大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少"避坑"经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批"好上手且有亮点"的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

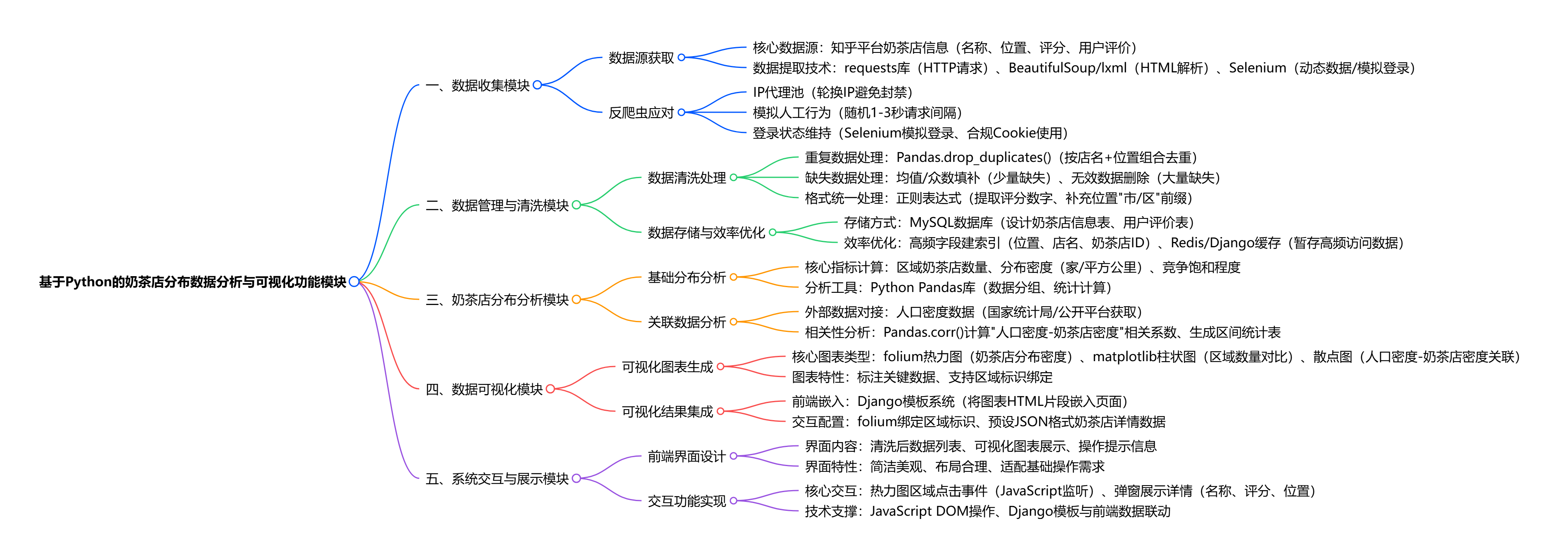
基于 Python 的奶茶店分布数据分析与可视化功能总结
- 数据收集功能:以知乎平台为核心数据源,通过 Python 爬虫技术(requests、BeautifulSoup、Selenium 等)获取奶茶店名称、位置、用户评价、评分等数据,针对反爬虫机制(IP 限制、登录要求),采用 IP 代理池、模拟登录、设置随机请求间隔等策略,确保数据合规且稳定获取。
- 数据管理与清洗功能:基于 Python 的 Pandas 库处理 "脏数据",包括删除重复的奶茶店记录、填补 / 删除缺失数据(如空位置、空评分)、用正则表达式统一混乱数据格式(如标准化位置描述、提取统一评分数值),同时通过 MySQL 数据库存储清洗后的数据,结合索引优化与缓存策略提升数据存取效率。
- 奶茶店分布分析功能:利用 Python 数据分析工具(如 Pandas)对清洗后的数据进行深度分析,计算不同区域奶茶店的数量、分布密度、竞争态势(如某区域奶茶店饱和程度),还可结合外部数据(如人口密度数据)分析两者相关性,挖掘奶茶店分布与市场需求的关联规律。
- 数据可视化功能:通过 Python 可视化工具(matplotlib、folium 等)生成多种可视化结果,包括奶茶店分布热力图(直观展示高密度区域)、区域数量柱状图(对比不同区域奶茶店规模)、"人口密度 - 奶茶店密度" 散点图(呈现数据关联),并借助 Django 模板系统将可视化结果嵌入前端页面,支持用户交互查看。
- 系统交互与展示功能:基于 Django 框架搭建 Web 系统,采用 MVC 模式设计架构,前端页面展示清洗后的数据、可视化图表,支持用户点击热力图区域查看对应区域奶茶店详细信息(名称、评分、位置),同时设计简洁美观的操作界面,提供清晰的操作提示,保障良好的用户交互体验。
【开题陈述】
各位老师好,我是H同学,课题是《基于Python的奶茶店分布数据分析与可视化》。系统采用 Django + Vue 的 B/S 架构:后台用 Python 编写 Scrapy 爬虫定时抓取主流点评平台的奶茶店名称、地址、评分、评论量等原始数据,经 Pandas 清洗后存入 MySQL;前端用 Vue3 + ECharts 实现地图热力图、柱状图、评价词云等可视化,并提供按城市、商圈、价格带的多维筛选。核心模块包括数据爬取、清洗入库、空间分析、商圈推荐、可视化展示五大块。下面请各位老师提问。
【答辩开始】
评委老师1:爬取点评网站时,如何防止被封 IP?
