该研究由小米具身智能团队(Xiaomi Embodied Intelligence Team) 共同完成。由该团队的郝孝帅 担任核心贡献第一作者,项目负责人则是小米智驾团队首席科学家陈龙。团队致力于打破单一领域的界限,构建能够同时理解物理世界并进行复杂推理的通用智能体(模型),汇聚了自动驾驶与具身智能领域的顶尖研究力量。

大语言模型(LLM)与多模态大语言模型(MLLM)的浪潮正以前所未有的速度席卷 AI 领域,但当算法试图走出数字世界,迈入物理实体时,却遭遇了严重的"水土不服"。
在传统的具身智能研发范式中,自动驾驶 (Autonomous Driving)与具身智能(Embodied AI)长期被视为两条平行线。前者在户外高速动态环境中,通过激光雷达与相机感知车流与红绿灯;后者则在室内静态或低速环境中,依赖机器人本体进行精细的导航和操作任务。
这种"各管一摊"的局面,导致了严重的领域割裂。现有的专用模型往往"偏科"严重:自动驾驶模型(如 DriveLMM)缺乏对物体部件级的精细理解,而机器人模型(如 RoboBrain2.0)则难以应对复杂的交通博弈与高动态场景。
结果就是,我们始终缺乏一个能够打通室内外、融合动静态感知的统一"大脑"。
