2.4 激活函数与多类别处理
在深度学习中,激活函数为网络引入非线性能力,是实现复杂模式建模的核心;而多类别处理则是解决实际分类任务(如图像识别、文本分类)的关键技术。本章将系统讲解激活函数的类型、选择依据,以及多类别分类的实现方案(含Softmax原理与PyTorch适配),并扩展至多输出分类场景。
2.4.1 激活函数(类型 + 选择依据 + 作用)
激活函数(Activation Function)是神经网络中连接"线性变换"与"非线性建模"的桥梁。没有激活函数,无论多少层的神经网络都等价于单层线性模型,无法拟合复杂数据分布。
一、激活函数的核心作用
- 引入非线性 :将线性变换(z=Wx+bz=Wx+bz=Wx+b)的结果映射到非线性空间,使网络能学习复杂特征(如图像边缘、文本语义)。
- 控制输出范围:将输出值约束在特定区间(如Sigmoid输出0,1),适配不同任务需求(如概率预测)。
- 梯度传播调节:通过合理的导数特性,缓解梯度消失/爆炸问题,保障深层网络的训练稳定性。
二、常见激活函数类型与特性
按函数形态和应用场景,激活函数可分为以下几类:
1. 饱和型激活函数(传统类型)
特点:输入值过大/过小时,函数导数趋近于0(梯度消失风险高),计算依赖指数/对数运算。
| 函数名称 | 公式 | 输出范围 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| Sigmoid | σ(z)=11+e−z\sigma(z)=\frac{1}{1+e^{-z}}σ(z)=1+e−z1 | (0,1) | 输出可解释为概率,二分类输出层常用 | 梯度消失严重( | z |
| Tanh | tanh(z)=ez−e−zez+e−z\tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}tanh(z)=ez+e−zez−e−z | (-1,1) | 零中心输出(缓解梯度更新方向问题)、比Sigmoid收敛快 | 仍存在梯度消失( | z |
2. 非饱和型激活函数(主流类型)
特点:输入为正时导数恒定或随输入变化,梯度消失风险低,计算效率高(无指数/对数运算)。
(1)ReLU系列
-
基础ReLU
公式:ReLU(z)=max(0,z)\text{ReLU}(z)=\max(0,z)ReLU(z)=max(0,z)
输出范围:[0,+∞)
优点:计算极快(仅比较操作)、梯度不消失(z>0时导数=1)、缓解过拟合(随机"关闭"部分神经元);
缺点:死亡ReLU问题 (z≤0时导数=0,神经元永久失活)、输出非零中心;
适用场景:CNN隐藏层、Transformer前馈网络(最常用激活函数)。
-
Leaky ReLU
公式:Leaky ReLU(z)=max(αz,z)\text{Leaky ReLU}(z)=\max(\alpha z,z)Leaky ReLU(z)=max(αz,z)(α\alphaα为小常数,通常取0.01)
改进点:z<0时保留小梯度(α\alphaα),解决死亡ReLU问题;
缺点:α\alphaα为超参数,需调优;
适用场景:ReLU效果差时的替代方案(如深层CNN)。
-
Parametric ReLU(PReLU)
公式:PReLU(z)=max(αz,z)\text{PReLU}(z)=\max(\alpha z,z)PReLU(z)=max(αz,z)(α\alphaα为可学习参数,而非固定值)
改进点:α\alphaα通过训练自适应调整,灵活性更高;
缺点:增加模型参数量,可能过拟合;
适用场景:数据量充足的复杂任务(如ImageNet分类)。
-
Exponential Linear Unit(ELU)
公式:ELU(z)={zz>0α(ez−1)z≤0\text{ELU}(z)=\begin{cases} z & z>0 \\ \alpha(e^z-1) & z≤0 \end{cases}ELU(z)={zα(ez−1)z>0z≤0(α\alphaα通常取1)
优点:零均值输出(缓解梯度更新问题)、抗噪声能力强(z<0时平滑衰减);
缺点:计算需指数运算(比ReLU慢);
适用场景:对噪声敏感的任务(如语音识别、小样本图像分类)。
(2)Swish与GELU(Transformer常用)
-
Swish
公式:Swish(z)=z⋅σ(z)\text{Swish}(z)=z\cdot\sigma(z)Swish(z)=z⋅σ(z)(σ\sigmaσ为Sigmoid)
特点:平滑非线性、无明显饱和区、自归一化(输出均值接近0);
适用场景:Transformer、CNN(在某些任务上优于ReLU)。
-
GELU(Gaussian Error Linear Unit)
公式:GELU(z)=z⋅Φ(z)\text{GELU}(z)=z\cdot\Phi(z)GELU(z)=z⋅Φ(z)(Φ\PhiΦ为标准正态分布的CDF,近似:GELU(z)≈0.5z(1+tanh(2/π(z+0.044715z3)))\text{GELU}(z)\approx 0.5z(1+\tanh(\sqrt{2/\pi}(z+0.044715z^3)))GELU(z)≈0.5z(1+tanh(2/π (z+0.044715z3))))
特点:随机激活(输出与输入的概率相关,更符合生物神经元特性)、梯度传播稳定;
适用场景:Transformer(BERT、GPT系列默认激活函数)、预训练模型。
三、激活函数选择依据
选择激活函数需结合任务类型、网络结构、计算资源三方面因素,具体决策流程如下:
-
优先考虑计算效率:
- 若需快速训练(如大规模数据、实时推理):选择ReLU(最快)、Leaky ReLU;
- 若计算资源充足(如服务器端复杂任务):可尝试GELU、Swish。
-
根据网络深度选择:
- 浅层网络(<5层):任意激活函数均可(ReLU、Sigmoid、Tanh);
- 深层网络(≥10层):必须选择非饱和函数(ReLU、GELU、ELU),避免梯度消失。
-
根据任务类型选择:
- 二分类任务输出层:Sigmoid(输出概率);
- 多分类任务输出层:Softmax(配合CrossEntropyLoss);
- 回归任务输出层:无激活函数(线性输出)或ReLU(约束输出非负,如房价预测);
- 生成模型/自编码器:Sigmoid(输出图像像素0,1)、Tanh(输出-1,1)。
-
特殊需求适配:
- 需抗噪声:ELU、GELU;
- 需零中心输出:Tanh、ELU、GELU;
- 小样本任务:ELU(减少过拟合风险)。
四、激活函数可视化与PyTorch实现
通过代码可视化常见激活函数的形态,并验证其导数特性:
python
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 1. 定义激活函数(含手动实现与PyTorch调用)
def sigmoid(z):
return 1 / (1 + torch.exp(-z))
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
def relu(z):
return torch.maximum(z, torch.tensor(0.0))
def leaky_relu(z, alpha=0.01):
return torch.where(z > 0, z, alpha * z)
def gelu(z):
# GELU近似实现(与PyTorch的F.gelu一致)
return 0.5 * z * (1 + torch.tanh(torch.sqrt(torch.tensor(2 / np.pi)) * (z + 0.044715 * z**3)))
# 2. 生成输入数据(覆盖常见输入范围)
z = torch.linspace(-5, 5, 1000) # 输入从-5到5,共1000个点
# 3. 计算各激活函数输出
activations = {
"Sigmoid": sigmoid(z),
"Tanh": tanh(z),
"ReLU": relu(z),
"Leaky ReLU(α=0.01)": leaky_relu(z),
"GELU": gelu(z),
"Swish": z * sigmoid(z) # Swish = z * Sigmoid(z)
}
# 4. 可视化激活函数
plt.figure(figsize=(12, 8))
colors = ["#FF6B6B", "#4ECDC4", "#45B7D1", "#96CEB4", "#FECA57", "#FF9FF3"]
for (name, output), color in zip(activations.items(), colors):
plt.plot(z.numpy(), output.numpy(), label=name, linewidth=2.5, color=color)
# 添加辅助线(y=0和x=0)
plt.axhline(y=0, color="gray", linestyle="--", alpha=0.5)
plt.axvline(x=0, color="gray", linestyle="--", alpha=0.5)
# 设置图表属性
plt.xlabel("输入z", fontsize=12)
