SparseFool: 少数像素带来巨大差异

原文链接:https://arxiv.org/pdf/1811.02248
摘要
深度神经网络在图像分类任务上取得了非凡的成果,但已被证明容易受到经过精心构造的输入数据扰动的攻击。尽管大多数攻击通常会改变图像多个像素的值,但研究表明深度网络也容易受到输入的稀疏修改的影响。然而,目前尚未提出计算稀疏扰动的计算高效方法。在本文中,我们利用决策边界的低平均曲率,提出了 SparseFool,一种受几何启发的稀疏攻击,可以控制扰动的稀疏性。广泛的评估表明,我们的方法能非常快地计算稀疏扰动,并且能高效地扩展到高维数据。我们进一步分析了这些扰动的可转移性和视觉效果,并展示了跨图像和网络存在的共享语义信息。最后,我们表明对抗性训练仅能轻微提高针对使用 SparseFool 计算的稀疏加性扰动的鲁棒性。¹
脚注 1: SparseFool 的代码可在 https://github.com/ITS4/SparseFool 获取,Foolbox 41 可在 https://github.com/bethgelab/foolbox 获取。
1 引言
深度神经网络是强大的学习模型,在许多不同的分类任务中实现了最先进的性能 27, 50, 1, 22, 9,但已被证明对其输入数据的非常微小且通常难以察觉的对抗性操纵具有脆弱性 47。有趣的是,这种对抗性扰动的存在不仅限于加性扰动 21, 12, 49 或分类任务 8,还可以在许多其他应用中找到 48, 7, 28, 31, 39, 42, 43。
对于图像分类任务,最常见的对抗性扰动类型是 ℓ p \ell_{p} ℓp 最小化扰动,因为它们更容易分析和优化。形式上,对于给定的分类器和图像 x ∈ R n \bm{x}\in\mathbb{R}^{n} x∈Rn,我们将最小扰动 r \bm{r} r 定义为改变分类器估计标签 k ( x ) k(\bm{x}) k(x) 的扰动:
min r ∥ r ∥ p s.t. k ( x + r ) ≠ k ( x ) , \min_{\bm{r}}\|\bm{r}\|_{p}\ \ \text{s.t.}\ \ k(\bm{x}+\bm{r})\neq k(\bm{x}), rmin∥r∥p s.t. k(x+r)=k(x),
已经提出了几种方法(攻击)来计算 ℓ 2 \ell_{2} ℓ2 和 ℓ ∞ \ell_{\infty} ℓ∞ 对抗性扰动 47, 15, 24, 33, 6, 32。然而,理解深度神经网络在其他扰动机制下的脆弱性仍然很重要。特别是,研究表明 38, 45, 35, 2, 18,当仅改变输入的一小部分(稀疏扰动)时,DNN 可能会对图像进行错误分类。在实践中,稀疏扰动可能对应于"停止"标志上反射阳光的一些雨滴,但这足以欺骗自动驾驶汽车;或者一片带有一些稀疏彩色花朵的农田,迫使无人机在未受影响的区域喷洒农药。理解深度网络对这种简单扰动机制的脆弱性可以进一步帮助设计提高深度分类器鲁棒性的方法。
最近已经开展了一些关于稀疏扰动的先前工作。文献 38 的作者提出了 JSMA
方法,该方法根据像素的显著性分数进行扰动。此外,文献 45 的作者利用进化算法实现极其稀疏的扰动,而文献 35 的作者最终提出了一种黑盒攻击,使用贪婪局部搜索算法计算稀疏对抗性扰动。
然而,在 ℓ 0 \ell_{0} ℓ0 意义上求解方程 (1) 中的优化问题是 NP 难的,并且当前算法都具有高复杂度的特点。产生的扰动通常包含高幅度噪声,集中在少量像素上。这使得它们相当明显,并且在许多情况下,扰动的像素甚至可能超出图像的动态范围。
因此,我们在本文中提出了一种高效且原则性的方法来计算稀疏扰动,同时确保扰动像素的有效性。
我们的主要贡献如下:
- 我们提出了 SparseFool,一种受几何启发的稀疏攻击,它利用边界的低平均曲率来高效计算对抗性扰动。
- 我们通过广泛的评估表明:(a) 我们的方法计算稀疏扰动的速度比现有方法快得多,并且 (b) 它可以高效地扩展到高维数据。
- 我们进一步提出了一种方法来控制所产生扰动的可感知性,同时保持稀疏性和复杂性的水平。
- 我们分析了受我们攻击影响的视觉特征,并展示了跨不同图像和网络存在的一些共享语义信息。
- 我们最终表明,使用 ℓ ∞ \ell_{\infty} ℓ∞ 扰动进行对抗性训练仅能略微降低对稀疏扰动的脆弱性,但尚不足以产生更鲁棒的分类器。
本文的其余部分组织如下:在第 2 节中,我们描述了计算稀疏对抗性扰动的挑战和问题。在第 3 节中,我们通过线性化并求解初始优化问题,提供了一种计算稀疏对抗性扰动的高效方法。最后,第 4 节提供了对所计算的稀疏扰动的评估和分析。

图 1: ImageNet 的对抗性示例,由 SparseFool 在 ResNet-101 架构上计算得出。每列对应不同水平的扰动像素。被欺骗的标签显示在图像下方。
2 问题描述
2.1 寻找稀疏扰动
大多数现有的对抗性攻击算法求解方程 (1) 中 p = 2 p=2 p=2 或 ∞ \infty ∞ 的优化问题,从而产生密集但难以察觉的扰动。对于稀疏扰动的情况,目标是最小化欺骗网络所需扰动的像素数量,这对应于最小化方程 (1) 中的 ∥ r ∥ 0 \|{\bm{r}}\|{0} ∥r∥0。不幸的是,这导致了 NP 难问题,通常无法保证达到全局最小值 40, 37, 3。存在不同的方法 40, 34 来避免此问题的计算负担,其中 ℓ 1 \ell{1} ℓ1 松弛是最常见的;在线性约束下最小化 ∥ r ∥ 0 \|{\bm{r}}\|{0} ∥r∥0 可以通过求解相应的凸 ℓ 1 \ell{1} ℓ1 问题来近似 5, 36, 10。² 因此,我们正在寻找一种有效的方法来利用这种松弛来求解方程 (1) 中的优化问题。
脚注 2: 在某些条件下,这种近似的解确实是最优的 16, 11, 4。
