基于 Python 的爱奇艺视频数据可视化分析系统 - 实战分享
作者:码界筑梦坊(各大平台同名)
本项目以真实的爱奇艺剧集数据为基础,构建了"数据爬取 → 数据存储 → 数据分析 → 可视化展示"的完整闭环,后端使用 Flask + SQLAlchemy + MySQL,前端采用 Bootstrap + ECharts,配合 Pandas/NumPy/jieba/wordcloud/matplotlib 实现数据处理与词云等可视化能力。本文将完整分享项目的技术栈、目录结构、核心功能、关键代码与可视化接入方式,帮助你快速上手或二次开发。
模型定义与表结构摘要
以下是基于 SQLAlchemy Declarative 的核心模型示例,字段请根据你的实际表结构调整(与 design_276_iqiyi.sql 对应):
python
# models_example.py(示例,与你的 models.py 思路一致)
from datetime import datetime
from sqlalchemy import (
Column, String, Integer, Float, Text, DateTime, Boolean, ForeignKey, create_engine, Index
)
from sqlalchemy.orm import declarative_base, relationship
DATABASE_URL = 'mysql+pymysql://user:password@localhost:3306/drama_db?charset=utf8mb4'
engine = create_engine(DATABASE_URL, pool_pre_ping=True)
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
email = Column(String(120), unique=True, nullable=False, index=True)
password_hash = Column(String(255), nullable=False)
is_admin = Column(Boolean, default=False, nullable=False)
created_at = Column(DateTime, default=datetime.utcnow)
comments = relationship('Comment', back_populates='user', cascade='all,delete-orphan')
favorites = relationship('Favorite', back_populates='user', cascade='all,delete-orphan')
class Drama(Base):
__tablename__ = 'dramas'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(255), nullable=False, index=True)
type = Column(String(50), nullable=True) # TV/Web/Variety
director = Column(String(255), nullable=True)
casts = Column(Text, nullable=True)
score = Column(Float, nullable=True)
hotness = Column(Integer, nullable=True)
