前期尝试用Unsloth微调大模型(大模型之用Unsloth微调医疗大模型实践),但整体步骤比较多,对初学者不太友好,下面介绍一款戏相对比较简单的大模型微调框架------LLaMA-Factory。
一、微调环境准备
1、安装Anaconda
介绍Anaconda安装的文章比较多,这里就不详细介绍了。可以参见:Anaconda安装。
(1)创建名称为"llama_factory"的虚拟环境。
conda create -n llama_factory python=3.11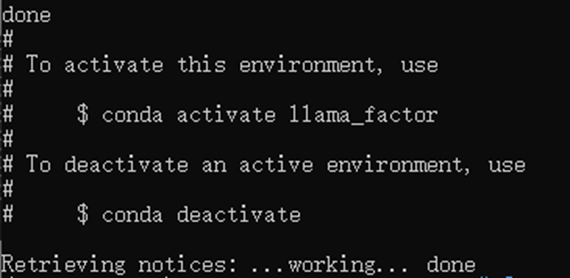
(2)查看已创建的虚拟环境列表。
conda env list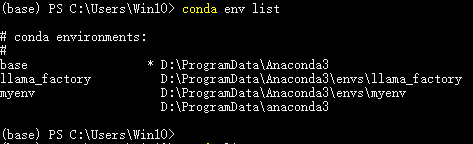
(3)激活虚拟环境llama_factory,
conda activate llama_factory
2、安装LLaMA-Factory
(1)从GitHub下载LLaMA-Factory,
git clone https://github.com/hiyouga/LLaMA-Factory.git(2)在LLaMA-Factory目录下安装所需的Python包
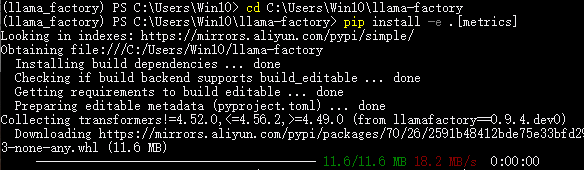
