一、循环神经网络基本概念
循环神经网络(RNN)作为人工神经网络的一种,其核心特性在于能够处理具有时序依赖的数据。
与传统神经网络不同,常规神经网络(如卷积神经网络)通常独立处理每个输入输出样本,例如图像分类中每张图片的特征提取互不关联。
而RNN通过记忆机制捕捉序列数据的前后关联性。以句子"我想吃北京烤鸭"为例:
首字"我"作为主语,会引导后续动词"吃"的出现概率提升;
动词"吃"进一步约束后续名词类型,使"食物"类词汇(如"烤鸭")的生成概率显著高于其他名词;
地域词"北京"与食物"烤鸭"的搭配也受到前文语义的直接影响。
这种序列建模能力使RNN在自然语言处理、时序预测等深度学习领域成为不可替代的工具。
二、为什么需要RNN
CNN存在两个主要局限性:其一,其特征传递是单向的,导致同层特征间缺乏交互;其二,输入层要求固定长度特征(例如100个单元),若需扩充输入信息则处理难度较大。
CNN更擅长处理二维图像数据,能够提取并归纳图像的深层特征。
然而现实场景中存在大量随时间演变的数据(如气温年度波动、人体生理信号、陀螺仪输出等),这类时序数据具有显著的时间依赖性,前后数据存在关联性。
因此需要一种能够保留历史特征记忆的模型,这正是RNN的用武之地。
三、最简单的RNN模型