在11.21日发表的技术报告《MiMo-Embodied: X-Embodied Foundation Model》中,小米具身智能团队指出了这一痛点,并发布了 MiMo-Embodied------这是首个开源的、成功融合了自动驾驶与具身智能的跨域基座模型。
研究数据显示,MiMo-Embodied 在17个具身智能基准 和12个自动驾驶基准上均刷新了记录(SOTA),不仅大幅超越了开源基线,更在空间推理与规划等关键指标上击败了 GPT-4o、Gemini-Pro 等闭源模型,证明了跨域知识融合的巨大潜力。

论文题目:
MiMo-Embodied: X-Embodied Foundation Model**
论文链接:
项目主页:
统一物理世界的认知基座
要解决领域割裂,不能简单地进行模型拼接。MiMo-Embodied 的核心在于构建了一个统一的感知与推理模型架构。
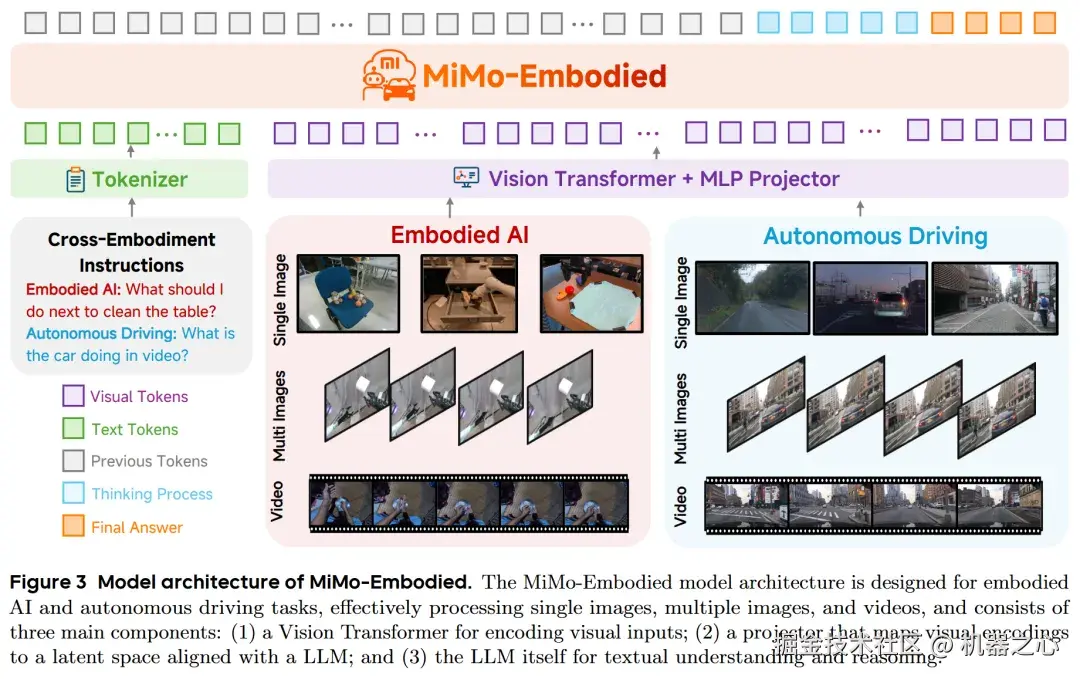
该模型基于小米自研的 MiMo-VL 架构(包含 Vision Transformer 视觉编码器与 MLP 投影层),将物理世界的交互能力解构为六大核心维度:
在自动驾驶侧 ,模型不仅要进行环境感知(识别车道、障碍物),更需具备状态预测(Status Prediction)与驾驶规划(Driving Planning)能力------即像老司机一样,预测旁车意图,并生成符合交通规则的驾驶轨迹。
