目录
[1. 传统模型(如 RNN)的困境](#1. 传统模型(如 RNN)的困境)
[2. Transformer 的解决方案](#2. Transformer 的解决方案)
[Transformer 的三大核心组件](#Transformer 的三大核心组件)
[1. 它是现代大语言模型的基石](#1. 它是现代大语言模型的基石)
[2. 它的应用领域极其广泛](#2. 它的应用领域极其广泛)
[3. 它代表了 AI 领域的一种"范式转移"](#3. 它代表了 AI 领域的一种“范式转移”)
一、什么是Transformer
Transformer 是一种革命性的深度学习模型架构,它在 2017 年由 Google 在论文《Attention Is All You Need》中提出。
它的核心思想是:完全摒弃了之前主流模型(如 RNN、LSTM)的"顺序处理"模式,转而完全依赖于一种叫做"注意力机制"(Attention Mechanism)的技术。
为了更好地理解,我们来做一个简单的对比:
1. 传统模型(如 RNN)的困境
想象一下你要翻译一个句子:"The cat sat on the mat"。
- RNN 的处理方式: 像人一个词一个词地读。它先看到 "The",然后把这个信息(记在"记忆"里),再看到 "cat",更新记忆,再看到 "sat",再更新记忆......
- 问题所在:
- 信息遗忘: 当处理到句子末尾的 "mat" 时,关于开头 "The" 的记忆可能已经模糊了。这就是所谓的"长期依赖问题"。
- 无法并行: 你必须先处理完 "The" 才能处理 "cat",再处理 "sat"。这个过程是串行的,计算效率很低,无法充分利用现代 GPU 的并行计算能力。
2. Transformer 的解决方案
Transformer 说:"我们为什么要一个一个地看?为什么不能一眼看全句,然后自己决定哪个词最重要?"
- Transformer 的处理方式: 它把整个句子一次性输入模型。然后,通过其核心部件------自注意力机制 ,让句子中的每一个词都去"关注"其他所有词,并计算出它们之间的关联强度。
- 比如,在翻译 "sat" 这个词时,模型会同时看到 "cat" 和 "mat",并判断出 "sat" 这个动作的发出者是 "cat",位置是 "mat"。这种关联是动态计算出来的,而不是靠顺序传递。
Transformer 的三大核心组件
-
自注意力机制: 这是 Transformer 的心脏。它允许模型在处理一个词时,直接计算并权衡句子中所有其他词对该词的重要性。这解决了 RNN 的长期依赖问题。
-
多头注意力: "自注意力"做一次还不够。Transformer 把它分成多个"头",让每个"头"从不同角度去关注词与词之间的关系。比如,一个头可能关注"主谓关系",另一个头关注"动宾关系"。这让模型的理解能力更加丰富和立体。
-
位置编码: 因为 Transformer 不再按顺序处理,它本身不知道词的先后顺序。为了解决这个问题,我们给每个词的位置加上一个特殊的"位置编码"信号。这样,模型就能同时知道"词是什么"和"词在哪里"。
总结一下: Transformer 是一个并行计算能力强、能精准捕捉长距离依赖关系 的模型架构,其核心是注意力机制。
二、为什么要学习Transformer
1. 它是现代大语言模型的基石
你现在能接触到的几乎所有顶尖 AI 应用,其底层核心都是 Transformer 或其变体。
- GPT 系列 (ChatGPT, GPT-4): 它们的名字就说明了------G enerative P re-trained Transformer。没有 Transformer,就没有今天的 ChatGPT。
- Google 的 Gemini: 同样基于 Transformer 架构。
- Anthropic 的 Claude: 也是 Transformer 家族的一员。
可以说,Transformer 是驱动生成式 AI 浪潮的引擎。想理解 LLMs 为什么这么强大,就必须理解 Transformer 的工作原理。
2. 它的应用领域极其广泛
Transformer 的影响力早已超越了自然语言处理,渗透到了 AI 的各个角落:
- 自然语言处理: 机器翻译、文本摘要、情感分析、问答系统......几乎所有 NLP 任务的最佳模型都是 Transformer。
- 计算机视觉: Vision Transformer (ViT) 将图像分割成小块,像处理单词一样处理这些图像块,在图像分类等任务上取得了顶尖成果。
- 多模态领域: 像 DALL-E, Midjourney, Stable Diffusion 这样的文生图模型,以及像 GPT-4V 这样的能理解图像的模型,都依赖于 Transformer 来连接文本和像素这两种不同的数据。