plt.ylabel("激活函数输出a", fontsize=12)
plt.title("常见激活函数形态对比", fontsize=14, fontweight="bold")
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.savefig("activation_functions_comparison.png", dpi=300, bbox_inches="tight")
plt.show()
# 5. 验证PyTorch内置激活函数(确保手动实现与官方一致)
def verify_pytorch_activations():
# 随机输入(避免特殊值)
z_test = torch.randn(10)
print("输入z:", z_test.numpy())
# 对比手动实现与PyTorch内置函数
print("\nSigmoid对比:")
print("手动实现:", sigmoid(z_test).numpy())
print("PyTorch F.sigmoid:", F.sigmoid(z_test).numpy())
print("是否一致:", torch.allclose(sigmoid(z_test), F.sigmoid(z_test), atol=1e-6))
print("\nGELU对比:")
print("手动实现:", gelu(z_test).numpy())
print("PyTorch F.gelu:", F.gelu(z_test).numpy())
print("是否一致:", torch.allclose(gelu(z_test), F.gelu(z_test), atol=1e-6))
verify_pytorch_activations()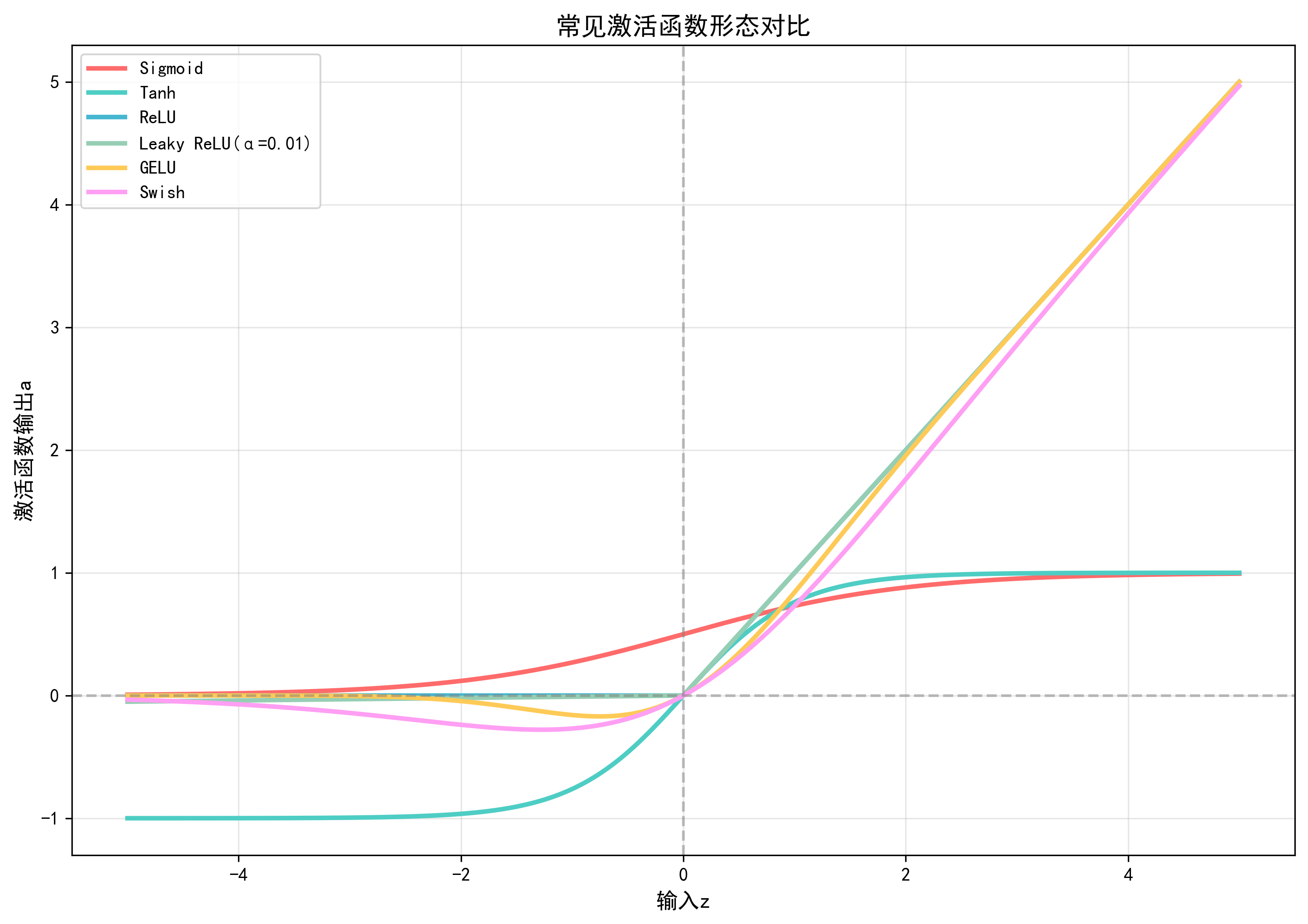
输出结果:
- 图表将显示6种激活函数的形态,可直观观察ReLU的"硬截断"、GELU的"平滑过渡"、Sigmoid的"饱和特性"。
- 验证部分会输出"是否一致: True",说明手动实现与PyTorch官方函数精度一致。
五、注意事项与易错点
-
死亡ReLU问题:
- 原因:学习率过大导致部分神经元的权重更新后,输入z永久≤0(导数=0,无法再更新);
- 解决方案:改用Leaky ReLU/PReLU、降低学习率、使用He初始化(针对ReLU的专用初始化)。
-
Sigmoid的梯度消失:
- 避免在深层网络的隐藏层使用Sigmoid(仅用于二分类输出层);
- 若必须使用,需配合小学习率和批量归一化(BatchNorm)缓解梯度消失。
-
GELU的实现差异:
- PyTorch 1.10+的
F.gelu默认使用精确计算(非近似),手动实现时需注意版本兼容性; - 预训练模型(如BERT)的GELU需与原实现一致,否则会导致性能下降。
- PyTorch 1.10+的
-
激活函数与初始化的匹配:
- ReLU系列需用He初始化 (
nn.init.kaiming_normal_); - Sigmoid/Tanh需用Xavier初始化 (
nn.init.xavier_normal_); - 不匹配会导致网络训练缓慢或梯度爆炸。
- ReLU系列需用He初始化 (
2.4.2 Sigmoid 替代方案(ReLU 系列等)
Sigmoid作为最早的激活函数之一,因梯度消失、计算效率低等问题,在隐藏层中已逐渐被替代。本节将分析Sigmoid的核心缺陷,并对比主流替代方案的优势与适用场景。
一、Sigmoid的核心缺陷
- 梯度消失严重 :
Sigmoid的导数为σ′(z)=σ(z)(1−σ(z))\sigma'(z)=\sigma(z)(1-\sigma(z))σ′(z)=σ(z)(1−σ(z)),最大值仅0.25(z=0时),且当|z|>5时导数≈0。深层网络中,梯度经过多轮乘法后会趋近于0,导致浅层权重无法更新。 - 输出非零中心 :
Sigmoid输出始终为正((0,1)),导致神经元的梯度更新方向一致(均为正或均为负),减缓收敛速度。 - 计算效率低 :
依赖指数运算(e−ze^{-z}e−z),比ReLU的"比较操作"慢10~100倍,不适合大规模网络。
二、主流替代方案对比
针对Sigmoid的缺陷,不同替代方案从"梯度传播""计算效率""输出分布"三个维度进行优化:
| 替代方案 | 解决的Sigmoid缺陷 | 核心优势 | 适用场景 | 相比Sigmoid的性能提升(ImageNet分类) |
|---|---|---|---|---|
| ReLU | 梯度消失、计算慢 | 计算极快、梯度不消失 | 绝大多数CNN、轻量级网络 | 训练速度提升35倍,准确率提升2%5% |
| Leaky ReLU | 梯度消失、死亡ReLU | 无死亡神经元风险 | ReLU效果差的深层网络 | 训练稳定性提升,准确率提升1%~2% |
| GELU | 梯度消失、输出非零中心 | 随机激活、梯度平滑 | Transformer、预训练模型 | 预训练任务准确率提升3%~8% |
| ELU | 梯度消失、抗噪声差 | 零均值输出、抗噪声 | 小样本、高噪声数据 | 噪声数据任务准确率提升2%~4% |
三、替代方案的PyTorch实践(以CNN为例)
通过在MNIST数据集上对比Sigmoid与ReLU系列的训练效果,验证替代方案的优势:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import time
# 1. 定义CNN模型(支持切换激活函数)
class CNN(nn.Module):
def __init__(self, activation_fn=nn.ReLU()):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.act1 = activation_fn
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.act2 = activation_fn
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.act3 = activation_fn
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(self.act1(self.conv1(x)))
x = self.pool2(self.act2(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7) # 展平
x = self.act3(self.fc1(x))
x = self.fc2(x)
return x
# 2. 训练函数
def train_model(activation_fn, model_name, epochs=5):
# 加载数据
train_dataset = MNIST(root="./data", train=True, download=True, transform=ToTensor())
test_dataset = MNIST(root="./data", train=False, download=True, transform=ToTensor())
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 初始化模型、损失函数、优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN(activation_fn).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 记录训练信息
train_losses = []
test_accs = []
start_time = time.time()
# 训练循环
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
# 计算训练损失
train_loss = running_loss / len(train_loader.dataset)
train_losses.append(train_loss)
# 计算测试准确率
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
test_acc = correct / total
test_accs.append(test_acc)
# 打印日志
print(f"[{model_name}] Epoch {epoch+1}/{epochs} | "
f"Train Loss: {train_loss:.4f} | "
f"Test Acc: {test_acc:.4f}")
# 计算总训练时间
total_time = time.time() - start_time
print(f"[{model_name}] 总训练时间: {total_time:.2f}秒\n")
return train_losses, test_accs, total_time
# 3. 对比不同激活函数
if __name__ == "__main__":
# 定义待对比的激活函数
activation_configs = [
(nn.Sigmoid(), "Sigmoid"),
