前言:
这个系列记录了我学习面向语言Java的完整过程,可以当作笔记使用。
每篇文章都包含可运行的代码示例和常见错误分析,尤其适合没有编程经验的读者。学习时建议先准备好安装JDK(Java Development Kit)和IDEA(IntelliJ IDEA集成开发环境),随时尝试修改示例代码。
集合框架:
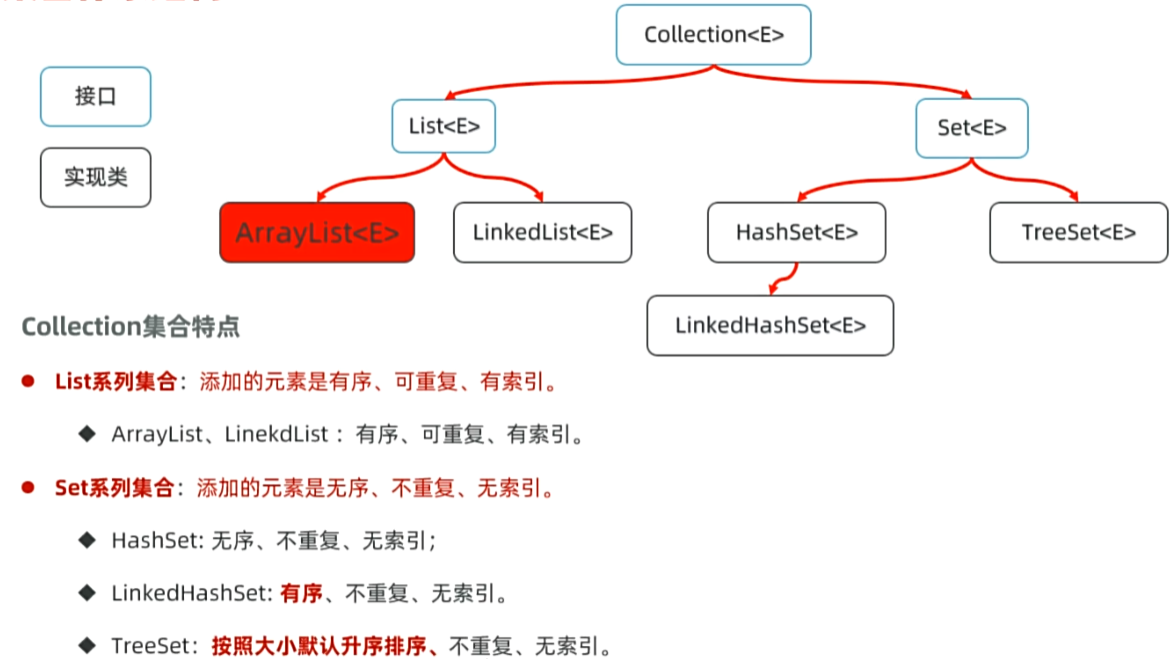
一,认识集合:
1,介绍:

2,集合体系结构:

二,Collection集合:
1,介绍:
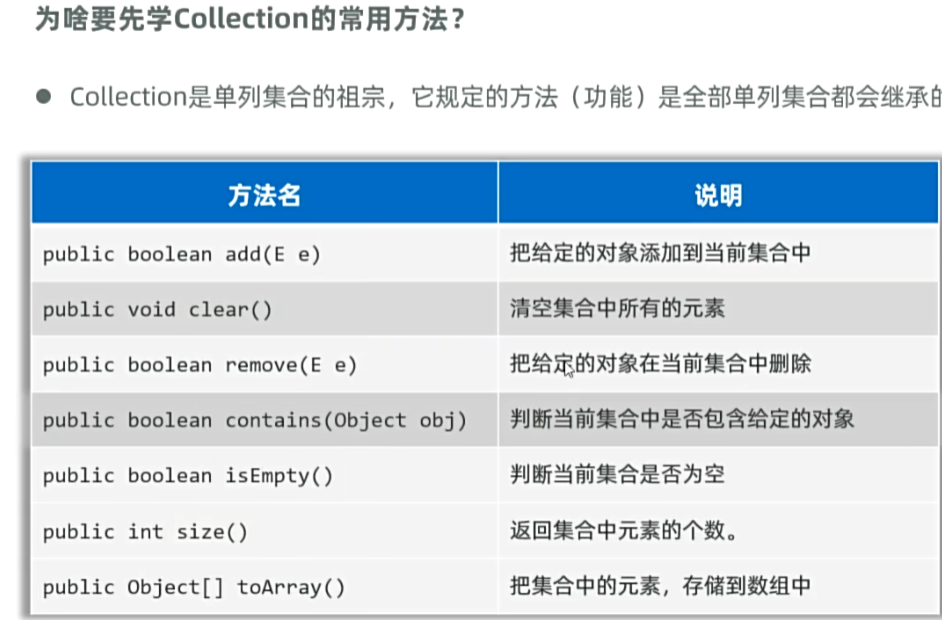
2,Collection的常用方法:
3,Collection的三种遍历方式:
I,迭代器遍历:

示例:
java
public static void main(String[] args) {
//目标:掌控Collection的遍历方式一:迭代器
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
System.out.println(list);
//1,得到这个集合的迭代器对象
Iterator<String> it = list.iterator();
while (it.hasNext()) {
//2,调用next方法,获取集合中的元素
String s = it.next();//迭代器会得到当前的元素,并移动到下一个位置
System.out.println(s);
}
}
II,增强for循环遍历:

示例:
java
public static void main(String[] args) {
//目标:掌控Collection的遍历方式二:增强for
ArrayList<String> list = new ArrayList<>();//集合
list.add("hello");
list.add("world");
list.add("java");
for(String s:list){
System.out.println(s);
}
String[] arr = {"hello","world","java"};//数组
for(String s:arr){
System.out.println(s);
}
}
III,Lambda表达式遍历:

示例:
java
public static void main(String[] args) {
//目标:掌控Collection的遍历方式三:lambda
ArrayList<String> list = new ArrayList<>();//集合
list.add("hello");
list.add("world");
list.add("java");
// list.forEach(new Consumer<String>() {
// @Override
// public void accept(String s) {
// System.out.println(s);
// }
// });
//lambda表达式简化
list.forEach(s -> System.out.println(s));
}
IV,三种遍历方式的区别:
认识并发修改异常问题:

示例:
public static void main(String[] args) {
//目标:认识并发修改异常问题,高清楚每种遍历的区别
ArrayList<String> list = new ArrayList<>();
list.add("Java入门");
list.add("宁夏枸杞");
list.add("黑枸杞");
list.add("枸杞子");
list.add("特级枸杞");
//需求1:删除全部枸杞
for(int i=0;i<list.size();i++){
String s = list.get(i);
if(s.contains("枸杞")){
list.remove(s);
}
}
System.out.println(list);//[Java入门, 黑枸杞, 特级枸杞]
//出现并发修改异常
System.out.println("===================================");
//解决方案1:
ArrayList<String> list2 = new ArrayList<>();
list2.add("Java入门");
list2.add("宁夏枸杞");
list2.add("黑枸杞");
list2.add("枸杞子");
list2.add("特级枸杞");
for(int i=0;i<list2.size();i++){
String s = list2.get(i);
if(s.contains("枸杞")){
list2.remove(s);
i--;
}
}
System.out.println(list2);
System.out.println("===================================");
//解决方案2:
ArrayList<String> list3 = new ArrayList<>();
list3.add("Java入门");
list3.add("宁夏枸杞");
list3.add("黑枸杞");
list3.add("枸杞子");
list3.add("特级枸杞");
for(int i=list3.size()-1;i>=0;i--){
String s = list3.get(i);
if(s.contains("枸杞")){
list3.remove(s);
}
}
System.out.println(list3);
System.out.println("===================================");
ArrayList<String> list4 = new ArrayList<>();
list4.add("Java入门");
list4.add("宁夏枸杞");
list4.add("黑枸杞");
list4.add("枸杞子");
list4.add("特级枸杞");
//迭代器遍历删除也存在并发修改异常问题
//可以解决:使用迭代器直接的方法来删除
Iterator<String> it = list4.iterator();
while(it.hasNext()){
String s = it.next();
if(s.contains("枸杞")){
//list4.remove(s);//出现并发修改异常
it.remove();
}
}
System.out.println(list4);
//如果用增强for循环和Lambda表达式来删除,也会出现并发修改异常
//结论:增强for循环和Lambda只适合做遍历,不适合做遍历并修改操作
// for(String s:list4){
// if(s.contains("枸杞")){
// list4.remove(s);
// }
// }
// System.out.println(list4);
// list4.forEach(s -> {
// if(s.contains("枸杞")){
// list4.remove(s);
// }
// });
// System.out.println(list4);
}总结:
解决并发修改异常问题的方案:

4,List家族的集合:
I,List集合的特有方法:
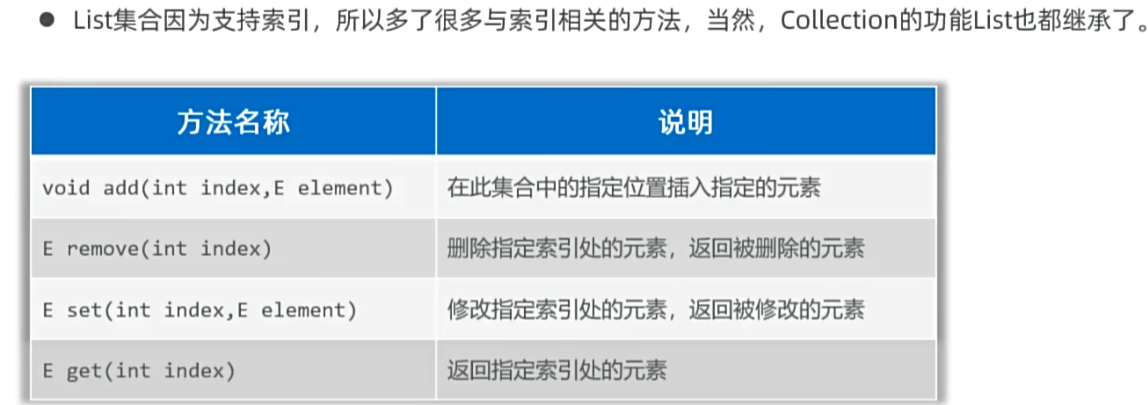
示例:
public static void main(String[] args) {
//目标:搞清楚Collection集合的整体特点
//1,List家族的集合,有序、可重复、有索引
List<String> list = new ArrayList();//多态性
list.add("hello");
list.add("world");
list.add("java");
System.out.println(list);//[hello, world, java]
list.add(1,"鸿蒙");//索引插入
System.out.println(list); // [hello, 鸿蒙, world, java]
list.remove(0);//索引删除
System.out.println( list);// [鸿蒙, world, java]
list.set(2,"java精通");//索引修改
System.out.println(list);// [鸿蒙, world, java精通]
System.out.println(list.get(0));//索引访问 输出:鸿蒙
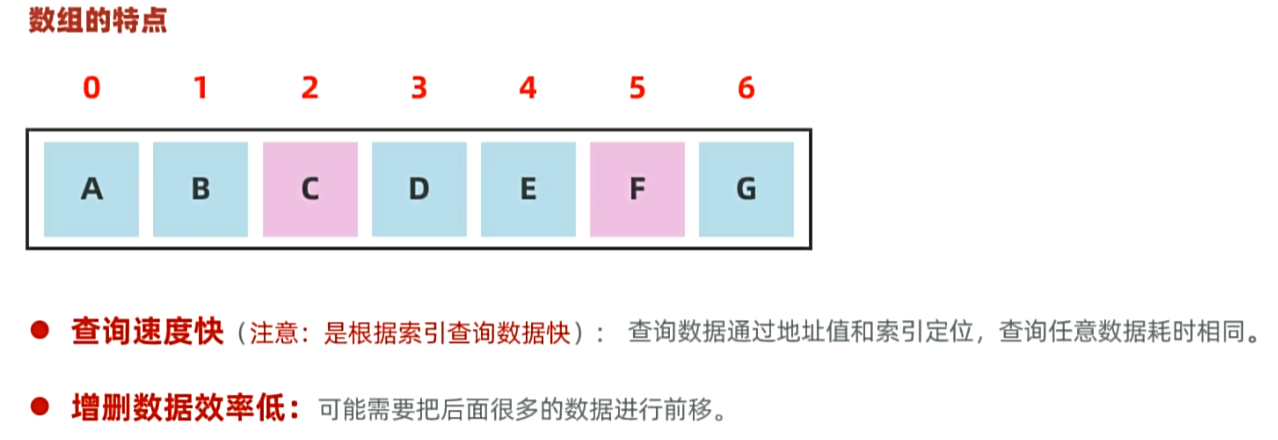
}II,ArrayList 的底层原理:

III,LinkedList 的底层原理:
基于双链表实现:



IV,LinkedList新增了很多首尾操作的特有方法:
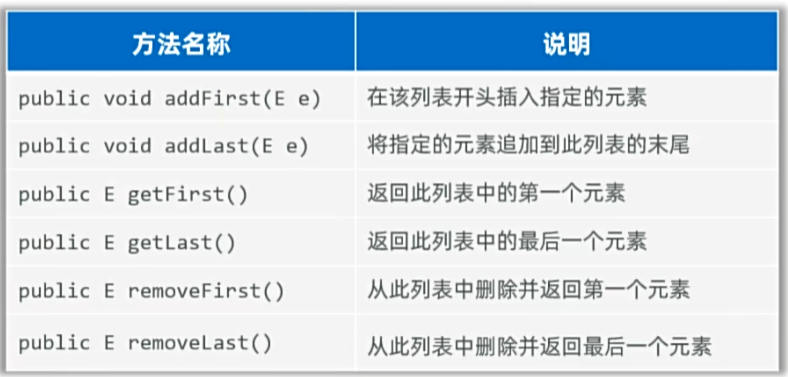
V,LinkedList的常见应用场景:
设计队列:

设计栈:
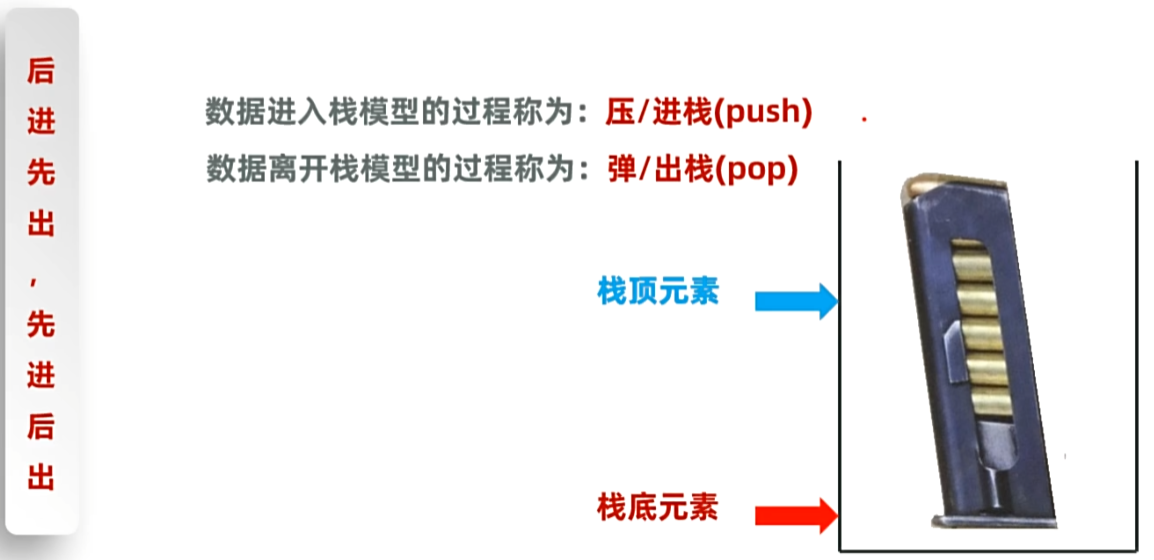
注:方法push 跟方法addFirst 用法作用相同,方法pop 跟方法removeFirst 也用法作用相同,
方法push 是方法addFirst 的包装,方法pop 是方法removeFirst的包装。
5,Set家族的集合:
I,认识:
public static void main(String[] args){
//目标:认识Set家族集合的特点
//1,创建一个Set集合,特点:无序、不可重复、无索引
Set<String> set = new HashSet<>();//无序、不可重复、无索引
//Set<String> set = new LinkedHashSet<>();//有序、不可重复、无索引
set.add("hello");
set.add("hello");
set.add("world");
set.add("world");
set.add("java");
set.add("java");
set.add("鸿蒙");
set.add("大数据");
System.out.println(set);//[java, 鸿蒙, 大数据, world, hello]
//2,创建一个TreeSet集合,特点:有序(默认一定按大小升序排列)、不可重复、无索引
Set<Double> set1 = new TreeSet<>();
set1.add(10.0);
set1.add(10.0);
set1.add(5.0);
set1.add(20.0);
set1.add(15.0);
System.out.println(set1);//[5.0, 10.0, 15.0, 20.0]
Set<String> set2 = new TreeSet<>();
set2.add("hello");
set2.add("world");
set2.add("java");
System.out.println(set2);//[hello, java, world]
}II,HashSet集合的底层原理:
注:当前数组元素不为null的数量超过(当前数组长度 * 默认加载因子 )(例如:16*0.75=12)的时候则进行扩容,扩容到原来的2倍。



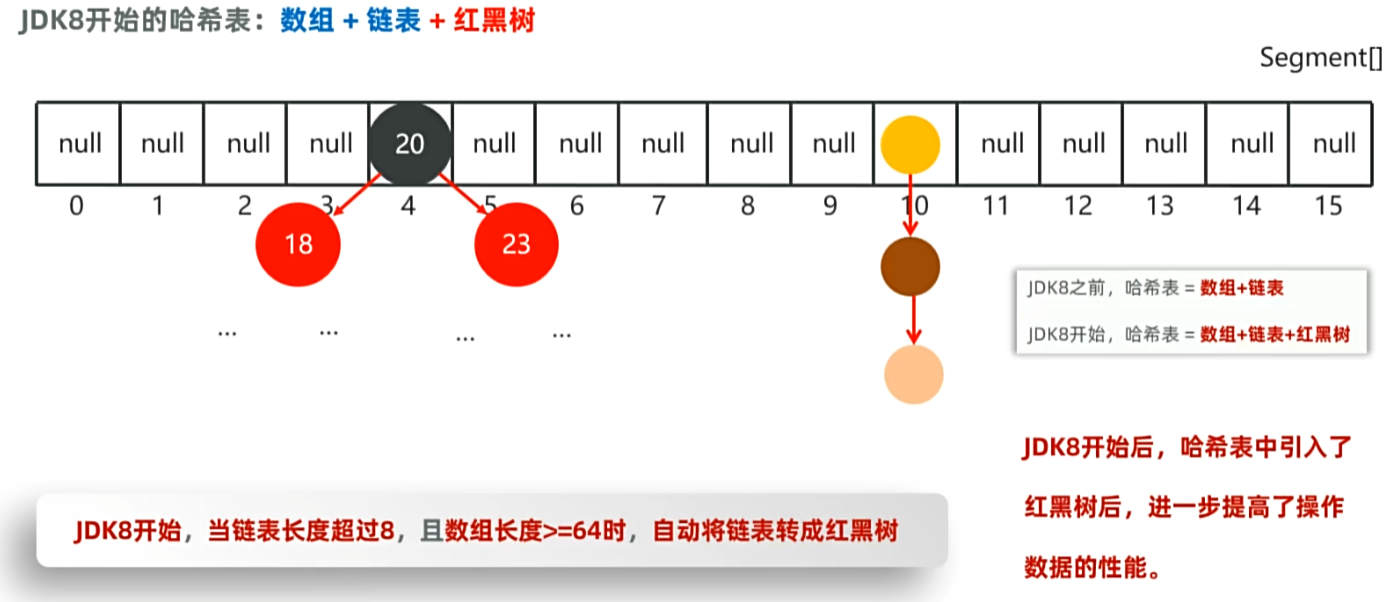
III,HashSet 集合元素的去重操作:
HashSet 集合去重复的机制:

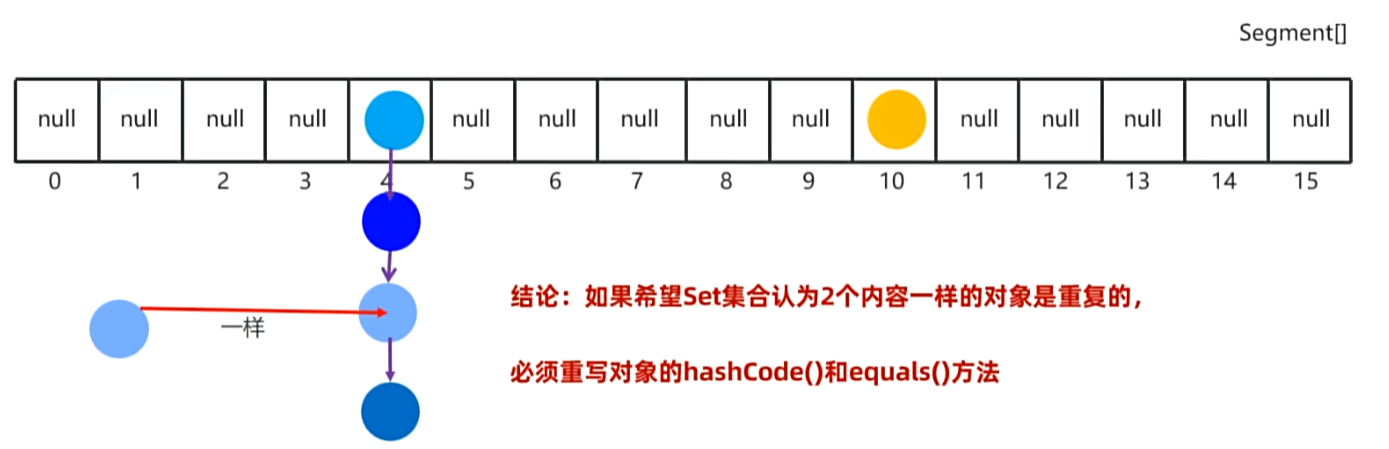
示例:
import java.util.HashSet;
public class SetDemo2 {
public static void main(String[] args){
//目标:掌握HashSet集合去重操作
Student s1 = new Student("张三", 18);
Student s2 = new Student("张三", 18);
Student s3 = new Student("李四", 28);
Student s4 = new Student("李四", 28);
HashSet<Student> set = new HashSet<>();
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
System.out.println(set);
}
}
public class Student {
private String name;
private int age;
//getset方法
//省略......
//有参、无参构造
//省略......
// 只要两个对象的内容一样结果一定是 true。
// s3.equals (s1)
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}'+"\n";
}
}运行结果:

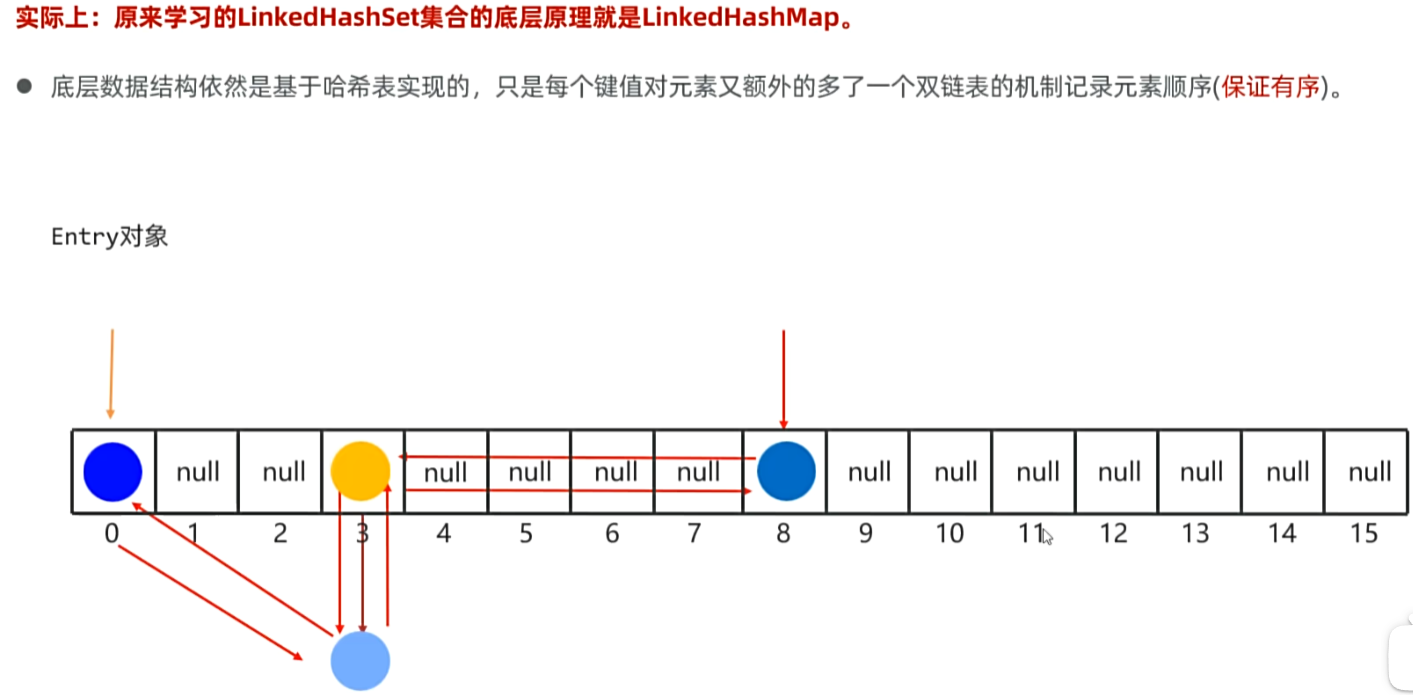
IV,LinkedHashSet 的底层原理:
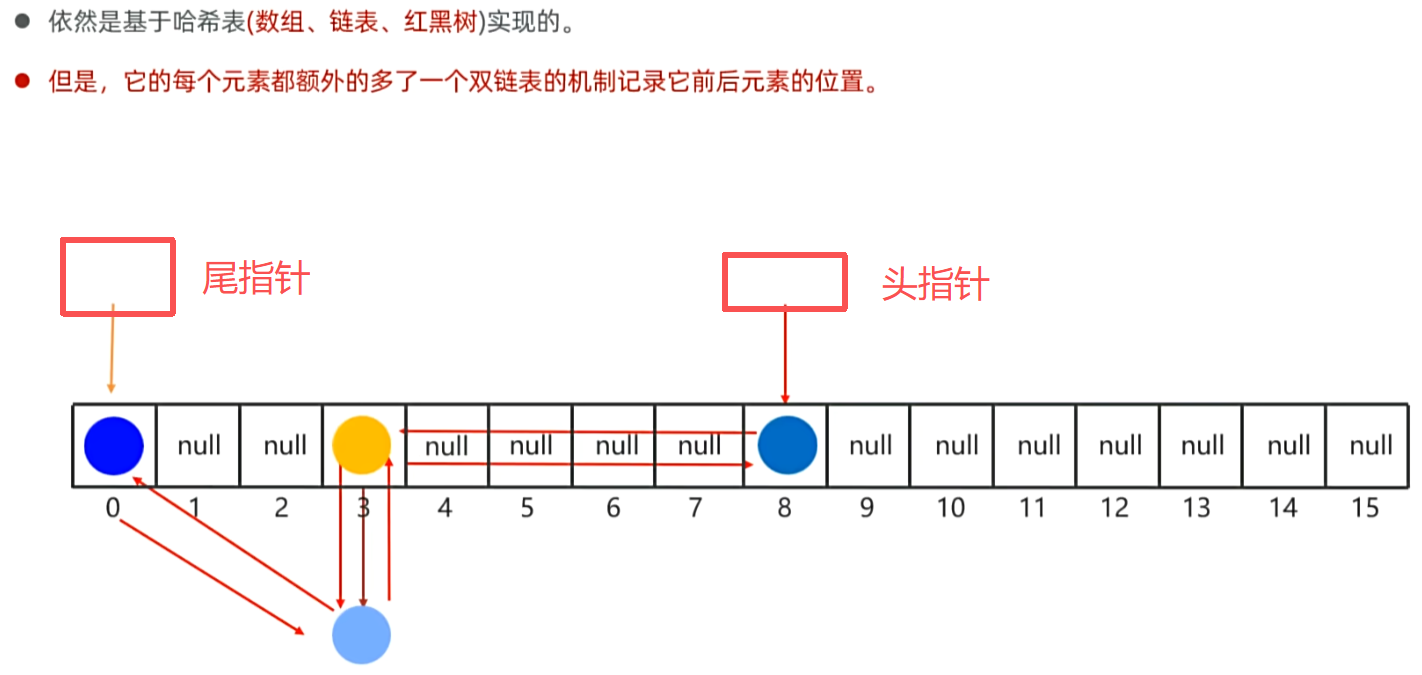
V,TreeSet集合(指定大小排序规则):



结论:TreeSet集合默不能给自定义对象排序,因为不知道大小规则
如果一定要解决在,怎么办?两种方案:
1,对象类实现一个Comparable****接口,并重写compareTo方法,指定大小排序规则
import java.util.Set;
import java.util.TreeSet;
public class SetDemo3 {
public static void main(String[] args){
//目标:搞清楚TreeSet集合对于自定义对象的排序
Set<Teacher> set = new TreeSet<>();//排序、不重复、无索引
set.add(new Teacher("张三", 28, 3000));
set.add(new Teacher("李四", 21, 14000));
set.add(new Teacher("小赵", 18, 5000));
set.add(new Teacher("小虎", 8, 2000));
System.out.println(set);
//结论:TreeSet集合默不能给自定义对象排序,因为不知道大小规则
//如果一定要解决在,怎么办?两种方案
//1,对象类实现一个Comparable接口,并重写compareTo方法,指定大小排序规则
//2,public TreeSet(Comparator c)集合自带比较器Comparator对象,指定比较规则
}
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data//getset方法
@AllArgsConstructor//有参构造
@NoArgsConstructor//无参构造
public class Teacher implements Comparable<Teacher> {
//姓名、年龄、工资
private String name;
private int age;
private double salary;
@Override
public String toString() {
return "Teacher{" +
"name='" + name + '\'' +
", age=" + age +
", salary=" + salary +
'}'+"\n";
}
//t2.compareTo (t1)
// t2 == this 比较者
// t1 == o 被比较者
// 规定 1:如果你认为左边大于右边 请返回正整数
// 规定 2:如果你认为左边小于右边 请返回负整数
// 规定 3:如果你认为左边等于右边 请返回 0
// 默认就会升序。
@Override
public int compareTo(Teacher o) {
return this.getAge() - o.getAge();
}
}
运行结果:
2,public TreeSet(Comparator c)集合自带比较器Comparator对象,指定比较规则
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class SetDemo3 {
public static void main(String[] args){
//目标:搞清楚TreeSet集合对于自定义对象的排序
Set<Teacher> set = new TreeSet<>(new Comparator<Teacher>() {
@Override
public int compare(Teacher o1, Teacher o2) {
// if (o1.getSalary() > o2.getSalary())
// return 1;
// else if (o1.getSalary() < o2.getSalary())
// return -1;
// return 0;
// return o1.getSalary() > o2.getSalary() ? -1 : o1.getSalary() < o2.getSalary() ? 1 : 0;
return Double.compare(o1.getSalary(), o2.getSalary());
}
});//排序、不重复、无索引
set.add(new Teacher("张三", 28, 3000));
set.add(new Teacher("李四", 21, 14000));
set.add(new Teacher("小赵", 18, 5000));
set.add(new Teacher("小虎", 8, 2000));
System.out.println(set);
//结论:TreeSet集合默不能给自定义对象排序,因为不知道大小规则
//如果一定要解决在,怎么办?两种方案
//1,对象类实现一个Comparable接口,并重写compareTo方法,指定大小排序规则
//2,public TreeSet(Comparator c)集合自带比较器Comparator对象,指定比较规则
}
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data//getset方法
@AllArgsConstructor//有参构造
@NoArgsConstructor//无参构造
public class Teacher{
//姓名、年龄、工资
private String name;
private int age;
private double salary;
@Override
public String toString() {
return "Teacher{" +
"name='" + name + '\'' +
", age=" + age +
", salary=" + salary +
'}'+"\n";
}
}运行结果:

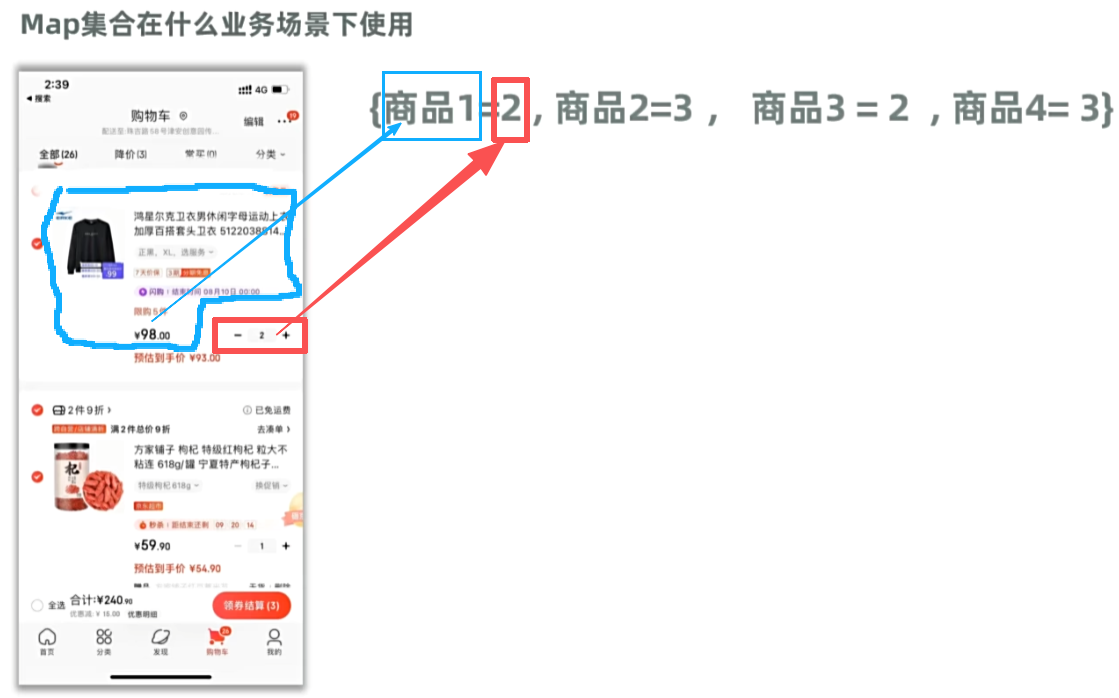
三,Map集合:
1,介绍:


java
public static void main(String[] args) {
//目标:认识Map集合的体系特点
//1,创建Map集合
//HasgMap特点:无序、不重复、无索引,键值对都可以是null,值不做要求(可以重复)
// LinkedMap 特点:有序,不重复,无索引,键值对都可以是 null,值不做要求(可以重复)
// TreeMap:按照键可排序,不重复,无索引
Map<String,Integer> map = new HashMap<>();//多态
map.put("洗衣液",40);
map.put("洗衣液",55);
map.put("水杯",10);
map.put("羽毛球拍",20);
map.put("游戏机",1000);
map.put(null,null);
System.out.println(map);//{null=null, 水杯=10, 游戏机=1000, 洗衣液=55, 羽毛球拍=20}
}
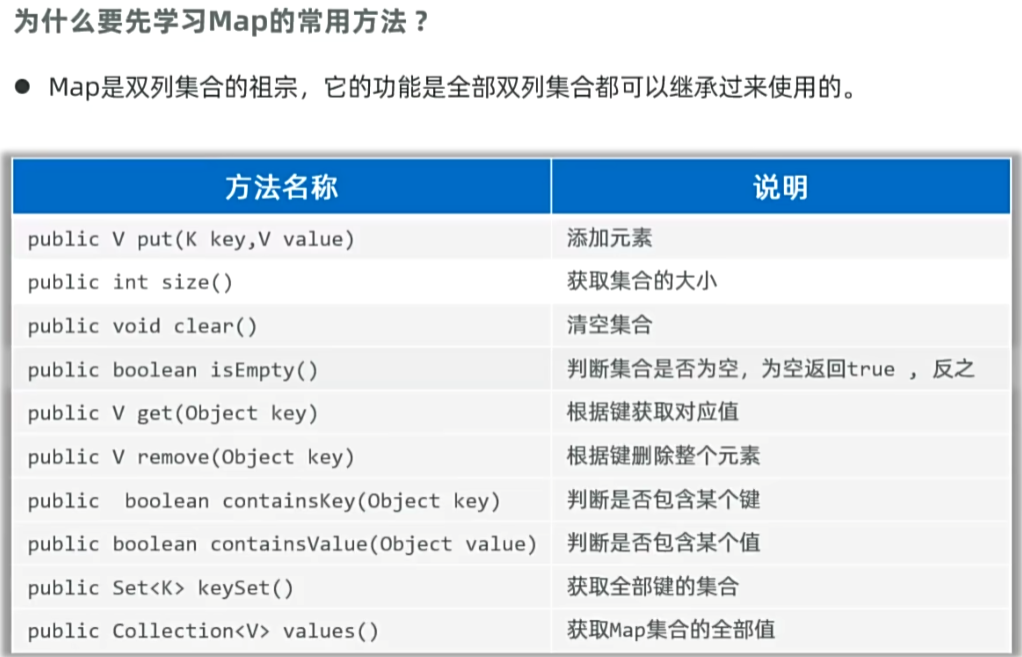
2,Map集合的常用功能:
3,keySet、values方法的示例:
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();//多态
map.put("洗衣液",40);
map.put("洗衣液",55);
map.put("水杯",10);
map.put("羽毛球拍",10);
map.put("游戏机",1000);
map.put(null,null);
System.out.println(map);//{null=null, 水杯=10, 游戏机=1000, 洗衣液=55, 羽毛球拍=20}
//keySet方法:获取所有的键,放到一个Set集合返回给我们
Set<String> keys = map.keySet();
for(String key:keys){
//通过key获取value
System.out.print(key+" ");
}
System.out.println();//换 行
//values方法:获取所有的值,放到一个Collection集合返回给我们
Collection<Integer> values = map.values();
for(Integer value:values){
System.out.print(value+" ");
}
}运行结果:

4,Map的三种遍历方式:
I,第一种(键找值):

示例:
public static void main(String[] args) {
//目标:掌握Map集合的遍历方式一:键找值
Map<String,Integer> map = new HashMap<>();//多态
map.put("洗衣液",40);
map.put("洗衣液",55);
map.put("水杯",10);
map.put("羽毛球拍",10);
map.put("游戏机",1000);
map.put(null,null);
System.out.println(map);//{null=null, 水杯=10, 游戏机=1000, 洗衣液=55, 羽毛球拍=20}
// 1、提取Map集合的全部键到一个Set集合中去
Set<String> keys = map.keySet();
// 2、遍历Set集合,得到每一个键
for (String key : keys) {
// 3、根据键去找值
Integer value = map.get(key);
System.out.println(key + "=" + value);
}
}运行结果:

II,第二种(键值对):

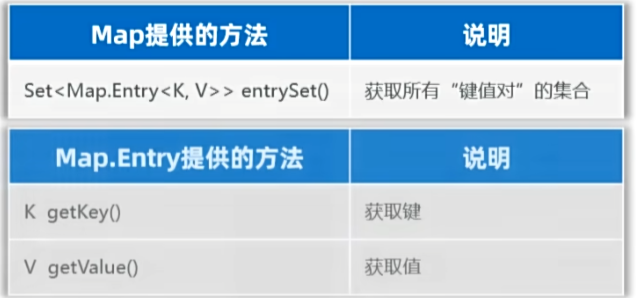
示例:
public static void main(String[] args) {
//目标:掌握Map集合的遍历方式二:键值对
Map<String,Integer> map = new HashMap<>();//多态
map.put("洗衣液",40);
map.put("洗衣液",55);
map.put("水杯",10);
map.put("羽毛球拍",10);
map.put("游戏机",1000);
System.out.println(map);//{null=null, 水杯=10, 游戏机=1000, 洗衣液=55, 羽毛球拍=20}
//1,把Map集合转化为Set集合,里面的元素类型都是键值对类型(Map.Entry<String,Integer>)
/**
* map = {水杯=10, 游戏机=1000, 洗衣液=55, 羽毛球拍=10}
* ↓
* map.entrySet()
* ↓
* Set<Map.Entry<String, Integer>> entries = [(嫦娥=28), (铁扇公主=38), (紫霞=31), (女儿国王=31)]
* entry
*/
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for(Map.Entry<String,Integer> entry:entries){
//通过entry获取键和值
String key = entry.getKey();//键
Integer value = entry.getValue();//值
System.out.println(key+"="+value);
}
}注:
1,map.entrySet() 方法返回的 Set 集合中,每个元素都是 Map.Entry 接口的实现类对象
2,当我们用一个 Set 类型的变量接收这个返回值时,由于集合中元素的 "接口类型" 是 Map.Entry<K, V>
III,第三种(Lambda表达式):


示例:
public static void main(String[] args) {
//目标:掌握Map集合的遍历方式三:Lambda表达式
Map<String,Integer> map = new HashMap<>();//多态
map.put("洗衣液",55);
map.put("水杯",10);
map.put("羽毛球拍",10);
map.put("游戏机",1000);
System.out.println(map);//{水杯=10, 游戏机=1000, 洗衣液=55, 羽毛球拍=20}
// 1、直接调用Map集合的forEach方法完成遍历
// map.forEach(new BiConsumer<String, Integer>() {
// @Override
// public void accept(String k, Integer v) {
// System.out.println(k + "=" + v);
// }
// });
// Lambda表达式简化:
map.forEach((k, v) -> System.out.println(k + "=" + v));
}调用了集合map的forEach方法,里面运用了第二种方法,还会回调重写的accept方法。
5,HashMap集合的底层原理:

6,LinkedHashMap集合的底层原理:
7,TreeMap集合(指定大小排序规则):

Stream流:
一,认识Stream流:

二,获取Stream流:

示例:
public static void main(String[] args) {
// 1、获取集合的Stream流:调用集合提供的stream()方法
Collection<String> list = new ArrayList<>();
Stream<String> s1 = list.stream();//Collection集合的stream()方法
// 2、Map集合,怎么拿Stream流。
Map<String, Integer> map = new HashMap<>();
// 获取键流,keySet方法:获取所有的键,放到一个Set集合中,并返回Set集合
Stream<String> s2 = map.keySet().stream();
// 获取值流,values方法:获取所有的值,放到一个Collection集合中,并返回Collection集合
Stream<Integer> s3 = map.values().stream();
// 获取键值对流,entrySet方法:获取所有的键值对,放到一个Set集合中,并返回Set集合
Stream<Map.Entry<String, Integer>> s4 = map.entrySet().stream();
// 3、获取数组的流。
String[] names = {"张三丰", "张无忌", "张翠山", "张良", "张学友"};
// Arrays.stream(T[] array)
Stream<String> s5 = Arrays.stream(names);
System.out.println(s5.count()); // 5
//of方法:参数可以是数组,也可以是多个元素
Stream<String> s6 = Stream.of(names);
Stream<String> s7 = Stream.of("张三丰", "张无忌", "张翠山", "张良", "张学友");
}三,Stream流常用的中间方法:
1,使用步骤:
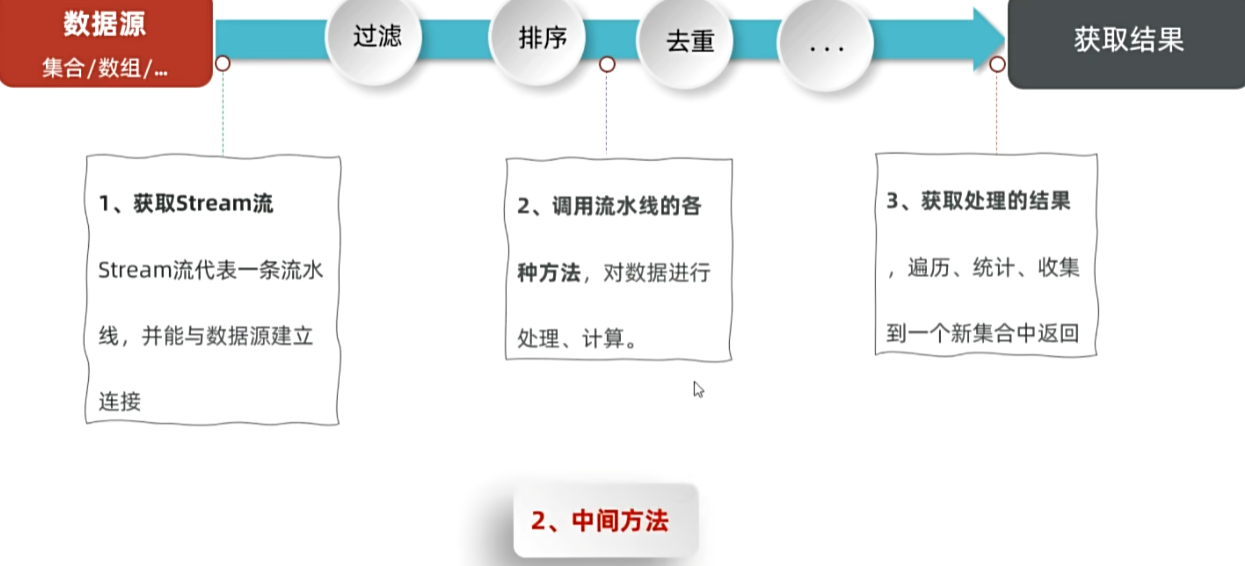
2,常用方法:

示例:
public static void main(String[] args) {
// 目标:掌握Stream提供的常用的中间方法,对流上的数据进行处理(返回新流:支持链式编程)
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.add("张翠山");
// 1、过滤方法,filter
list.stream().filter(s -> s.startsWith("张") && s.length() == 3).forEach(s -> System.out.println(s));
// 2、排序方法, sorted
List<Double> scores = new ArrayList<>();
scores.add(88.6);
scores.add(66.6);
scores.add(77.6);
scores.add(99.6);
scores.stream().sorted().forEach(s -> System.out.println(s)); // 默认是升序。
System.out.println("--------------------------------");
scores.stream().sorted((s1, s2) -> Double.compare(s2, s1)).forEach(s -> System.out.println(s)); // 降序
System.out.println("--------------------------------");
scores.stream().sorted((s1, s2) -> Double.compare(s2, s1)).limit(2).forEach(System.out::println); // 只要前2名
System.out.println("--------------------------------");
scores.stream().sorted((s1, s2) -> Double.compare(s2, s1)).skip(2).forEach(System.out::println); // 跳过前2名
System.out.println("--------------------------------");
// 如果希望自定义对象能够去重复,重写对象的hashCode和equals方法,才可以去重复!
scores.stream().sorted((s1, s2) -> Double.compare(s2, s1)).distinct().forEach(System.out::println); // 去重复
// 映射/加工方法:把流上原来的数据拿出来变成新数据又放到流上去。
scores.stream().map(s -> "加10分后:" + (s + 10)).forEach(System.out::println);
// 合并流:
Stream<String> s1 = Stream.of("张三丰", "张无忌", "张翠山", "张良", "张学友");
Stream<Integer> s2 = Stream.of(111, 22, 33, 44);
Stream<Object> s3 = Stream.concat(s1, s2);
System.out.println(s3.count());// 9 //这个新的流元素个数为9(5+4).
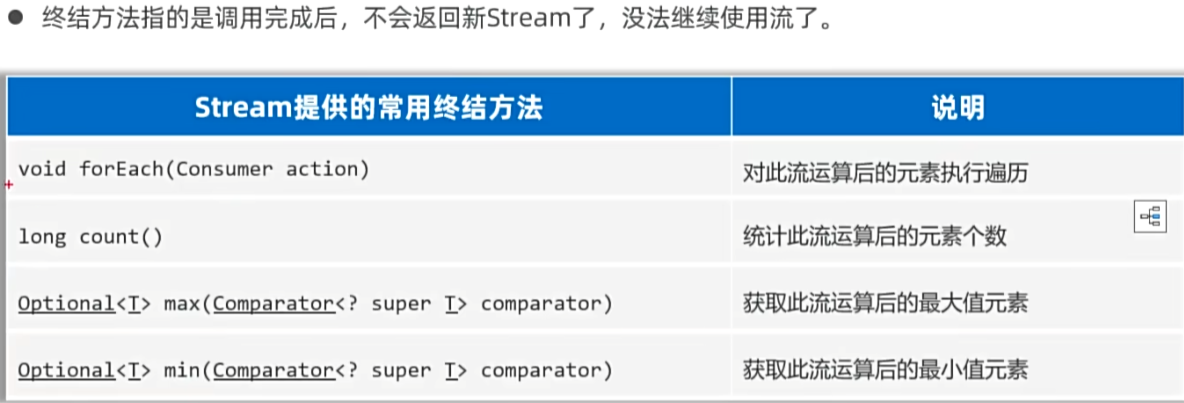
}四,终极方法,收集Stream流:
1,终极方法:
示例:
public static void main(String[] args) {
// 目标:掌握Stream流的统计,收集操作(终结方法)
List<Teacher> teachers = new ArrayList<>();
teachers.add(new Teacher("张三", 23, 5000));
teachers.add(new Teacher("金毛狮王", 54, 16000));
teachers.add(new Teacher("李四", 24, 6000));
teachers.add(new Teacher("王五", 25, 7000));
teachers.add(new Teacher("白眉鹰王", 66, 108000));
teachers.add(new Teacher("陈昆", 42, 48000));
teachers.stream().filter(t -> t.getSalary() > 15000).forEach(System.out::println);
System.out.println("-------------------------------------------------");
long count = teachers.stream().filter(t -> t.getSalary() > 15000).count();
System.out.println(count);
System.out.println("-------------------------------------------------");
// 获取薪水最高的老师对象
Optional<Teacher> max = teachers.stream().max((t1, t2) -> Double.compare(t1.getSalary(), t2.getSalary()));
Teacher maxTeacher = max.get(); // 获取Optional对象中的元素
System.out.println(maxTeacher);
Optional<Teacher> min = teachers.stream().min((t1, t2) -> Double.compare(t1.getSalary(), t2.getSalary()));
Teacher minTeacher = min.get(); // 获取Optional对象中的元素
System.out.println(minTeacher);
}