- 生物信息学: AlphaFold 2 使用了类似 Transformer 的注意力机制来预测蛋白质结构,解决了生物学领域一个长达 50 年的重大挑战。
- 语音处理: 语音识别和语音合成模型也广泛采用 Transformer 架构。
3. 它代表了 AI 领域的一种"范式转移"
Transformer 的成功,标志着 AI 研究从"特征工程"和"模型迭代"转向了**"架构创新"** 和**"大规模预训练"**。
- "Attention Is All You Need" 这篇论文的标题本身就极具颠覆性。它证明了,一个设计精良的核心机制,其威力可以超越复杂的、堆砌起来的结构。
- 它催生了"预训练-微调"这一主流范式。先在海量无标签数据上预训练一个巨大的 Transformer 模型,然后在特定任务上用少量数据进行微调。这极大地降低了 AI 应用的门槛。
三、文本分类代码
代码基于ChnSentiCorp_htl_all.csv文件对评论文本进行分类,分为好评和差评两个类别。
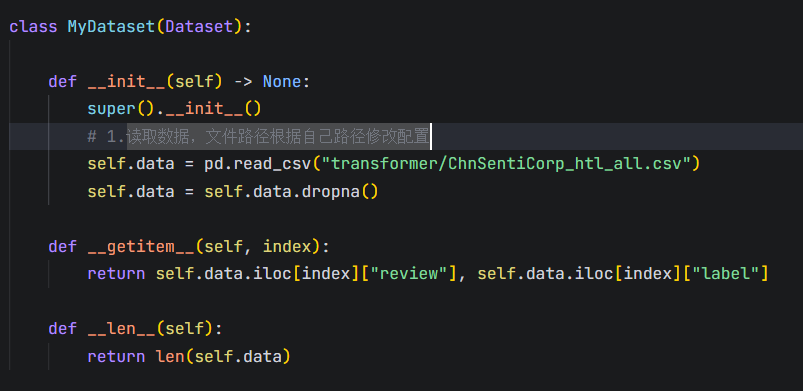
1.读取数据:
创建MyDataset类,来获取csv文件中的数据和标签, 返回文本内容和其对应的类别。self.data.ilocindex"review"是文本内容, self.data.ilocindex"label"是文本的类别(好评/差评)
2.创建模型:
本文使用的是官方的rbt3预训练模型来训练,可以在hugging face下载预训练模型。也可以使用自己搭建的transformer模型来训练(后续再写)

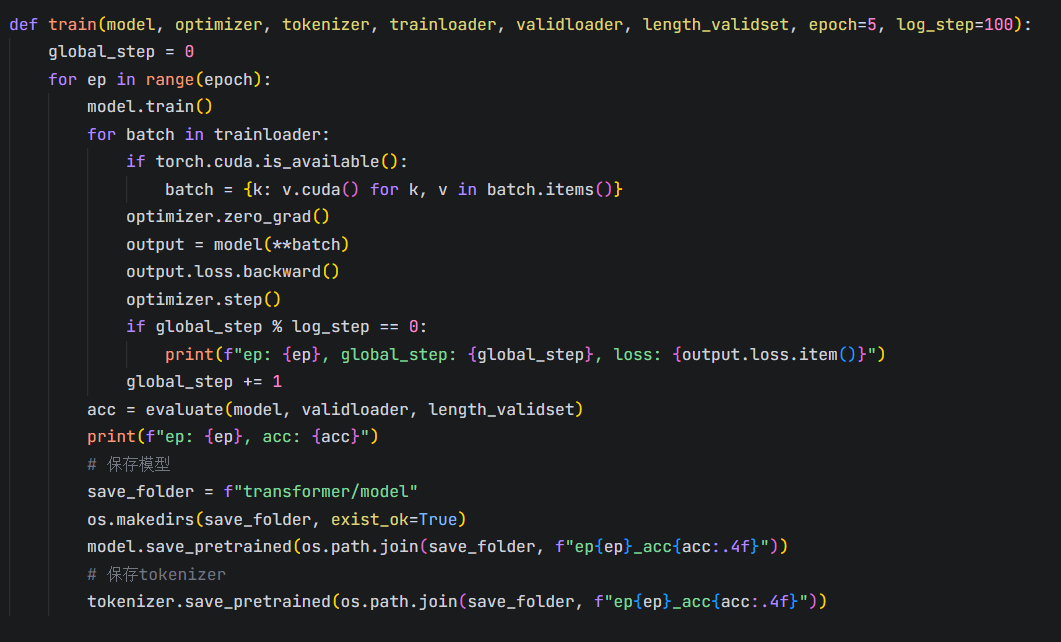
3.训练及验证模型
batchsize根据显存大小进行修改
4.完整代码
(学习代码比较粗糙,后续有空再调整优化)
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import pandas as pd
from torch.utils.data import Dataset, random_split, DataLoader
from torch.optim import Adam
import torch
import os
class MyDataset(Dataset):
def __init__(self) -> None:
super().__init__()
# 1.读取数据,文件路径根据自己路径修改配置
self.data = pd.read_csv("transformer/ChnSentiCorp_htl_all.csv")
self.data = self.data.dropna()
def __getitem__(self, index):
return self.data.iloc[index]["review"], self.data.iloc[index]["label"]
def __len__(self):
return len(self.data)
def evaluate(model, validloader, length_validset):
model.eval()
acc_num = 0
with torch.inference_mode():
for batch in validloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
output = model(**batch)
pred = torch.argmax(output.logits, dim=-1)
acc_num += (pred.long() == batch["labels"].long()).float().sum()
return acc_num / length_validset
def train(model, optimizer, tokenizer, trainloader, validloader, length_validset, epoch=5, log_step=100):
global_step = 0
for ep in range(epoch):
model.train()
for batch in trainloader:
if torch.cuda.is_available():
batch = {k: v.cuda() for k, v in batch.items()}
optimizer.zero_grad()
output = model(**batch)
output.loss.backward()