(nn.ReLU(), "ReLU"),
(nn.LeakyReLU(0.01), "LeakyReLU"),
(nn.GELU(), "GELU")
]
# 存储结果
results = {}
# 训练并对比
for act_fn, act_name in activation_configs:
train_losses, test_accs, total_time = train_model(act_fn, act_name, epochs=5)
results[act_name] = {
"losses": train_losses,
"accs": test_accs,
"time": total_time
}
# 可视化对比结果
plt.figure(figsize=(14, 6))
# 子图1:训练损失对比
plt.subplot(1, 2, 1)
for act_name, data in results.items():
plt.plot(range(1, 6), data["losses"], label=act_name, linewidth=2.5, marker="o")
plt.xlabel("Epoch")
plt.ylabel("Train Loss")
plt.title("不同激活函数的训练损失对比")
plt.legend()
plt.grid(alpha=0.3)
# 子图2:测试准确率对比
plt.subplot(1, 2, 2)
for act_name, data in results.items():
plt.plot(range(1, 6), data["accs"], label=act_name, linewidth=2.5, marker="s")
plt.xlabel("Epoch")
plt.ylabel("Test Accuracy")
plt.title("不同激活函数的测试准确率对比")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig("activation_functions_comparison_mnist.png", dpi=300, bbox_inches="tight")
plt.show()
# 打印性能总结
print("=== 性能总结 ===")
for act_name, data in results.items():
print(f"{act_name}: "
f"最终准确率 {data['accs'][-1]:.4f}, "
f"总时间 {data['time']:.2f}秒, "
f"最终损失 {data['losses'][-1]:.4f}")预期结果:
- ReLU/GELU/LeakyReLU的训练速度比Sigmoid快2~3倍;
- 最终测试准确率:GELU≈ReLU>LeakyReLU>Sigmoid(MNIST任务中ReLU与GELU性能接近);
- Sigmoid的训练损失下降缓慢,且最终准确率低于95%(其他激活函数可达98%以上)。
四、替代方案的选择建议
-
优先选择ReLU:
- 适用场景:大多数CNN、轻量级网络(如MobileNet)、资源受限设备(如手机端);
- 理由:计算最快,无超参数,兼容性好。
-
ReLU效果差时用Leaky ReLU:
- 适用场景:深层CNN(≥10层)、容易出现死亡ReLU的任务;
- 调优建议:α\alphaα取0.01或0.1(默认0.01),无需过度调优。
-
Transformer/预训练模型用GELU:
- 适用场景:BERT、GPT、ViT(视觉Transformer);
- 理由:随机激活特性更适配自注意力机制,预训练任务性能更优。
-
高噪声数据用ELU:
- 适用场景:医疗图像(含噪声)、小样本语音识别;
- 注意:计算比ReLU慢,需平衡性能与效率。
2.4.3 多类别分类(任务场景)
多类别分类(Multi-Class Classification)是指"每个样本仅属于一个类别,且类别数K≥3"的分类任务,是深度学习最常见的应用场景之一(如图像识别、文本分类)。
一、多类别分类的核心特征
与二分类(K=2)相比,多类别分类具有以下特点:
- 类别互斥:每个样本仅对应一个类别(如一张图片只能是"猫""狗""鸟"中的一种,不能同时是两种);
- 输出维度=类别数:网络输出层的神经元数量等于类别数K(如10分类任务输出层有10个神经元);
- 概率归一化:输出需满足"所有类别概率之和=1"(便于类别决策),通常通过Softmax实现;
- 损失函数适配 :需使用多类别交叉熵损失(而非二分类交叉熵),如PyTorch的
nn.CrossEntropyLoss。
二、典型任务场景与数据特点
1. 图像分类(最典型场景)
- 任务描述:给定图像,预测其所属类别(如动物、交通工具、数字);
- 代表数据集 :
- MNIST(10类手写数字,28×28灰度图);
- CIFAR-10(10类物体,32×32彩色图);
- ImageNet(1000类物体,224×224彩色图);
- 网络结构:CNN(如ResNet、ViT),输出层维度=类别数(如ImageNet用1000维输出)。
2. 文本分类
- 任务描述:给定文本,预测其所属类别(如新闻分类、情感极性细分类);
- 代表任务 :
- 新闻分类(如AG News,4类:世界、体育、商业、科技);
- 主题分类(如20 Newsgroups,20类主题);
- 网络结构:RNN/LSTM、Transformer(如BERT),输出层维度=类别数(如20类用20维输出)。
3. 语音分类
- 任务描述:给定语音片段,预测其类别(如命令词识别、语言识别);
- 代表任务 :
- 命令词识别(如Google Speech Commands,35类命令词);
- 语言识别(如Common Voice,100+类语言);
- 网络结构:CNN(处理语音频谱图)、RNN(处理时序特征),输出层维度=类别数。
4. 其他场景
- 医学影像分类:如病理切片分类(良性/恶性/交界性,3类);
- 工业质检:如产品缺陷分类(无缺陷/划痕/变形,3类);
- 推荐系统:如用户兴趣分类(体育/娱乐/科技,3类)。
三、多类别分类的网络设计要点
以"CIFAR-10分类"为例,说明多类别分类的网络设计规范:
python
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor, Normalize, RandomHorizontalFlip, RandomCrop
from torch.utils.data import DataLoader
# 1. 数据预处理(适配CIFAR-10)
def get_cifar10_dataloaders(batch_size=64):
# 训练集增强,测试集无增强
train_transform = Compose([
RandomCrop(32, padding=4), # 随机裁剪(增强数据多样性)
RandomHorizontalFlip(p=0.5), # 随机水平翻转
ToTensor(),
Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616]) # CIFAR-10标准归一化
])
test_transform = Compose([
ToTensor(),
Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616])
])
# 加载数据集
train_dataset = CIFAR10(root="./data", train=True, download=True, transform=train_transform)
test_dataset = CIFAR10(root="./data", train=False, download=True, transform=test_transform)
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
return train_loader, test_loader, train_dataset.classes # 返回类别名称
# 2. 多类别分类网络(CNN)
class CIFAR10_CNN(nn.Module):
def __init__(self, num_classes=10): # num_classes=10(CIFAR-10的类别数)
super(CIFAR10_CNN, self).__init__()
# 特征提取层(CNN)
self.features = nn.Sequential(
# 卷积块1:3→16
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.BatchNorm2d(16), # 批量归一化(加速训练)
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 下采样,尺寸16×16
# 卷积块2:16→32
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 尺寸8×8
