摘要 :统一多模态模型在图像生成与编辑任务中的性能,根本上受限于其训练数据的质量与全面性。尽管现有数据集已涵盖风格迁移和简单物体操作等基础任务,但往往缺乏现实应用所需的系统性结构和挑战性场景。为突破这一瓶颈,我们推出OpenGPT-4o-Image数据集------该大规模数据集通过将分层任务分类体系与自动化数据生成方法相结合的创新方式构建而成。我们的分类体系不仅包含文本渲染和风格控制等基础能力,还引入了化学插图等科学图像生成及需同时执行多项操作的复杂指令编辑等兼具实用性与挑战性的类别。通过利用结构化资源池和GPT-4o的自动化流水线,我们生成了8万个高质量的指令-图像配对样本,涵盖11个主要领域和51个子任务,并确保了可控的多样性。大量实验表明,在OpenGPT-4o-Image数据集上微调的主流模型在多个基准测试中均取得显著性能提升,其中编辑任务(UniWorld-V1在ImgEdit-Bench上)提升最高达18%,生成任务(Harmon在GenEval上)提升最高达13%。本研究表明,系统化的数据构建是推动多模态人工智能能力发展的关键。Huggingface链接:Paper page,论文链接:2509.24900
研究背景和目的
研究背景:
随着人工智能技术的快速发展,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图像生成与编辑领域取得了显著进展。
然而,现有数据集主要集中在基本任务,如风格迁移和简单对象操作,缺乏系统性和挑战性的真实世界应用场景。这些数据集在覆盖复杂场景和特殊知识需求方面存在明显不足,导致模型在处理技术插图、多指令同时执行等复杂任务时表现受限。为了推动多模态AI能力的进步,迫切需要构建一个更全面、更具挑战性的数据集,以支持模型在真实世界应用中的广泛部署。
研究目的:
本研究旨在通过构建一个名为OpenGPT-4o-Image的大型数据集,解决现有数据集在复杂性和系统性方面的不足。
该数据集旨在为图像生成与编辑任务提供高质量、多样化的训练数据,涵盖多个专业领域和复杂操作,以推动多模态AI模型在真实世界应用中的性能提升。具体目标包括:
- 系统性分类:构建一个层次分明的分类法,系统分解图像生成与编辑的复杂任务。
- 自动化生成:开发一个自动化、可扩展的数据生成管道,利用GPT-4o生成大规模、高质量的指令-图像对。
- 性能提升验证:通过实验验证,展示在OpenGPT-4o-Image数据集上微调的模型在多个基准测试上的性能提升。
研究方法
1. 层次分类法构建:
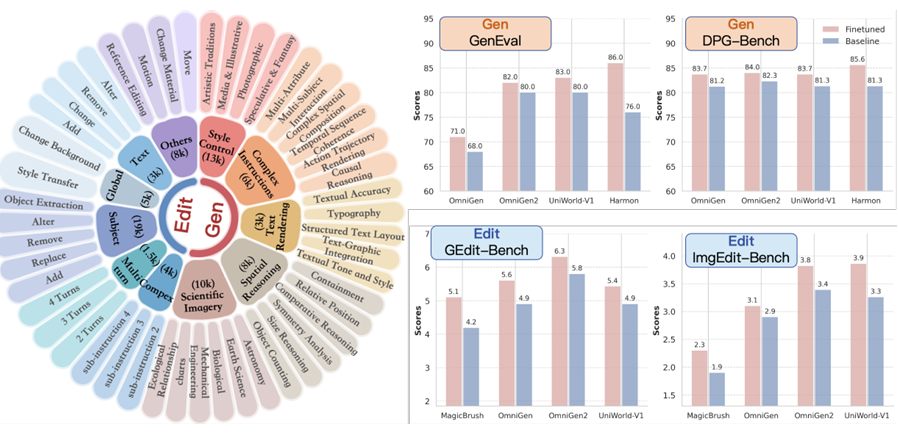
研究首先定义了一个层次分类法,将图像生成任务分为五个核心模块:风格控制、复杂指令跟随、图像内文本渲染、空间推理和科学图像。
每个模块进一步细分为多个子任务,以覆盖广泛的视觉能力和应用场景。例如,风格控制模块包括艺术传统、媒体与插图、摄影风格等子任务;复杂指令跟随模块涵盖多属性组合、多主体交互等子任务。
2. 图像编辑任务定义:
对于图像编辑任务,研究定义了六个主要类别和21个子任务,包括主体操作、文本编辑、复杂指令编辑、多轮编辑、全局编辑和其他具有挑战性的编辑形式。
每个类别和子任务都通过详细的指令模板进行描述,以确保数据的多样性和可控性。
3. 自动化数据生成管道:
研究开发了一个自动化、可扩展的数据生成管道,利用GPT-4o生成大规模、高质量的指令-图像对。该管道包括两个主要阶段:任务定义与范围界定和结构化提示生成。
