从11%到53%!双LLM驱动的工业级代码修复方案,Google数据集验证有效
论文信息
- 论文原标题:Abstain and Validate: A Dual-LLM Policy for Reducing Noise in Agentic Program Repair
- 主要作者及研究机构:Google Research团队(数据集与实验均基于Google内部代码库) José Cambronero1, Michele Tufano1, Sherry Shi1, Renyao Wei1, Grant Uy1, Runxiang Cheng1, Chin-Jung Liu1, Shiying Pan1, Pat Rondon1, Satish Chandra2 ∗
- 引文格式(APA):Google Research Team. (2025). Dual-LLM Strategies for Reducing Noise in Industrial Agentic Automated Program Repair. arXiv preprint arXiv:2510.03217.
- 论文链接:https://arxiv.org/pdf/2510.03217
一段话总结
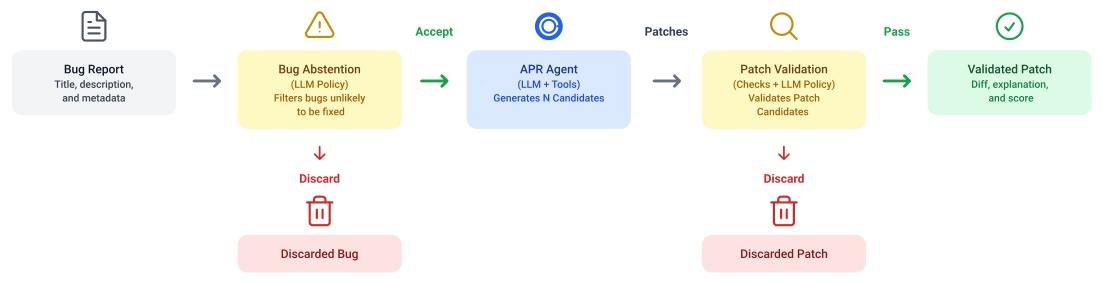
为解决工业界"代码自动修复(APR)系统生成的补丁需人工审核,但无效方案太多、浪费开发者时间"的核心痛点,Google研究团队提出双LLM策略:修复前用"Bug规避"筛选APR难以处理的bug,修复后用"补丁验证"剔除无效补丁。在Google三类数据集(174个人工报告bug、198个机器NPE bug、50个sanitizer机器bug)上测试显示,双策略结合后,人工bug的审核成功率从11%飙升至53%,机器NPE bug的有效补丁率从38%升至62%,且假阳性率低至0.04,为工业级APR系统的落地提供了轻量、可复制的解决方案。
思维导图

研究背景:从"实验室成功"到"工业落地"的鸿沟
想象你是一名程序员:遇到代码bug时,打开"自动修复助手"(APR系统),它一次给你10个补丁,但8个要么编译失败,要么没解决根本问题------你得一个个检查,半小时过去还在做"无用功"。这就是工业界使用Agentic APR系统的真实困境。
近年来,基于大语言模型(LLM)的Agentic APR系统 (如SWEAgent、AutoCodeRover)已经很"厉害":在实验室的SWE-Bench-Verified基准上,"一次修复成功"(pass@1)的概率最高能到75.2%。但到了实际生产中,这些系统面临一个致命问题:噪声太多。
具体来说,工业场景需要"人工审核补丁"才能最终上线,但系统会做两件"浪费时间的事":
- 对着"根本修不好的bug"反复生成补丁(比如bug描述模糊、需要修改核心架构);
- 生成大量"看似能跑但没解决问题"的无效补丁。
这不仅浪费服务器的计算资源,更让开发者对自动化工具失去信任------毕竟,没人愿意把时间花在"看助手瞎忙活"上。而这篇论文,就是要填补"实验室高成功率"与"工业级高可用性"之间的鸿沟。
创新点:双LLM策略的"漏斗式控噪"
这篇论文的核心创新,在于提出"修复前+修复后"的双阶段LLM筛选策略,像两个"漏斗"一样层层过滤噪声,且每个策略都有独特设计:
-
创新1:修复前的"轻量Bug规避"------不碰代码库也能筛bug
传统方案要判断bug是否可修,往往需要读取整个代码库,复杂且耗时。而本研究的Bug规避策略仅用bug报告(标题、描述、元数据) 就能判断:通过加入"5条人工提炼的可修复性准则"(如"问题描述清晰""修复动作明确""只需局部修改"),让LLM精准识别"APR能搞定的bug",提前过滤78%的"难修bug",从源头减少无效修复尝试。
-
创新2:修复后的"有规范补丁验证"------让LLM判断有"标准"
以往补丁验证要么只看"编译是否通过",要么让LLM凭感觉判断,容易误判。本研究引入"修复规范(fix specification) ":让LLM先基于bug信息和原始代码,写一份"修复说明书"(含问题诊断、正确修复该有的特征),再结合补丁和测试结果判断------相当于给LLM一个"判断标准",大幅降低假阳性率(仅0.04)。