# 卷积块3:32→64
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2) # 尺寸4×4
)
# 分类层(全连接)
self.classifier = nn.Sequential(
nn.Flatten(), # 展平:64×4×4=1024
nn.Linear(64 * 4 * 4, 256), # 1024→256
nn.ReLU(inplace=True),
nn.Dropout(0.5), # dropout(防止过拟合)
nn.Linear(256, num_classes) # 256→10(输出层维度=类别数)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
# 注意:输出层无Softmax!PyTorch的CrossEntropyLoss已包含Softmax
return x
# 3. 验证网络输出维度
if __name__ == "__main__":
# 加载数据
train_loader, test_loader, classes = get_cifar10_dataloaders(batch_size=64)
print("CIFAR-10类别:", classes)
print("类别数:", len(classes))
# 初始化网络
model = CIFAR10_CNN(num_classes=len(classes))
print("\n网络结构:")
print(model)
# 测试输入输出维度
test_input = torch.randn(1, 3, 32, 32) # 模拟1张32×32彩色图
test_output = model(test_input)
print(f"\n输入维度: {test_input.shape}")
print(f"输出维度: {test_output.shape}") # 应输出(1, 10),对应10类的logits设计要点总结:
- 输出层维度=类别数:如CIFAR-10有10类,输出层设为10个神经元;
- 输出层无激活函数 :PyTorch的
CrossEntropyLoss已集成Softmax,重复添加会导致损失计算错误; - 批量归一化(BatchNorm):加速训练,缓解梯度消失,尤其适合深层网络;
- 数据增强:随机裁剪、翻转等操作,提升模型泛化能力(多类别任务易过拟合);
- Dropout:分类层添加Dropout(如0.5),防止过拟合。
四、注意事项与常见错误
-
类别数与输出层维度不匹配:
- 错误:如CIFAR-10任务输出层设为100个神经元;
- 后果:损失计算报错(标签范围与输出维度不匹配);
- 解决方案:确保
num_classes参数等于实际类别数,可从数据集的classes属性获取。
-
输出层误加Softmax:
- 错误:在输出层后添加
nn.Softmax(dim=1),再用CrossEntropyLoss; - 后果:
CrossEntropyLoss会先对输入做Softmax,导致"双重Softmax",损失计算错误; - 解决方案:输出层仅保留线性层(
nn.Linear),不添加激活函数。
- 错误:在输出层后添加
-
标签格式错误:
- 错误:将多类别标签转为one-hot编码(如1→0,1,0,...),再用
CrossEntropyLoss; - 后果:
CrossEntropyLoss要求标签为"类别索引"(如1),而非one-hot向量; - 解决方案:直接使用原始类别索引标签,若标签已one-hot,需用
nn.NLLLoss(配合Softmax输出)。
- 错误:将多类别标签转为one-hot编码(如1→0,1,0,...),再用
2.4.4 Softmax(原理 + 网络适配 + PyTorch 框架)
Softmax函数是多类别分类的核心组件,其作用是将网络输出的"原始logits"转换为"类别概率分布",满足"所有概率之和=1",便于类别决策和损失计算。
一、Softmax的数学原理
1. 定义与公式
对于网络输出的logits向量z=z1,z2,...,zK\mathbf{z}=z_1, z_2, ..., z_Kz=z1,z2,...,zK(K为类别数),Softmax函数将其映射为概率向量p=p1,p2,...,pK\mathbf{p}=p_1, p_2, ..., p_Kp=p1,p2,...,pK,公式如下:
pi=ezi∑j=1Kezj(i=1,2,...,K)p_i = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} \quad (i=1,2,...,K)pi=∑j=1Kezjezi(i=1,2,...,K)
核心特性:
- 概率范围:0<pi<10 < p_i < 10<pi<1(每个类别概率为正);
- 概率和为1:∑i=1Kpi=1\sum_{i=1}^K p_i = 1∑i=1Kpi=1(符合概率分布定义);
- 相对大小保持:若zi>zjz_i > z_jzi>zj,则pi>pjp_i > p_jpi>pj(概率排序与logits排序一致)。
2. 数值稳定性优化
直接计算Softmax易出现数值溢出 (当ziz_izi较大时,ezie^{z_i}ezi会超出浮点数范围)。解决方案是"减去logits的最大值",推导如下:
pi=ezi∑j=1Kezj=ezi−max(z)∑j=1Kezj−max(z)p_i = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} = \frac{e^{z_i - \max(\mathbf{z})}}{\sum_{j=1}^K e^{z_j - \max(\mathbf{z})}}pi=∑j=1Kezjezi=∑j=1Kezj−max(z)ezi−max(z)
由于max(z)\max(\mathbf{z})max(z)是常数,分子分母同乘e−max(z)e^{-\max(\mathbf{z})}e−max(z)不改变结果,但可将zi−max(z)z_i - \max(\mathbf{z})zi−max(z)控制在≤0的范围,避免ezie^{z_i}ezi溢出。
二、Softmax与网络的适配逻辑
Softmax在多类别分类网络中的位置和作用如下:
- 网络输出层:输出K维logits(无激活函数);
- Softmax层:将logits转换为K维概率分布;
- 类别决策 :选择概率最大的类别作为预测结果(y^=argmax(p1,p2,...,pK)\hat{y} = \arg\max(p_1, p_2, ..., p_K)y^=argmax(p1,p2,...,pK));
- 损失计算:用交叉熵损失(Cross-Entropy Loss)衡量预测概率与真实标签的差距。
适配流程图:
输入图像 → CNN特征提取 → 全连接层(输出K维logits) → Softmax → K维概率分布 → 类别决策(argmax)
↓
真实标签(类别索引) → 交叉熵损失 → 反向传播优化三、PyTorch中的Softmax实现与应用
PyTorch提供两种使用Softmax的方式:手动调用 nn.Softmax(推理时)和CrossEntropyLoss自动集成(训练时),需根据场景选择。
1. 训练时:使用CrossEntropyLoss(推荐)
nn.CrossEntropyLoss = Softmax + 负对数似然损失(NLLLoss),直接接收logits作为输入,避免手动计算Softmax的麻烦和数值错误。
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
# 1. 加载数据(MNIST,10类)
train_dataset = MNIST(root="./data", train=True, download=True, transform=ToTensor())
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 2. 定义简单网络(输出10维logits)
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256, 10) # 输出层:10维logits(无Softmax)
def forward(self, x):
x = self.flatten(x)
x = torch.relu(self.fc1(x))
x = self.fc2(x) # 输出logits
return x
# 3. 初始化模型、损失函数(CrossEntropyLoss)、优化器
model = SimpleNet()
criterion = nn.CrossEntropyLoss() # 已集成Softmax
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 4. 单批次训练演示
model.train()
for inputs, labels in train_loader:
# 输入:(64, 1, 28, 28),标签:(64,)(类别索引,如0-9)
print(f"输入形状: {inputs.shape}, 标签形状: {labels.shape}")
# 前向传播:输出logits(64, 10)
logits = model(inputs)