DeepFool 33 是一种利用这种松弛的算法,它采用迭代过程,包括在每次迭代时对分类器进行线性化,以估计最小对抗性扰动 r {\bm{r}} r。具体来说,假设 f f f 是一个分类器,在每次迭代 i i i 时, f f f 在当前点 x ( i ) {\bm{x}}^{(i)} x(i) 附近被线性化,最小扰动 r ( i ) {\bm{r}}^{(i)} r(i)(在 ℓ 2 \ell_{2} ℓ2 意义上)被计算为 x ( i ) {\bm{x}}^{(i)} x(i) 在线性化超平面上的投影,并更新下一个迭代点 x ( i + 1 ) {\bm{x}}^{(i+1)} x(i+1)。可以使用这种线性化过程来求解方程 (1) 中 p = 1 p=1 p=1 的情况,从而获得 ℓ 0 \ell_{0} ℓ0 解的近似值。因此,通过将投影推广到 ℓ p \ell_{p} ℓp 范数 ( p ∈ [ 1 , ∞ ) p\in[1,\infty) p∈[1,∞)) 并设置 p = 1 p=1 p=1, ℓ 1 \ell_{1} ℓ1-DeepFool 提供了一种使用 ℓ 1 \ell_{1} ℓ1 投影计算稀疏对抗性扰动的有效方法。
2.2 扰动的有效性
尽管 ℓ 1 \ell_{1} ℓ1-DeepFool 能高效计算稀疏扰动,但它没有明确考虑对抗性图像值有效性的约束。在计算对抗性扰动时,确保对抗性图像 x + r {\bm{x}}+{\bm{r}} x+r 的像素值位于彩色图像的有效范围内(例如, 0 , 255 0,255 0,255)非常重要。对于 ℓ 2 \ell_{2} ℓ2 和 ℓ ∞ \ell_{\infty} ℓ∞ 扰动,图像的几乎所有像素都被小幅度噪声扭曲,因此最常见的算法通常忽略此类约束 33, 15。在这种情况下,许多像素不太可能超出其有效范围;即使如此,在计算此类对抗性图像后裁剪无效值的影响也很小。
然而,不幸的是,对于稀疏扰动来说,情况并非如此;求解 ℓ 1 \ell_{1} ℓ1 优化问题会导致少数像素被高幅度噪声扭曲,并且在计算对抗性图像后裁剪值可能会对攻击的成功产生重大影响。换句话说,随着扰动变得越稀疏,每个像素的贡献通常比 ℓ 2 \ell_{2} ℓ2 或 ℓ ∞ \ell_{\infty} ℓ∞ 扰动强得多。
我们演示了这种裁剪操作对 ℓ 1 \ell_{1} ℓ1-DeepFool 生成的对抗性扰动质量的影响。例如,对于在 ImageNet 9 上训练的 VGG-16 44 网络计算的扰动,我们观
察到 ℓ 1 \ell_{1} ℓ1-DeepFool 通过平均仅扰动 0.037 % 0.037\% 0.037% 的像素实现了几乎 100 % 100\% 100% 的欺骗率。然而,将对抗性图像的像素值裁剪到 0 , 255 0,255 0,255 会导致欺骗率仅为 13 % 13\% 13%。此外,将裁剪操作符纳入算法的迭代过程中并不能改善结果。换句话说, ℓ 1 \ell_{1} ℓ1-DeepFool 未能正确计算稀疏扰动。这突显了需要一种改进的攻击算法,该算法能自然地考虑生成的对抗性图像的有效性,如下一节所提出的。
2.3 问题表述
基于上述讨论,稀疏对抗性扰动通过求解以下一般形式的优化问题获得:
minimize r ∥ r ∥ 1 subject to k ( x + r ) ≠ k ( x ) l ≼ x + r ≼ u , \begin{array}{ll} \underset{\bm{r}}{\text{minimize}} & \|\bm{r}\|_{1} \\ \text{subject to} & k(\bm{x}+\bm{r}) \neq k(\bm{x}) \\ & \bm{l} \preccurlyeq \bm{x} + \bm{r} \preccurlyeq \bm{u}, \end{array} rminimizesubject to∥r∥1k(x+r)=k(x)l≼x+r≼u,
其中 l , u ∈ R n \bm{l},\bm{u}\in\mathbb{R}^{n} l,u∈Rn 表示 x + r \bm{x}+\bm{r} x+r 值的下限和上限,使得 l i ≤ x i + r i ≤ u i , i = 1 ... n l_{i}\leq x_{i}+r_{i}\leq u_{i}, ~~i=1\dots n li≤xi+ri≤ui, i=1...n。
为了找到问题 (2) 的有效松弛,我们关注决策边界的几何特征,特别是其曲率。研究表明 13, 14, 20,最先进的深度网络的决策边界在数据样本邻域内具有相当低的平均曲率。换句话说,对于数据点 x \bm{x} x 及其相应的最小 ℓ 2 \ell_{2} ℓ2 对抗性扰动 v \bm{v} v,在 x \bm{x} x 附近的决策边界可以通过穿过数据点 x B = x + v \bm{x}_{B}=\bm{x}+\bm{v} xB=x+v 且具有法向量 w \bm{w} w 的超平面进行局部良好近似(见图 2)。
因此,我们利用这一特性并线性化优化问题 (2),从而可以通过求解以下框约束优化问题来计算稀疏对抗性扰动:
minimize r ∥ r ∥ 1 subject to w T ( x + r ) − w T x B = 0 l ≼ x + r ≼ u . \begin{array}{ll} \underset{\bm{r}}{\text{minimize}} & \|\bm{r}\|{1} \\ \text{subject to} & \bm{w}^{T}(\bm{x}+\bm{r})-\bm{w}^{T}\bm{x}{B}=0 \\ & \bm{l} \preccurlyeq \bm{x} + \bm{r} \preccurlyeq \bm{u}. \end{array} rminimizesubject to∥r∥1wT(x+r)−wTxB=0l≼x+r≼u.