-
创新3:双策略互补------1+1>2的控噪效果
Bug规避解决"修之前选对问题",补丁验证解决"修之后选对方案",二者形成"双重漏斗"。单独用Bug规避能让成功率从11%升至21%,单独用补丁验证能升至29%,而结合后最高能到53%,效果远超单一策略。
研究方法与实验设计:把复杂问题拆成"可落地步骤"
一、双LLM策略的详细步骤
1. Bug规避策略(修复前执行)
三步完成"轻量筛选",全程不访问代码库:
- 步骤1:收集输入:仅提取bug报告的核心信息(标题、描述、所属模块等元数据);
- 步骤2:选择bug表示方案:推荐用"r2方案"(bug信息 + Agent工具能力 + 5条可修复性准则),比仅用bug信息的"r1方案"预测更准;
- 步骤3:LLM预测与决策:用Gemini 2.0 Flash预测该bug的修复成功率,若≥0.5(默认阈值)则保留,否则直接规避(不启动修复流程)。
2. 补丁验证策略(修复后执行)
三阶段完成"精准过滤",层层淘汰无效补丁:
- 阶段1:前置基础过滤:先踢掉"编译失败"或"复现测试不过"的补丁(比如bug复现用的测试用例,修复后仍失败的直接排除);
- 阶段2:生成修复规范:用Gemini 2.5 Pro基于"bug信息 + 原始代码(Agent修改的文件)",生成一份"修复说明书",明确"这个bug该解决什么问题""正确的修复应该满足哪些条件";
- 阶段3:LLM判断与筛选:LLM结合"补丁内容 + 测试结果 + 修复规范",输出"是否有效"和"置信度得分",再按75分位(宽松)或90分位(严格)的阈值筛选------90分位更严格,能进一步提升成功率。
二、实验设计:用工业数据验证效果
为了确保方案能落地,研究选择了Google内部的三类真实工业数据集,覆盖"人工报告"和"机器自动发现"的bug:
| 数据集类型 | 数量 | 来源与特点 | 用于验证的策略 | 成功判断标准 |
|---|---|---|---|---|
| 人工报告bug | 174 | Google单仓库,有真值修复和复现测试 | Bug规避+补丁验证 | 通过"隐藏的复现测试"(修复前失败、后成功) |
| NPE机器bug | 198 | 实时部署系统,自动捕获的空指针错误 | 仅补丁验证 | 代码所有者确认有效 / 人工检查正确 |
| Sanitizer机器bug | 50 | 含内存错误、数据竞争,有真值修复 | 仅补丁验证 | 补丁与真值修复语义等价 |
关键实验指标 :filtered-success@k------即"经过策略筛选后,保留的bug/补丁中,随机选k个(k=1时为'一次修复')能成功的概率",直接反映"人工审核的效率"。
研究问题(RQ):围绕核心效果设计4个问题,逐一验证:
- RQ1:Bug规避策略单独使用时,能否提升筛选后成功率?
- RQ2:补丁验证策略单独使用时,效果如何?
- RQ3:双策略结合后,是否能实现"1+1>2"?
- RQ4:补丁验证策略在机器自动发现的bug上,是否同样有效?
主要成果:用数据说话,效果看得见
研究通过4个RQ的验证,得出了清晰、可落地的结果,核心成果用表格总结如下:
| 研究问题(RQ) | 测试对象 | 核心方案 | 筛选后成功率(filtered-success@1) | 对比基线提升 | 关键结论 |
|---|---|---|---|---|---|
| RQ1 | 人工报告bug | 单独Bug规避(r2) | 21.05% | +9.76个百分点(基线11.29%) | 仅用bug报告就能有效筛bug |
| RQ2 | 人工报告bug | 单独补丁验证(90分位) | 29% | +15个百分点(基线14%) | 有规范的验证比基础过滤好 |
| RQ3 | 人工报告bug | 双策略结合(90分位) | 53% | +42个百分点(基线11%) | 双重漏斗效果远超单一策略 |
| RQ4 | NPE机器bug | 补丁验证(90分位) | 62% | +24个百分点(基线38%) | 对机器bug适应性同样强 |
| RQ4 | Sanitizer机器bug | 补丁验证(90分位) | 65% | +15个百分点(基线50%) | 覆盖内存错误等复杂场景 |
这些成果的工业价值是什么?
