| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain聊天模型多案例实战 |
前情摘要:
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain聊天模型多案例实战
本文章目录
- 零基础学AI大模型之LangChain链
-
- [1. 引言:为什么需要「Chain」?](#1. 引言:为什么需要「Chain」?)
- [2. 核心概念:什么是Chain?](#2. 核心概念:什么是Chain?)
-
- [2.1 Chain的定义](#2.1 Chain的定义)
- [2.2 用Java责任链模式类比理解](#2.2 用Java责任链模式类比理解)
- [2.3 Chain的核心价值](#2.3 Chain的核心价值)
- [3. 基础链实战:LLMChain](#3. 基础链实战:LLMChain)
-
- [3.1 LLMChain的核心构成](#3.1 LLMChain的核心构成)
- [3.2 LLMChain完整实战案例](#3.2 LLMChain完整实战案例)
-
- [3.2.1 环境准备](#3.2.1 环境准备)
- [3.2.2 代码实现(含详细注释)](#3.2.2 代码实现(含详细注释))
- [3.2.3 运行结果示例](#3.2.3 运行结果示例)
- [3.3 LLMChain的适用场景](#3.3 LLMChain的适用场景)
- [4. 新范式实战:LCEL(LangChain Expression Language)](#4. 新范式实战:LCEL(LangChain Expression Language))
-
- [4.1 为什么需要LCEL?](#4.1 为什么需要LCEL?)
- [4.2 LCEL的核心语法](#4.2 LCEL的核心语法)
- [4.3 LCEL完整实战案例(对比旧版LLMChain)](#4.3 LCEL完整实战案例(对比旧版LLMChain))
-
- [4.3.1 案例需求](#4.3.1 案例需求)
- [4.3.2 代码实现(LCEL版 vs LLMChain版)](#4.3.2 代码实现(LCEL版 vs LLMChain版))
- [4.3.3 运行结果对比](#4.3.3 运行结果对比)
- [5. 旧版Chain vs 新版LCEL核心差异](#5. 旧版Chain vs 新版LCEL核心差异)
- [6. 总结](#6. 总结)
-
- [6.1 核心总结](#6.1 核心总结)
零基础学AI大模型之LangChain链
1. 引言:为什么需要「Chain」?
在LangChain中,单个组件(如PromptTemplate、ChatOpenAI)只能解决单一问题:提示模板负责格式化输入,大模型负责生成内容,但实际AI应用往往需要多步骤协作------比如"接收用户问题→填充提示模板→调用大模型→解析输出结果→存储到数据库"。
「Chain(链)」正是为解决这一需求而生:它像一条"流水线",将多个独立组件按逻辑顺序串联,形成可复用、可扩展的任务流程。类比Java中的责任链模式或工作流引擎,Chain让复杂AI任务的开发从"零散拼接"变成"标准化组装"。

2. 核心概念:什么是Chain?
2.1 Chain的定义
Chain是LangChain构建语言模型应用的核心组件,本质是「多个处理单元(模型/工具/逻辑)的有序组合」,用于实现端到端的任务流程。
2.2 用Java责任链模式类比理解
如果你熟悉Java,可以通过以下代码快速get Chain的设计思想:
java
// 1. 定义处理单元接口(类似LangChain的Runnable)
public interface Handler {
void handle(Request request);
}
// 2. 实现具体处理单元(类似LangChain的Prompt、LLM、Parser)
class ValidationHandler implements Handler {
// 第一步:验证用户输入合法性
@Override
public void handle(Request request) {
if (request.getContent() == null) {
throw new IllegalArgumentException("输入不能为空");
}
}
}
class LLMProcessingHandler implements Handler {
// 第二步:调用大模型处理
@Override
public void handle(Request request) {
String result = llmClient.generate(request.getContent());
request.setLlmResult(result); // 传递结果给下一个单元
}
}
class DatabaseSaveHandler implements Handler {
// 第三步:存储结果到数据库
@Override
public void handle(Request request) {