在下一节中,我们提供了一种求解优化问题 (3) 的方法,并介绍了 SparseFool,一种快速而高效的计算稀疏对抗性扰动的算法,它通过将决策边界近似为仿射超平面来线性化约束。
3 稀疏对抗性扰动
3.1 线性化问题求解
在求解优化问题 (3) 时,将 x \bm{x} x 投影到近似超平面上的 ℓ 1 \ell_{1} ℓ1 投影计算不能保证得到解。对于一个扰动图像,考虑其某些值超出由 l \bm{l} l 和 u \bm{u} u 定义的边界的情况。因此,通过重新调整无效值以满足约束条件,所产生的对抗性图像最终可能不会位于近似超平面上。
出于这个原因,我们提出了一种迭代过程,在每次迭代中,我们只朝着法向量 w \bm{w} w 的一个坐标方向投影。如果朝着特定方向投影 x \bm{x} x 不能提供解,那么该坐标处的扰动图像已达到其极值。因此,在下次迭代中,应忽略该方向,因为它无法再为找到更好的解做出贡献。
形式上,令 S S S 是一个包含所有 w \bm{w} w 中不能为最小扰动做出贡献的方向的集合。然后,
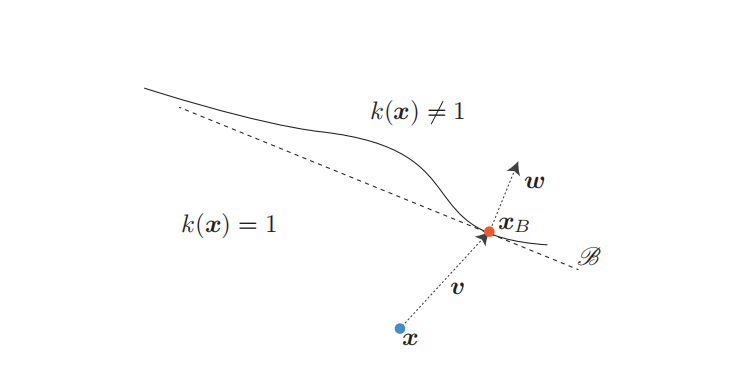
图 2: 属于类别 1 的数据点 x \bm{x} x 附近的近似决策边界 B \mathcal{B} B。 B \mathcal{B} B 可以看作是类别 1 的一对多线性分类器。
最小扰动 r \bm{r} r 通过当前数据点 x ( i ) \bm{x}^{(i)} x(i) 在估计超平面上的 ℓ 1 \ell_{1} ℓ1 投影更新为:
r d ← ∣ w T ( x ( i ) − x B ) ∣ ∣ w d ∣ ⋅ sign ( w d ) , r_{d}\leftarrow\frac{|\bm{w}^{T}(\bm{x}^{(i)}-\bm{x}{B})|}{|w{d}|}\cdot\text{sign}(w_{d}), rd←∣wd∣∣wT(x(i)−xB)∣⋅sign(wd),
其中 d d d 是 w \bm{w} w 的绝对值最大且尚未被使用的索引
d ← arg max j ∉ S ∣ w j ∣ . d\leftarrow\arg\max_{j\notin S}|w_{j}|. d←argj∈/Smax∣wj∣.
在进入下一次迭代之前,我们必须确保下一个迭代点 x ( i + 1 ) \bm{x}^{(i+1)} x(i+1) 的值的有效性。为此,我们使用一个投影算子 Q ( ⋅ ) Q(\cdot) Q(⋅),通过将 x ( i ) + r \bm{x}^{(i)}+\bm{r} x(i)+r 投影到由 l \bm{l} l 和 u \bm{u} u 定义的框约束上,来重新调整更新点中超出边界的值。因此,新的迭代点 x ( i + 1 ) \bm{x}^{(i+1)} x(i+1) 更新为 x ( i + 1 ) ← Q ( x ( i ) + r ) \bm{x}^{(i+1)}\gets Q(\bm{x}^{(i)}+\bm{r}) x(i+1)←Q(x(i)+r)。请注意,这里的边界 l \bm{l} l、 u \bm{u} u 不仅限于表示图像的动态范围,而且可以推广以满足任何类似的限制。例如,正如我们将在第 4.2 节中描述的,它们可用于控制所计算的对抗性图像的可感知性。
下一步是检查新的迭代点 x ( i + 1 ) \bm{x}^{(i+1)} x(i+1) 是否已达到近似超平面。否则,这意味着坐标 d d d 处的扰动图像已达到其极值,因此我们无法再进一步改变它;朝着相应方向扰动将没有效果。因此,我们通过将方向 d d d 添加到禁止集 S S S 中来减少搜索空间,并重复该过程直到我们到达近似超平面。求解线性化问题的算法总结在算法 1 中。


3.2 寻找点 x B \bm{x}_{B} xB 和法向量 w \bm{w} w
为了完成我们对优化问题 (3) 的求解,我们现在关注决策边界的线性近似。回顾第 2.3 节,我们需要找到边界点 x B \bm{x}_{B} xB 以及相应的法向量 w \bm{w} w。
寻找 x B \bm{x}{B} xB 类似于计算(在 ℓ 2 \ell{2} ℓ2 意义上) x \bm{x} x 的一个对抗性示例,因此可以通过应用现有的 ℓ 2 \ell_{2} ℓ2 攻击算法之一来近似。然而,并非所有这些攻击都适合我们的任务;我们需要一种快速的方法来找到尽可能接近原始图像 x \bm{x} x 的对抗性示例。回顾 DeepFool 33 迭代地将 x \bm{x} x 移向决策边界,并在扰动数据点到达边界另一侧时立即停止。因此,产生的扰动样本通常非常接近决策边界,因此, x B \bm{x}{B} xB 可以通过 x + r adv \bm{x}+\bm{r}{\text{adv}} x+radv 很好地近似,其中 r adv \bm{r}{\text{adv}} radv 是 x \bm{x} x 对应的 ℓ 2 \ell{2} ℓ2-DeepFool 扰动。然后,如果我们将网络的分类函数表示为 f f f,则可以估计在数据点 x B \bm{x}_{B} xB 处决策边界的法向量为:
w : = ∇ f k ( x B ) ( x B ) − ∇ f k ( x ) ( x B ) . \bm{w}:=\nabla f_{k(\bm{x}{B})}(\bm{x}{B})-\nabla f_{k(\bm{x})}(\bm{x}_{B}). w:=∇fk(xB)(xB)−∇fk(x)(xB).
