召回率对于任何 RAG 应用程序来说都是一个非常重要的指标。它虽然只是衡量检索系统为给定用户问题进行搜索或找到正确文档的能力。
但是,这会强烈影响生成的结果的好坏--无论我们是在构建聊天机器人还是其他类似的应用。
大多数人现在都知道这一点:如果你不为 LLM 提供必要的上下文,无论你在RAG链的末端做多少提示工程,它都无法产生好的结果。
因此,在RAG中,获得良好结果的最大因素(通常)是良好的检索。我们衡量这一点的方法就是用召回率。
设置: 经典的 RAG 管线
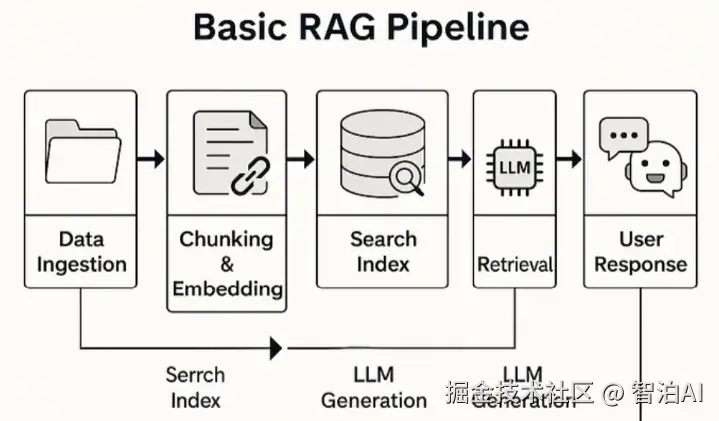
从高层次视角来看,这是一个非常经典的 RAG 项目。我们构建了一个供内部使用的聊天机器人,专门供客户服务人员更快地查找信息。
基本流程:
从不同的客户系统和数据库获取数据
预处理数据: 分块、嵌入和所有常见的 RAG内容
从这些文档块构建搜索索引
将聊天机器人连接到该搜索索引,以便用户可以用自然语言提问
机器人从索引中检索相关文档,然后使用该文档生成响应。简单、标准的 RAG。
初始版本: 朴素的方法
我们的第一个朴素版本看起来像这样
在索引方面:
我们清理了来自不同系统的数据
把它切成小块
创建了用于向量搜索的嵌入
将这些块和嵌入向量加载到矢量数据库(在本例中为 Azure Al搜索)中。
我们有各种各样的数据,但对于这个例子,我们将重点介绍两种文档类型:位置和专家。
这位客户在水疗和健康空间。他们有:
水疗中心和健身房等位置,每个位置都有包括服务(例如护理、按摩)、机器、城市和地区在内的描述。
按摩治疗师和私人教练等专家,具有类似的服务描述。
我们将所有相关字段(描述、城市、地区)合并到一个内容字段中以进行文本搜索。我们还创建了该字段的嵌入以进行向量搜索。
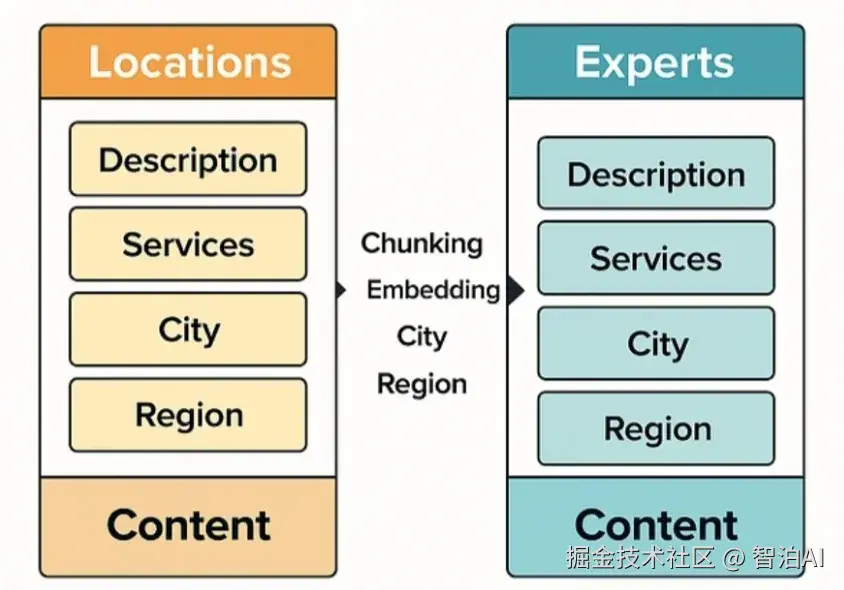
将"位置"和"专家"作为统一的内容文档进行可视化比较 - 旨在清晰、干净地编制索引
在前端:
用户会键入类似的内容: "赫尔辛基的瑞典式按摩"。
然后,我们将按以下任一方式运行该查询:
针对内容向量字段的向量搜索,或
针对内容字段的全文 BM25 搜索。
我们尝试了两者--但都遇到了问题。
为什么它不起作用?
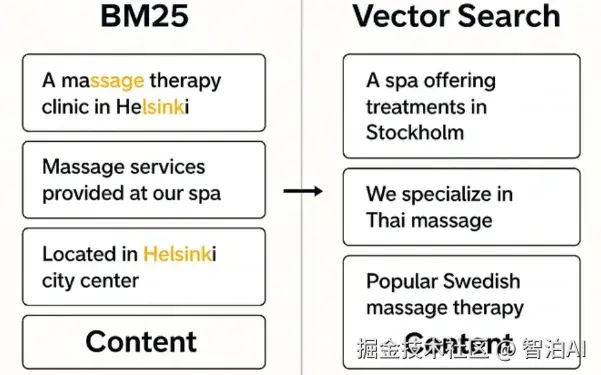
比较 BM25 与使用 ai 制作的矢量搜索结果
矢量搜索
这完全不行。
虽然向量搜索非常适合模糊匹配和语义相似性,但在我们的例子中,我们需要完全匹配--服务和位置。
相反,矢量搜索会返回类似的服务或城市(如芬兰的其他按摩店或其他首都),但并不完全是用户要求的内容。没有帮助。
BM25型
稍微好一点,但仍然不好
BM25 根据搜索词的频率对文档进行排名。这听起来没问题,直到你意识到:
一份多次提及"按摩"和随机提及"瑞典肉丸"的文件可能比真正的赫尔辛基水疗中心提供瑞典式按摩的排名更高--只是因为术语频率。
它不优先考虑完全匹配,而这正是我们的主要需求。
其他问题
我们还遇到了
共轭问题--特别是因为该项目是芬兰语的。例如,"in Helsinki"以不同的方式变位,如果变位与用户查询不完全匹配,BM25 将找不到它。
解决方法:在 LLM 辅助下进行结构化搜索以下是我们如何解决这个问题并将回忆率提高到95% 以上的方法。
第1步: 修改索引
我们在搜索索引中添加了一个新字段:services作为结构化列表,而不是将它们嵌入到自由格式描述中。
但这些数据无法直接获得,因此我们在索引期间使用LLM提取服务。
例如,从位置或专家描述中,我们会提示 LLM 生成:

然后,我们完全删除了向量嵌入--它们对我们的需求没有用处。
第2步: 转换查询
这才是真正的游戏规则改变者。
我们现在没有将用户的原始查询直接传递到搜索中,而是使用 LLM 将查询构建为如下格式:

这样,我们就可以对城市和服务字段运行精确的筛选查询,只获取完全匹配的文档。
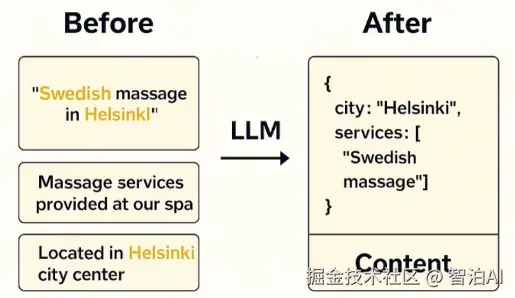
展示如何使用 AI制作的结构对查询进行转换和索引
结果
在实施这些更改后,我们又进行了一轮用户测试结果很明显:
召回率从 50-60% 跃升至近 100%
以前的大多数问题都已得到解决
只剩下少数边缘情况,主要是由于数据质量差

直观地显示使用 AI进行的召回改进
权衡
1.索引现在更昂贵,因为我们使用 LLM 来提取服务。但这个工具是为数百名内部用户构建的,为他们节省了数千小时,因此非常值得。
2.前端有轻微延迟。我们添加了一个额外的LLM 交互,以在检索之前构建查询。但它很快: 输入和输出短,我们在这里使用了一个小模型。
最后的思考
这是一个巨大的胜利,通过相对简单和直观的改变来实现。
有时你不需要Agentic RAG 或研究论文中的其他流行技术。你只需要清楚地了解你的实际问题。
在我们的例子中,用户需要特定服务位置查询的精确匹配。这为我们指明了结构化过滤作为解决方案的方向。
虽然 RAG 通常意味着检索增强生成,但它也反过来工作。有各种巧妙的方法可以使用 LLM 来构建更好的检索。
希望对你有所帮助!