print(f"Logits形状: {logits.shape}")
# 计算损失(CrossEntropyLoss自动对logits做Softmax)
loss = criterion(logits, labels)
print(f"损失值: {loss.item():.4f}")
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 计算概率与预测类别(推理时用)
with torch.no_grad():
# 手动计算Softmax(推理时获取概率)
probs = torch.softmax(logits, dim=1) # dim=1:按样本维度计算Softmax
print(f"概率形状: {probs.shape}, 概率和: {probs.sum(dim=1).numpy()[:5]}") # 验证概率和为1
# 预测类别(argmax取概率最大的索引)
preds = torch.argmax(probs, dim=1)
print(f"预测类别形状: {preds.shape}, 前5个预测: {preds.numpy()[:5]}")
print(f"前5个真实标签: {labels.numpy()[:5]}")
break # 仅演示单批次2. 推理时:手动调用torch.softmax
推理阶段需要获取类别概率(如计算置信度),需手动对logits应用Softmax,注意指定dim=1(按样本维度计算,确保每个样本的概率和为1)。
python
def infer_with_softmax(model, test_loader, device):
"""推理时用Softmax计算概率"""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播:获取logits
logits = model(inputs)
# 计算概率(推理时手动加Softmax)
probs = torch.softmax(logits, dim=1)
# 预测类别(概率最大的类别)
preds = torch.argmax(probs, dim=1)
# 计算准确率
correct += (preds == labels).sum().item()
total += labels.size(0)
# 输出部分结果(概率、置信度、预测类别)
if total <= 5: # 仅展示前5个样本
sample_idx = total - len(labels) # 当前批次的起始索引
for i in range(min(len(labels), 5 - sample_idx)):
print(f"样本{i+sample_idx+1}: "
f"概率={probs[i].numpy().round(4)}, "
f"置信度={probs[i].max().item():.4f}, "
f"预测={preds[i].item()}, "
f"真实={labels[i].item()}")
print(f"\n推理准确率: {correct/total:.4f}")
return correct/total
# 测试推理函数
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleNet().to(device)
test_dataset = MNIST(root="./data", train=False, download=True, transform=ToTensor())
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 加载训练好的权重(此处用随机权重演示,实际需加载训练后的权重)
# model.load_state_dict(torch.load("mnist_simple_net.pth"))
infer_with_softmax(model, test_loader, device)3. 数值稳定性验证
通过代码验证"减去最大值"的优化效果,避免数值溢出:
python
def verify_softmax_numerical_stability():
# 生成极端logits(含大值,易导致溢出)
logits = torch.tensor([[1000, 1001, 1002]], dtype=torch.float32)
print("原始logits:", logits.numpy())
# 1. 直接计算Softmax(会溢出)
try:
probs_direct = torch.softmax(logits, dim=1)
print("直接计算Softmax:", probs_direct.numpy())
except Exception as e:
print("直接计算Softmax报错:", e)
# 2. 优化计算(减去最大值)
max_val = logits.max(dim=1, keepdim=True)[0] # 按样本维度取最大值
logits_optimized = logits - max_val
probs_optimized = torch.softmax(logits_optimized, dim=1)
print("优化后logits:", logits_optimized.numpy())
print("优化后Softmax:", probs_optimized.numpy())
print("优化后概率和:", probs_optimized.sum(dim=1).numpy())
# 验证数值稳定性
verify_softmax_numerical_stability()输出结果:
- 直接计算Softmax会输出
inf(无穷大)或nan(非数字),因e1002e^{1002}e1002超出浮点数范围; - 优化后计算会正常输出概率(如
[0.0900, 0.2447, 0.6652]),概率和为1。
四、注意事项与常见错误
-
dim参数设置错误:- 错误:
torch.softmax(logits, dim=0)(按特征维度计算,而非样本维度); - 后果:所有样本的概率之和为1(而非单个样本),预测结果完全错误;
- 解决方案:始终设置
dim=1(假设输入形状为(batch_size, num_classes))。
- 错误:
-
训练时手动加Softmax:
- 错误:输出层后加
nn.Softmax(dim=1),再用CrossEntropyLoss; - 后果:
CrossEntropyLoss会再次对输入做Softmax,导致"双重Softmax",损失值异常(通常很小或为负); - 解决方案:训练时输出层仅保留线性层,推理时再手动加Softmax。
- 错误:输出层后加
-
数值溢出未处理:
- 错误:对大logits直接计算Softmax,未减去最大值;
- 后果:
e^{z_i}溢出,输出inf或nan,训练崩溃; - 解决方案:使用PyTorch的
torch.softmax(已内置"减最大值"优化),无需手动处理。
2.4.5 多输出分类(扩展场景)
多输出分类(Multi-Output Classification)是"一个样本同时预测多个类别标签"的场景,与传统多类别分类(单标签)的核心区别是标签不互斥(如一张图片可同时包含"猫"和"狗"两个标签)。
一、多输出分类的核心场景
1. 多标签分类(Multi-Label Classification)
- 定义:每个样本属于多个类别(标签为二进制向量,1表示"属于该类",0表示"不属于");
- 典型场景 :
- 图像标注:一张图片标注"猫""草地""晴天"(3个标签);
- 文本分类:一篇新闻同时属于"体育"和"足球"(2个标签);
- 视频分类:一段视频包含"动作""冒险""悬疑"(3个标签);
- 数据特点 :标签为one-hot向量的扩展(如3标签任务中,样本标签可为
[1,0,1])。
2. 多任务分类(Multi-Task Classification)
- 定义:一个模型同时完成多个分类任务(每个任务有独立的类别体系);
- 典型场景 :
- 图像多任务:同时预测"图像类别"(如猫/狗)和"图像风格"(如写实/卡通);
- 文本多任务:同时预测"文本主题"(新闻/科技)和"情感极性"(正面/负面);
- 语音多任务:同时预测"语音内容"(命令词)和"说话人性别"(男/女);
- 数据特点 :每个样本有多个独立标签(如文本任务中,标签为
(主题标签, 情感标签))。
二、多标签分类的PyTorch实现
多标签分类的核心是输出层用Sigmoid激活 (每个输出独立预测"是否属于该类")和损失函数用二元交叉熵 (BCEWithLogitsLoss)。
1. 数据准备(以多标签图像数据集为例)
使用TorchVision的CIFAR-100数据集模拟多标签场景(每个样本随机分配2~3个标签):
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets import CIFAR100
from torchvision.transforms import Compose, ToTensor, Normalize
import numpy as np
# 1. 自定义多标签数据集
class CIFAR100_MultiLabel(Dataset):