因此,决策边界现在可以通过仿射超平面 B ≜ { x : w T ( x − x B ) = 0 } \mathcal{B}\triangleq\{\bm{x}:\bm{w}^{T}(\bm{x}-\bm{x}_{B})=0\} B≜{x:wT(x−xB)=0} 来近似,并且通过应用算法 1 来计算稀疏对抗性扰动。
3.3 SparseFool
然而,尽管我们期望有一个一步解,但在许多情况下算法并不收敛。这种行为背后的原因在于网络的决策边界只是局部平坦 的 13, 14, 20。因此,如果 ℓ 1 \ell_{1} ℓ1 扰动将数据点 x \bm{x} x 移出其邻域,那么"局部平坦性"属性
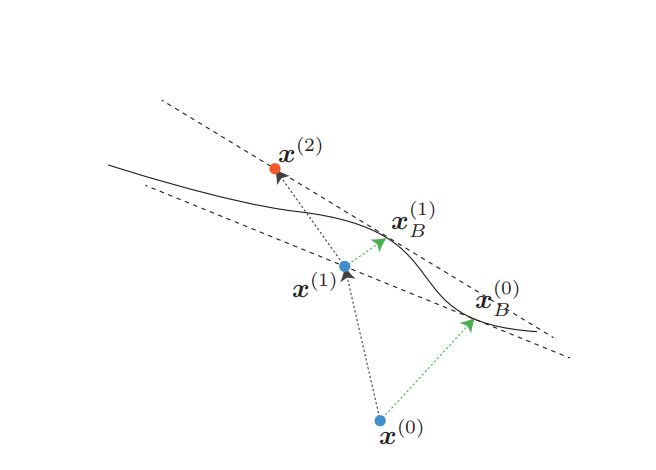
图 3: SparseFool 算法示意图。绿色表示每次迭代计算的 ℓ 2 \ell_{2} ℓ2-DeepFool 对抗性扰动。在此示例中,算法在 2 2 2 次迭代后收敛,总扰动为 r = x ( 2 ) − x ( 0 ) \bm{r}=\bm{x}^{(2)}-\bm{x}^{(0)} r=x(2)−x(0)。
可能会丢失,最终扰动点将无法到达决策边界的另一侧(投影到一个"弯曲"区域)。
我们通过一种迭代方法(即 SparseFool)来缓解收敛问题,每次迭代都包括决策边界的线性近似。具体来说,在迭代 i i i 时,边界点 x B ( i ) \bm{x}{B}^{(i)} xB(i) 和法向量 w ( i ) \bm{w}^{(i)} w(i) 使用基于当前迭代点 x ( i ) \bm{x}^{(i)} x(i) 的 ℓ 2 \ell{2} ℓ2-DeepFool 进行估计。然后,下一个迭代点 x ( i + 1 ) \bm{x}^{(i+1)} x(i+1) 通过算法 1 的解进行更新,但以 x ( i ) \bm{x}^{(i)} x(i) 作为初始点,当 x ( i ) \bm{x}^{(i)} x(i) 改变网络的标签时算法终止。SparseFool 的图示见图 3,算法总结在算法 2 中。
然而,我们观察到,在 SparseFool 的第 6 步中,不使用边界点 x B ( i ) \bm{x}{B}^{(i)} xB(i),而是通过进一步进入边界的另一侧,并找到穿过数据点 x ( i ) + λ ( x B ( i ) − x ( i ) ) \bm{x}^{(i)}+\lambda(\bm{x}{B}^{(i)}-\bm{x}^{(i)}) x(i)+λ(xB(i)−x(i)) 的超平面的解,可以获得更好的收敛(错误分类),其中 λ ≥ 1 \lambda\geq 1 λ≥1。具体来说,如图 4 所示,该参数用于控制欺骗率、稀疏性和复杂性之间的权衡。接近 1 1 1 的值会导致更稀疏的扰动,但也会导致更低的欺骗率和增加的复杂性。相反,较高的 λ \lambda λ 值会导致快速收敛------甚至一步解------但产生的扰动稀疏性较低。由于 λ \lambda λ 是算法的唯一参数,可以轻松调整它以在欺骗率、稀疏性和复杂性方面满足相应的需求。
最后,请注意 B \mathcal{B} B 对应于对抗类别和估计真实类别之间的边界,因此可以将其视为仿射二分类器。由于在每次迭代中,对抗类别被计算为与真实类别最接近(在 ℓ 2 \ell_{2} ℓ2 意义上)的类别,我们可以说 SparseFool 作为非目标攻击运行。尽管如此,它可以轻松转换为目标攻击,只需在每次迭代时计算特定类别的对抗性示例------从而近似其决策边界。
4 实验结果
4.1 设置
我们在深度卷积神经网络架构上测试 SparseFool,使用 MNIST 26 测试集的 10000 10000 10000 张图像、CIFAR-10 23 测试集的 10000 10000 10000 张图像,以及从 ILSVRC2012 验证集中随机选择的 4000 4000 4000 张图像。为了评估我们的算法并与相关工作进行比较,我们计算了欺骗率、中位数扰动百分比和平均执行时间。给定一个数据集 D \mathcal{D} D,欺骗率使用以下公式衡量算法的效率: ∣ x ∈ D : k ( x + r x ) ≠ k ( x ) ∣ / ∣ D ∣ |\bm{x}\in\mathcal{D}:k(\bm{x}+\bm{r}{\bm{x}})\neq k(\bm{x})|/|\mathcal{D}| ∣x∈D:k(x+rx)=k(x)∣/∣D∣,其中 r x \bm{r}{\bm{x}} rx 是对应于图像 x \bm{x} x 的扰动。中位数扰动百分比对应于每个被欺骗样本中扰动像素的中位数百分比,而平均执行时间衡量的是每个样本算法的平均执行时间³。
脚注 3: 所有实验均在 GTX TITAN X GPU 上进行。
我们将 SparseFool 与 JSMA 攻击 38 的实现进行比较。由于 JSMA 是一种目标攻击,我们在其"非目标"版本上进行评估,其中目标类别是随机选择的。我们还在成功条件上做了一个修改;我们不是检查预测类别是否等于目标类别,而是简单地检查它是否与源类别不同。请注意,由于 JSMA 在所有候选对上进行搜索的计算成本巨大 6,我们未在 ImageNet 数据集上对其进行评估。我们还将 SparseFool 与 45 中提出的"单像素攻击"进行比较。由于"单像素攻击"恰好扰动 κ \kappa κ 个像素,对于每张图像,我们从 κ = 1 \kappa=1 κ=1 开始增加,直到"单像素攻击"找到一个对抗性示例。同样,由于高维图像的高计算成本,我们未在 ImageNet 数据集上评估"单像素攻击"。
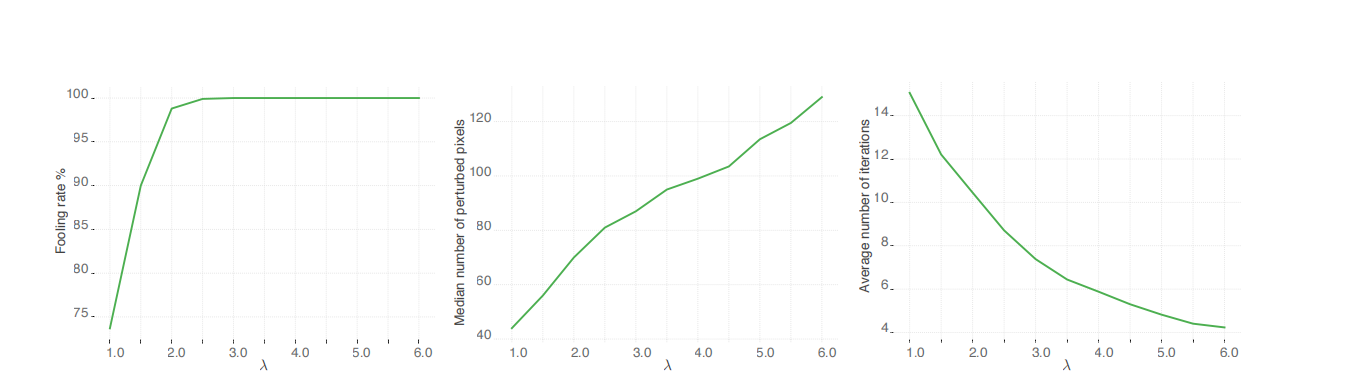
图 4: 对于 ImageNet 数据集上的 4000 4000 4000 张图像使用 Inception-v3 46 模型,SparseFool 在不同 λ \lambda λ 值下的欺骗率、扰动稀疏度和平均迭代次数。
4.2 结果