在具身智能侧 ,模型重点攻克可供性预测(Affordance Prediction)与空间理解(Spatial Understanding) 。这意味着模型不仅要识别物体,还要理解物体"哪里能抓"、"哪里能放",并能解析复杂的空间介词(如"在...左边的物体,在...的前方区域")。
四阶段进化:从"看懂"到"决策"
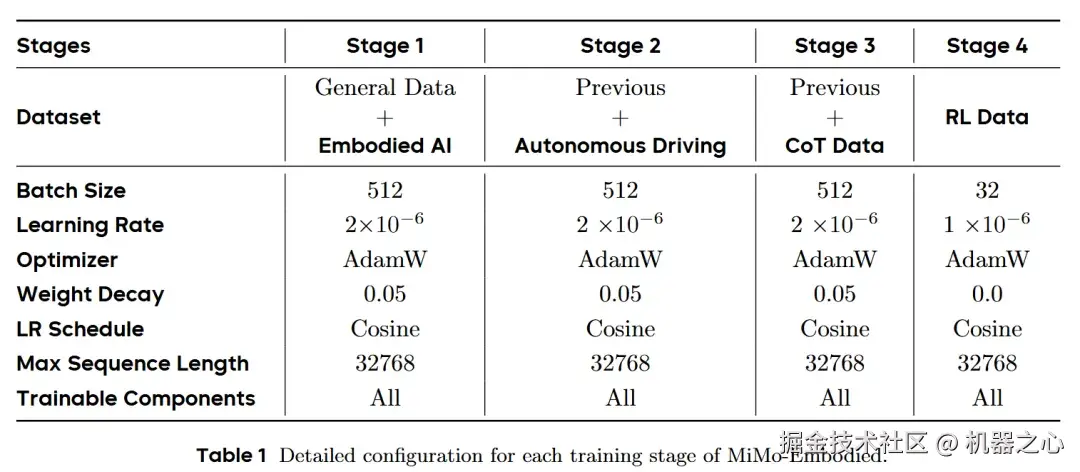
如何在单一模型中融合差异巨大的跨域数据,同时避免"灾难性遗忘"?小米团队设计了一套严谨的四阶段渐进式训练策略(Progressive Four-stage Training Strategy) ,这也是该模型性能卓越的关键。
简单的混合训练往往会导致"灾难性遗忘"。团队首先利用海量通用数据与具身数据奠定基础,建立模型对物体与空间的初级认知;随后引入大规模自动驾驶数据,通过混合监督学习,让模型在掌握高速动态感知的同时,保留对室内精细操作的理解。
阶段一:具身与通用知识奠基。 这一阶段类似于人类的"通识教育"。模型利用海量通用图文数据(Visual Grounding、OCR)和具身智能数据(如 RoboRefIt、Cosmos-Reason1)进行监督微调。这建立了模型对细粒度物体部件的定位能力,以及对基础空间关系的理解,使其学会"看懂"静态物理世界。