cover_image = Column(String(255), nullable=True) # static/img/drama/xxx.jpg
created_at = Column(DateTime, default=datetime.utcnow)
comments = relationship('Comment', back_populates='drama', cascade='all,delete-orphan')
favorites = relationship('Favorite', back_populates='drama', cascade='all,delete-orphan')
Index('idx_dramas_hotness', Drama.hotness.desc())
class Comment(Base):
__tablename__ = 'comments'
id = Column(Integer, primary_key=True, autoincrement=True)
user_id = Column(Integer, ForeignKey('users.id'), nullable=False, index=True)
drama_id = Column(Integer, ForeignKey('dramas.id'), nullable=False, index=True)
content = Column(Text, nullable=False)
likes = Column(Integer, default=0)
created_at = Column(DateTime, default=datetime.utcnow)
user = relationship('User', back_populates='comments')
drama = relationship('Drama', back_populates='comments')
class Favorite(Base):
__tablename__ = 'favorites'
id = Column(Integer, primary_key=True, autoincrement=True)
user_id = Column(Integer, ForeignKey('users.id'), nullable=False, index=True)
drama_id = Column(Integer, ForeignKey('dramas.id'), nullable=False, index=True)
created_at = Column(DateTime, default=datetime.utcnow)
user = relationship('User', back_populates='favorites')
drama = relationship('Drama', back_populates='favorites')
def init_db():
Base.metadata.create_all(engine)
if __name__ == '__main__':
init_db()提示:生产环境建议使用迁移工具(如 Alembic)管理表结构变更,并在关键字段上建立合理的索引(如
title、hotness、user_id、drama_id)。
目录
- 项目概览
- 技术栈
- 目录结构
- 环境准备与运行
- 数据流与架构设计
- 后端核心代码示例
- 数据分析与词云示例
- [可视化展示(ECharts 接入)](#可视化展示(ECharts 接入))
- 后台管理与权限
- 性能与优化建议
- 可视化效果占位与扩展