大家应该都见过网上这类图片吧?左图简洁到抽象,但第一眼真让人摸不着头脑。
转到右侧的时间展开图就清晰多了:初始状态h0之后,依次排列着4个时间步的输入x1到x4。
这些特征可能是向量/矩阵,甚至单个数值,但那个h到底代表什么?还是得继续往下看才能明白。
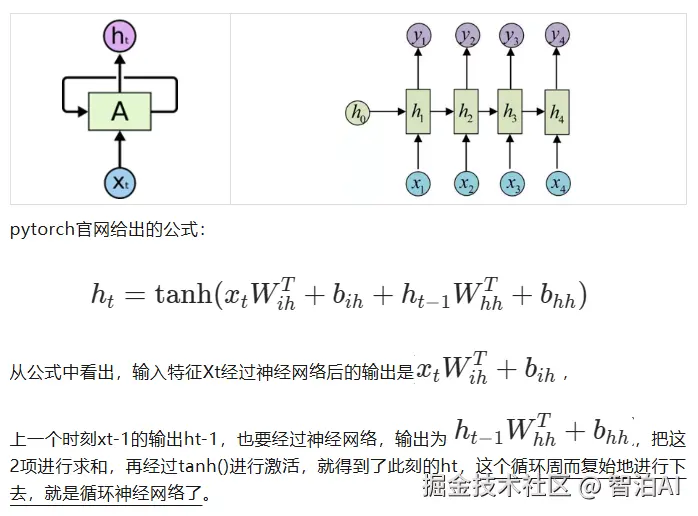
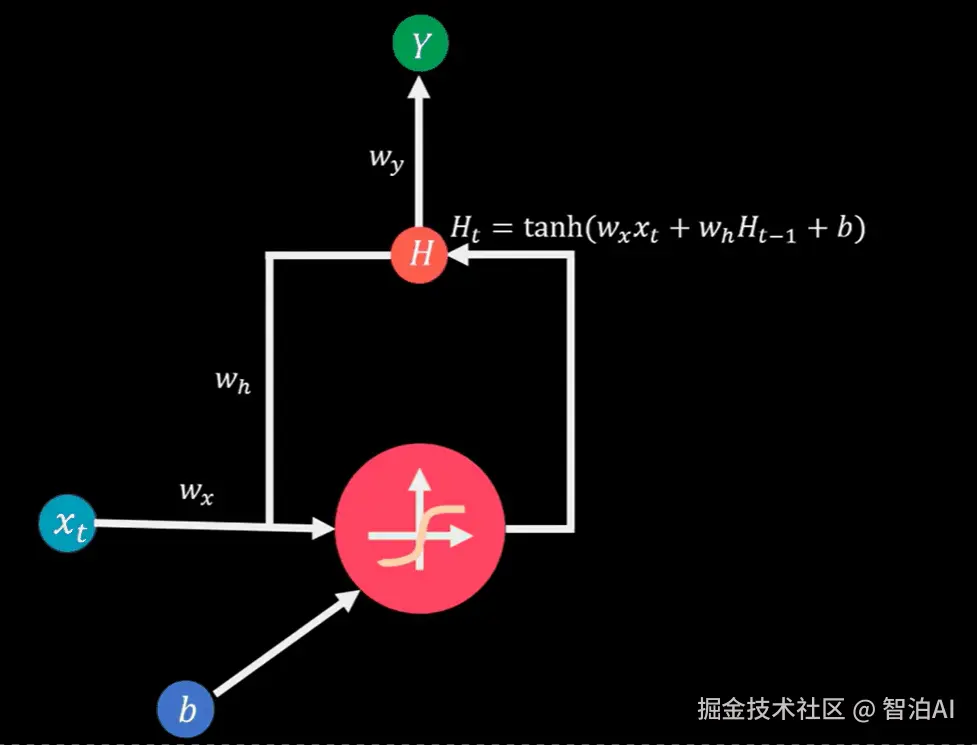
看下面这个图,表达的就很清楚了,Wih就是输入到神经网络的权重参数,与输入有关,所以用i。Whh是隐藏层到神经网络的权重参数,所以用h标记,b就是偏置了。
ht-1和xt都是神经网络的输入,与各自的权重系数相乘,再加上偏置,就是标准的神经元运算过程,只不过后面加了一步求和再激活,h的数值和过去有关,相当于一个记忆。
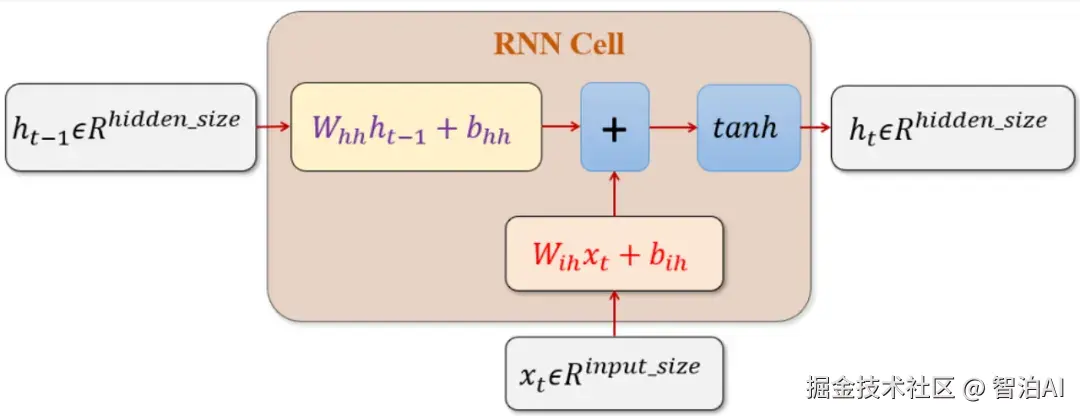
为了更清晰地展示细节,下图直观呈现了关键结构。需特别说明的是,图中虽显示为两个隐藏层,但实际为同一隐藏层在不同时间步的复用。
由于各时间步的权重矩阵存在差异,因此隐藏层的运算结果也会相应变化。该图完整展示了RNN单步的计算流程,理解此图即可掌握RNN的核心原理。