阶段二:自动驾驶知识注入与混合监督。 模型随后进入"驾校"。团队引入了包括 CODA-LM(长尾场景)、nuScenes-QA 在内的大规模自动驾驶数据。关键创新在于混合监督(Mixed Supervision) ------在注入高速动态驾驶知识的同时,保留部分具身数据。这确保模型在学习识别红绿灯和车道线时,不会遗忘如何识别室内的水杯和把手。
阶段三:思维链推理(CoT)的逻辑升华。 只会感知还不够,智能体必须具备逻辑推理能力。团队构建了包含显式推理步骤(Rationale)的数据集,利用 Chain-of-Thought (CoT) 技术进行微调。 例如,在面对"车辆是否应该变道?"的问题时,模型不再直接输出"是/否",而是生成一段完整的思考路径:"检测到前方拥堵 -> 左侧车道空闲 -> 且后方无快速来车 -> 因此建议变道"。这种显式的逻辑生成,极大提升了模型在长尾复杂场景下的鲁棒性与可解释性。
阶段四:强化学习(RL)的终极打磨。 这是画龙点睛的一笔。针对多模态模型常有的"幻觉"问题(如生成的坐标不准确),团队利用 GRPO算法。通过设计针对性的奖励函数,RL 算法迫使模型在面对同一个问题时,从多个候选答案中收敛到逻辑更严密、坐标更精准的输出。这就像是考前的"高强度刷题",将模型的执行精度推向了极致。
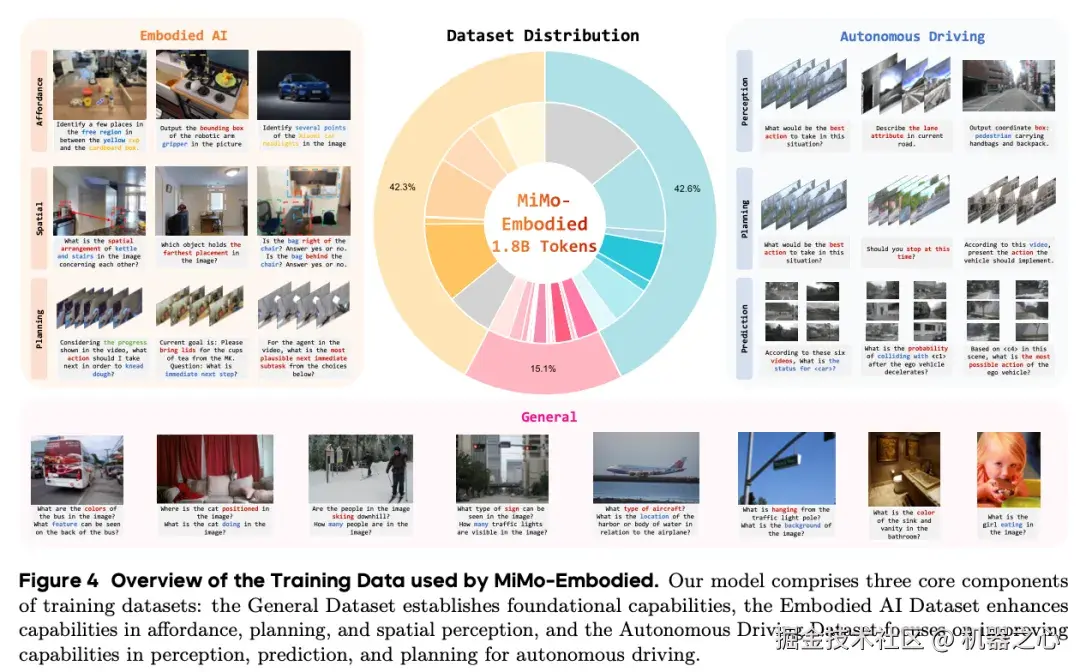