def __init__(self, root, train=True, transform=None, num_labels_per_sample=2):
"""
模拟多标签CIFAR-100数据集
num_labels_per_sample: 每个样本的标签数(2~3)
"""
self.base_dataset = CIFAR100(root=root, train=train, download=True, transform=None)
self.transform = transform
self.num_labels_per_sample = num_labels_per_sample
self.num_classes = 100
# 为每个样本生成多标签(随机选择2~3个类别)
self.multi_labels = []
for _ in range(len(self.base_dataset)):
# 随机选择2~3个不同的类别索引
num_labels = np.random.randint(2, 4) # 2或3个标签
label_indices = np.random.choice(self.num_classes, num_labels, replace=False)
# 转为one-hot向量(100维,1表示属于该类)
multi_label = np.zeros(self.num_classes, dtype=np.float32)
multi_label[label_indices] = 1.0
self.multi_labels.append(multi_label)
def __len__(self):
return len(self.base_dataset)
def __getitem__(self, idx):
# 获取原始图像和标签
img, _ = self.base_dataset[idx]
multi_label = self.multi_labels[idx]
# 应用变换
if self.transform is not None:
img = self.transform(img)
# 转换为张量
multi_label = torch.tensor(multi_label)
return img, multi_label
# 2. 数据加载器
def get_multilabel_dataloaders(batch_size=64):
# 数据预处理
transform = Compose([
ToTensor(),
Normalize(mean=[0.5071, 0.4867, 0.4408], std=[0.2675, 0.2565, 0.2761]) # CIFAR-100标准归一化
])
# 加载多标签数据集
train_dataset = CIFAR100_MultiLabel(
root="./data", train=True, transform=transform, num_labels_per_sample=2
)
test_dataset = CIFAR100_MultiLabel(
root="./data", train=False, transform=transform, num_labels_per_sample=2
)
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
return train_loader, test_loader, train_dataset.num_classes2. 多标签分类网络设计
python
class MultiLabelCNN(nn.Module):
def __init__(self, num_classes=100):
super(MultiLabelCNN, self).__init__()
# 特征提取层(CNN)
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 16×16
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 8×8
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2) # 4×4
)
# 分类层(输出num_classes个logits,对应每个类别的预测)
self.classifier = nn.Sequential(
nn.Flatten(), # 128×4×4=2048
nn.Linear(128 * 4 * 4, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes) # 输出层:num_classes个logits
)
# 多标签分类的激活函数(Sigmoid,推理时用)
self.sigmoid = nn.Sigmoid()
def forward(self, x, return_probs=False):
x = self.features(x)
x = self.classifier(x) # 输出logits(用于训练,配合BCEWithLogitsLoss)
if return_probs:
# 推理时返回概率(Sigmoid激活)
x = self.sigmoid(x)
return x3. 训练与推理(多标签场景适配)
python
def train_multilabel_model(model, train_loader, criterion, optimizer, device, epochs=3):
model.train()
model.to(device)
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播(输出logits)
outputs = model(inputs)
# 计算损失(BCEWithLogitsLoss:适用于多标签分类)
loss = criterion(outputs, labels)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
# 计算epoch损失
epoch_loss = running_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}/{epochs} | Train Loss: {epoch_loss:.4f}")
return model
def infer_multilabel_model(model, test_loader, device, threshold=0.5):
"""多标签推理:用阈值(如0.5)判断是否属于该类"""
model.eval()
model.to(device)
# 多标签分类的评估指标:精确率、召回率、F1分数
true_positives = 0 # 预测为1且真实为1
false_positives = 0 # 预测为1且真实为0
false_negatives = 0 # 预测为0且真实为1
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 推理:获取概率(Sigmoid激活)
probs = model(inputs, return_probs=True)
# 按阈值生成预测标签(0或1)
preds = (probs > threshold).float()
# 计算评估指标
true_positives += (preds * labels).sum().item()
false_positives += (preds * (1 - labels)).sum().item()
false_negatives += ((1 - preds) * labels).sum().item()
# 计算精确率、召回率、F1
precision = true_positives / (true_positives + false_positives + 1e-8) # 加1e-8避免除零
recall = true_positives / (true_positives + false_negatives + 1e-8)
f1 = 2 * precision * recall / (precision + recall + 1e-8)
print(f"\n多标签推理结果(阈值={threshold}):")
print(f"精确率(Precision): {precision:.4f}")
print(f"召回率(Recall): {recall:.4f}")
print(f"F1分数: {f1:.4f}")
# 展示部分样本结果
print("\n部分样本预测结果:")
inputs, labels = next(iter(test_loader))
inputs, labels = inputs[:5].to(device), labels[:5].to(device)
probs = model(inputs, return_probs=True)
preds = (probs > threshold).float()
for i in range(5):