cd C:\Users\Win10\llama-factory
pip install -e .[metrics]注意:该命令必须在LLaMA-Factory安装目录中执行。
......
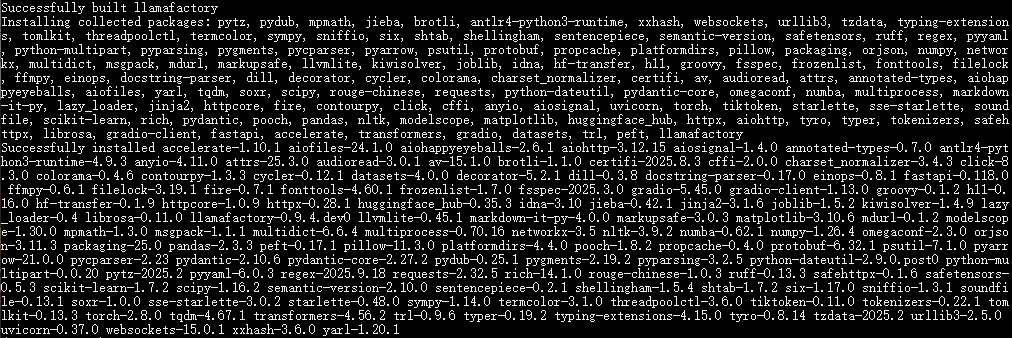
(3)检验LLaMA-Factory是否安装成功
python
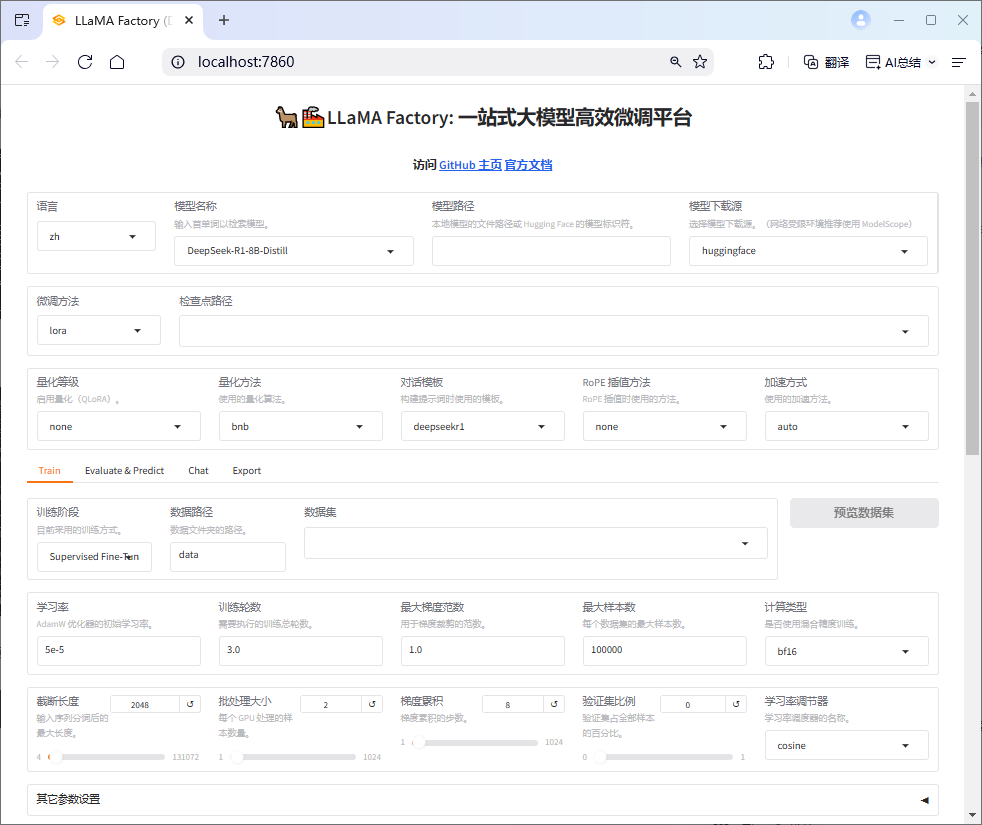
llamafactory-cli webui如出现以下提示和LLaMA-Factory页面表示已成功安装。

3、安装torch
(1)查看CUDA版本(需提前安装CUDA),
nvidia-smi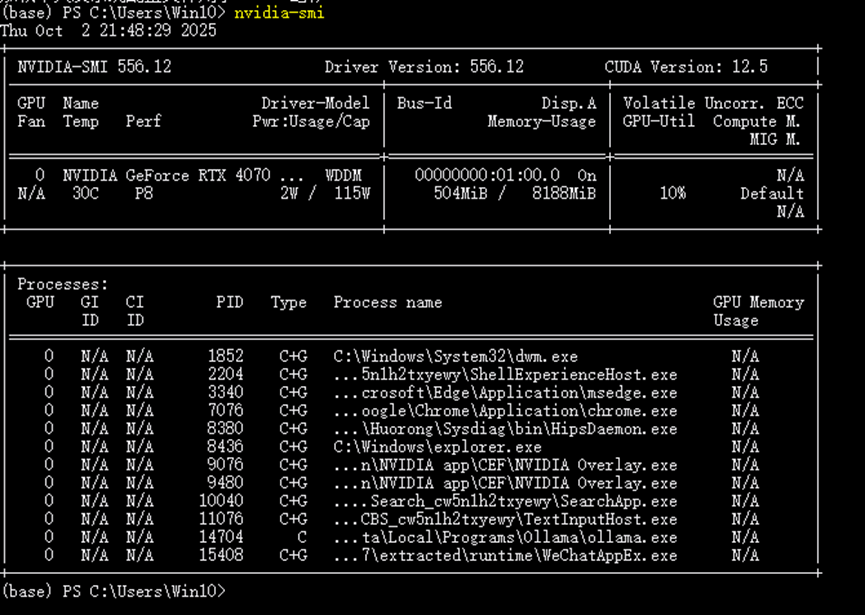
CUDA安装可参考(CUDA安装教程)。
(2)接下来选择合适的CUDA版本安装torch。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124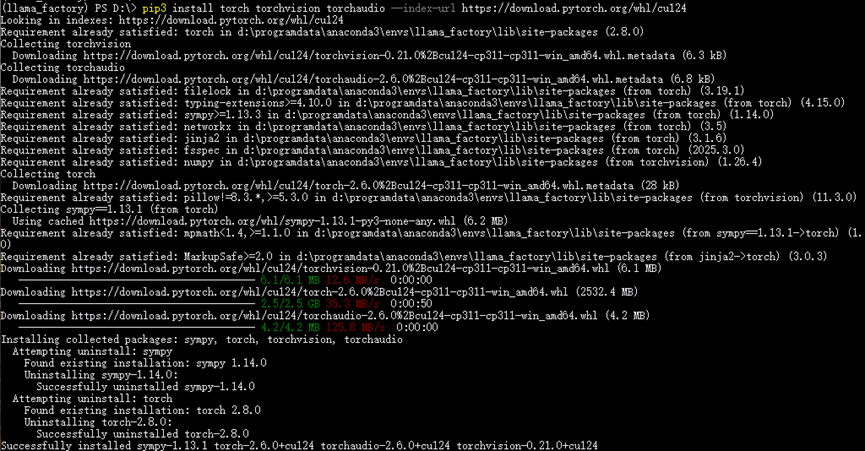
具体可参考(Python/torch/深度学习------环境安装)。
(3)检验torch是否安装成功
python