dbClient.save(request.getLlmResult());
}
}
// 3. 构建Chain并执行(类似LangChain的链组装)
public class ChainDemo {
public static void main(String[] args) {
List<Handler> chain = Arrays.asList(
new ValidationHandler(),
new LLMProcessingHandler(),
new DatabaseSaveHandler()
);
Request request = new Request("如何学习AI大模型?");
for (Handler handler : chain) {
handler.handle(request); // 按顺序执行
}
}
}2.3 Chain的核心价值
- 解耦组件:每个单元只负责单一职责(验证/生成/存储),便于维护和替换;
- 流程复用:定义好的Chain可在多个场景中重复调用(如"问答→存储"链);
- 扩展灵活:可随时新增/删除处理单元(如在"生成"后加"结果脱敏"单元)。
3. 基础链实战:LLMChain
LLMChain是LangChain中最基础的链,专门用于"提示模板+大模型"的简单组合,负责"填充模板→调用模型→返回结果"的单步流程。
注意:LLMChain是旧版(LangChain 0.2及之前)的核心链,目前LangChain 0.3+已推荐使用LCEL,但LLMChain仍被保留,适合入门理解链的本质。
3.1 LLMChain的核心构成
LLMChain由3个核心部分组成,参数说明如下表:
| 参数名 | 作用 | 类比Java场景 | 示例值 |
|---|---|---|---|
llm |
依赖的大模型实例 | 注入的第三方服务客户端 | ChatOpenAI(model_name="qwen-plus") |
prompt |
预定义的提示词模板(含动态变量) | 带占位符的String模板 | PromptTemplate(input_variables=["product"], template="列举{product}的3个卖点") |
output_parser |
(可选)模型输出的后处理器 | JSON解析工具(如Jackson) | CommaSeparatedListOutputParser() |
3.2 LLMChain完整实战案例
3.2.1 环境准备
需先安装LangChain相关依赖:
bash
pip install langchain langchain-openai3.2.2 代码实现(含详细注释)
python
# 1. 导入依赖
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain_core.prompts import PromptTemplate
# 2. 1 定义提示词模板(动态变量为product)
# 类似Java的String.format("列举%s的3个卖点", product)
prompt_template = PromptTemplate(
input_variables=["product"], # 声明动态变量
template="你是文案高手,请列举{product}的3个核心卖点,每个卖点用简短短语描述:"
)
# 2.2 初始化大模型(以阿里通义千问为例,需替换为自己的api_key)
model = ChatOpenAI(
model_name='deepseek-r1:7b', # 本地模型名称,根据实际情况填写
base_url="http://127.0.0.1:11434/v1", # 本地模型API地址
api_key="none", # 本地模型通常不需要真实API密钥
temperature=0.7 # 可根据需要调整温度参数
)
# 3. 构建LLMChain(组装模板和模型)
llm_chain = LLMChain(
llm=model, # 注入模型
prompt=prompt_template # 注入提示模板
)
# 4. 调用链(注意:需传递包含动态变量的字典)
# 旧版run()方法已淘汰,LangChain 0.3+统一用invoke()
result = llm_chain.invoke({"product": "大模型"}) # 变量product赋值为"大模型"
# 5. 输出结果
print("LLMChain输出结果:")
print(result["text"]) # result是字典,key为"text"(默认输出键)3.2.3 运行结果示例
LangChainDeprecationWarning: The class `LLMChain` was deprecated in LangChain 0.1.17 and will be removed in 1.0. Use :meth:`~RunnableSequence, e.g., `prompt | llm`` instead.
