1. 核心理念:打破传统检测的桎梏
长期以来,计算机视觉(CV)落地面临着"长尾场景难、训练成本高、逻辑判断弱"的三大痛点。传统的视觉检测范式(如 YOLO 系列)本质上是模式匹配:它能极快地框出"车",却无法理解"车停在这里 5 分钟属于违章,而停在红绿灯前属于正常"。
本项目提出了一种视觉检测的新范式:利用多模态大语言模型(VLM)的强大语义理解能力,结合"时序-空间映射"技术,将复杂的视频事件检测转化为单次图文问答任务。我们不再需要为每一个新场景训练模型,只需改变自然语言提示词(Prompt),即可实现从"检测物体"到"理解行为"的跨越。
2. 关键创新:4 帧时序拼接技术(The 2x2 Temporal Grid)
现有的 VLM 大多仅支持单图输入,缺乏对时间维度的感知,导致无法判断"运动"、"停止"或"趋势"。
本项目独创性地引入了**"时序拼图"预处理机制**:
-
采样策略:系统在边缘端建立帧缓冲区,建立四个时刻的关键帧。
-
空间映射:将这四帧图像按照时间顺序拼接为一张2x2的田字格图像。
-
推理逻辑:利用大模型对图像细节的极致观察力,让模型通过对比四个分格中的像素位移、参照物关系(如车道线),来推断物体的运动状态。
这一设计巧妙地将"视频理解问题"降维成了"图像找不同问题",在不引入昂贵的视频专用模型(Video-LLM)的前提下,极低成本地实现了时序事件检测。
3. 系统优势
-
零样本冷启动:
无需采集数千张"违停车辆"样本进行训练。只需输入 Prompt:"若车辆在 4 个画面中位置相对地面完全静止,回答是",系统即可即刻上线。
-
极强的抗干扰能力:
通过 Prompt 工程(Prompt Engineering),我们赋予了系统类似人类的判断逻辑------"忽略摄像头轻微抖动"、"忽略树叶晃动"。这是传统算法通过阈值设置难以做到的。
-
交互式定义任务:
用户可以通过自然语言随时更改检测逻辑。从"检测违停"切换到"检测工人未戴安全帽"或"检测老人跌倒",无需修改一行代码,仅需修改文字指令。
4. 落地案例:城市交通异常停车检测
在本项目实现的演示系统中,我们针对"车辆违停"这一经典难题进行了验证:
-
输入:实时监控流(支持 RTSP/MP4)。
-
处理:每隔 5 秒生成一张包含过去 4 秒信息的拼接图。
-
推理:Qwen3-VL-4B 模型分析拼图。
-
输出:系统能够精准输出"停车报警"或"无事件",并提供毫秒级的推理耗时日志。
5. 示例
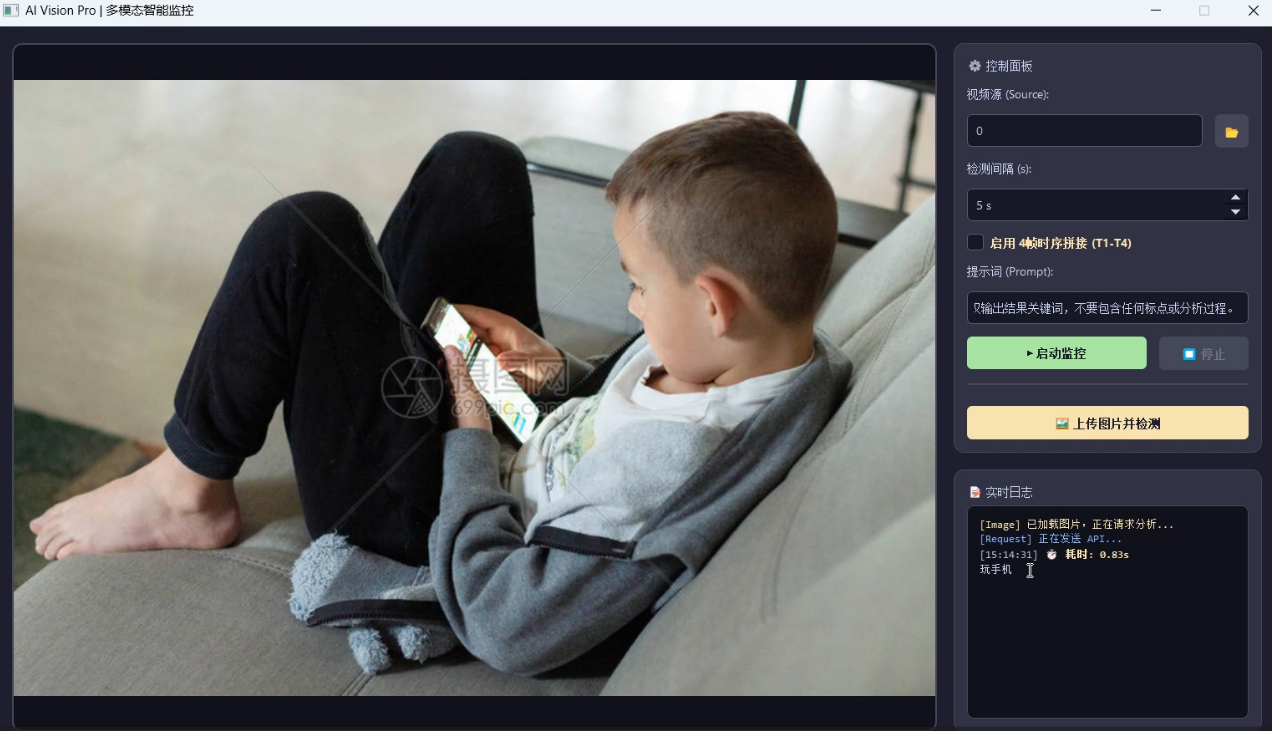
6. 总结
本项目不仅是一个监控工具,更是Edge-AI的一次探索。它证明了通用大模型完全可以运行在端侧,通过巧妙的工程化设计,解决传统深度学习难以处理的逻辑推理问题。这标志着视觉检测正从"专用小模型时代"迈向"通用大模型+提示词工程"**的新时代。