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__以下显示表示torch已经成功安装。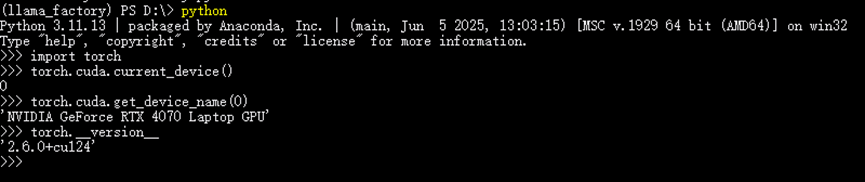
二、基座模型准备
1、下载基座模型
创建一个文件夹存放基座模型,这里以下载魔搭社区的DeepSeek-R1-Distill-Llama-8B模型为例。
python
cd D:\AI\LLaMA-Factory\model_base
git clone https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B
2、测试模型推理
python
llamafactory-cli webchat --model_name_or_path D:/AI/LLaMA-Factory/model_base/DeepSeek-R1-Distill-Llama-8B --template deepseekr1注意:不同的模型需要使用不同的模版,具体见(LLaMaFactory - 支持的模型和模板 && 常用命令)当然,也可以通过"llamafactory-cli webui"命令在LLaMA-Factory页面进行测试。
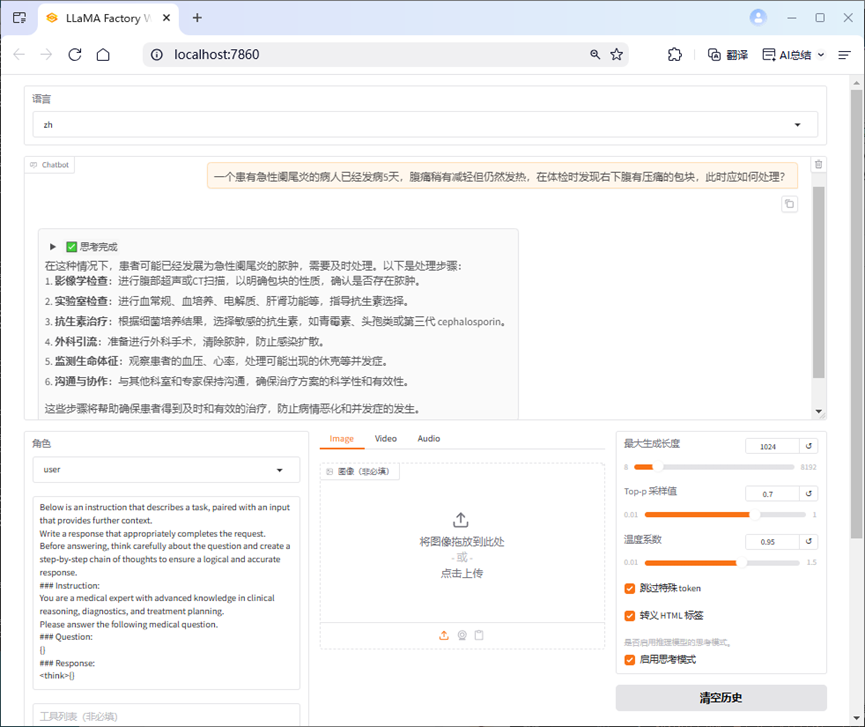
这里我们先对微调前的模型进行提问,并保留其结果,方便与微调后的模型推理进行对比。
三、训练数据准备
1、下载训练数据
下载训练数据集并复制到llama-factory\data文件夹下,我这里使用的是huggingface上的"FreedomIntelligence/medical-o1-reasoning-SFT"数据集(方便与前期用Unsloth微调进行对比,使用了相同的模型和数据集)。

数据集格式如下:

2、修改数据集配置文件
打开llama-factory\data\dataset_info.json文件,在文件最后添加以下代码:
python
"traindata_local": {
"file_name": "medical/medical_o1_sft_Chinese.json",
"columns": {
"prompt": "Question",
"response": "Response"
},
"tags": {
"reasoning": "Complex_CoT"
}
}四、微调模型
1、方式一(Web页面)
执行以下代码进入LLaMA-Factory页面。
python
