目录
HDFS的web界面:localhost:9870
HDFS命令:shell文件系统命令前加上hdfs
概述
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统,解决的问题是大数据存储。
HDFS(Hadoop Distributed File System)是Hadoop项目的一个子项目,Hadoop非常适于存储大型数据,其使用HDFS作为存储系统。HDFS使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
HDFS特点
可存储超大文件,时效性稍差,导致hive不能顶替mysql
具有硬件故障检测和自动快速回复功能
提供很强的横向扩展能力
一般为,一次写入多次读取,只支持追加写入,不支持更新操作
默认的block块大小是128M,默认副本数2
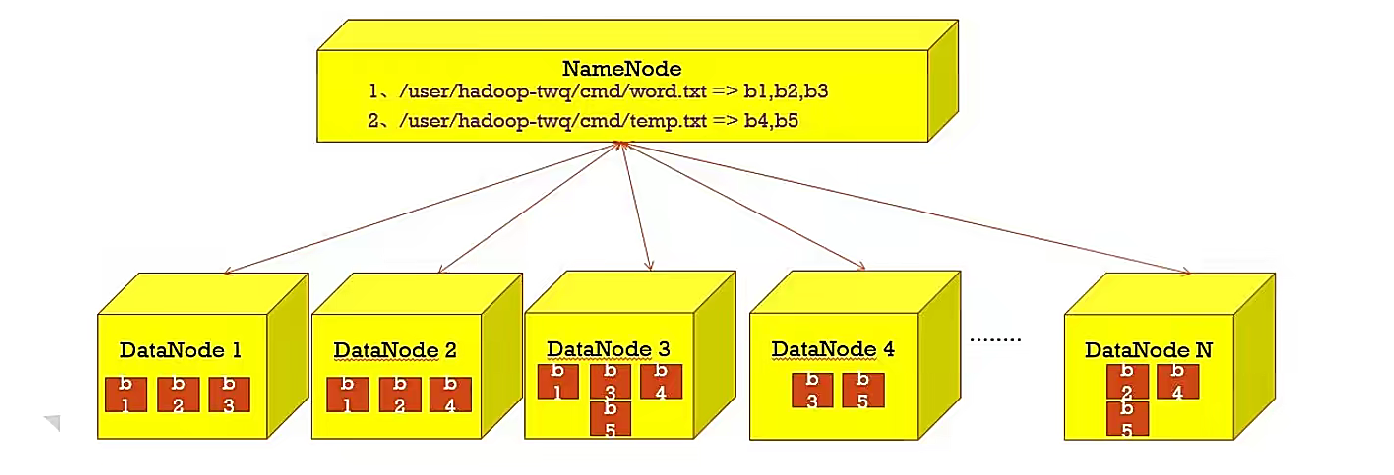
HDFS三个角色
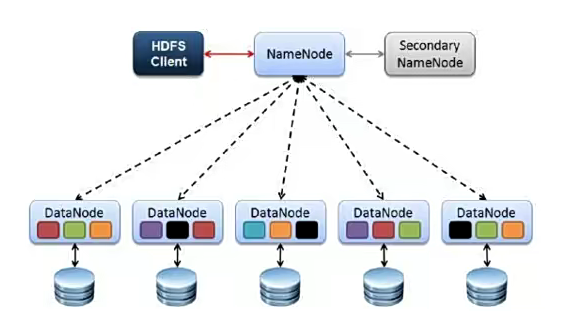
HDFS运行过程
角色详解
Cilent
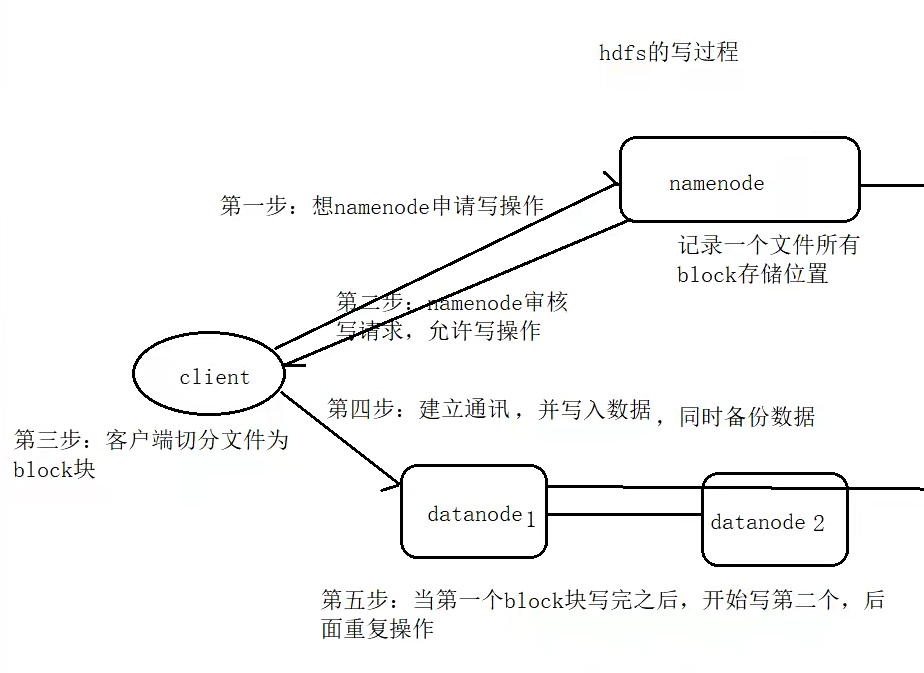
客户端,文件上传到HDFS的时候,Cilent将文件切分成一个一个的Block,进行存储。
与NameNode交互,获取文件的位置信息
与DataNode交互,读取或者写入数据
Cilent提供一些命令来管理和访问HDFS,比如启动和关闭HDFS
NameNode
master,主管、管理者。
管理HDFS元数据(文件路径、文件的大小、文件的名字、文件权限、文件的block切片信息...)