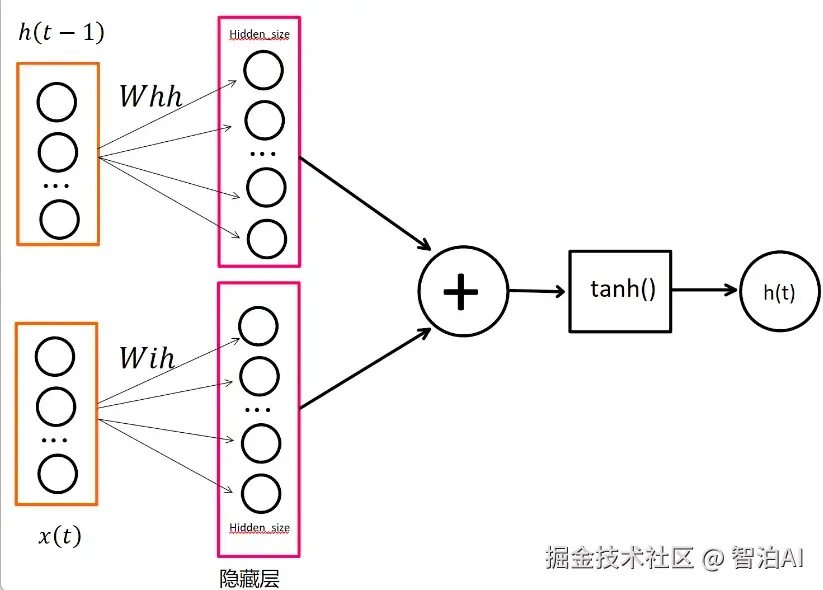
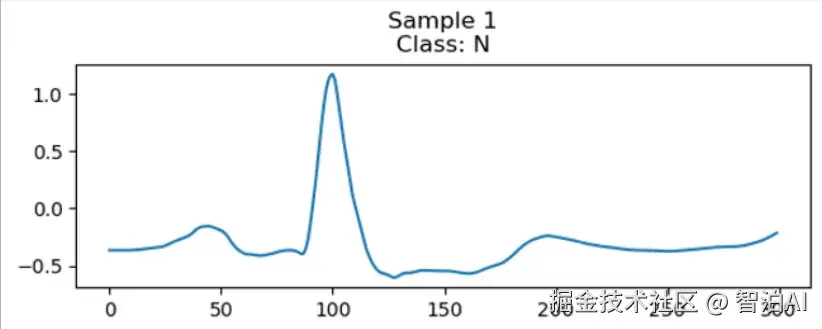
输入特征x的维度取决于数据本身的性质:例如在气候分析场景中,通常将风速、大气温度、相对湿度等作为特征变量;而对于心电信号而言,输入特征则是单通道体表电位测量值。
如图示案例所示,心电信号的时间序列包含300个采样点(即300个时间步长),由于每个时间步仅对应1个测量值,因此其特征维度为1。
隐藏层中神经元的数量由hidden_size参数决定,显然,神经元数量增加会导致计算量上升。
接下来说明RNN为何能适应变长输入。
观察下方动图可知,在自然语言处理中,每个词作为独立的输入特征按序传递即可,句子长度不会构成限制,本质上只需增加数据传递的频次。
但是,RNN的计算复杂度是和序列长度(时间步长度)呈线性关系的。
RNN的隐藏层可以不只1层,但是一般不超过3层。
四、双向RNN
传统的RNN结构模型仅能处理历史时序数据,无法纳入未来信息。
为解决这一局限,双向RNN结构通过将输入特征序列进行倒序排列,并在模型中引入反向传播隐藏层,最终将反向传播结果与前向输出相结合作为整体输出。
以隐藏层神经元数量为25为例,每个时间步的输出结果会由正向25维和反向25维数据共同构成,形成50维的最终输出特征。