llamafactory-cli webui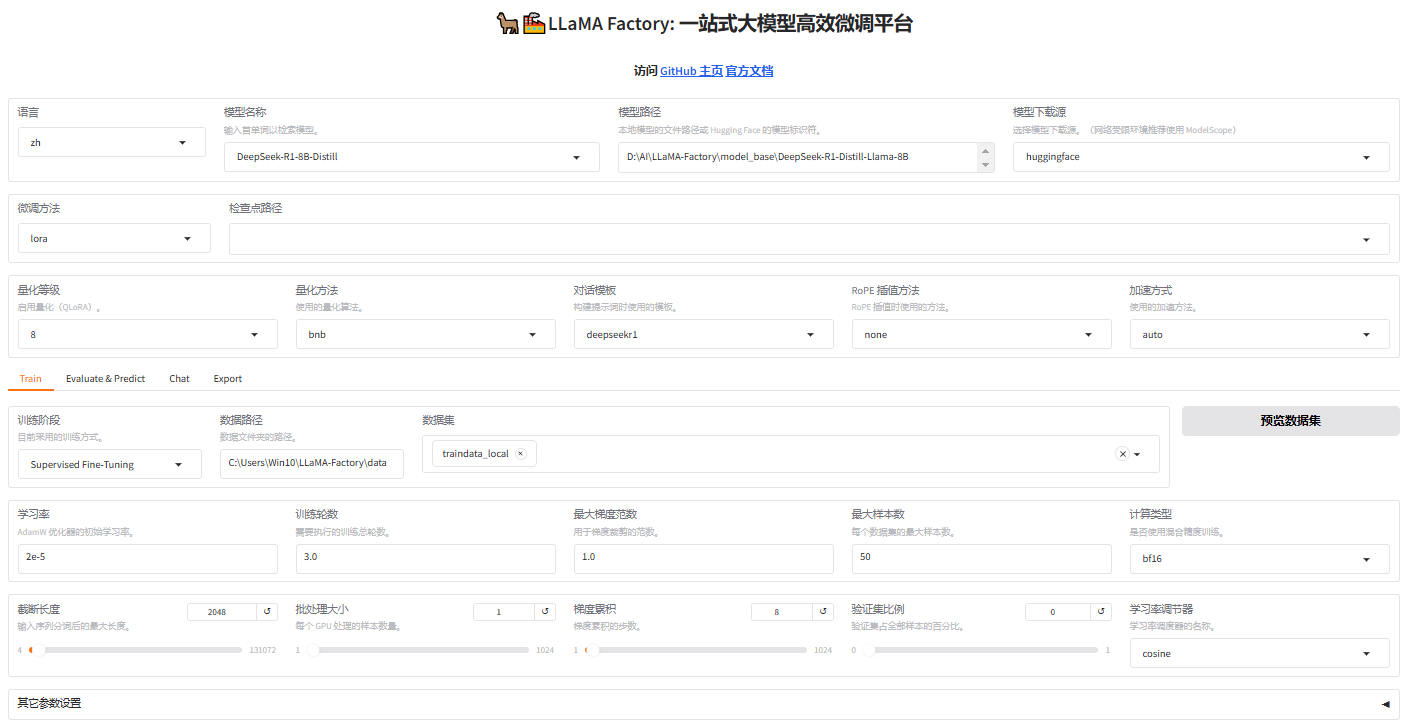
分别填写基础模型、训练数据等参数,填写完成后可以选择"预览命令"查看微调命令,同时可"保存训练参数",以备下次直接导入使用。具体参数设置可参见(LlamaFactory可视化微调大模型 - 参数详解)。
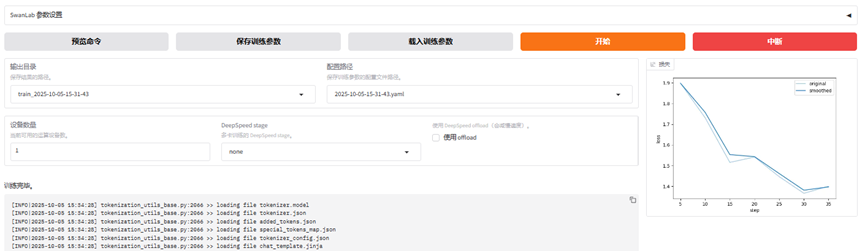
配置完成就可以开始执行,如遇错误可根据提示信息修改完善配置参数的设置,直到训练完成。微调训练过程中可以观察训练进度条和损失曲线。

2、方式二(命令行)
可在命令行模式下直接执行以下命令进行微调。
python
llamafactory-cli train `
--stage sft `
--do_train True `
--model_name_or_path D:\AI\LLaMA-Factory\model_base\DeepSeek-R1-Distill-Llama-8B `
--preprocessing_num_workers 16 `
--finetuning_type lora `
--template deepseekr1 `
--flash_attn auto `
--dataset_dir C:\Users\Win10\LLaMA-Factory\data `
