摘要:
自监督学习已经成为数据增强的重要工具,传统方法通常依赖于对特定于任务的标签进行微调,当标签数据稀缺时,限制了它们的有效性。创建一个面向图的LLM,能够在不依赖于下游图数据的情况下对各种数据集和任务进行特殊的泛化(所谓的zero-shot)。文章提出的GraphGPT将大模型和图结构知识集成在一起,由两部分组成:1)文本-图对齐 ;2)双阶段图指令微调。
介绍:
目前的GNN方法的一个显著局限性是严重依赖于监督学习,这会导致在面对稀疏和噪声数据时鲁棒性和泛化能力不足。SSL增强的图学习方法有两种主要的范例:对比式和生成式。对比式重点在于在于通过对比正样本和负样本来学习表征,如DGI和GCA。生成式专注于生成与原始图形结构非常相似的合成样本,使用掩码自动编码器,如GraphMAE和S2GAE等技术。这些模型主要用来生成用于下游任务的编码,在微调时需要使用特定于下游图表学习场景的标签,但高质量的应用于特定任务的数据必要但难得。

仅输入节点文本数据和采用文本化图结构的实验感知表明纯文本提示无法让 LLM 有效建模图结构------ 要么完全缺失结构信息,要么无法精准传递结构逻辑,最终导致节点分类结果错误,凸显纯文本方式在图结构建模中的固有局限性。GraphGPT 通过保留图结构信息的设计,有效解决了上述问题:GraphGPT 不依赖文本化描述图结构,而是通过 "文本 - 图接地" 机制将图结构编码为图 token(如<graph>标识 + 结构化的图 token 序列),向 LLM 输入 "包含目标论文文本 + 图 token 的子图信息"。
文章做的事情可以分为三点:
1)文本-图的对齐:对齐图结构编码与语言空间,为 LLM 提供可理解的图结构输入。
2)双阶段图指令微调: 阶段1:自监督指令微调(无标注数据):图匹配任务 ------ 以节点为中心采样 h-hop 子图,输入<graph>标识与打乱的节点文本,让 LLM 按图 token 顺序重排文本,学习图结构与文本的对应关系。阶段二:特定指令微调(有标注数据)针对节点分类、链路预测等任务设计统一指令模板(含<graph>标识、图信息、人类问题)。
3)思维链(CoT)蒸馏:提升 LLM 的图推理能力,应对分布偏移(如不同数据集节点类数差异)。
方法论
文本-图对齐的结构信息编码
使用图编码器fG生成图的结构信息编码H,使用tfG(Transformer或bert)对文本信息进行处理,得到T。
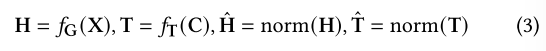
之后得到损失函数L,通过最小化总损失,不断调整图编码器与文本编码器的参数,最终让图结构信息与节点文本信息映射到统一的语义空间,实现两者的有效对齐,为后续 LLM 同时理解图结构与文本语义打下基础。T'是邻居节点的文本信息编码
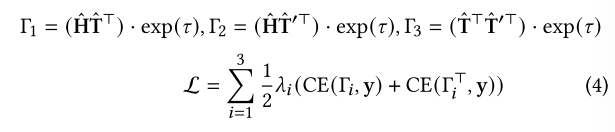
双阶段图指令调优
双阶段图指令调优范式建立在指令调优的概念基础上,指令调优是最近提出的,以增强语言模型对特定领域的适应性。
自监督指令微调
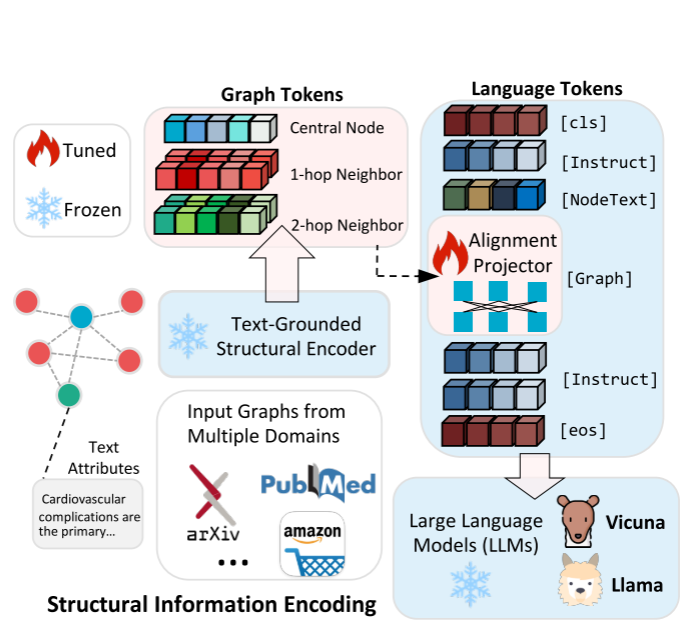
首先,对一个图选取一个中心点之后进行采样,比如选 1-hop、2-hop 邻居,生成一个小的子图(包含中心节点、邻居节点及它们的连接关系);同时,提取子图中所有节点的文本信息(如引文图中的论文标题、摘要),但故意打乱文本顺序(比如把 "论文 A、B、C" 的标题乱排成 "B、A、C")。
将采到的子图的结构信息H通过一个对齐网络(简单线性网络)生成图token ;而人类问题 是有明确任务要求,比如 "请根据图 token 的顺序,重新排列以下打乱的节点文本";预期输出指LLM 需输出 "图 token 与文本的对应关系"(如 "<graph_token1 > 对应论文 A 标题,<graph_token2 > 对应论文 B 标题")。上面三个组合形成指令。
而LLM的输入除了指令外还包括节点的文本信息。LLM 完成匹配后,将其输出与 "真实对应关系"(比如 < graph_token1 > 本就该对应中心节点的文本)对比,对比错误的仅仅对对其网络进行调整。
特定于任务的指令调整
接第一阶段 "自监督指令微调" 的结构理解基础,核心目标是让模型针对节点分类、链路预测等具体图任务做定制化适配,确保 LLM 能结合图结构与文本生成符合任务要求的输出。这里不像第一阶段,使用的数据是带标签的。
指令组成上跟第一阶段相比并无变化,但人类问题和预期输出格式上更贴近具体任务设计,当然采样策略可能也会有所变化。如下图

训练时,在第一阶段的基础上微调对齐网络的参数,避免 "忘记" 通用关联规律,仅针对任务需求微调,实现 "通用能力 + 任务适配" 的结合。
思想链(COT)蒸馏
核心目标是解决大语言模型(LLM)在复杂图任务(如多类别节点分类)和数据分布偏移场景下 "推理能力不足" 的问题,通过从大模型(如 GPT-3.5)中提取 "逐步推理知识" 并迁移到 GraphGPT,让模型具备 "一步一步分析图结构与文本" 的能力。
具体来说,我们给大模型发个 "带要求的提示",让它不光给结果,还得写清 "怎么想的,之后将大模型的思考过程融入指令中进行微调,使 GraphGPT 具备 "逐步分析图结构与文本" 的能力。