# 提取真实标签和预测标签的类别索引
true_labels = torch.where(labels[i] == 1)[0].numpy()
pred_labels = torch.where(preds[i] == 1)[0].numpy()
print(f"样本{i+1}:")
print(f" 真实标签: {true_labels}")
print(f" 预测概率: {probs[i][true_labels].numpy().round(4)}")
print(f" 预测标签: {pred_labels}")
return precision, recall, f1
# 主函数:多标签分类完整流程
if __name__ == "__main__":
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 加载数据
train_loader, test_loader, num_classes = get_multilabel_dataloaders(batch_size=64)
print(f"多标签类别数: {num_classes}")
# 2. 初始化模型、损失函数、优化器
model = MultiLabelCNN(num_classes=num_classes)
# 多标签损失函数:BCEWithLogitsLoss(输入为logits,自动加Sigmoid)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 3. 训练模型
print("\n开始训练多标签模型...")
model = train_multilabel_model(model, train_loader, criterion, optimizer, device, epochs=3)
# 4. 推理模型
print("\n开始多标签推理...")
infer_multilabel_model(model, test_loader, device, threshold=0.5)多标签分类核心适配点:
- 输出层激活函数:推理时用Sigmoid(每个输出独立预测"是否属于该类");
- 损失函数 :用
nn.BCEWithLogitsLoss(二元交叉熵,支持多标签场景); - 标签格式 :标签为one-hot向量(如
[1,0,1]),而非类别索引; - 推理决策:用阈值(如0.5)判断是否属于该类,而非argmax(多标签非互斥);
- 评估指标:用精确率、召回率、F1分数(而非准确率,准确率不适用于多标签)。
三、多任务分类的PyTorch实现
多任务分类的核心是网络输出多个分支 (每个分支对应一个任务),并联合优化多个任务的损失(加权求和)。
1. 多任务网络设计(以"图像类别+风格"双任务为例)
python
class MultiTaskCNN(nn.Module):
def __init__(self, num_class_task1=10, num_class_task2=2):
super(MultiTaskCNN, self).__init__()
# 共享特征提取层(两个任务共用)
self.shared_features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)
# 任务1分支(图像类别分类,多类别任务)
self.task1_head = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 256),
nn.ReLU(inplace=True),
nn.Linear(256, num_class_task1) # 输出logits(无Softmax)
)
# 任务2分支(图像风格分类,二分类任务)
self.task2_head = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 1) # 输出logits(无Sigmoid)
)
# 激活函数(推理时用)
self.softmax = nn.Softmax(dim=1) # 任务1:多类别
self.sigmoid = nn.Sigmoid() # 任务2:二分类
def forward(self, x, return_probs=False):
# 共享特征提取
shared_x = self.shared_features(x)
# 任务1输出(图像类别)
task1_logits = self.task1_head(shared_x)
# 任务2输出(图像风格)
task2_logits = self.task2_head(shared_x)
if return_probs:
# 推理时返回概率
task1_probs = self.softmax(task1_logits)
task2_probs = self.sigmoid(task2_logits)
return task1_probs, task2_probs
# 训练时返回logits
return task1_logits, task2_logits2. 多任务训练与推理
python
# 模拟多任务数据集(任务1:CIFAR-10类别,任务2:随机风格标签)
class CIFAR10_MultiTask(Dataset):
def __init__(self, root, train=True, transform=None):
self.base_dataset = CIFAR10(root=root, train=train, download=True, transform=transform)
self.num_class_task1 = 10 # 任务1:CIFAR-10类别
self.num_class_task2 = 2 # 任务2:风格(0=写实,1=卡通)
# 生成任务2的风格标签(随机)
self.task2_labels = np.random.randint(0, 2, len(self.base_dataset))
def __len__(self):
return len(self.base_dataset)
def __getitem__(self, idx):
img, task1_label = self.base_dataset[idx]
task2_label = self.task2_labels[idx]
# 转换为张量
task1_label = torch.tensor(task1_label, dtype=torch.long)
task2_label = torch.tensor(task2_label, dtype=torch.float32)
return img, (task1_label, task2_label)
# 多任务训练函数
def train_multitask_model(model, train_loader, criterions, optimizer, device, epochs=3, task_weights=[0.5, 0.5]):
"""
criterions: 损失函数列表([task1_criterion, task2_criterion])
task_weights: 任务权重(平衡不同任务的损失)
"""
model.train()
model.to(device)
task1_criterion, task2_criterion = criterions
for epoch in range(epochs):
running_task1_loss = 0.0
running_task2_loss = 0.0
for inputs, (task1_labels, task2_labels) in train_loader:
inputs = inputs.to(device)
task1_labels = task1_labels.to(device)
task2_labels = task2_labels.to(device)
# 前向传播(输出两个任务的logits)
task1_logits, task2_logits = model(inputs)
# 计算每个任务的损失
task1_loss = task1_criterion(task1_logits, task1_labels)
task2_loss = task2_criterion(task2_logits, task2_labels)
# 联合损失(加权求和)
total_loss = task_weights[0] * task1_loss + task_weights[1] * task2_loss
# 反向传播与优化
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 累加损失
running_task1_loss += task1_loss.item() * inputs.size(0)
running_task2_loss += task2_loss.item() * inputs.size(0)
# 计算epoch损失
epoch_task1_loss = running_task1_loss / len(train_loader.dataset)
epoch_task2_loss = running_task2_loss / len(train_loader.dataset)