--dataset traindata_local `
--cutoff_len 1024 `
--learning_rate 5e-05 `
--num_train_epochs 3.0 `
--max_samples 50 `
--per_device_train_batch_size 1 `
--gradient_accumulation_steps 4 `
--lr_scheduler_type cosine `
--max_grad_norm 1.0 `
--logging_steps 5 `
--save_steps 100 `
--warmup_steps 0 `
--packing False `
--enable_thinking True `
--report_to none `
--output_dir saves\DeepSeek-R1-8B-Distill\lora\train_2025-10-05-19-46-10 `
--bf16 True `
--plot_loss True `
--trust_remote_code True `
--ddp_timeout 180000000 `
--include_num_input_tokens_seen True `
--optim adamw_torch `
--quantization_bit 8 `
--quantization_method bnb `
--double_quantization True `
--lora_rank 8 `
--lora_alpha 16 `
--lora_dropout 0 `
--lora_target all 模型微调完成后会在对应位置自动创建的saves文件夹。
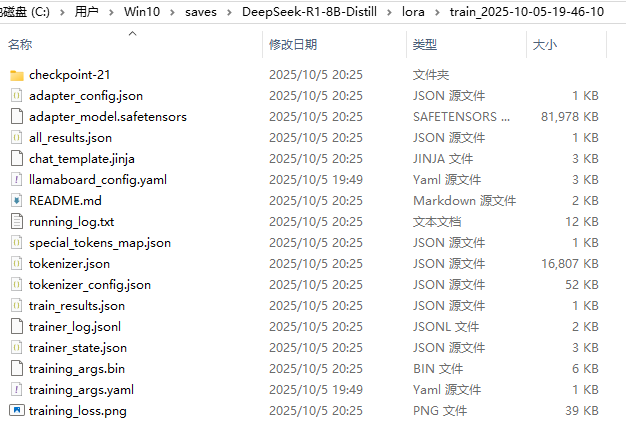
五、测试微调后模型
下面合并基础模型和LoRA微调进行推理。
1、方式一(Web页面)
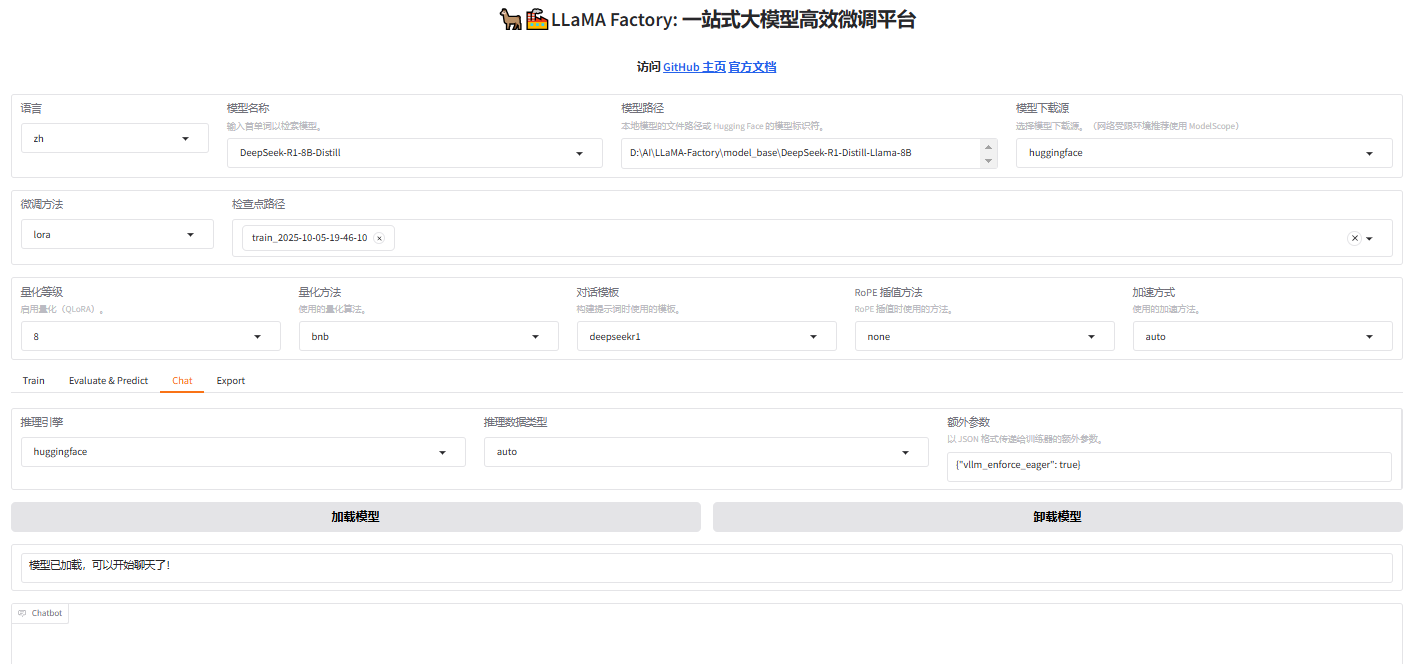
微调结束后,可直接在Web下选择"Chat"页面,然后设置"模型路径"(基座模型)和"检查点路径","检查点路径"为刚训练好的模型,再点击加载模型即可开始合并推理。
2、方式二(命令行)
执行以下命令:
python
llamafactory-cli webchat `
----model_name_or_path D:\AI\LLaMA-Factory\model_base\DeepSeek-R1-Distill-Llama-8B `