在任务定义阶段,明确每个子任务的目标和能力边界;在结构化提示生成阶段,利用资源池和模板生成多样化的指令,并通过GPT-4o生成对应的图像。
4. 实验设置:
实验选用了四个领先的模型架构(UniWorld-V1、Harmon、OmniGen2和MagicBrush)进行微调,并在四个标准基准测试(GEdit-Bench、ImgEdit-Bench、GenEval和DPG-Bench)上评估模型性能。
通过对比微调前后的性能变化,验证OpenGPT-4o-Image数据集的有效性。
研究结果
1. 数据集规模与多样性:
OpenGPT-4o-Image数据集包含80,000个高质量的指令-图像对,覆盖11个主要领域和51个子任务。
数据集在风格控制、复杂指令跟随、图像内文本渲染、空间推理和科学图像等模块上表现出高度的多样性和复杂性。例如,风格控制模块涵盖了从西方艺术运动到东方传统绘画的多种风格;科学图像模块则涉及数学、物理、生物学等多个专业领域。
2. 模型性能提升:
实验结果表明,在OpenGPT-4o-Image数据集上微调的模型在多个基准测试上表现出显著的性能提升。
例如,UniWorld-V1在ImgEdit-Bench上的性能提升了18%,Harmon在GenEval上的性能提升了13%。这些提升表明,OpenGPT-4o-Image数据集能够有效增强模型在复杂任务上的表现。
3. 定量与定性分析:
定量分析显示,微调后的模型在多个评估维度上均有所提升,特别是在处理复杂指令和多轮编辑任务时表现尤为突出。
定性分析进一步揭示了模型在图像生成与编辑任务中的具体改进,如更准确地遵循复杂指令、生成更精细的图像细节等。
研究局限
1. 数据生成依赖GPT-4o:
尽管GPT-4o在生成高质量指令-图像对方面表现出色,但其固有的偏见和局限性可能影响数据集的多样性和质量。
例如,GPT-4o可能在某些专业领域的知识覆盖上存在不足,导致生成的数据在这些领域上的表现受限。
2. 评估基准的局限性:
现有评估基准可能无法完全捕捉真实世界应用场景中的复杂性和多样性。
尽管OpenGPT-4o-Image数据集在多个基准测试上表现出色,但仍需开发更全面的评估方法来验证模型在实际应用中的性能。
3. 数据集扩展性:
尽管OpenGPT-4o-Image数据集在规模和多样性上表现出色,但受限于计算资源和时间,研究未进行大规模的数据扩展和模型扩展实验。未来研究可探索更大规模的数据集和更复杂的模型架构,以进一步提升模型性能。
未来研究方向
1. 改进数据生成方法:
探索结合多种生成模型和方法,减少对单一模型的依赖,提高数据集的多样性和质量。例如,可结合扩散模型(Diffusion Models)和生成对抗网络(GANs)来生成更复杂的图像和指令对。
2. 开发新的评估基准:
针对真实世界应用场景,开发更全面、更具挑战性的评估基准。这些基准应涵盖更多复杂场景和特殊知识需求,以更准确地评估模型在实际应用中的性能。
3. 探索多模态模型的协同作用:
研究如何更好地利用多模态模型中的视觉和语言信息,实现更高效的协同作用。例如,可探索如何通过视觉信息增强语言理解能力,或通过语言指导视觉生成过程。
4. 推动实际应用:
将OpenGPT-4o-Image数据集应用于更多实际场景,如教育、医疗、娱乐等领域。通过在实际应用中验证数据集的有效性,进一步推动多模态AI技术的发展和应用。