整体性能 。我们首先在不同的数据集和架构上评估 SparseFool、JSMA 和"单像素攻击"的性能。SparseFool 中的控制参数 λ \lambda λ 对于 MNIST 和 CIFAR-10 数据集分别设置为 1 1 1 和 3 3 3。我们在表 1 中观察到,对于 MNIST 数据集,SparseFool 计算出的扰动比 JSMA 稀疏 2.9 × 2.9\times 2.9×,并且速度快 4.7 × 4.7\times 4.7×。对于 CIFAR-10 数据集,这种行为保持相似,SparseFool 平均计算出稀疏度高 2.4 × 2.4\times 2.4× 的扰动,并且速度快 15.5 × 15.5\times 15.5×。请注意执行时间的差异:随着输入数据维度的增加,JSMA 变得慢得多,而 SparseFool 的时间复杂度保持在非常低的水平。
然后,与"单像素攻击"相比,我们观察到对于 MNIST 数据集,我们的方法计算出的扰动稀疏 5.5 × 5.5\times 5.5×,并且快了超过 3 3 3 个数量级。对于 CIFAR-10 数据集,SparseFool 仍然能够找到非常稀疏的扰动,但在此情况下不如"单像素攻击"。原因在于我们的方法并不求解原始的 ℓ 0 \ell_{0} ℓ0 优化问题,而是通过线性化问题的 ℓ 1 \ell_{1} ℓ1 解来计算稀疏扰动。产生的解通常是次优的,并且可能仅在数据点非常接近边界(此时线性近似更准确)时是最优的。然而,求解我们的线性化问题是快速的,并使我们的方法能够高效地扩展到高维数据,而"单像素攻击"则不然。考虑到解的稀疏性和所需复杂性之间的权衡,我们选择牺牲前者,而不是遵循像 45 那样复杂的穷举方法。事实上,我们的方法能够比"单像素攻击"算法快 270 × 270\times 270× 计算稀疏扰动,并且需要的网络查询次数少 2 2 2 个数量级。
最后,由于 JSMA 和"单像素攻击"的巨大计算成本,我们没有将它们用于大型 ImageNet 数据集。在这种情况下,我们改为将 SparseFool 与一种随机算法进行比较,该算法从每个颜色通道(RGB)中选择一个元素子集,并将其强度替换为集合 V = { 0 , 255 } V=\{0,255\} V={0,255} 中的随机值。每个通道子集的基数被限制为匹配 SparseFool 的每个通道扰动元素数量的中位数;对于每个通道,我们选择的元素数量等于 SparseFool 对该通道所有图像的扰动元素数量的中位数。SparseFool 在 ImageNet 数据集上的性能报告在表 2 中,而随机算法的相应欺骗率分别为 18.2 % 18.2\% 18.2%、 13.2 % 13.2\% 13.2%、 14.5 % 14.5\% 14.5% 和 9.6 % 9.6\% 9.6%。观察到随机算法获得的欺骗率与 SparseFool 的无法相提并论,表明所提出的算法巧妙地找到了非常稀疏的解。确实,我们的方法在不同架构之间是一致的,平均扰动 0.21 % 0.21\% 0.21% 的像素,每个样本的平均执行时间为 7 7 7 秒。
据我们所知,我们是第一个提供足够稀疏攻击的人,该攻击能有效实现如此高的欺骗率和稀疏性,同时又能扩展到高维数据。"单像素攻击"不一定能为所有研究的数据集找到好的解,然而,SparseFool------由于它依赖于分类器的高维几何------成功地为所有三个数据集计算了足够稀疏的扰动。
可感知性 。在本节中,我们展示了一些由 SparseFool 生成的对抗性示例,针对三种不同的稀疏度水平:高度稀疏扰动、稀疏扰动以及介于两者之间的扰动。对于 MNIST 和 CIFAR-10 数据集(分别见图 5a 和 5b),我们观察到对于高度稀疏的情况,扰动要么难以察觉,要么非常稀疏(即 1 1 1 个像素)以至于可以轻松忽略。然而,随着扰动像素数量的增加,失真变得更加明显,并且在某些情况下,噪声是可检测的,远非难以察觉。对于 ImageNet 数据集(图 1),也观察到了相同的行为。对于高度稀疏的扰动,噪声再次要么难以察觉要么可忽略,但随着密度的增加,它变得越来越可见。
为了消除这种可感知性效应,我们关注对抗性图像 x ^ \hat{\bm{x}} x^ 值的下限和上限。回顾第 2.3 节,边界 l \bm{l} l、 u \bm{u} u 的定义方式使得 l i ≤ x ^ i ≤ u i , i = 1 ... n l_{i}\leq\hat{x}{i}\leq u{i}, ~~i=1\ldots n li≤x^i≤ui, i=1...n。如果这些边界代表图像的动态范围,那么 x ^ i \hat{x}{i} x^i 可以取该范围内的每个可能值,并且元素 i i i 处的噪声幅度可能达到某些可见水平。然而,如果每个元素的扰动值接近原始值 x i x{i} xi,那么我们可能会阻止幅度达到非常高的水平。为此,假设动态范围为 0 , 255 0,255 0,255,我们明确限制 x ^ i \hat{x}{i} x^i 的值位于 x i x{i} xi 附近的小区间 ± δ \pm\delta ±δ 内,使得 0 ≤ x i − δ ≤ x ^ i ≤ x i + δ ≤ 255 0\leq x_{i}-\delta\leq\hat{x}{i}\leq x{i}+\delta\leq 255 0≤xi−δ≤x^i≤xi+δ≤255。
不同 δ \delta δ 值所产生的稀疏度如图所示

图 5: (a) MNIST 和 (b) CIFAR-10 数据集的对抗性示例,分别由 SparseFool 在 LeNet 和 ResNet-18 架构上计算得出。每列对应不同水平的扰动像素。
图 6。 δ \delta δ 值越高,我们给扰动的自由度越大,对于 δ = 255 \delta=255 δ=255,我们利用了整个动态范围。但观察到在 δ ≈ 25 \delta\approx 25 δ≈25 之后,稀疏度水平似乎几乎保持不变,这表明我们不需要使用整个动态范围。此外,我们观察到从该值开始,SparseFool 的每个样本平均执行时间似乎也保持恒定,而欺骗率始终为 100 % 100\% 100%,与 δ \delta δ 无关。因此,通过选择适当的 δ \delta δ 值,我们可以控制所产生扰动的可感知性,并将稀疏度保持在足够的水平。 δ \delta δ 对扰动可感知性和稀疏度的影响在图 7 中展示。