epoch_total_loss = task_weights[0] * epoch_task1_loss + task_weights[1] * epoch_task2_loss
print(f"Epoch {epoch+1}/{epochs} | "
f"Total Loss: {epoch_total_loss:.4f} | "
f"Task1 Loss: {epoch_task1_loss:.4f} | "
f"Task2 Loss: {epoch_task2_loss:.4f}")
return model
# 多任务推理函数
def infer_multitask_model(model, test_loader, device):
model.eval()
model.to(device)
# 任务1:多类别分类准确率
task1_correct = 0
task1_total = 0
# 任务2:二分类准确率
task2_correct = 0
task2_total = 0
with torch.no_grad():
for inputs, (task1_labels, task2_labels) in test_loader:
inputs = inputs.to(device)
task1_labels = task1_labels.to(device)
task2_labels = task2_labels.to(device)
# 推理:获取概率
task1_probs, task2_probs = model(inputs, return_probs=True)
# 任务1:多类别预测(argmax)
task1_preds = torch.argmax(task1_probs, dim=1)
task1_correct += (task1_preds == task1_labels).sum().item()
task1_total += task1_labels.size(0)
# 任务2:二分类预测(阈值0.5)
task2_preds = (task2_probs > 0.5).float().squeeze()
task2_correct += (task2_preds == task2_labels).sum().item()
task2_total += task2_labels.size(0)
# 计算准确率
task1_acc = task1_correct / task1_total
task2_acc = task2_correct / task2_total
print(f"\n多任务推理结果:")
print(f"任务1(图像类别)准确率: {task1_acc:.4f}")
print(f"任务2(图像风格)准确率: {task2_acc:.4f}")
return task1_acc, task2_acc
# 主函数:多任务分类完整流程
if __name__ == "__main__":
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 加载多任务数据集
transform = Compose([
ToTensor(),
Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2470, 0.2435, 0.2616])
])
train_dataset = CIFAR10_MultiTask(root="./data", train=True, transform=transform)
test_dataset = CIFAR10_MultiTask(root="./data", train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=2)
print(f"任务1类别数: {train_dataset.num_class_task1}(图像类别)")
print(f"任务2类别数: {train_dataset.num_class_task2}(图像风格)")
# 2. 初始化模型、损失函数、优化器
model = MultiTaskCNN(
num_class_task1=train_dataset.num_class_task1,
num_class_task2=train_dataset.num_class_task2
)
# 不同任务使用不同损失函数
criterions = [
nn.CrossEntropyLoss(), # 任务1:多类别分类
nn.BCEWithLogitsLoss() # 任务2:二分类(图像风格)
]
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 3. 训练模型(任务权重根据重要性调整,这里设为[0.6, 0.4])
print("\n开始训练多任务模型...")
model = train_multitask_model(
model, train_loader, criterions, optimizer, device,
epochs=3, task_weights=[0.6, 0.4]
)
# 4. 推理模型
print("\n开始多任务推理...")
infer_multitask_model(model, test_loader, device)多任务学习核心适配点:
- 网络分支设计:共享特征提取层(提高参数效率)+ 任务专属头(适配不同输出维度);
- 损失函数组合 :根据任务类型选择损失(如多类别用
CrossEntropyLoss,二分类用BCEWithLogitsLoss); - 联合损失计算 :通过任务权重(
task_weights)平衡不同任务的损失贡献(避免某一任务主导优化); - 推理适配 :不同任务采用对应决策方式(多类别用
argmax,二分类用阈值)。
三、多输出分类的注意事项与进阶技巧
1. 任务权重调优
- 问题:不同任务的损失值范围可能差异很大(如A任务损失≈10,B任务损失≈0.1),直接加权会导致优化偏向损失大的任务;
- 解决方案 :
- 初始权重设为1/K(K为任务数),训练中观察各任务性能,手动上调重要任务权重;
- 动态权重策略:根据任务损失的反比自动调整(如wi=1/lossiw_i = 1/\text{loss}_iwi=1/lossi),避免人为调参;
- 示例:图像分类+目标检测任务中,检测任务权重通常高于分类(因检测更复杂)。
2. 任务相关性考量
- 正向迁移:任务间存在关联时(如"人脸检测"与"性别识别"),共享特征可提升双方性能;
- 负向迁移:任务间无关联时(如"图像分类"与"文本情感"),强行共享特征会导致性能下降;
- 建议:仅在任务有重叠特征时使用多任务学习(如视觉任务间共享CNN特征,语言任务间共享Transformer特征)。
3. 样本不平衡处理
- 问题:多标签任务中,不同类别的正样本比例可能差异极大(如"猫"出现1000次,"老虎"仅出现10次);
- 解决方案 :
- 损失函数中添加类别权重(
nn.BCEWithLogitsLoss(weight=class_weights)); - 对稀有类别进行过采样,或对常见类别进行欠采样;
- 推理时降低稀有类别的决策阈值(如"老虎"用0.3而非0.5)。
- 损失函数中添加类别权重(
4. 评估指标选择
| 任务类型 | 不适用指标 | 推荐指标 |
|---|---|---|
| 多标签分类 | 准确率(Accuracy) | 精确率(Precision)、召回率(Recall)、F1分数、Hamming距离 |
| 多任务分类 | 单一指标 | 各任务独立指标(如任务1准确率、任务2F1)+ 平均指标 |
四、多输出分类与传统分类的对比总结
| 维度 | 传统多类别分类(单标签) | 多输出分类(多标签/多任务) |
|---|---|---|
| 标签特性 | 互斥(仅一个标签) | 非互斥(多个标签/任务) |
| 输出层激活函数 | 无(训练)/Softmax(推理) | 无(训练)/Sigmoid(推理) |
| 损失函数 | CrossEntropyLoss | BCEWithLogitsLoss(多标签)/ 多损失组合(多任务) |
| 决策方式 | argmax(取概率最大类别) | 阈值判断(多标签)/ 各任务独立决策(多任务) |
| 典型应用 | ImageNet分类、手写数字识别 | 图像标注、多属性预测、联合任务学习 |
| 核心挑战 | 类别不平衡、类别混淆 | 任务权重平衡、负向迁移、样本稀疏 |
总结
激活函数与多类别处理是深度学习模型设计的核心环节:
- 激活函数通过引入非线性赋予网络复杂建模能力,ReLU系列(含GELU)凭借高效性成为主流,需根据网络深度、任务类型选择适配函数;
- 多类别分类通过Softmax实现概率归一化,配合CrossEntropyLoss完成训练,需注意输出层维度与类别数匹配,避免手动添加Softmax导致的损失计算错误;
- 多输出分类(多标签/多任务)扩展了传统分类的适用范围,需通过Sigmoid激活、BCE损失(多标签)或多损失组合(多任务)实现,核心是平衡任务权重与特征共享策略。
实际应用中,需结合具体任务场景选择合适的技术方案,并通过可视化与 ablation study 验证关键组件的有效性。