**答辩学生:**Scrapy 中间件随机切换 UA 和 20 个高匿代理,并把下载延迟设为 0.8--2 s 随机值;同时降低并发数到 16,若返回 403 或验证码则自动降速并记录失败 URL 稍后重试。
评委老师2:同一奶茶店在多个平台名称略有差异(如"喜茶"vs"HEYTEA"),如何合并?
**答辩学生:**用模糊匹配 + 地址距离双阈值:Levenshtein 相似度 > 0.8 且经纬度距离 < 200 m 即判定为同店,再以最早抓取的名称为基准写入统一 ID。
评委老师3:MySQL 里已存 40 万条店铺,地图热力图一次性加载太慢,怎么优化?
**答辩学生:**后台按城市网格预聚合,把 1 km² 内店铺数、平均评分先算好存入 agg_grid 表;前端地图只在当前视野范围内请求对应网格,加载时间从 6 s 降到 0.8 s。
评委老师4:前端词云用的是什么库,评论文本如何做敏感词过滤?
**答辩学生:**词云用 wordcloud.js,敏感词则调用本地敏感词树+正则替换,树文件约 1 万条,2 MB 常驻内存,过滤耗时 < 30 ms,不影响渲染。
评委老师5:若明年新增"奶茶品牌总部管理"角色,需要看到各城市加盟店的实时销售额,但销售数据不在你爬取范围,如何扩展?
**答辩学生:**①在数据库增加 sales 表并开放 API,品牌方每日批量上传加密 CSV;②后端解析后写入,按店 ID 关联;③前端在原有热力图加"营业额"图层,销售额分五级颜色渲染;权限用 Django-group 做行级过滤,确保总部看到全部,城市经理只看属地。
评委老师6:假如政府把高德/百度地图 POI 接口收紧,要求必须走官方授权且返回坐标是加密坐标,你怎么保证空间分析结果仍与之前兼容?
**答辩学生:**①调用官方授权接口时将返回的"火星坐标"用国测局解密库转成 WGS84,统一入库;②历史数据因已用 BD09 坐标,写一次性脚本批量转换,转换误差 < 2 m;③空间分析算法全部基于 WGS84,这样无论来源新旧,最终结果在同一基准,不影响热力图与商圈推荐。
评委老师7:系统声称能提供"商圈推荐",但仅依据现有店铺密度可能陷入"过热"区域,如何把人口密度、客流、租金等外部因子量化并加入推荐评分?
**答辩学生:**①购买或合作获取 250 m×250 m 网格人口与客流大数据(手机信令),租金用商铺挂牌均价;②对三类指标做 Min-Max 归一化,权重 0.4/0.4/0.2,加权得"潜力分";③用 XGBoost 训练已开店"月营收"与潜力分关系,取 SHAP 值解释;④推荐引擎输出 Top10 网格并给出预期营收区间,供决策者权衡进入或避开红海。
【评价总结】
H同学对爬虫策略、数据清洗与可视化性能优化均有具体措施,外部因子融合与坐标体系转换也考虑周全,具备实际落地价值。若后续补充多源数据验证与模型误差回溯,将更完善。总体表现良好,同意开题,继续推进。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告可参考。