配置副本策略
处理客户端读写请求
DataNode
Slave。NameNode下达命令,DataNode执行实际的操作
存储实际的数据块
执行数据块的读/写操作
定时向NameNode汇报block信息
Sceondary NameNode
并非NameNode的热备,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助NameNode,分担其工作量
在紧急情况下,可辅助恢复NameNode
HDFS副本机制
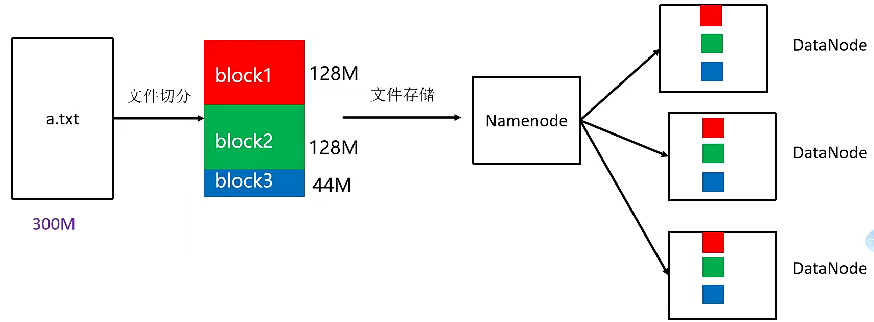
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本,每个文件的数据块大小和副本系数都是可配置的。
Hadoop2.x当中,文件的block块大小默认是128M(134217728字节)
HDFS基准测试
1. TestDFSIO
TestDFSIO是 Hadoop 自带的一个用于测试 HDFS 读写性能的工具,它可以模拟多线程的读写操作。
(1)写测试 使用 TestDFSIO 进行写测试时,命令格式如下:
hdfs dfsadmin -safemode leave # 离开安全模式(如果处于安全模式,可能影响测试)
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*.jar TestDFSIO -write -nrFiles <文件数量> -size <文件大小>参数说明:
-write:指定执行写测试。
-nrFiles:要创建的文件数量。例如,设置为10,表示生成 10 个测试文件。
-size:每个文件的大小,可以使用单位,如128MB、1GB等。比如设置为128MB,则每个测试文件大小为 128 兆字节。
示例:
hdfs dfsadmin -safemode leave
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.4.jar TestDFSIO -write -nrFiles 20 -size 128MB执行完成后,会输出类似以下信息:
...
18/08/20 11:23:17 INFO TestDFSIO: : org.apache.hadoop.mapred.LocalJobRunner$Job:
18/08/20 11:23:17 INFO TestDFSIO: : Counters: 30
18/08/20 11:23:17 INFO TestDFSIO: : File System Counters
18/08/20 11:23:17 INFO TestDFSIO: : FILE: Number of bytes read=0
18/08/20 11:23:17 INFO TestDFSIO: : FILE: Number of bytes written=17592186044416
18/08/20 11:23:17 INFO TestDFSIO: : FILE: Number of read operations=0
18/08/20 11:23:17 INFO TestDFSIO: : FILE: Number of large read operations=0
18/08/20 11:23:17 INFO TestDFSIO: : FILE: Number of write operations=0
18/08/20 11:23:17 INFO TestDFSIO: : HDFS: Number of bytes read=0
18/08/20 11:23:17 INFO TestDFSIO: : HDFS: Number of bytes written=2560000000
18/08/20 11:23:17 INFO TestDFSIO: : HDFS: Number of read operations=0
18/08/20 11:23:17 INFO TestDFSIO: : HDFS: Number of large read operations=0
18/08/20 11:23:17 INFO TestDFSIO: : HDFS: Number of write operations=20
18/08/20 11:23:17 INFO TestDFSIO: : Job Counters
18/08/20 11:23:17 INFO TestDFSIO: : Launched map tasks=1
18/08/20 11:23:17 INFO TestDFSIO: : Launched reduce tasks=0
...
18/08/20 11:23:17 INFO TestDFSIO: Throughput for write: 22.3 MB/sec重点关注 Throughput for write 这一行,它表示写操作的吞吐量。
(2)读测试读测试的命令格式为:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*.jar TestDFSIO -read -nrFiles <文件数量> -size <文件大小>参数 -read 表示执行读测试,其他参数含义与写测试相同。
示例:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.4.jar TestDFSIO -read -nrFiles 20 -size 128MB执行后同样会输出相关性能数据,关注读操作的吞吐量信息,如 Throughput for read 行。
(3)清理测试文件测试完成后,建议删除生成的测试文件,避免占用过多存储空间,命令如下:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*.jar TestDFSIO -clean2. NNBench
NNBench 主要用于测试 NameNode 的性能,比如元数据操作的性能。
写操作测试
hadoop jar $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-*.jar nnbench -write -files <文件数量> -maps <map任务数> -blockSize <块大小> -replication <副本数>参数说明:
-write:指定执行写操作测试。
-files:要创建的文件数量。
-maps:执行写操作的 Map 任务数量。
-blockSize:文件块大小,如64MB。
-replication:文件副本数。
示例:
hadoop jar /usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-3.3.4.jar nnbench -write -files 100 -maps 5 -blockSize 128MB -replication 3读操作测试
hadoop jar $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-*.jar nnbench -read -files <文件数量> -maps <map任务数>参数
-read表示执行读操作测试,其他参数含义类似写测试。