--adapter_name_or_path saves\DeepSeek-R1-8B-Distill\lora\train_2025-10-03-21-59-27 `
--template deepseekr1 `
--finetuning_type lora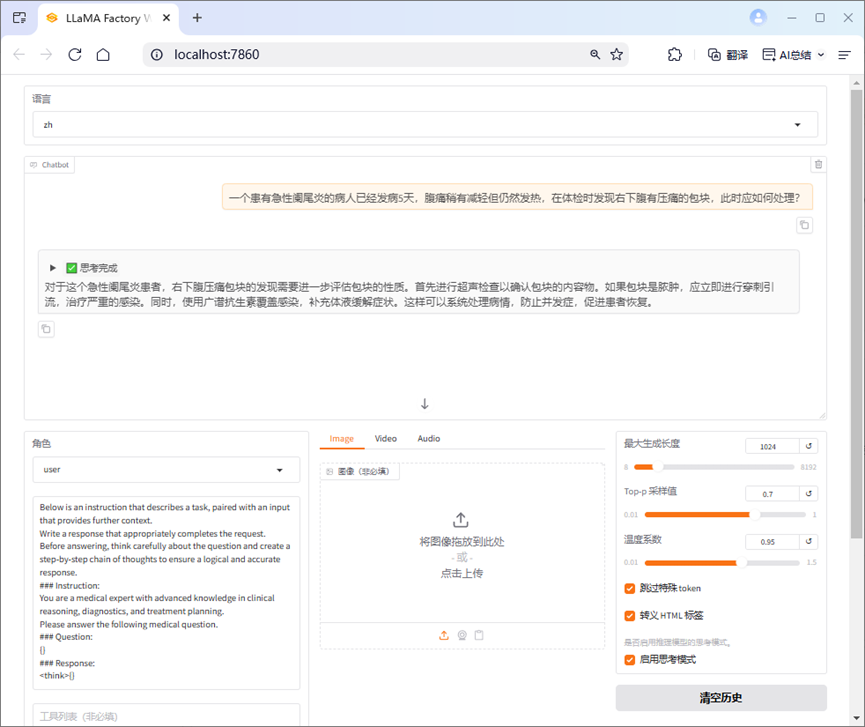
输入与微调前测试的相同问题进行微调后推理,可以观察前后回答不同,当然具体效果与数据集质量和微调参数设置密切相关。
六、微调模型合并
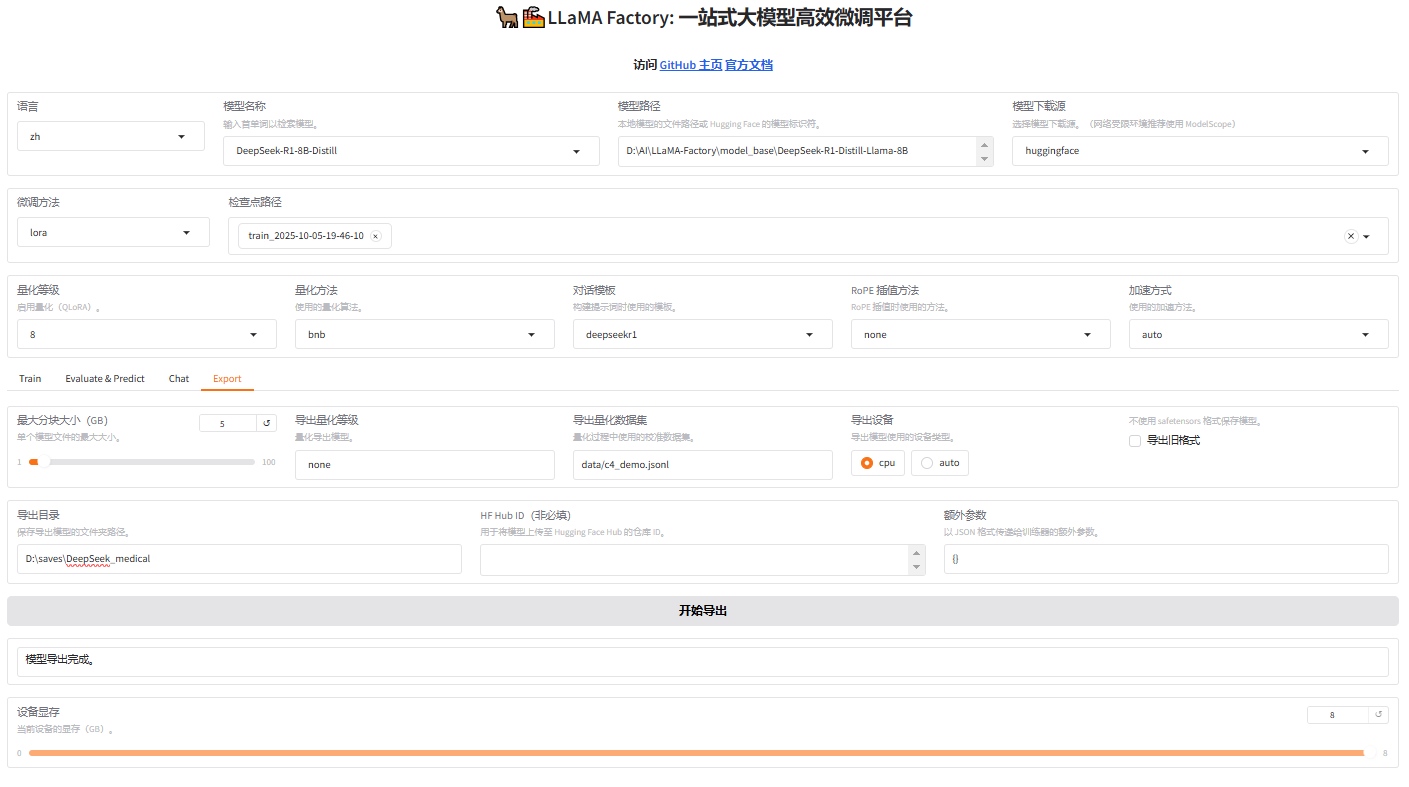
在Web下选择"Export"页面,然后设置"模型路径"(基座模型)、"检查点路径"(微调模型)、"导出目录",即可开始合并基座模型和微调模型,合并完成后即可在"Chat"页面直接使用。
七、评估与优化
在Web下选择"Export"页面,然后设置"模型路径"(基座模型)、"检查点路径"(微调模型)、"数据路径"(验证数据集),即可开始进行模型评估。
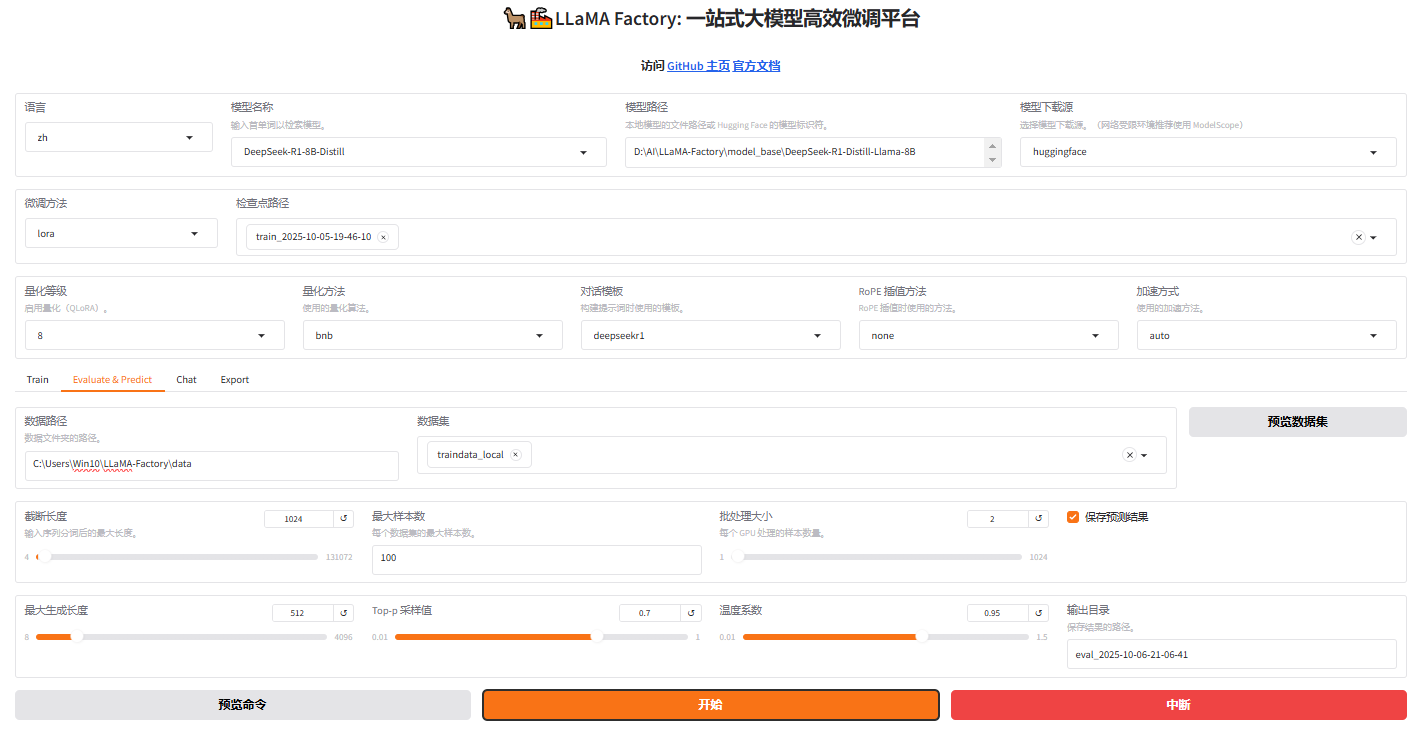
评估完成后会在界面上显示验证集的分数,其中ROUGE分数衡量了模型输出答案(predict)和验证集中标准答案(label)的相似度,ROUGE分数越高代表模型学习得更好。