- 省时间:开发者不用再审核无效补丁------比如人工bug场景,原本要审核174个bug的补丁,筛选后仅需看12个,成功率就达53%,效率提升14倍;
- 省资源:Bug规避提前过滤78%的难修bug,Agent不用白跑修复流程,减少服务器计算成本;
- 建信任:高成功率让开发者愿意用APR工具------当工具给出的补丁"一半以上能成"时,自然会愿意依赖它,推动自动化修复落地。
关键问题:问答形式拆解核心疑问
1. 为什么双策略结合后,效果会比单独用强这么多?
因为二者"分工完全不重叠":Bug规避在修复前 解决"挑对要修的问题"(排除APR搞不定的bug),避免Agent做无用功;补丁验证在修复后解决"挑对修好的方案"(排除看似有效实则无效的补丁),减少人工审核量。相当于先"选对靶子",再"选对子弹",双重过滤自然比单一步骤更精准,成功率从21%(单规避)、29%(单验证)飙升到53%。
2. Bug规避的"r2方案"比"r1方案"好在哪?普通人能复制这个设计吗?
r2比r1多了"5条人工总结的可修复性准则"(比如"bug描述里要能明确代码修改的大致位置""修复不需要改动多个模块"),这些准则来自对50个"APR成功修复案例"的手动分析,本质是"告诉LLM该关注哪些特征"。正因为有了这些准则,r2的预测分布与真实成功率的偏差(Wasserstein距离)从0.363降到0.126,精准度提升2倍。
普通人完全能复制:不用改LLM逻辑,只需从自己项目的"成功修复bug"里提炼类似准则(比如"我们团队的APR擅长修语法错误,不擅长修架构问题"),就能提升筛选效果。
3. 这个方案会误判"有效补丁"为无效吗?如何控制假阳性?
假阳性率很低,仅0.04(100个有效补丁里只误判4个),控制方法有两个:
- 先做"前置过滤":把"编译失败""测试不过"的明显无效补丁先踢掉,减少LLM判断的基础噪声;
- 引入"修复规范":让LLM判断时有明确的"标准"(比如"修复规范要求'避免空指针',补丁做到了就有效"),不是凭感觉下结论,自然减少误判。
4. 这个方案依赖特定LLM(Gemini),换其他LLM(比如GPT-4)能用吗?
理论上能。研究选择Gemini是因为实验在Google内部进行,但方案的核心逻辑(bug规避用"报告+准则"、补丁验证用"修复规范")不绑定特定LLM。只要换用的LLM能理解bug报告、生成修复规范,就能复用这套策略------比如用GPT-4替代Gemini,可能需要微调阈值(比如把0.5调整为0.6),但核心效果不会大幅变化。
详细探究
一、研究背景与核心问题
- Agentic APR的发展现状 :
基于大语言模型(LLM)的Agentic APR系统 (如SWEAgent、AutoCodeRover、RepairAgent)已能处理"仓库级"复杂bug,在SWE-Bench-Verified等基准上的pass@1(单次修复成功)率最高达75.2%(截至2025年9月)。 - 工业界核心痛点 :
工业部署中,APR生成的补丁需人工审核确认,但大量"不可能修复成功的bug"或"无效补丁"(噪声)会浪费开发者时间,并降低对自动化工具的信任------这是阻碍Agentic APR大规模应用的关键障碍。
二、核心双LLM策略设计
(1)Bug Abstention(Bug规避策略)
- 定义:修复流程启动前,基于LLM预测APR系统修复该bug的成功率,筛选出"成功率低于阈值"的bug,避免无效修复尝试。
- 核心约束 :仅使用bug报告信息(标题、描述、元数据),不访问代码库(避免策略复杂化,保证效率)。
- 技术细节 :
-
概率建模:用LLM预测bug修复成功的概率(P_a(b)),通过阈值(\tau)(默认(\tau=0.5))决策:若(P_a(b) \geq \tau)则执行修复,否则规避。
-
Bug表示方案 (两种对比):
表示方案 输入内容 效果(Wasserstein距离,越小越优) r1 bug标题+描述+Agent工具能力(如code_search、bazel测试) 0.363 r2(推荐) r1 + 5条人工提炼的判断准则(如"问题与修复动作清晰""代码定位精确") 0.126 -
关键结果:r2方案的预测分布更贴合"实证成功率"(多数bug实证成功率集中在0-15%),假阳性率仅16.5%。
-
(2)Patch Validation(补丁验证策略)
-
定义:修复流程结束后(Agent生成trajectory/patch后),通过多阶段流程判断补丁是否为有效修复,剔除噪声补丁。
-
多阶段流程 :
- 前置过滤:剔除"编译失败"或"复现测试失败"的补丁(若有复现测试则优先用复现测试过滤);
- Fix Specification生成:LLM基于"bug信息+原始代码(Agent修改的文件)"生成修复规范(无真值依赖,包含"问题诊断+正确修复的预期属性");
- LLM判断:LLM结合"bug信息+补丁(unified-diff格式)+测试结果+fix specification",输出"是否正确(布尔值)+自然语言解释+置信度得分"(得分=正判断时token日志概率的指数平均,负判断时为0)。
-
决策方式 (两种对比):