可转移性和语义信息。我们现在研究 SparseFool 对抗性扰动是否可以泛化到不同的架构。对于 VGG-16、ResNet-101 和 DenseNet-161 19 架构,我们在表 3 中报告了每个模型在输入由另一个模型生成的对抗性示例时的欺骗率。我们观察到稀疏对抗性扰动只能在一定程度上泛化,并且,正如预期的那样 29,它们从较大架构到较小架构的可转移性更强。这表明不同架构之间应该存在一些 SparseFool 利用的共享语义信息,但扰动主要依赖于网络。
关注 ImageNet 数据集的一些动物类别,我们观察到扰动确实集中在"重要"区域(即头部)周围,但没有一致的模式表明对网络最重要的特定特征(即眼睛、耳朵、鼻子等);在许多情况下,噪声也散布在图像的不同部分。现在检查语义信息是否在不同架构之间共享(图 8),我们观察到在所有网络中,噪声始终位于
表 1: SparseFool (SF)、JSMA 38 和"单像素攻击" (1-PA) 45 在 MNIST 和 CIFAR-10 数据集上的性能。³ 注意,由于其高复杂性,"单像素攻击"仅在 100 100 100 个样本上进行了评估。

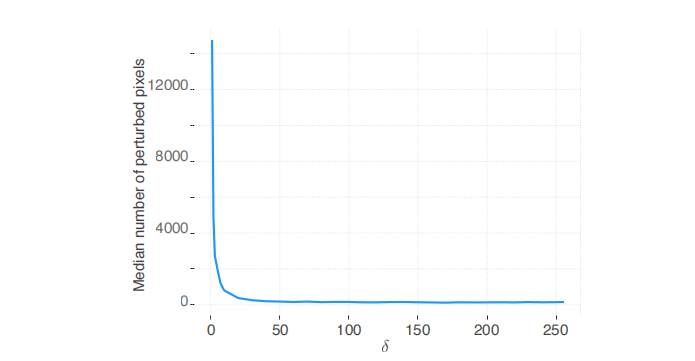
图 6: 对于 ImageNet 上的 100 100 100 个样本在 ResNet-101 架构上,SparseFool 扰动在 x \bm{x} x 值 ± δ \pm\delta ±δ 范围内所产生的稀疏度。
表 2: SparseFool 在 ImageNet 数据集上的性能,使用 PyTorch 提供的预训练模型。³
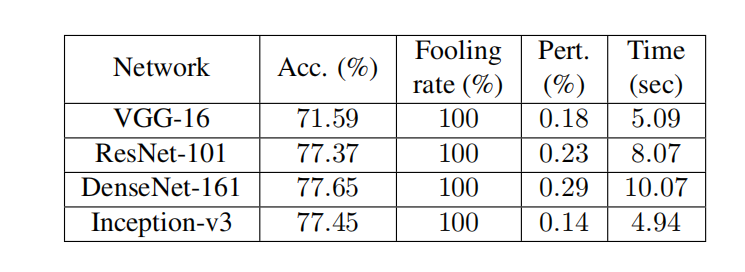

图 7: δ \delta δ 对 SparseFool 扰动的可感知性和稀疏度的影响。 δ \delta δ 的值显示在每列顶部,而被欺骗的标签和扰动像素百分比写在每个图像下方。
图像的重要区域周围,但噪声集中或散布的方式因网络而异。
对于 CIFAR-10 数据集,我们观察到在许多动物类别的情况下,SparseFool 倾向于扰动头部区域周围的一些通用特征(即眼睛、耳朵、鼻子、嘴巴等),如图 9a 所示。此外,我们试图理解扰动像素与被欺骗类别之间是否存在相关性。有趣的是,我们观察到在许多情况下,算法会扰动图像中那些对应于被欺骗类别重要特征的区域,例如,当将"鸟"标签更改为"飞机"时,扰动似乎代表了飞机的某些部分(即机翼、尾翼、机头、涡轮)。当被欺骗的标签是"鹿"时,这种行为变得更加明显,噪声主要分布在头部区域,类似于鹿角。
对抗训练网络的鲁棒性 。最后,我们研究了一个在 CIFAR-10 数据集上使用 ℓ ∞ \ell_{\infty} ℓ∞ 扰动进行对抗训练的 ResNet-18 网络对稀疏扰动的鲁棒性。这个更鲁棒的网络的准确率为 82.17 % 82.17\% 82.17%,其训练过程和整体性能与 30 中提供的相似。与表 1 的结果相比,平均时间下降到 0.3 0.3 0.3 秒,但扰动百分比

图 8: 在三种不同架构上计算的 ImageNet 的 SparseFool 扰动的共享信息。对于所有网络,第一行图像被分类为"吉娃娃",并被误分类为"法国斗牛犬",第二行图像分别被分类为"鸵鸟"和"鹤"。
表 3: 对于来自 ImageNet 的 4000 4000 4000 个样本,SparseFool 扰动在模型对之间的欺骗率。行和列分别表示源模型和目标模型。
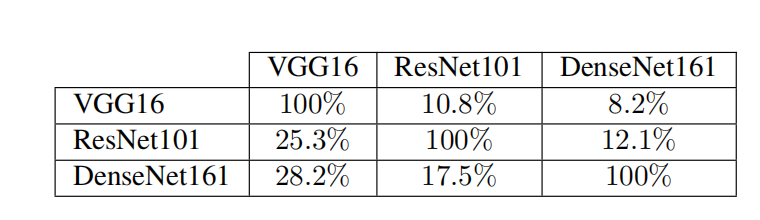

图 9: 在 ResNet-18 架构上,CIFAR-10 数据集的 SparseFool 扰动的语义信息。观察到扰动集中在 (a) 面部区域周围的一些特征上,以及 (b) 对被欺骗类别重要的区域上。
参考文献
-
1 S. Abu-El-Haija, N. Kothari, J. Lee, P. Natsev, G. Toderici, B. Varadarajan, and S. Vijayanarasimhan. Youtube-8m: A large-scale video classification benchmark. arXiv preprint arXiv:1609.08675, 2016.
-
2 A. Bibi, M. Alfadly, and B. Ghanem. Analytic expressions for probabilistic moments of pl-dnn with gaussian input. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
-
3 T. Blumensath and M. E. Davies. Iterative thresholding for sparse approximations. Journal of Fourier Analysis and Applications, 14(5):629-654, 2008.
-
4 E. Candes, M. Rudelson, T. Tao, and R. Vershynin. Error correction via linear programming. 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS'05), pages 668-681, 2005.
-
5 E. Candes and T. Tao. Decoding by linear programming. IEEE Transactions on Information Theory, 51(12):4203-4215, 2005.
-
6 N. Carlini and D. Wagner. Towards evaluating the robustness of neural networks. IEEE Symposium on Security and Privacy (SP), pages 39-57, 2017.