- 数据导入与清洗示例
- 简单爬虫/图片更新脚本示例
- 部署与配置(可选)
- [常见问题 FAQ](#常见问题 FAQ)
- 结语与联系方式
项目概览
- 类型:视频数据可视化分析平台
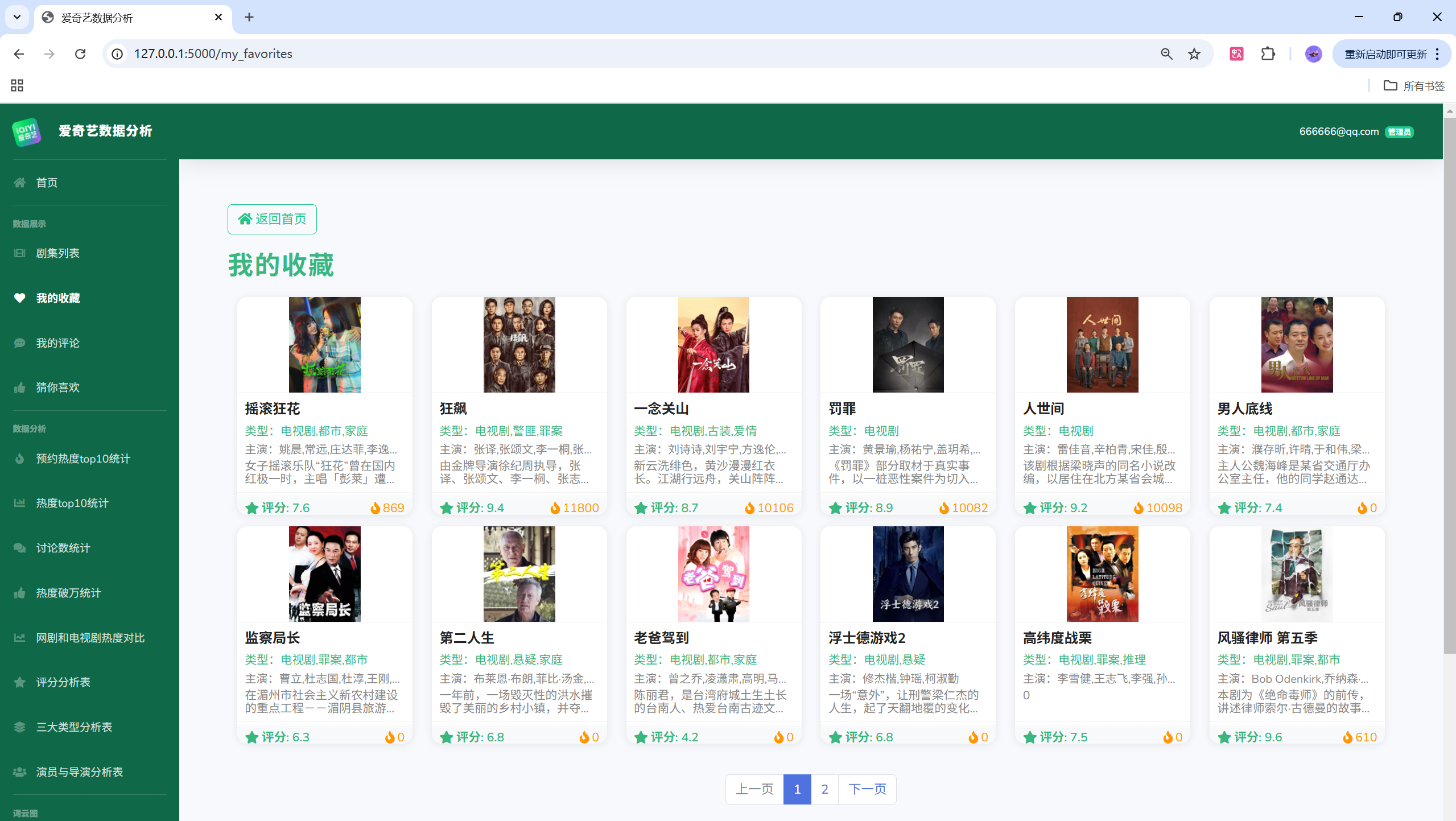
- 功能:用户体系、剧集检索与详情、收藏与评论、可视化分析(热度、评分、类型、演员/导演、词云、对比分析等)、后台管理(用户/评论/剧集/收藏/日志)
- 数据源:爱奇艺剧集相关数据(含图片、评论文本、评分与热度等结构化信息)
- 特点:模块化、可扩展、前后端分离程度适中,二次开发友好
技术栈
后端
- Python 3.8+
- Flask(Web 框架)
- SQLAlchemy(ORM)
- MySQL 5.7+
数据处理与可视化
- Pandas(数据清洗与聚合)
- NumPy(数值计算)
- jieba(中文分词)
- wordcloud(词云生成)
- matplotlib(静态图表与词云渲染)
前端
- HTML5/CSS3/JavaScript
- Bootstrap 4(响应式 UI)
- jQuery(DOM 与 AJAX)
- ECharts(交互式可视化)
- FontAwesome(图标库)
项目演示
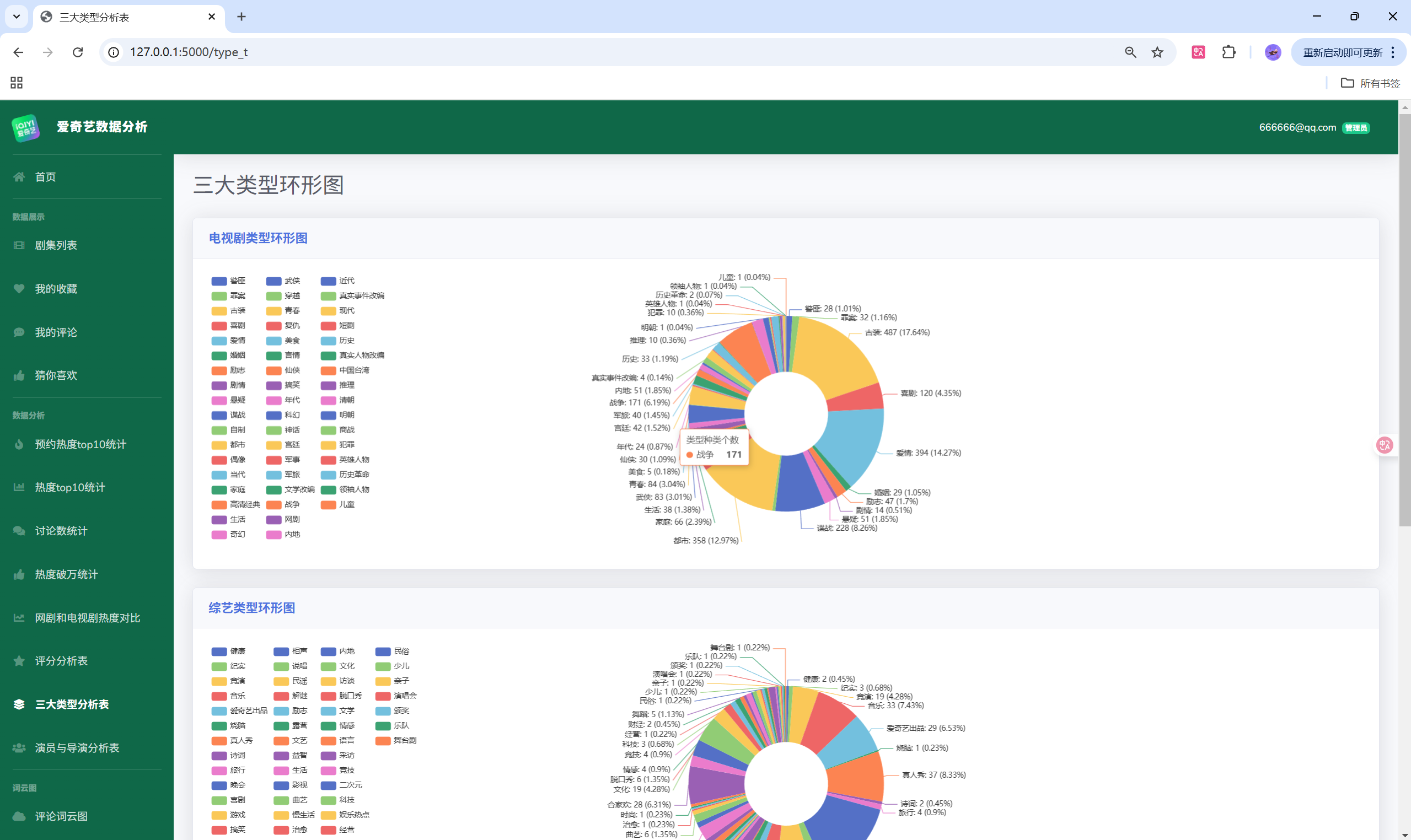
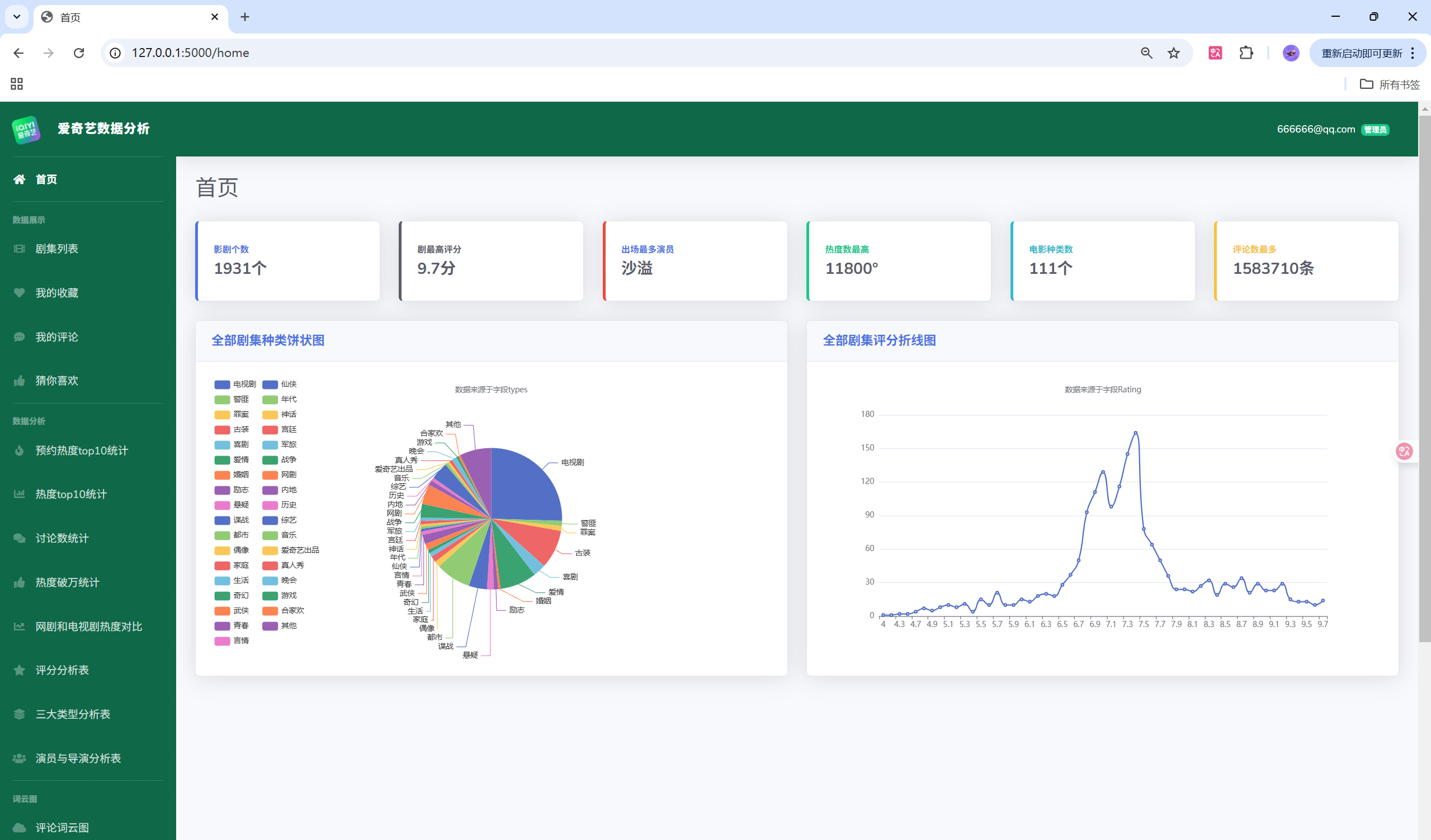
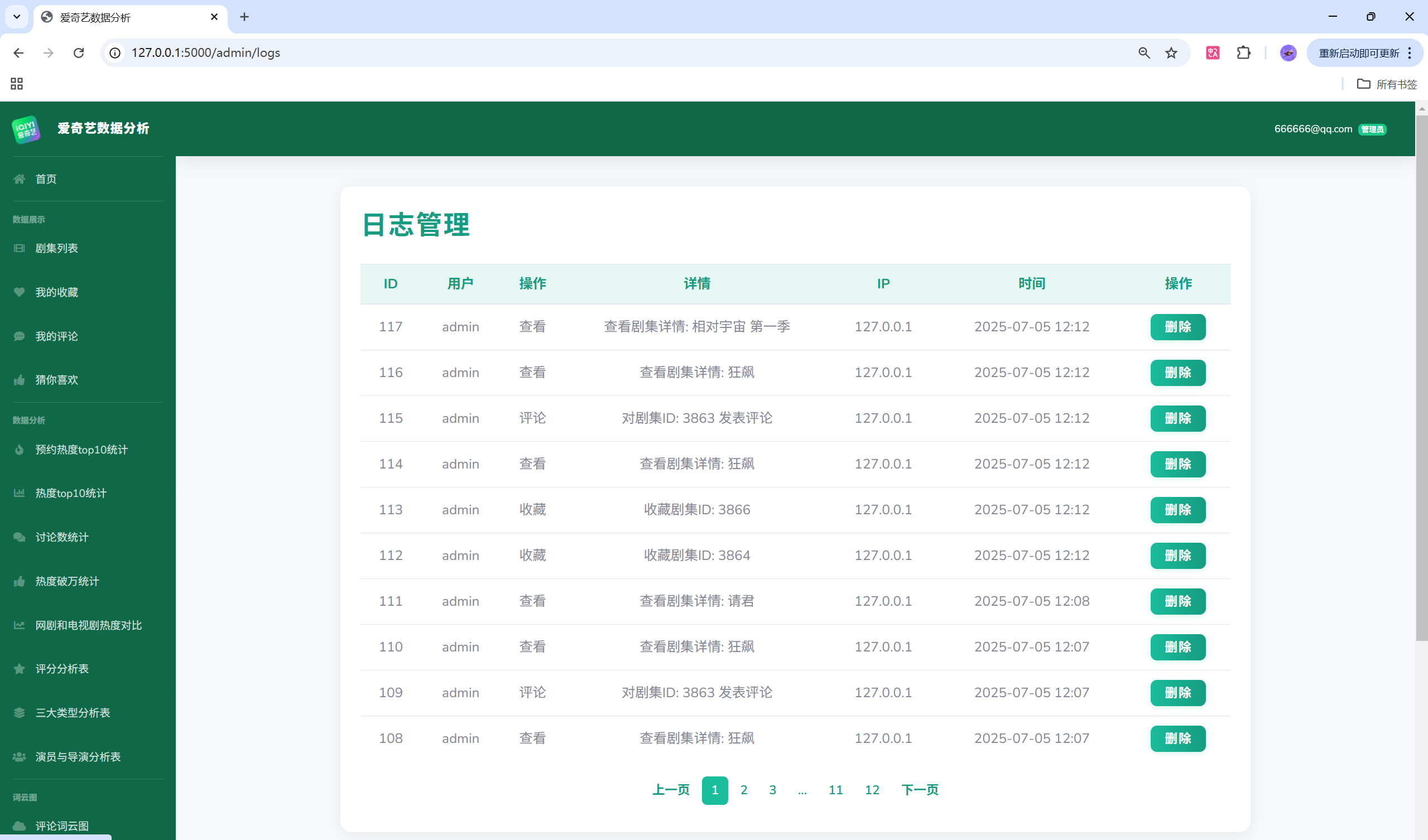
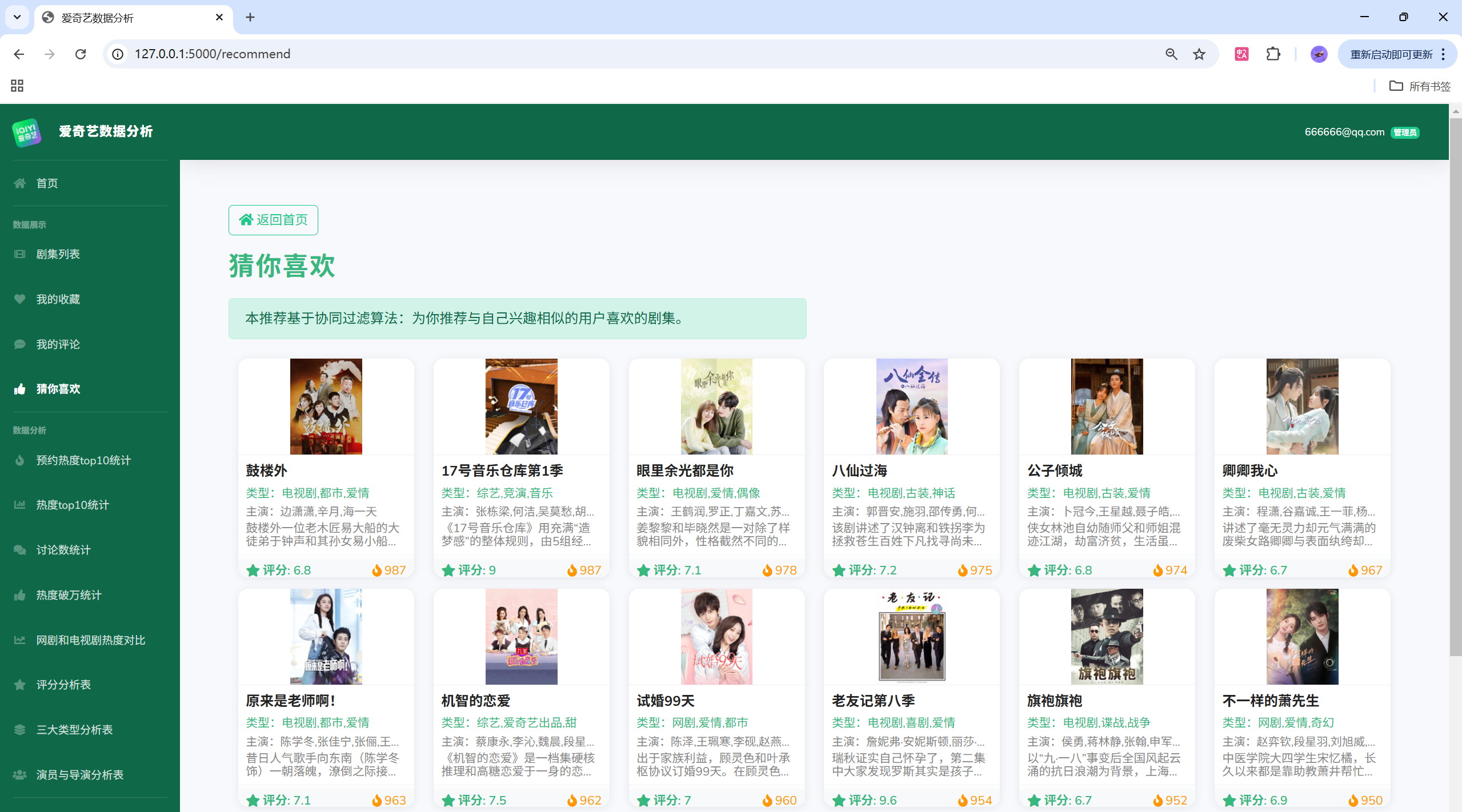
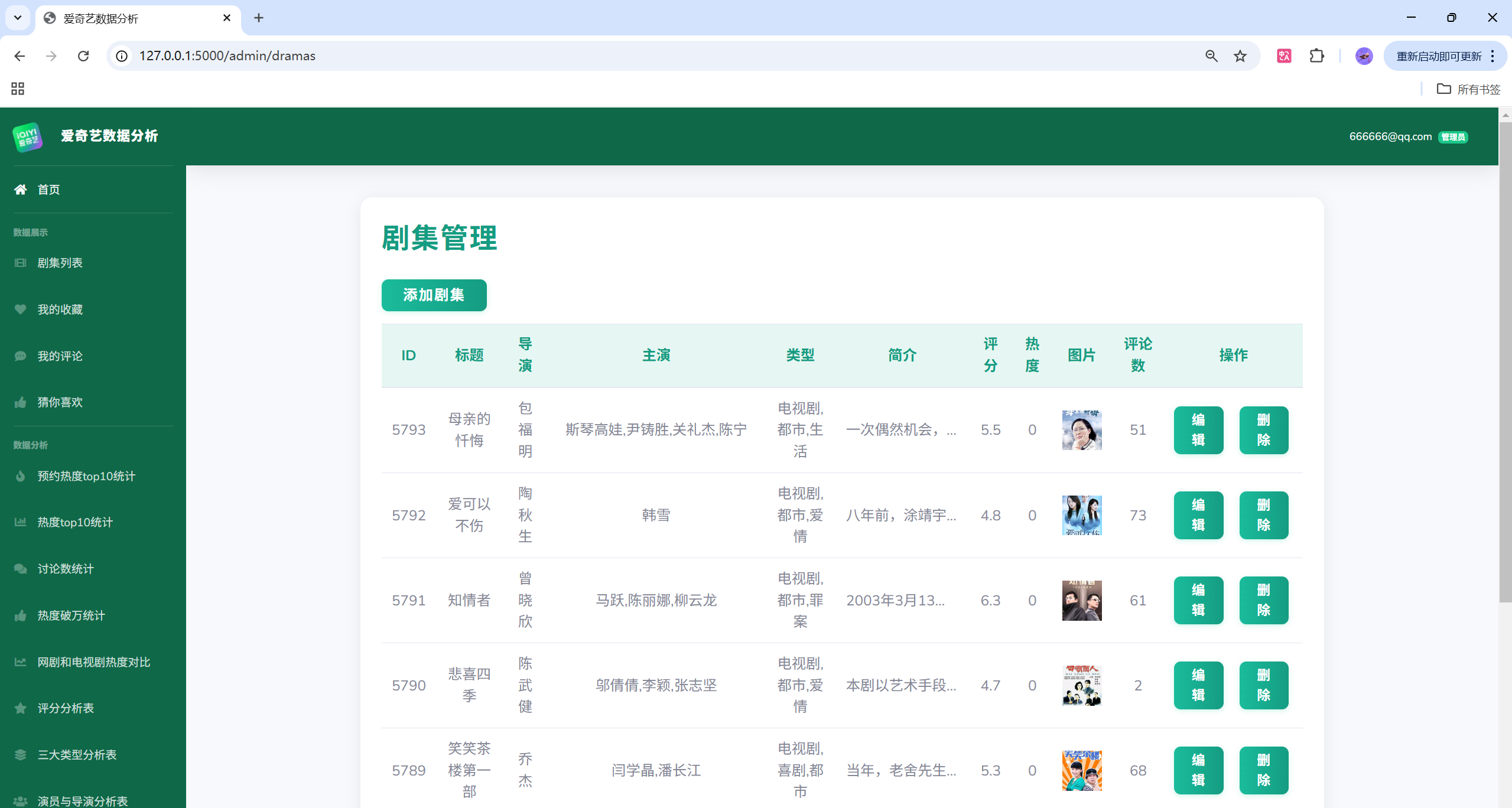
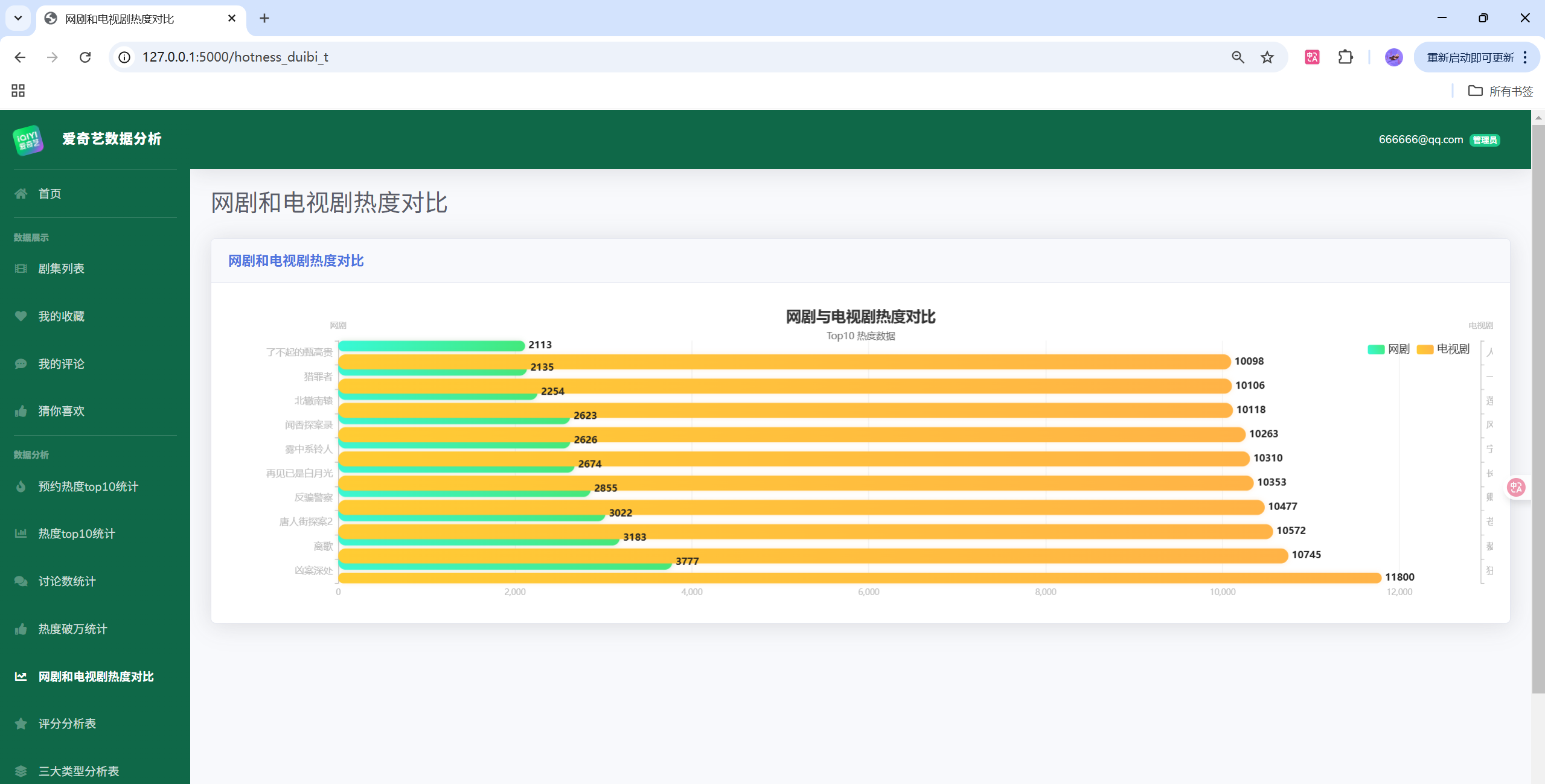
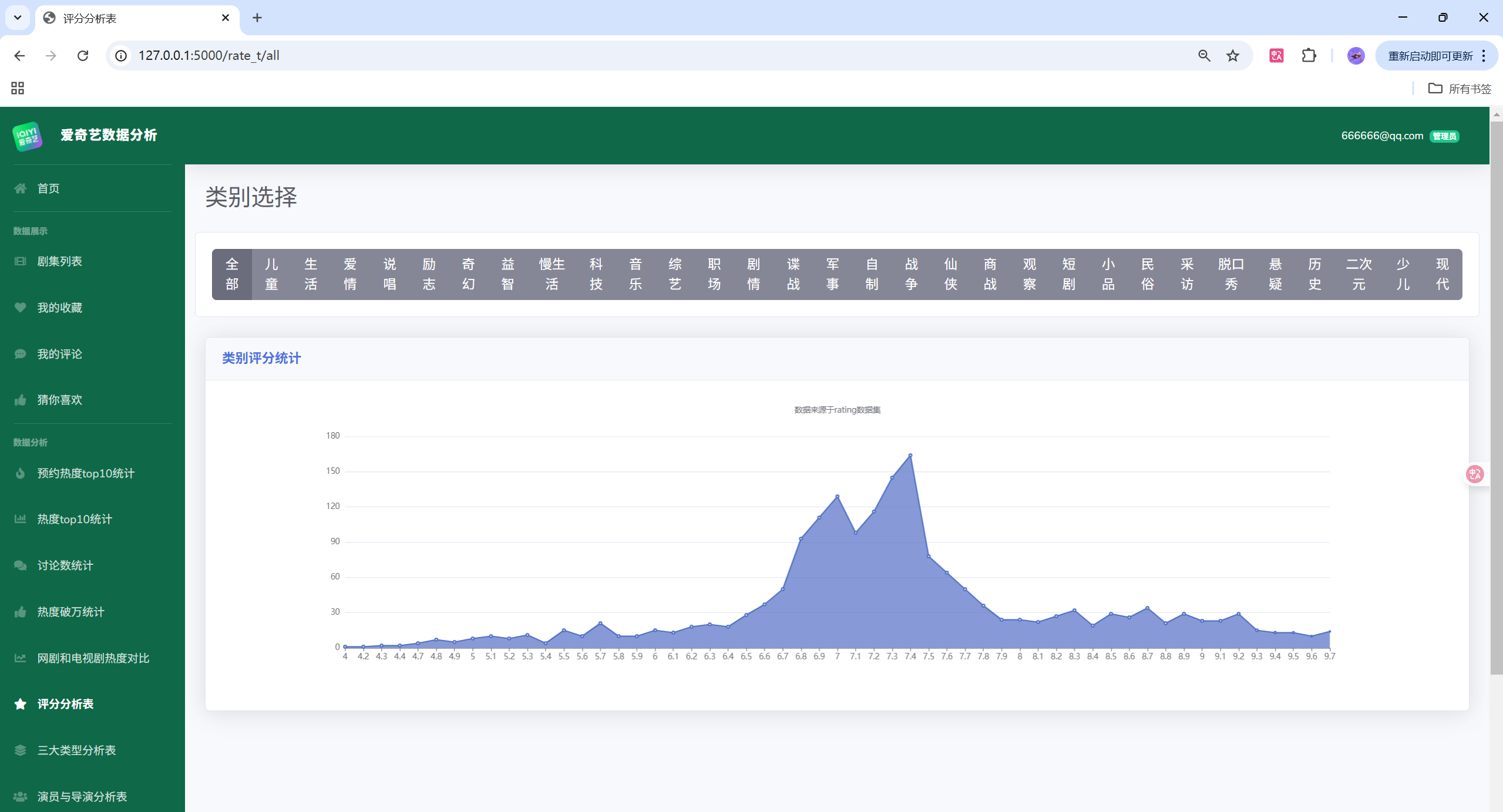
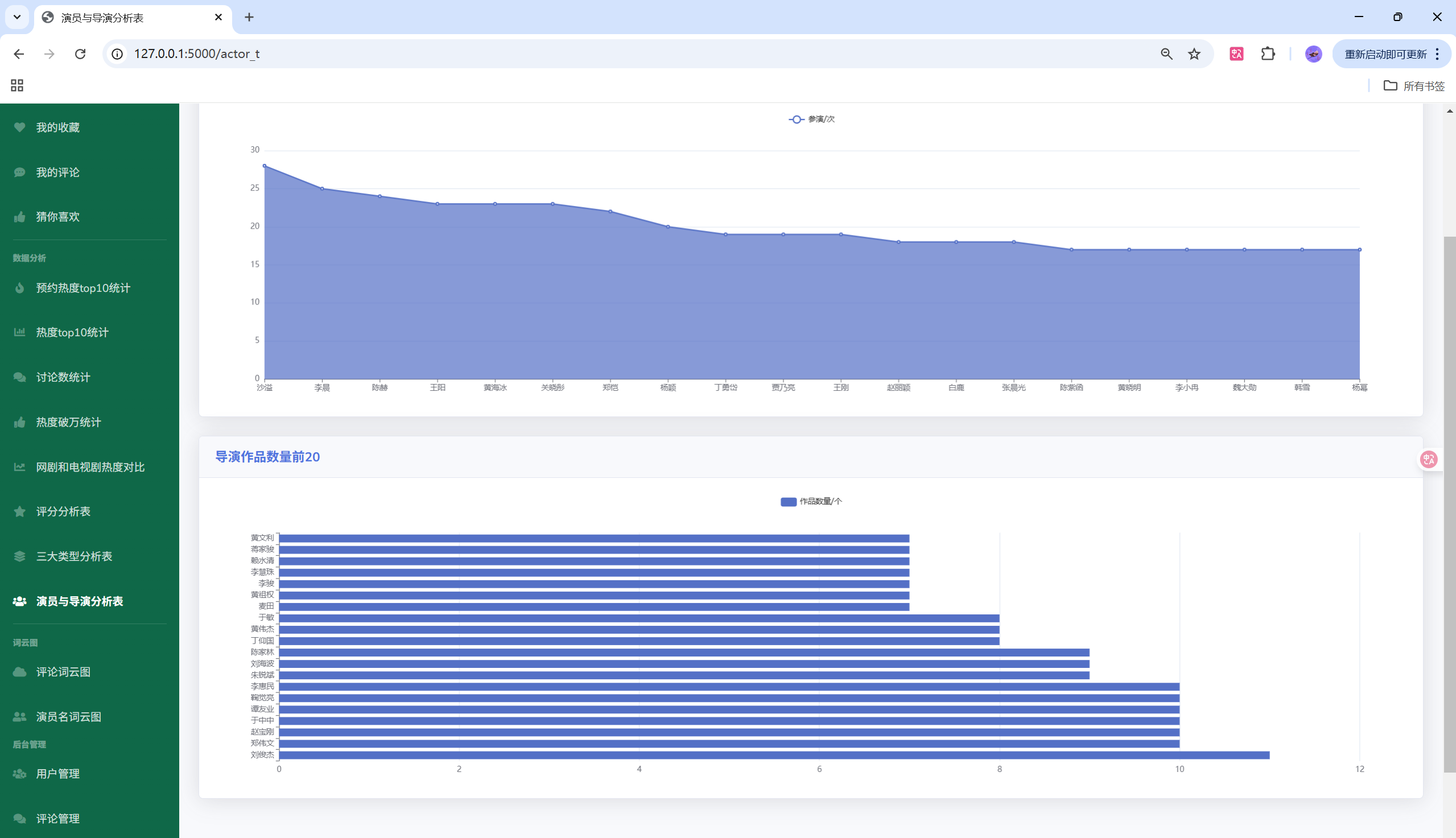
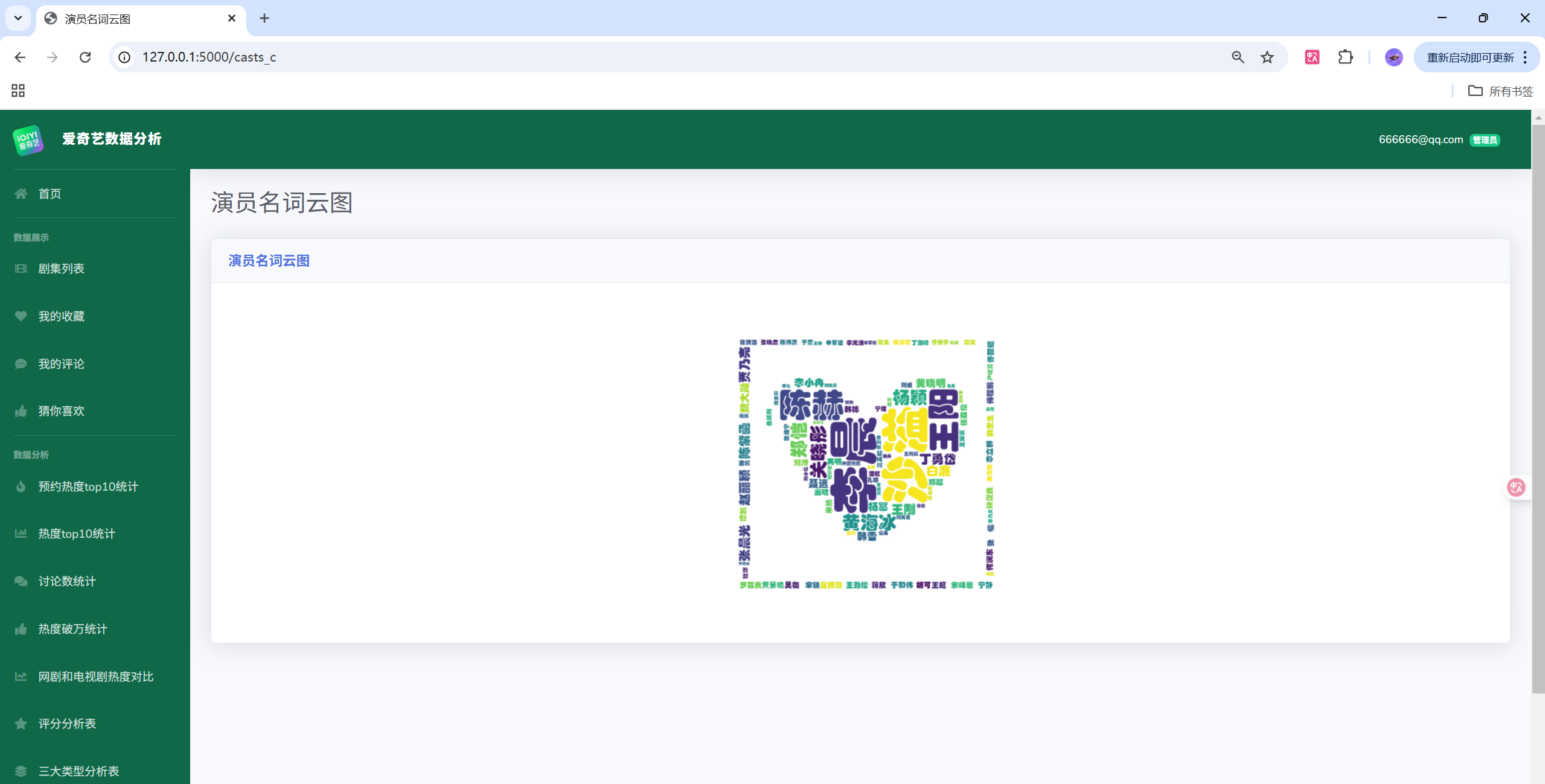
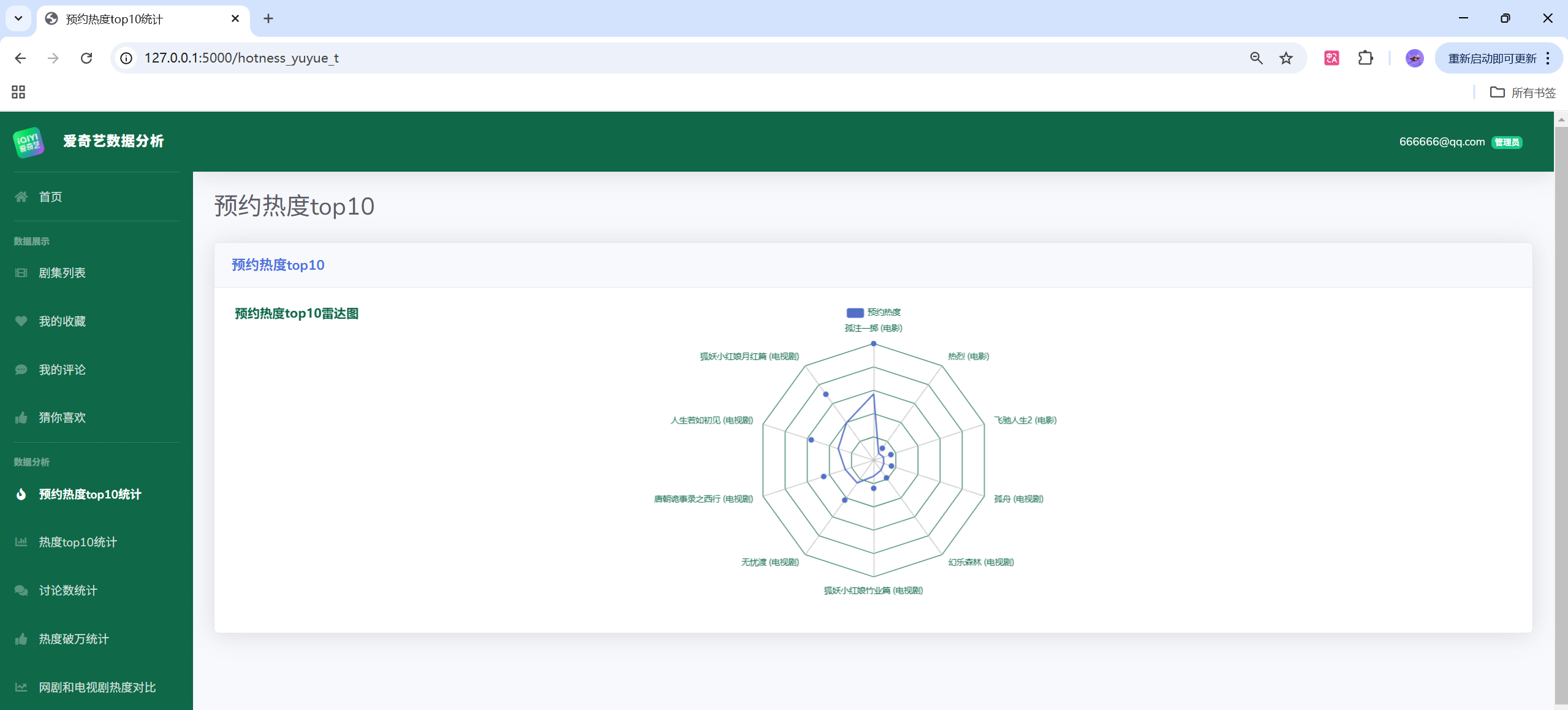
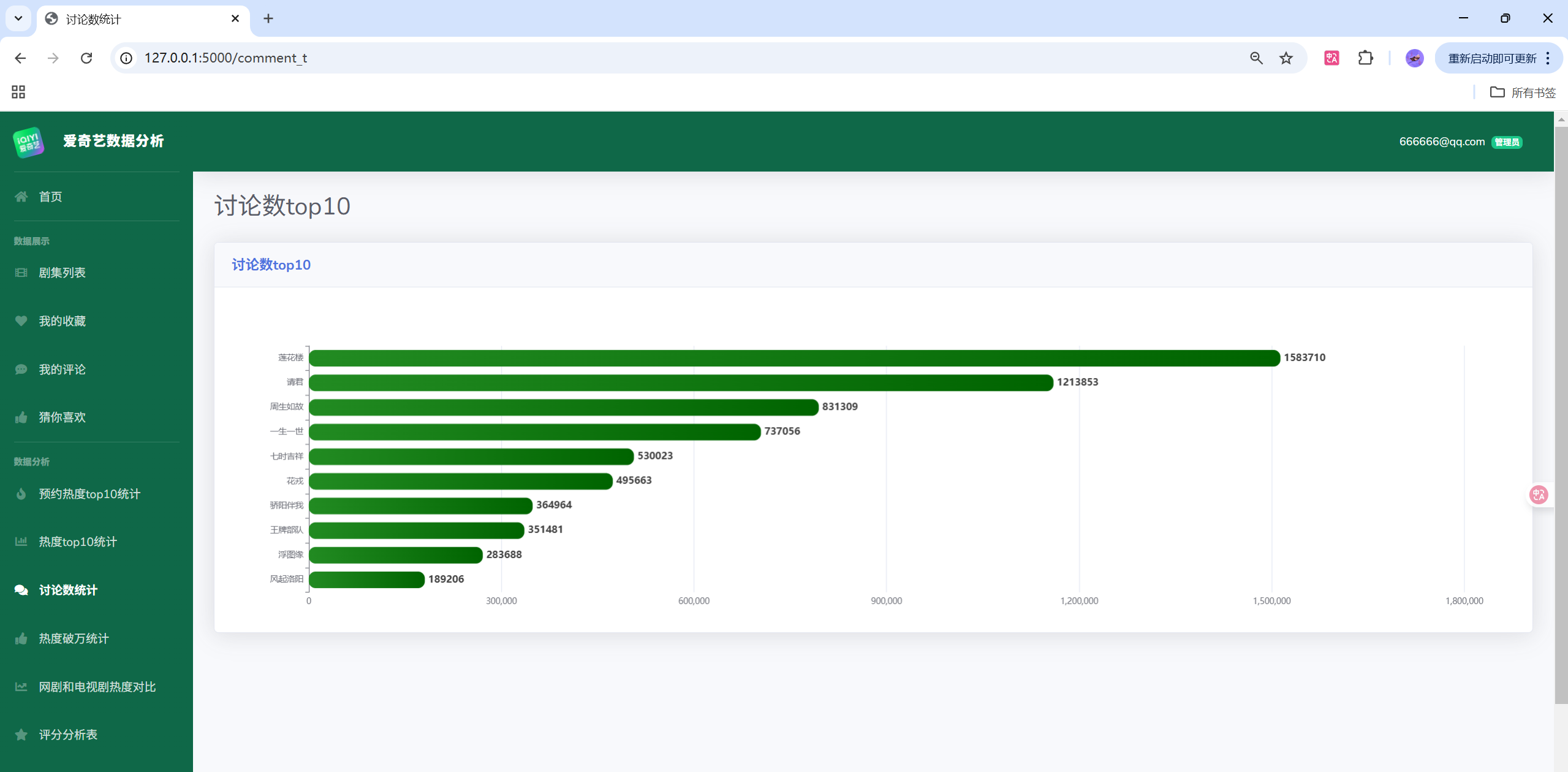
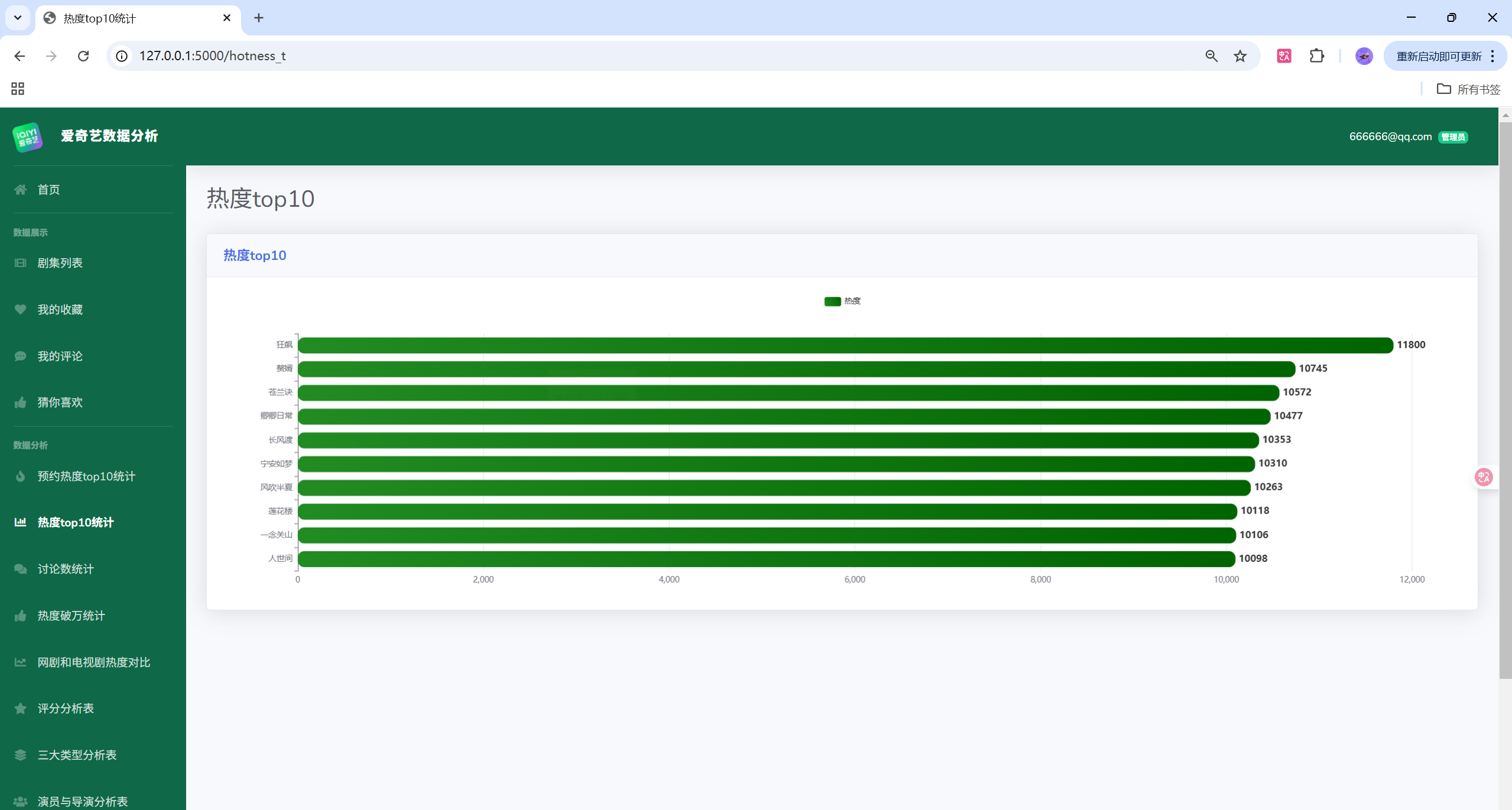
目录结构
项目关键结构如下(节选):
text
python爱奇艺数据可视化分析/
├── app.py # 主应用入口
├── models.py # 数据模型定义(SQLAlchemy)
├── requirements.txt # 依赖列表
├── create_admin.py # 初始化管理员脚本
├── import_drama_data.py # 导入剧集数据
├── download_and_update_drama_images.py # 下载/更新剧集图片(爬取图片)
├── word_cloud.py # 词云生成脚本
├── design_276_iqiyi.sql # 数据库结构/示例 SQL(你的仓库中为此名)
├── 合并后的数据.csv / 合并后的数据.xlsx # 原始/整合后的数据
├── static/ # 静态资源(CSS/JS/图片/vendor)
├── templates/ # Jinja2 模板(页面)
└── utils/ # 业务数据获取与统计重要页面模板位于 templates/,前端静态资源在 static/,数据统计逻辑集中在 utils/ 下的各个 get* 模块。
环境准备与运行
- 安装依赖
bash