llm_chain = LLMChain(
LLMChain输出结果:
<think>
嗯,用户让我帮忙作为文案高手,列出大模型的三个核心卖点,每个卖点用简短的话描述。首先,我需要明确用户的需求是什么。他们可能是在准备产品推广或者市场宣传,想突出大模型的主要优势。
接下来,我要考虑大模型最吸引人的地方通常是什么。数据驱动是关键,所以第一个卖点应该是"数据驱动"。这个点能突出模型有多强大,处理的信息量大,结果准确可靠。
然后,自然流畅的输出也很重要。用户可能经常需要处理文本,无论是写文案、翻译还是生成内容,自然语言的处理能力能让他们的工作更高效。所以第二个卖点是"自然流畅的输出"。
第三个卖点应该是计算速度方面。虽然数据驱动和自然输出很重要,但快速响应也是用户关注的重点,尤其是在需要即时反馈的情况下。因此,我想到"轻松应对复杂任务"作为第三个点。
最后,我要确保每个卖点都是简短而有力的,能够吸引读者的注意力并传达关键信息。这样用户的文案就能更好地突出大模型的优势了。
</think>
1. **数据驱动**
大模型基于海量数据,提供准确、可靠的内容生成与分析。
2. **自然流畅的输出**
支持多种语言,精准理解用户意图,生成自然地道的语言内容。
3. **轻松应对复杂任务**
灵活处理多种应用场景,快速响应专业或创意需求,满足多领域应用需求。
Process finished with exit code 0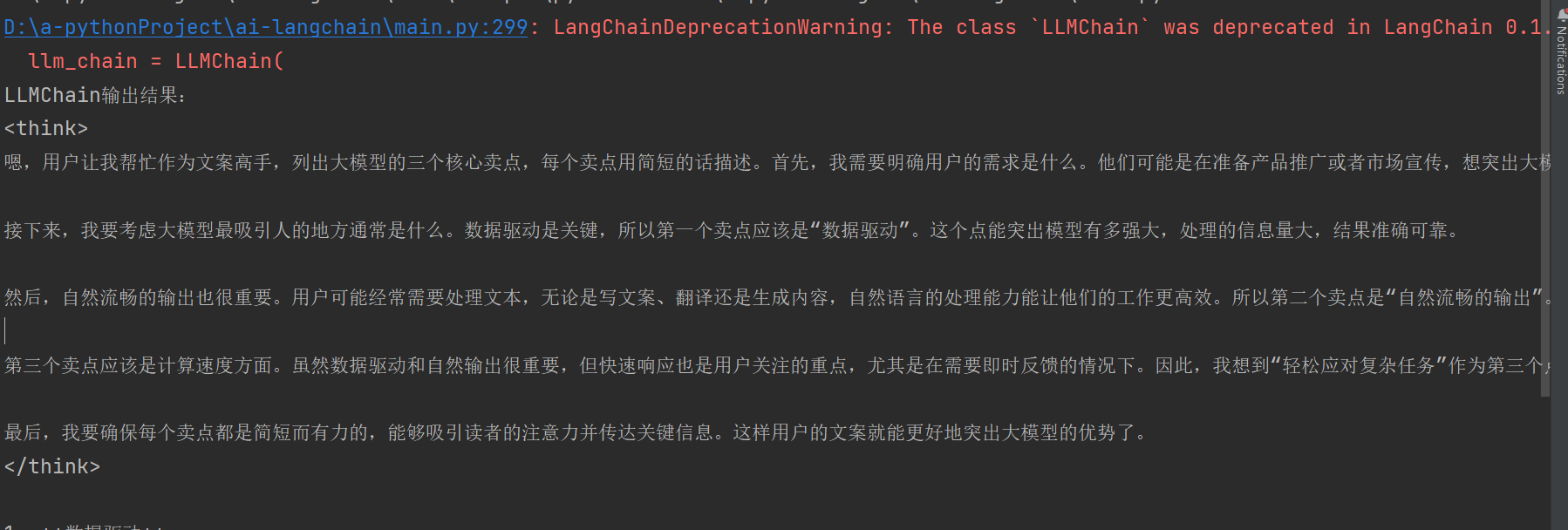
3.3 LLMChain的适用场景
LLMChain仅适合简单的单步任务,例如:
- 生成某产品的文案/卖点;
- 翻译指定文本(模板为"将{text}翻译成英文");
- 给文章起标题(模板为"给{article_content}起3个标题")。
局限性:无法实现多步骤流程(如"生成卖点→存储到Excel"),需用更复杂的链(如SequentialChain)或新版LCEL。
4. 新范式实战:LCEL(LangChain Expression Language)
LCEL是LangChain 0.3+推出的声明式编程语言 ,核心思想是用「管道符|」串联组件,替代旧版的类继承式链,解决了LLMChain的灵活性不足问题。
4.1 为什么需要LCEL?