-
7 N. Carlini and D. Wagner. Audio adversarial examples: Targeted attacks on speech-to-text. IEEE Security and Privacy Workshops (SPW), 2018.
-
8 M. Cisse, Y. Adi, N. Neverova, and J. Keshet. Houdini: Fooling deep structured prediction models. In Advances in Neural Information Processing Systems (NeurIPS), pages 6977-6987, 2017.
-
9 J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and F.-F. Li. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
-
10 D. L. Donoho. Compressed sensing. IEEE Transactions on Information Theory, 52(4):1289-1306, 2006.
-
11 D. L. Donoho and M. Elad. Optimally sparse representation in general (nonorthogonal) dictionaries via ℓ 1 \ell_{1} ℓ1 minimization. National Academy of Sciences, 100(5):2197-2202, 2003.
-
12 A. Fawzi and P. Frossard. Manitest: Are classifiers really invariant? British Machine Vision Conference (BMVC), 2015.
-
13 A. Fawzi, S.-M. Moosavi-Dezfooli, and P. Frossard. The robustness of deep networks: A geometrical perspective. IEEE Signal Processing Magazine, 34(6):50-62, 2017.
-
14 A. Fawzi, S.-M. Moosavi-Dezfooli, P. Frossard, and S. Soatto. Empirical study of the topology and geometry of deep networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
-
15 I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. In International Conference on Learning Representations (ICLR), 2015.
-
16 R. Gribonval and M. Nielsen. Sparse representations in unions of bases. IEEE Transactions on Information Theory, 49(12):3320-3325, 2003.
-
17 K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
-
18 M. Hein and M. Andriushchenko. Formal guarantees on the robustness of a classifier against adversarial manipulation. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
-
19 G. Huang, Z. Liu, L. Maaten, and K. Q. Weinberger. Densely connected convolutional networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
-
20 S. Jetley, N. A. Lord, and P. H. Torr. With friends like these, who needs adversaries? arXiv preprint arXiv:1807.04200, 2018.
-
21 C. Kanbak, S.-M. Moosavi-Dezfooli, and P. Frossard. Geometric robustness of deep networks: analysis and improvement. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
-
22 I. Krasin, T. Duerig, N. Alldrin, A. Veit, S. Abu-El-Haija, S. Belongie, D. Cai, Z. Feng, V. Ferrari, V. Gomes, A. Gupta, D. Narayanan, C. Sun, G. Chechnik, and K. Murphy. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.com/openimages, 2016.
-
23 A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
-
24 A. Kurakin, I. J. Goodfellow, and S. Bengio. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533, 2016.
-
25 Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278-2324, 1998.
-
26 Y. LeCun and C. Cortes. Mnist handwritten digits database. Dataset available from http://yann.lecun.com/exdb/mnist/, 2010.
-
27 T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft coco: Common objects in context. In The European Conference on Computer Vision (ECCV), pages 740-755, 2014.
-
28 Y.-C. Lin, Z.-W. Hong, Y.-H. Liao, M.-L. Shih, M.-Y. Liu, and M. Sun. Tactics of adversarial attack on deep reinforcement learning agents. International Joint Conference on Artificial Intelligence (IJCAI), pages 3756-3762, 2017.
-
29 Y. Liu, X. Chen, C. Liu, and D. Song. Delving into transferable adversarial examples and black-box attacks. arXiv preprint arXiv:1611.02770, 2016.
-
30 A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations (ICLR), 2018.
-
31 J. H. Metzen, M. C. Kumar, T. Brox, and V. Fischer. Universal adversarial perturbations against semantic image segmentation. In IEEE International Conference on Computer Vision (ICCV), pages 2774-2783, 2017.
-
32 S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard. Universal adversarial perturbations. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
-
33 S.-M. Moosavi-Dezfooli, A. Fawzi, and P. Frossard. Deepfool: A simple and accurate method to fool deep neural networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
-
34 M. Nagahara, D. E. Quevedo, and J. Ostergaard. Sparse packetized predictive control for networked control over erasure channels. IEEE Transactions on Automatic Control, 59(7):1899-1905, 2014.
-
35 N. Narodytska and S. P. Kasiviswanathan. Simple black-box adversarial attacks on deep neural networks. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017.
-
36 B. K. Natarajan. Sparse approximate solutions to linear systems. SIAM Journal on Computing, 24(2):227-234, 1995.
-
37 M. Nikolova. Description of the minimizers of least squares regularized with ℓ 0 \ell_{0} ℓ0-norm. uniqueness of the global minimizer. SIAM Journal on Imaging Sciences, 6(2):904-937, 2013.
-
38 N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami. The limitations of deep learning in adversarial settings. IEEE European Symposium on Security and Privacy (EuroS&P), pages 372-387, 2016.
-
39 N. Papernot, P. McDaniel, A. Swami, and R. Harang. Crafting adversarial input sequences for recurrent neural networks. IEEE Military Communications Conference (MILCOM), pages 49-54, 2016.
-
40 A. Patrascu and I. Necoara. Random coordinate descent methods for ℓ 0 \ell_{0} ℓ0 regularized convex optimization. IEEE Transactions on Automatic Control, 60(7):1811-1824, 2015.
-
41 J. Rauber, W. Brendel, and M. Bethge. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv preprint arXiv:1707.04131, 2017.
-
42 A. Rozsa, M. Gunther, E. M. Rudd, and T. E. Boult. Are facial attributes adversarially robust? International Conference on Pattern Recognition (ICPR), pages 3121-3127, 2016.
-
43 A. Rozsa, M. Gunther, E. M. Rudd, and T. E. Boult. Facial attributes: Accuracy and adversarial robustness. Pattern Recognition Letters, 2017.
-
44 K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations (ICLR), 2015.
-
45 J. Su, D. V. Vargas, and S. Kouichi. One pixel attack for fooling deep neural networks. arXiv preprint arXiv:1710.08864, 2017.
-
46 C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
-
47 C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. J. Goodfellow, and R. Fergus. Intriguing properties of neural networks. In International Conference on Learning Representations (ICLR), 2014.
-
48 P. Tabacof, J. Tavares, and E. Valle. Adversarial images for variational autoencoders. arXiv preprint arXiv:1612.00155, 2016.
-
49 C. Xiao, J.-Y. Zhu, B. Li, W. He, M. Liu, and D. Song. Spatially transformed adversarial examples. In International Conference on Learning Representations (ICLR), 2018.
-
50 Y. Zhang, K. Lee, and H. Lee. Augmenting supervised neural networks with unsupervised objectives for large-scale image classification. In International Conference on Machine Learning (ICML), volume 48, pages 612-621, 2016.