决策方式 逻辑 关键效果(人工报告bug集filtered-fail-to-pass@1) Binary 基于LLM的布尔判断,仅接受"正确"补丁 0.16(较基线build-and-test的0.14提升2个百分点) Percentile 基于所有补丁的置信度得分分位值(75th/90th),接受得分≥分位值的补丁 75th:0.21(提升7个百分点);90th:0.29(提升15个百分点)
三、实验设计与关键参数
(1)数据集详情(核心信息来自Table 1)
| 数据集类型 | 描述 | 数量 | 适用策略 | 成功判断标准 |
|---|---|---|---|---|
| 人工报告bug | 有真值修复、复现测试,来自Google单仓库 | 174 | Bug Abstention + Patch Validation | 通过"held-out复现测试"(修复前失败、修复后成功) |
| NPE机器bug | 来自实时部署的开源bug,含堆栈信息 | 198 | 仅Patch Validation | 代码所有者确认正确 / 人工检查正确 |
| Sanitizer机器bug | 含真值修复、复现测试,覆盖内存错误、数据竞争等 | 50 | 仅Patch Validation | 人工对比补丁与真值修复的语义等价性 |
(2)关键实验配置
- Agent系统:ReAct-style循环,支持5类工具(code_search、cat、ls、find_and_replace_text、bazel),trajectory步数上限25(人工报告bug:20条trajectory/ bug;NPE bug:5条trajectory/bug);
- LLM选择:Bug Abstention用Gemini 2.0 Flash,Patch Validation用Gemini 2.5 Pro,均为贪心解码(temperature=0);
- 核心指标:filtered-success@k(仅统计策略"允许"的bug/补丁的成功率,公式含义:在筛选后的bug集中,随机选k个补丁,至少1个成功的期望概率)。
四、实验结果(按RQ划分)
(1)RQ1:Bug Abstention的有效性
- 基线(无规避):人工报告bug集fail-to-pass@1=11.29%;
- r1规避:filtered-fail-to-pass@1=16.81%(提升5.52个百分点);
- r2规避(推荐):filtered-fail-to-pass@1=21.05%(提升9.76个百分点),且当k=20时,filtered-fail-to-pass@20从基线27.01%升至44.74%(提升17.73个百分点)。
(2)RQ2:Patch Validation的有效性
- 基线(仅build-and-test过滤):filtered-fail-to-pass@1=0.14;
- 无规范验证(no-spec):90th分位下filtered-fail-to-pass@1=0.22(提升8个百分点);
- 有规范验证(spec-based,推荐):90th分位下filtered-fail-to-pass@1=0.29(提升15个百分点),假阳性率低至0.04(较no-spec的0.06更低)。
(3)RQ3:双策略结合的有效性
-
结合逻辑:先通过r2规避策略筛选bug(τ=0.5),再通过spec-based验证策略筛选补丁;
-
关键结果(人工报告bug集filtered-fail-to-pass@1):
策略组合 筛选后bug数量 filtered-fail-to-pass@1 相对基线提升 无策略(基线) 174 0.11 - 仅r2规避 39 0.215 +10.5个百分点 规避+binary验证 33 0.29 +18个百分点 规避+75th验证 25 0.35 +24个百分点 规避+90th验证(严格) 12 0.53 +42个百分点
(4)RQ4:机器bug上的Patch Validation效果
- NPE bug集:基线(build-and-test)filtered-accept@1=0.38;90th分位spec-based验证后升至0.62(提升24个百分点);
- Sanitizer bug集:基线(repro-test过滤)filtered-accept@1=0.5;90th分位验证后最高提升15个百分点,且k=1时no-spec验证(0.65)略优于spec-based验证(0.62)。
五、研究贡献与局限
(1)核心贡献
- 提出Bug Abstention策略,为Agentic APR系统筛选"适合修复"的bug;
- 提出多阶段Patch Validation策略,通过"修复规范+LLM判断"提升补丁筛选精度;
- 在三类工业级数据集上完成大规模评估,验证双策略的有效性与互补性。
(2)主要局限
- 数据集仅来自Google代码库,可能受内部开发流程、bug报告风格影响,泛化性需验证;
- 人工验证补丁正确性时,可能与实际代码所有者的判断存在偏差;
- 实验依赖特定LLM版本(Gemini 2.0 Flash/2.5 Pro),新LLM可能带来性能变化。
4. 关键问题与答案
问题1:Bug Abstention与Patch Validation为何能形成"互补效应"?二者在信息利用和执行时机上的核心差异是什么?