optimizer.step()
if global_step % log_step == 0:
print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")
global_step += 1
acc = evaluate(model, validloader, length_validset)
print(f"ep: {ep}, acc: {acc}")
# 保存模型
save_folder = f"transformer/model"
os.makedirs(save_folder, exist_ok=True)
model.save_pretrained(os.path.join(save_folder, f"ep{ep}_acc{acc:.4f}"))
# 保存tokenizer
tokenizer.save_pretrained(os.path.join(save_folder, f"ep{ep}_acc{acc:.4f}"))
def collate_func(batch, tokenizer):
texts, labels = [], []
for item in batch:
texts.append(item[0])
labels.append(item[1])
#将输入统一规整到一定的长度
inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")
inputs["labels"] = torch.tensor(labels)
return inputs
def train_main():
# 1. 加载数据集
dataset = MyDataset()
# 2. 划分训练集和验证集
trainset, validset = random_split(dataset, lengths=[0.9, 0.1])
# 3.创建Dataloader
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, collate_fn=lambda batch: collate_func(batch, tokenizer))
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=lambda batch: collate_func(batch, tokenizer))
# 4.从本地加载模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained("transformer/rbt3")
model = AutoModelForSequenceClassification.from_pretrained("transformer/rbt3")
if torch.cuda.is_available():
model = model.cuda()
# 5. 训练模型
optimizer = Adam(model.parameters(), lr=2e-5)
train(model, optimizer, tokenizer, trainloader, validloader, len(validset))
def pre_main():
# 预测
sen = "房间很旧,设施也比较落后"
id2_label = {0: "差评!", 1: "好评!"}
# 从本地加载模型
model = AutoModelForSequenceClassification.from_pretrained("transformer/model/ep2_acc0.9008")
tokenizer = AutoTokenizer.from_pretrained("transformer/model/ep2_acc0.9008")
if torch.cuda.is_available():
model = model.cuda()
model.eval()
with torch.inference_mode():
inputs = tokenizer(sen, return_tensors="pt")
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
logits = model(**inputs).logits
pred = torch.argmax(logits, dim=-1)
print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
if __name__ == "__main__":
train_main()