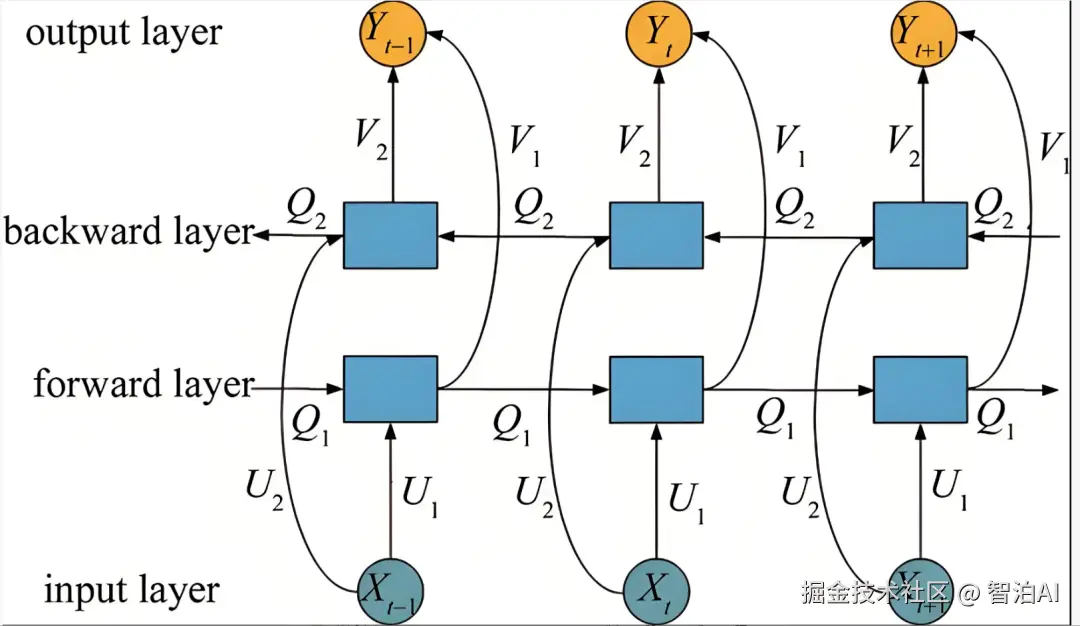
通过提取最终时间步的输出特征,该特征已整合了所有输入时间步的信息,从而有效捕捉时序数据的动态关联性。
对于分类任务,仅需在模型末端叠加全连接层即可实现类别预测。
五、重要参数
先看pytorch官网对于RNN的模型定义

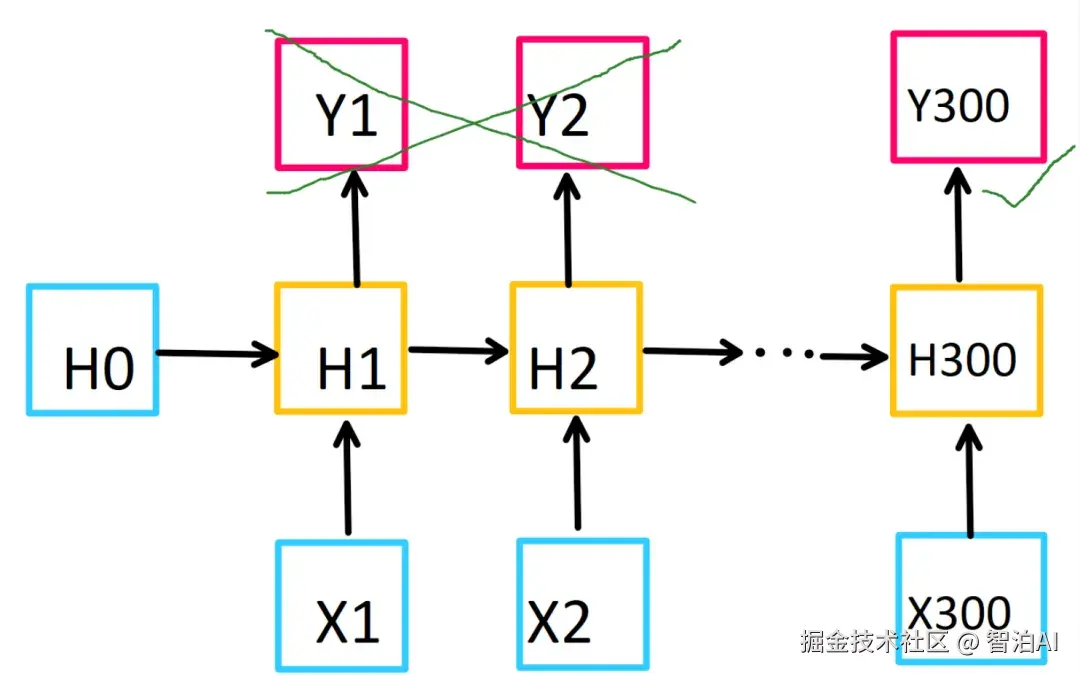
下面结合实例来看一下,这个RNN模型接收上面的心电信号,共300个采样数据,也就是300个时间步,每次输入的特征只有一个:

该RNN模型采用单样本输入方式,每个样本包含300个采样点。模型在内部会执行300次迭代计算,由于配置了50个神经元,因此每次迭代都会产生一个50维的输出向量。
在训练过程中,我们仅保留最终时间步(第300步)的输出结果Y300,将其作为特征输入到全连接层。
通过构建一个从50维特征空间到5类输出的神经网络映射关系,最终实现五分类任务。
具体实现方式如图所示:提取Y300中的50个特征维度,建立50到5的线性变换结构完成分类输出。
六、结语
有了上面的RNN模型基础,针对RNN模型的很多变种,如LSTM、GRU等,就可以很快理解并使用了。