总体数据集规模与配置如下:
实验结果:正向迁移引发的性能跃升
这种"四步走"策略带来的效果是结构性的。实验表明,MiMo-Embodied 并非两个领域的简单叠加,而是实现了正向迁移。
🎯 具身智能基准测试:17项SOTA全面突破
在17个具身智能基准测试中,MiMo-Embodied 在可供性预测(Affordance Prediction)、任务规划(Task Planning)和空间理解(Spatial Understanding)三大核心能力上全面刷新记录。
可供性预测能力
MiMo-Embodied 模型在 RoboRefIt、Where2Place、VABench-Point、Part-Afford 和 RoboAfford-Eval 五个专业基准上均达到最优性能。特别值得注意的是,MiMo-Embodied 在 VABench-Point、Part-Afford 和 RoboAfford-Eval 上大幅领先其他具身智能模型,展现出在精细可供性推理方面的强大能力。
任务规划能力
MiMo-Embodied 在 RoboVQA 基准上表现最优,展示了在因果推理和目标导向结果理解方面的卓越能力。在长时规划基准 EgoPlan2 上也取得了极具竞争力的成绩,充分证明了模型在长时推理方面的有效性。

空间理解能力
MiMo-Embodied在综合空间智能任务 CV-Bench 上取得最优结果,在空间关系推理的 RoboSpatial、RefSpatial-Bench 和 CRPE 关系子集上均领先。这些结果验证了 MiMo-Embodied 在物理世界具身推理方面的强大能力。
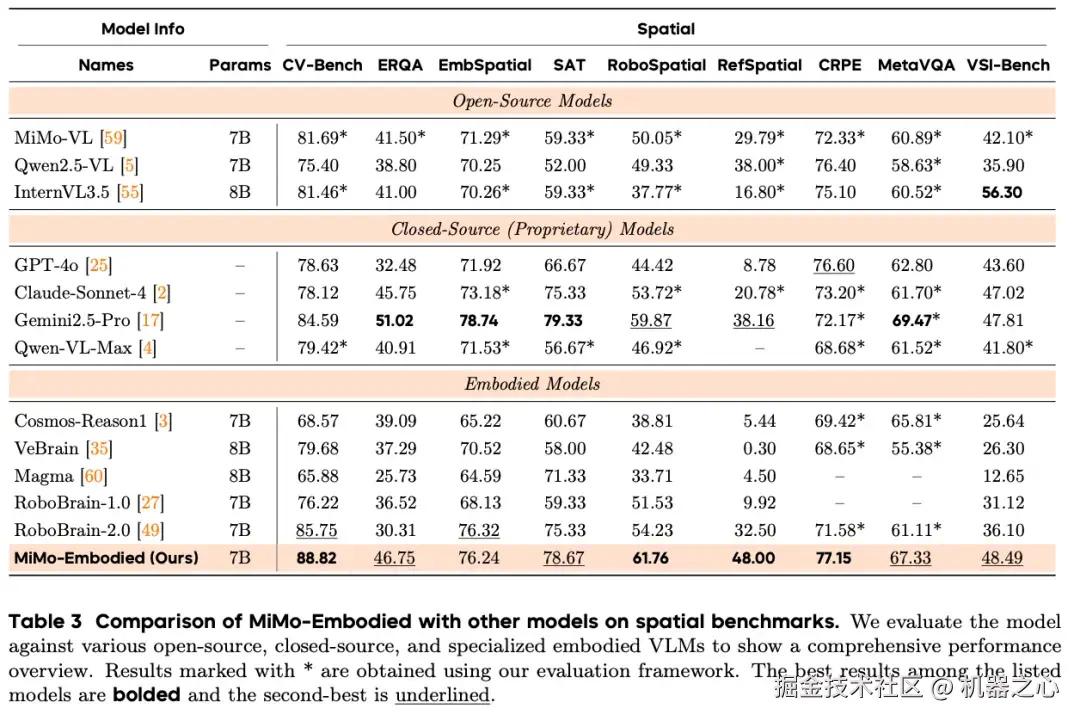
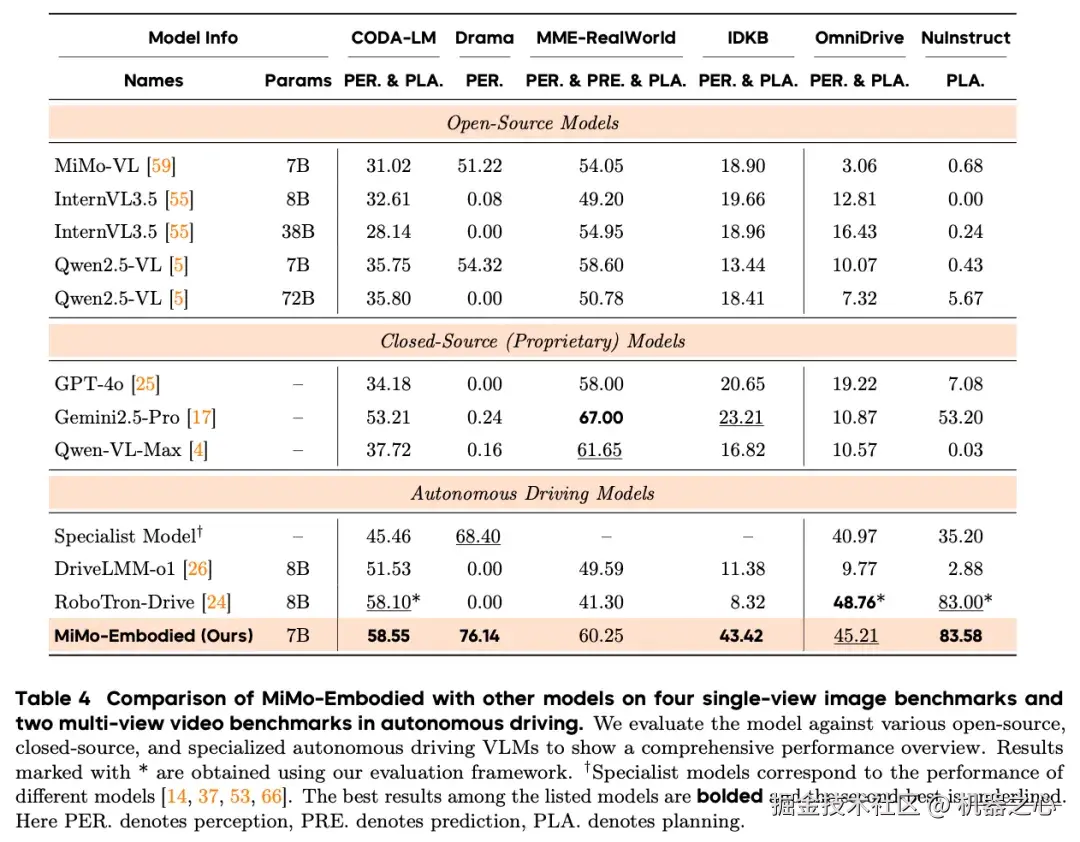
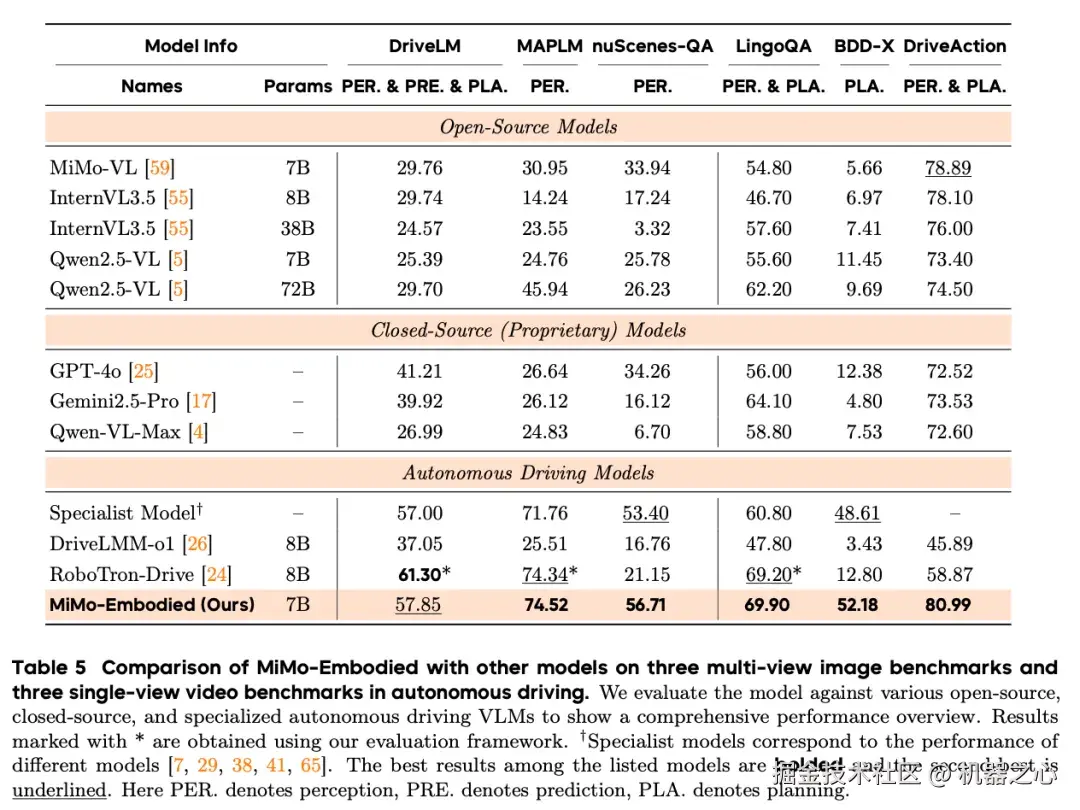
🚗 自动驾驶基准测试:12项指标全面领先
MiMo-Embodied 在12个自动驾驶基准上表现卓越,涵盖环境感知、状态预测和驾驶规划三大维度。
环境感知能力
在全景语义理解任务上展现最优表现,在具有挑战性的局部感知场景中也表现出卓越的鲁棒性。实验结果令人信服地证明,MiMo-Embodied 具备多层次、高保真的环境感知能力。
状态预测能力
在单图像基准 MME-RealWorld 和多视图图像基准 DriveLM 上均取得强劲表现,准确捕捉个体行为意图并有效建模多智能体间的复杂交互。
驾驶规划能力
在所有面向规划的基准测试中均表现突出。这种持续的优越性充分说明,模型不仅能生成准确、符合情境的驾驶决策,还能产生与现实世界交通逻辑和驾驶规范相符的连贯、可解释的推理过程。
💪 真实世界场景验证:从仿真到实战