pip install -r requirements.txt- 初始化数据库(MySQL 5.7+)
bash
# 登录 MySQL 并创建数据库(示例)
mysql -u root -p
CREATE DATABASE drama_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;- 初始化管理员账户与基础数据
bash
python create_admin.py
python import_drama_data.py- 运行应用
bash
python app.py
# 浏览器访问 http://localhost:5000数据流与架构设计
- 数据采集:通过脚本采集剧集基础信息与图片等资源(例如
download_and_update_drama_images.py),或从既有数据文件合并后的数据.csv/.xlsx导入。 - 数据存储:经清洗后的结构化数据写入 MySQL;图片保存于
static/img/drama/。 - 服务层:Flask 提供页面路由与数据接口(JSON),SQLAlchemy 屏蔽底层 SQL。
- 分析层:Pandas/NumPy 完成聚合与统计,jieba/wordcloud/matplotlib 负责中文文本和词云渲染。
- 展示层:前端以 ECharts 呈现交互式图表,Jinja2 模板负责页面布局与数据注入。
简化数据流:采集/导入 → 清洗/入库 → 分析/聚合 → API → 前端可视化。
后端核心代码示例
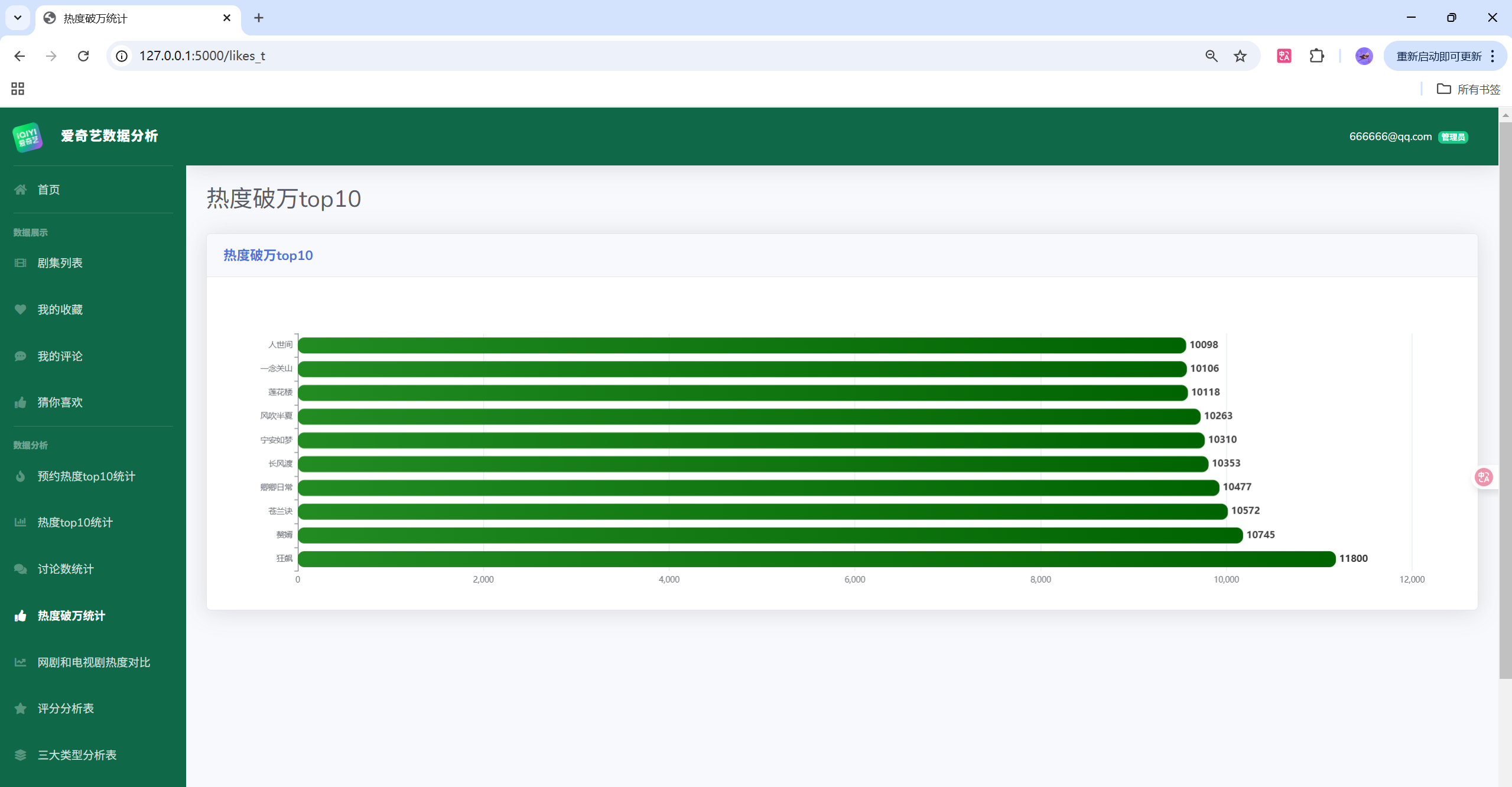
以下示例展示一个常用的接口:返回 ECharts 可直接消费的 JSON 数据(柱状图 Top10 热度)。
python
# 示例:app_charts.py(示例文件,便于理解,可合并进 app.py 或蓝图)
from flask import Flask, jsonify
import pandas as pd
import sqlalchemy as sa
app = Flask(__name__)
# 使用 SQLAlchemy Engine 直连(生产建议使用应用级 Session 管理)
engine = sa.create_engine(
'mysql+pymysql://user:password@localhost:3306/drama_db?charset=utf8mb4',
pool_recycle=3600,
pool_pre_ping=True
)
@app.route('/api/hotness/top10')
def api_hotness_top10():
query_sql = """
SELECT title, hotness
FROM dramas
WHERE hotness IS NOT NULL
ORDER BY hotness DESC
LIMIT 10
"""
df = pd.read_sql(query_sql, engine)
# 返回给 ECharts 的格式
return jsonify({
'categories': df['title'].tolist(),
'series': df['hotness'].tolist()
})
if __name__ == '__main__':
app.run(debug=True)如果你使用 models.py 与 Session 管理,也可以用 ORM 查询后转换成 DataFrame:
python
from sqlalchemy.orm import Session