答案:二者的互补性源于"执行时机+信息利用范围"的差异:
- 执行时机:Bug Abstention在修复流程启动前执行 ,目的是"提前排除APR系统无法修复的bug",避免无效修复尝试的计算成本;Patch Validation在修复流程结束后执行,目的是"剔除Agent已生成但无效的补丁",减少人工审核噪声;
- 信息利用:Bug Abstention仅依赖bug报告信息 (标题、描述、元数据),不访问代码库,无法获取"修复轨迹、代码修改内容";而Patch Validation除bug报告外,还利用Agent的修复轨迹、原始代码、测试结果 ,并通过LLM生成"修复规范(fix specification)",能更精准判断补丁与bug的匹配度。
这种"前筛选+后过滤"的漏斗模式,使二者结合后能同时减少"无效bug的修复尝试"和"无效补丁的审核成本",最终实现成功率的大幅提升(如人工报告bug集上结合后最高提升39个百分点)。
问题2:在Bug Abstention的两种表示方案(r1与r2)中,r2为何能显著优于r1?其设计背后的逻辑是什么?
答案 :r2优于r1的核心原因是加入了"人工提炼的判断准则",使LLM的预测更贴合"Agentic APR系统的实际修复能力":
- r1的局限:仅输入"bug报告+Agent工具能力",LLM缺乏"判断bug可修复性的明确依据",导致预测分布较均匀(与"多数bug实证成功率集中在0-15%"的实际情况偏离较大),Wasserstein距离达0.363;
- r2的优化:在r1基础上加入5条人工总结的"可修复性判断准则"(如"问题与修复动作清晰""代码定位精确""预期修复是局部小改动"等),这些准则来自对50个人工报告bug的手动分析,直接对应"Agent能成功修复的bug特征";
- 效果体现:r2的预测分布与实证成功率分布的Wasserstein距离降至0.126(仅为r1的1/3),filtered-fail-to-pass@1从r1的16.81%升至21.05%,证明准则的加入让LLM更精准识别"高可修复性bug"。
问题3:该双策略对"工业级Agentic APR系统部署"的核心价值是什么?能否解决现有工业应用中的关键痛点?
答案 :该双策略的核心价值是平衡"修复效率"与"审核成本",直接解决工业应用中"噪声过多、开发者信任不足"的关键痛点,具体体现在三方面:
- 降低审核成本:通过筛选,开发者无需审核"不可能正确的补丁"------如严格配置下(combined-p90),人工报告bug的审核成功率达53%(1/2概率正确),较基线(11.29%)提升近5倍,大幅减少无效审核时间;
- 节省计算资源:Bug Abstention提前排除"难以修复的bug"(如r2策略可过滤约78%的低成功率bug),避免Agent为这类bug生成大量无效trajectory,降低计算开销;
- 建立工具信任:高成功率的筛选结果能提升开发者对自动化工具的信任------工业界研究显示(文档参考文献4,24),AI工具的信任度直接依赖"有效输出比例",该策略使APR系统从"低成功率噪声源"转变为"高可靠性辅助工具",适合大规模部署(如Google实时部署的NPE bug修复场景)。
总结:工业级APR落地的"实用手册"
这篇论文没有追求复杂的算法创新,而是聚焦工业界的"真痛点"------APR系统的噪声过多问题,提出了一套轻量、可落地的双LLM策略。其核心价值在于:
- 用"修复前Bug规避"和"修复后补丁验证"形成双重漏斗,把人工审核成功率从11%提升到53%;
- 策略不依赖复杂的代码库分析,仅用bug报告和基础测试就能运行,企业容易复制;
- 在Google三类工业数据集上验证有效,覆盖人工和机器bug,适应性强。
当然,方案也有局限:数据集仅来自Google,可能受内部开发流程影响;依赖特定LLM版本,换其他模型可能需要微调;人工验证补丁时存在主观偏差。但总体来说,这篇论文为工业级APR系统的落地提供了"实用手册",让"代码自动修复"从实验室的"演示功能",变成了能真正帮开发者省时间的"生产力工具"。