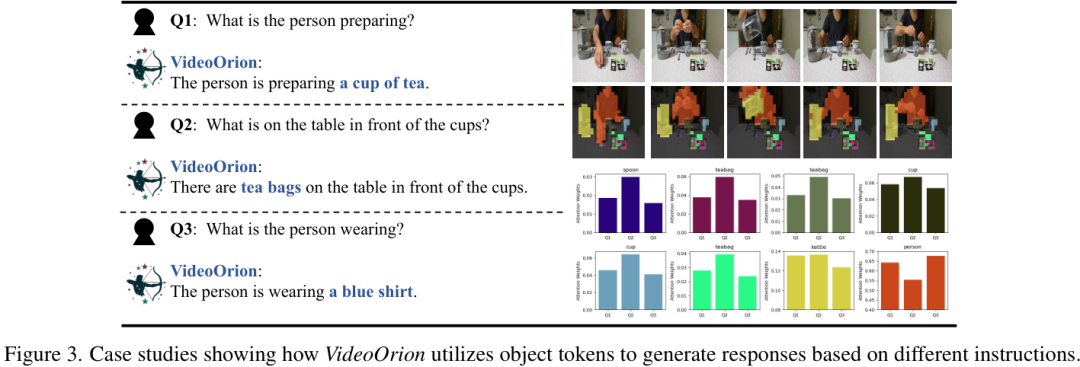
上图展示了当被问到不同问题时,VideoOrion如何动态地调整对不同物体Token的注意力。当问题是"这个人在干什么?"时,模型会更关注"人"这个物体。当问题是"杯子前面是什么?"时,模型则会把注意力更多地放在"茶包"和"杯子"上。这种动态的注意力分配机制,让VideoOrion能够根据指令灵活地聚焦于最相关的信息。

即使在一些复杂的场景下,比如需要理解人与人之间的交互,VideoOrion也能给出更准确的描述。
局限性与未来
当然,没有哪个模型是完美的。作者也坦诚地指出了VideoOrion的一些局限性。

例如,物体追踪流水线的性能直接影响最终效果。如果视频质量不高,或者物体检测、追踪失败了,模型的理解就会出错。上图就展示了一个追踪失败的例子。

此外,注意力机制偶尔也可能"开小差",错误地关注了不相关的物体,导致判断失误。

同时,引入这个复杂的物体分支也带来了额外的计算开销,推理时间增加了约38.5%。不过,CV君认为,考虑到其带来的显著性能提升,这个代价是值得的。并且作者也指出,未来随着视觉基础模型的进步,这些问题都有望得到缓解。
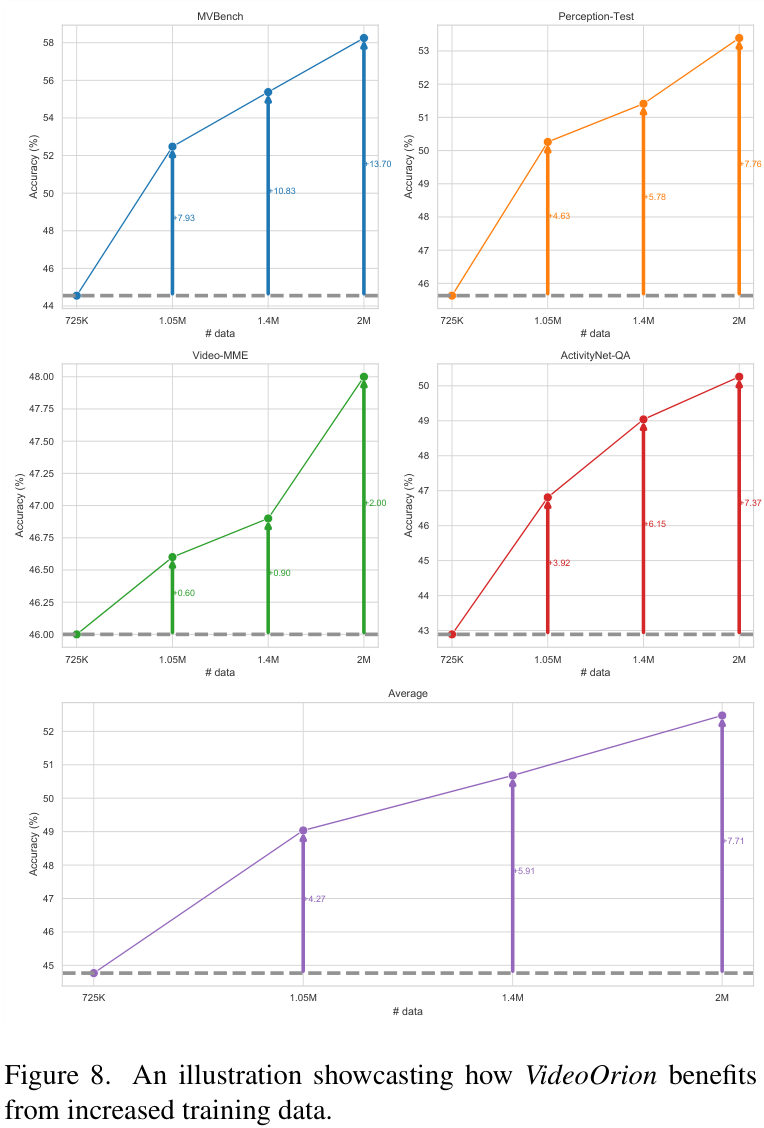
一个令人振奋的发现是,随着训练数据的增加,VideoOrion的性能能够持续稳定地提升,这展示了它巨大的潜力。
总的来说,VideoOrion为视频理解领域提供了一个非常新颖且有效的思路:通过显式地为视频中的物体建立动态模型,让大模型能够从"看热闹"进化到"看门道"。
大家对这个方法怎么看?欢迎在评论区留下你的看法!