from models import Drama, engine # 假设 models.py 暴露了 engine 与模型
import pandas as pd
def get_hotness_top10_via_orm():
with Session(engine) as session:
rows = (
session.query(Drama.title, Drama.hotness)
.filter(Drama.hotness.isnot(None))
.order_by(Drama.hotness.desc())
.limit(10)
.all()
)
df = pd.DataFrame(rows, columns=['title', 'hotness'])
return df进一步,推荐将接口拆分为蓝图(Blueprint),使路由更清晰:
python
# charts_blueprint.py(示例)
from flask import Blueprint, jsonify
from sqlalchemy.orm import Session
from models import Drama, engine
import pandas as pd
charts_bp = Blueprint('charts', __name__, url_prefix='/api')
@charts_bp.get('/hotness/top10')
def hotness_top10():
with Session(engine) as session:
rows = (
session.query(Drama.title, Drama.hotness)
.filter(Drama.hotness.isnot(None))
.order_by(Drama.hotness.desc())
.limit(10)
.all()
)
df = pd.DataFrame(rows, columns=['title', 'hotness'])
return jsonify({'categories': df['title'].tolist(), 'series': df['hotness'].tolist()})
# app.py 中注册:
# from charts_blueprint import charts_bp
# app.register_blueprint(charts_bp)数据分析与词云示例
- 使用 Pandas 读取整合数据并进行分组统计:
python
import pandas as pd
df = pd.read_csv('合并后的数据.csv') # 或 read_excel('合并后的数据.xlsx')
# 评分分布(四分位统计)
describe = df['score'].describe()
print(describe)
# 类型热度聚合(示例字段以实际为准)
type_hotness = (
df.groupby('type')['hotness']
.sum()
.sort_values(ascending=False)
.reset_index()
)
print(type_hotness.head(10))- 基于中文评论文本生成词云:
python
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
text_series = df['comment'].dropna().astype(str)
text = " ".join([" ".join(jieba.cut(t)) for t in text_series])
w = WordCloud(