附录 A SparseFool 对抗性示例
在本节中,我们提供了由 SparseFool 为不同数据集生成的一些补充对抗性示例。这些示例对应三种不同的稀疏度水平:(a) 高度稀疏, (b) 非常稀疏, 和 © 稀疏扰动。ImageNet、CIFAR-10 和 MNIST 数据集的相应结果分别显示在图 10 - 12 中。观察到对于高度和非常稀疏的扰动,噪声要么难以察觉,要么足够稀疏可以忽略。然而,随着扰动像素数量的增加,噪声可能变得相当明显。

图 10: ImageNet 数据集在不同稀疏度水平下的 SparseFool 对抗性示例。预测标签显示在图像上方,被欺骗的标签在下方,扰动像素的数量写在括号内。

图 11: CIFAR-10 数据集在不同稀疏度水平下的 SparseFool 对抗性示例。被欺骗的标签显示在图像下方,扰动像素的数量写在括号内。
附录 B 控制扰动的可感知性
我们现在在图 13 中展示一些 ImageNet 数据集上的对抗性示例,当我们控制由 SparseFool 计算的扰动的可感知性时。这可以通过适当地约束扰动图像的值位于原始图像值的 ± δ \pm\delta ±δ 范围内来实现。

图 12: MNIST 数据集在不同稀疏度水平下的 SparseFool 对抗性示例。被欺骗的标签显示在图像下方,扰动像素的数量写在括号内。

图 13: 控制由 SparseFool 计算的扰动的可感知性。第一行:原始图像及其下方的预测标签。第二行:由 SparseFool 使用整个动态范围生成的对抗性示例。第三行:由 SparseFool 通过将噪声限制在图像值 ± 10 \pm 10 ±10 范围内生成的对抗性示例。对于对抗性示例,被欺骗的标签显示在图像下方,扰动像素的百分比写在括号内。请注意,被欺骗的标签可能会改变,因为 SparseFool 是作为非目标攻击运行的。
附录 C 控制参数 λ \lambda λ
在本节中,我们提供控制参数 λ \lambda λ 对 (a) 欺骗率, (b) 扰动的稀疏度, 和 (c) SparseFool 收敛性的影响。 λ \lambda λ 的不同值对 MNIST、CIFAR-10 和 ImageNet 数据集上不同网络的影响分别显示在图 14 - 16 中。
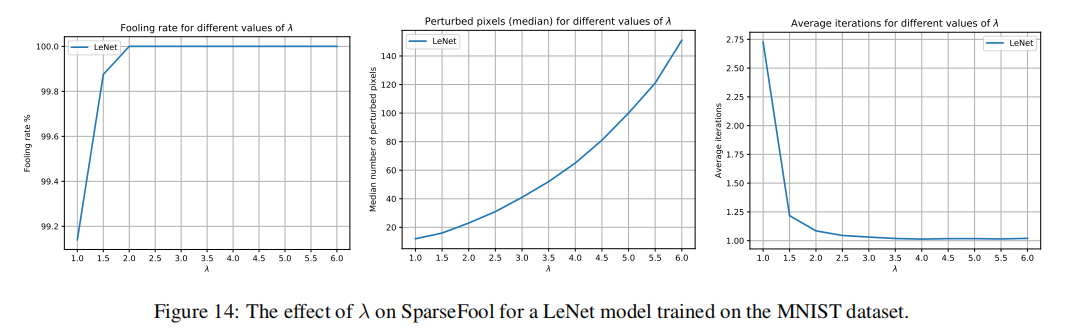
图 14: λ \lambda λ 对在 MNIST 数据集上训练的 LeNet 模型的 SparseFool 的影响。
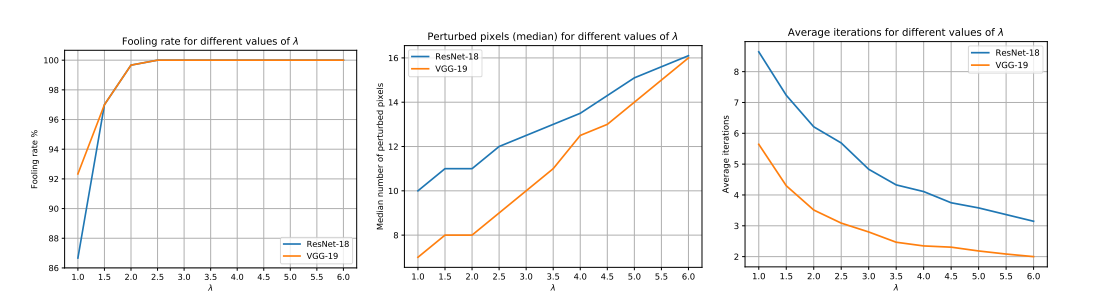
图 15: λ \lambda λ 对在 CIFAR-10 数据集上训练的不同网络的 SparseFool 的影响。
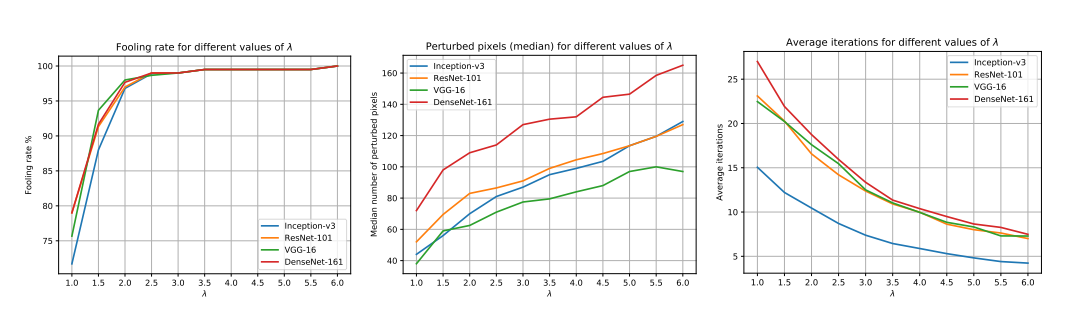
图 16: λ \lambda λ 对在 ImageNet 数据集上训练的不同网络的 SparseFool 的影响。
附录 D 与相关方法比较的对抗性示例
在本节中,我们展示了由 SparseFool 生成的对抗性示例,并与由 JSMA 和"单像素攻击"计算的相应示例进行比较。在 MNIST 和 CIFAR-10 数据集上获得的结果分别描绘在图 17 和图 18 中。

图 17: 由 (a) SparseFool(第一行)、(b) "单像素攻击"(第二行)和 © JSMA(第三行)生成的 MNIST 对抗性示例。被欺骗的标签显示在每个图像下方,扰动像素的数量写在括号内。

图 18: 由 (a) SparseFool(第一行)、(b) "单像素攻击"(第二行)和 © JSMA(第三行)生成的 CIFAR-10 对抗性示例。被欺骗的标签显示在每个图像下方,扰动像素的数量写在括号内。