具身导航与操作
团队在具身导航和操作两个基础下游应用中验证了模型的实用性。在导航任务中,MiMo-Embodied 在四个家庭导航场景中表现优异:定位卧室中的床、在餐厅找到吸尘器、在书房识别植物、在浴室定位马桶。

在操作任务中,模型展现了出色的可供性预测和空间推理整合能力,在识别粉色勺子的可抓取把手、定位底排橙子之间的中间放置位置、选择最左侧面包等功能导向任务中均表现出色。

自动驾驶轨迹规划
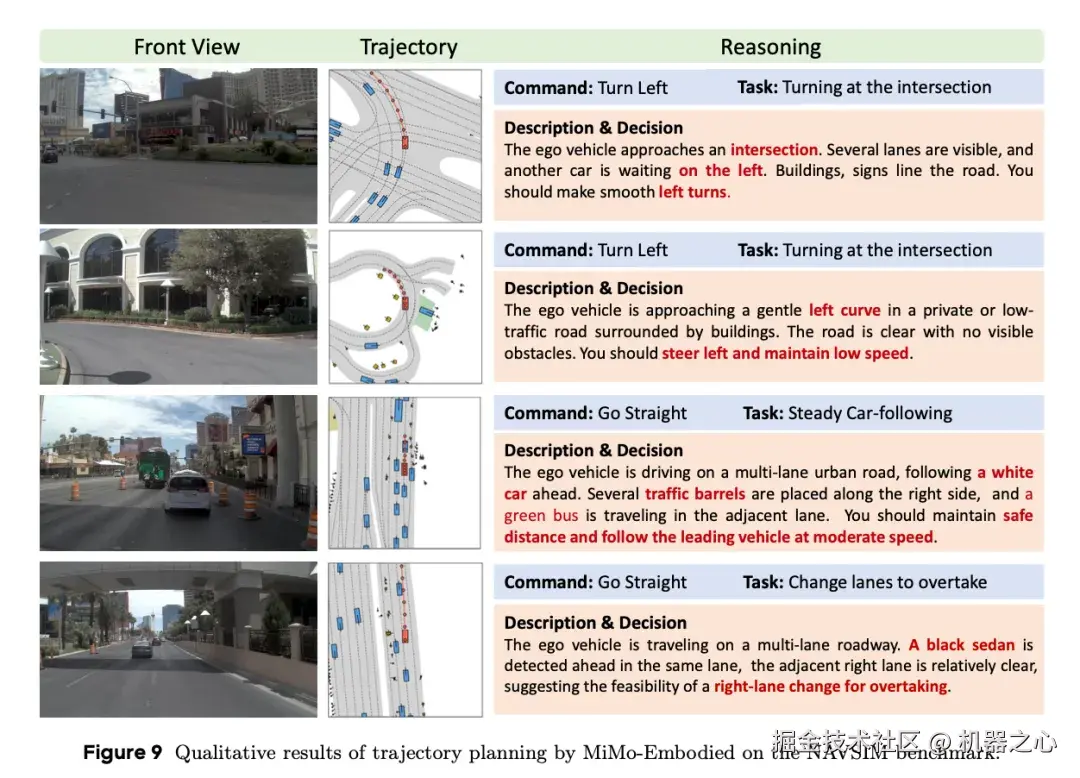
公开基准表现。在 NAVSIM 基准上,MiMo-Embodied 显著超越竞争模型,在模仿学习(IL)阶段和强化学习(RL)阶段均取得最优性能。
定性结果表明,MiMo-Embodied 能够处理多样化的自动驾驶场景并完成具有挑战性的任务,包括路口转弯、弯道掉头、跟车和变道超车。
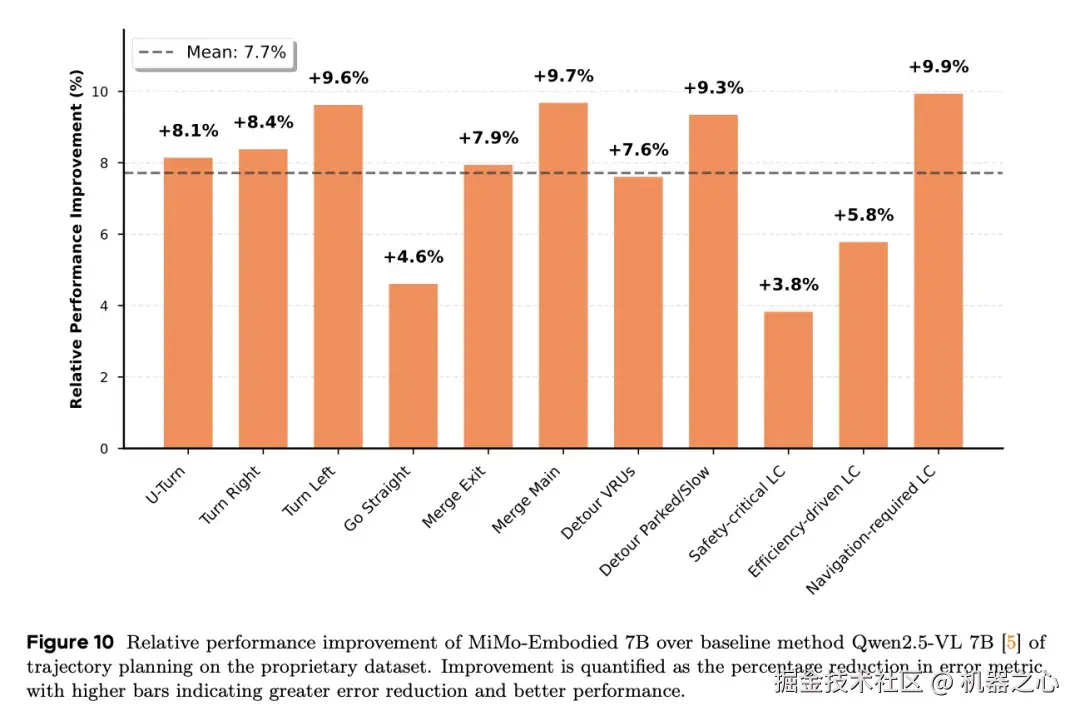
专有数据集验证。在大规模专有数据集上的评估显示,MiMo-Embodied 在所有评估类别中均显著超越基线。特别值得注意的是,在复杂的交互任务(如转弯、绕障和变道)中性能提升最为显著。
这种在高复杂度场景中的大幅改进,有力证明了具身训练范式赋予模型在复杂驾驶情境中更强的推理能力,并转化为更准确、更符合人类专家驾驶行为的轨迹生成。