font_path='static/fonts/msyh.ttc', # 请替换为存在的中文字体路径
background_color='white',
width=1200,
height=800,
max_words=300
)
w.generate(text)
plt.figure(figsize=(12, 8))
plt.imshow(w, interpolation='bilinear')
plt.axis('off')
plt.tight_layout()
plt.savefig('static/img/summary_cloud.png', dpi=150)可视化展示(ECharts 接入)
前端通过 AJAX 拉取 /api/hotness/top10 的数据,然后渲染柱状图:
html
<div id="hotnessTop10" style="width:100%;height:420px;"></div>
<script src="/static/js/echarts.js"></script>
<script>
(function() {
const chart = echarts.init(document.getElementById('hotnessTop10'));
fetch('/api/hotness/top10')
.then(r => r.json())
.then(data => {
chart.setOption({
tooltip: { trigger: 'axis' },
grid: { left: 48, right: 24, top: 24, bottom: 64 },
xAxis: { type: 'category', data: data.categories, axisLabel: { rotate: 30 } },
yAxis: { type: 'value', name: '热度' },
series: [{ type: 'bar', data: data.series, itemStyle: { color: '#2ecc71' } }]
});
});
})();
</script>同理,可扩展折线图、饼图与对比分析图,只需返回相应的 JSON 结构即可。
后台管理与权限
- 用户:注册/登录、角色区分(管理员/普通用户)、密码修改、个人中心。
- 管理端:用户、评论、剧集、收藏与日志的增删改查与审计。
- 权限建议:基于角色的路由保护与模板条件渲染;日志记录包含操作类型映射与时间戳。
性能与优化建议
- 数据库层:为高频字段加索引(如
title、type、hotness),分页查询使用覆盖索引。 - ORM 层:控制 N+1 查询,复杂统计走 SQL 或物化表/视图。
- 缓存层:热门榜单与词云数据可引入缓存(如 Redis)定时刷新。
- 前端层:合并压缩静态资源、启用浏览器缓存;图表初始化懒加载。
可视化效果占位与扩展
你可以在文档或首页预留展示位,后续替换为生成的图片或动态图表:
markdown



也可以以动态方式渲染 ECharts 区域,提前在模板中加入容器与脚本占位:
html
<div id="chartPlaceholder" style="width:100%;height:420px;"></div>
<script>
// TODO: 后续替换为真实接口
// echarts.init(...).setOption(...)
// 占位用的空配置,防止布局抖动
</script>数据导入与清洗示例
以下示例展示如何从 Excel/CSV 导入剧集数据并清洗后入库:
python
# import_drama_data_example.py(示例,与你的 import_drama_data.py 思路一致)
import pandas as pd
import sqlalchemy as sa
engine = sa.create_engine('mysql+pymysql://user:password@localhost:3306/drama_db?charset=utf8mb4')
def normalize_title(title: str) -> str:
return (title or '').strip()
def main():
df = pd.read_excel('合并后的数据.xlsx') # 或 read_csv('合并后的数据.csv')
# 基础清洗
df['title'] = df['title'].astype(str).map(normalize_title)
df = df.drop_duplicates(subset=['title']).reset_index(drop=True)
# 类型标准化示例
type_map = {'电视剧': 'TV', '网剧': 'Web', '综艺': 'Variety'}
if 'type' in df.columns:
df['type'] = df['type'].map(lambda x: type_map.get(str(x), str(x)))
# 写入临时表或目标表(存在则追加)
df.to_sql('dramas', con=engine, if_exists='append', index=False)
if __name__ == '__main__':
main()注意:生产中请使用显式字段映射与批量插入(如
to_sql的method='multi'),并对数据类型进行严格校验。
简单爬虫/图片更新脚本示例
在不触犯目标站点使用条款的前提下,可利用请求库抓取公开图片并保存到 static/img/drama/。示例(与你仓库中的 download_and_update_drama_images.py 角色一致):
python
# download_and_update_drama_images_example.py(示例)
import os
import time
import requests
from urllib.parse import urlparse
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0 Safari/537.36'
}
SAVE_DIR = 'static/img/drama'
os.makedirs(SAVE_DIR, exist_ok=True)
def safe_filename(url: str) -> str:
path = urlparse(url).path
name = os.path.basename(path)
return name or f"{int(time.time()*1000)}.jpg"
def download_image(url: str, timeout: int = 10) -> str:
resp = requests.get(url, headers=HEADERS, timeout=timeout)
resp.raise_for_status()
filename = safe_filename(url)
file_path = os.path.join(SAVE_DIR, filename)
with open(file_path, 'wb') as f:
f.write(resp.content)
return file_path