🔬 消融实验:多阶段策略的关键作用
为验证多阶段训练策略的有效性,团队进行了系统性消融实验。结果显示:
-
仅使用具身数据训练的模型在两个领域均表现强劲,但仅使用自动驾驶数据训练的模型在具身任务上性能显著下降
-
直接混合训练两个领域的数据,具身任务有所改进,但自动驾驶性能略有下降
-
采用多阶段训练策略的 MiMo-Embodied 在具身任务上平均达到62.4%(相比混合训练提升4%),在自动驾驶任务上达到最优的63.3%(相比混合训练提升8.1%)
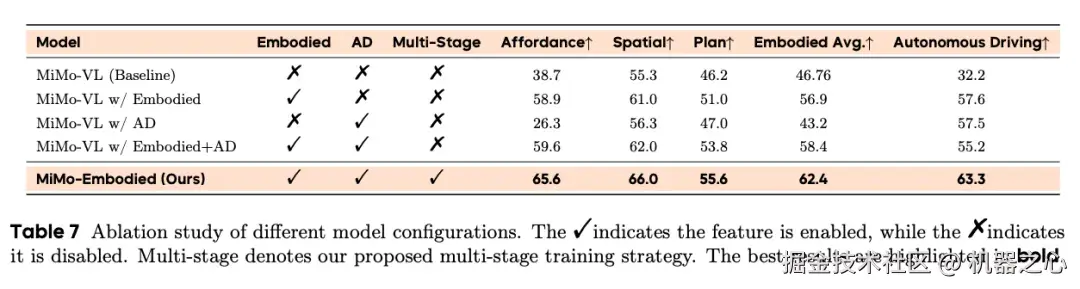
这充分证明,多阶段训练策略能够在不牺牲单一任务性能的前提下,实现具身智能和自动驾驶能力的协同提升,为构建统一的具身基座模型提供了有效的训练范式。
结语
MiMo-Embodied 的出现,标志着具身智能研究进入了一个新的阶段。
它证明了物理世界的认知逻辑是统一的------无论是控制机器人还是驾驶汽车,都依赖于对三维空间、因果关系及行为预测的深刻理解。小米具身智能团队通过构建统一的跨域基座模型,成功打破了长期以来的领域壁垒,让数据在不同具身形态间产生了"化学反应"。
这项工作不仅为构建通用的 VLA(Vision-Language-Action) 模型提供了基础,也让"一个大脑,通用于百变机身"的未来愿景变得触手可及。