def batch_download(image_urls: list[str]) -> list[str]:
saved = []
for u in image_urls:
try:
saved.append(download_image(u))
time.sleep(0.2) # 礼貌性延时
except Exception as e:
print('download failed:', u, e)
return saved
if __name__ == '__main__':
urls = [
'https://example.com/path/a_100000489_m_601.jpg',
# ... 你的图片 URL 列表
]
batch_download(urls)建议:遵循目标网站的 robots 协议与服务条款,合理设置速率限制与重试,避免对服务造成压力。
部署与配置(可选)
1) 配置文件与环境变量
bash
# .env(示例)
FLASK_ENV=production
DATABASE_URL=mysql+pymysql://user:password@127.0.0.1:3306/drama_db?charset=utf8mb4
SECRET_KEY=please-change-meapp.py 中读取:
python
import os
from dotenv import load_dotenv
load_dotenv()
DATABASE_URL = os.getenv('DATABASE_URL')
SECRET_KEY = os.getenv('SECRET_KEY', 'dev')2) Gunicorn 与 Nginx(Linux)
bash
pip install gunicorn gevent
gunicorn -k gevent -w 2 -b 0.0.0.0:5000 app:appNginx 反向代理(片段):
nginx
server {
listen 80;
server_name your.domain.com;
location /static/ {
alias /var/www/yourapp/static/;
expires 7d;
}
location / {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}Windows 下可直接使用 waitress:
bash
pip install waitress
python -m waitress --host=0.0.0.0 --port=5000 app:app常见问题 FAQ
- 是否包含爬虫?
- 存在用于下载/更新剧集图片的脚本
download_and_update_drama_images.py,数据也可从现有CSV/XLSX导入。
- 存在用于下载/更新剧集图片的脚本
- 是否使用 Pandas / NumPy?
- 是,数据清洗、聚合与统计分析广泛使用 Pandas 与 NumPy。
- 词云如何生成?
- 借助
jieba分词与wordcloud生成,并可用matplotlib渲染输出到static/img/。
- 借助
- 前端图表框架?
- 使用 ECharts 实现交互式图表;样式基于 Bootstrap 4。
结语与联系方式
本项目适合作为 Python + Flask + ECharts 的完整数据可视化工程实践模板,也可作为课程/竞赛/毕设的基础框架进一步拓展(如引入推荐算法、更多数据源、API 网关与前后端完全分离等)。欢迎 Star 与二次开发。
联系方式:码界筑梦坊(各大平台同名)
© 2024-2025 码界筑梦坊 | MIT License