旧版Chain(如LLMChain)存在以下痛点:
- 多组件组合繁琐(如"模板+模型+解析器"需手动封装);
- 不支持流式响应(无法实现ChatGPT的"逐字输出"效果);
- 同步/异步调用不统一(需分别处理同步
run()和异步arun())。
LCEL的核心优势正是解决这些痛点:
- 代码极简 :用
|串联组件,如prompt | model | parser; - 原生支持流式:可直接返回迭代器,实现"逐字输出";
- 标准化接口 :所有组件均实现
Runnable协议,输入输出均为字典,无缝衔接; - 高级功能内置:支持调试、重试、并行调用(如同时调用两个模型对比结果)。
4.2 LCEL的核心语法
LCEL的核心是「管道符|」,规则如下:
- 左侧组件的输出 → 作为右侧组件的输入;
- 所有组件的输入/输出均为字典格式(键为变量名,值为数据);
- 链的最终调用用
invoke()(同步)、ainvoke()(异步)或stream()(流式)。
语法结构示例:
python
# 组件1:提示模板(输入:question;输出:格式化后的prompt)
prompt = ChatPromptTemplate.from_template("回答问题:{question}")
# 组件2:大模型(输入:格式化后的prompt;输出:模型原始响应)
model = ChatOpenAI(...)
# 组件3:输出解析器(输入:模型原始响应;输出:纯文本)
parser = StrOutputParser()
# 用|串联成链
chain = prompt | model | parser
# 调用链(输入字典需包含question变量)
result = chain.invoke({"question": "如何学习AI大模型?"})4.3 LCEL完整实战案例(对比旧版LLMChain)
4.3.1 案例需求
实现"接收用户问题→生成格式化提示→调用模型→解析纯文本输出"的流程,对比LCEL与LLMChain的代码差异。
4.3.2 代码实现(LCEL版 vs LLMChain版)
python
# 导入依赖(LCEL需额外导入输出解析器)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
# 初始化大模型(两版共用)
model = ChatOpenAI(
model_name='deepseek-r1:7b', # 本地模型名称,根据实际情况填写
base_url="http://127.0.0.1:11434/v1", # 本地模型API地址
api_key="none", # 本地模型通常不需要真实API密钥
temperature=0.7 # 可根据需要调整温度参数
)
# --------------------------
# 方式1:新版LCEL实现(推荐)
# --------------------------
print("=== LCEL版输出 ===")
# 1. 定义提示模板(用ChatPromptTemplate,支持多轮对话格式)
lcel_prompt = ChatPromptTemplate.from_template(
"你是AI学习顾问,请用3个步骤回答:{question}"
)
# 2. 定义输出解析器(将模型响应转为纯文本)
parser = StrOutputParser()
# 3. 用管道符串联组件(prompt → model → parser)
lcel_chain = lcel_prompt | model | parser
# 4. 调用链(输入为字典,key与模板变量一致)
lcel_result = lcel_chain.invoke({"question": "零基础如何学习AI大模型?"})
print(lcel_result)
# --------------------------
# 方式2:旧版LLMChain实现
# --------------------------
print("\n=== LLMChain版输出 ===")
# 1. 定义提示模板
llmchain_prompt = ChatPromptTemplate.from_template(
"你是AI学习顾问,请用3个步骤回答:{question}"
)
# 2. 构建LLMChain(需显式传入llm和prompt)
llm_chain = LLMChain(
llm=model,
prompt=llmchain_prompt
)
# 3. 调用链(需传递字典参数)
llmchain_result = llm_chain.invoke({"question": "零基础如何学习AI大模型?"})
print(llmchain_result["text"])4.3.3 运行结果对比
两者输出逻辑一致,但LCEL代码更简洁(少了显式的LLMChain封装):
=== LCEL版输出 ===
<think>
嗯,我现在想开始学习人工智能大模型,但我对这个领域几乎一无所知。首先,我得弄清楚人工智能和大模型到底是什么。听说大模型像ChatGPT那样可以回答各种问题,这看起来很酷,但我不确定具体是怎么运作的。
接下来,我觉得基础知识是必须有的。数学方面,听说线性代数、微积分和概率统计很重要,但我对这些领域了解不多。我应该从哪里开始呢?可能需要找一些入门教程或者书籍来学习这些基础概念。然后编程基础也很重要,特别是Python,因为我知道它被广泛用于机器学习。如果我对编程不太熟悉,可能需要花时间学习数据结构、算法以及Python的基础语法。
接着是机器学习和深度学习的概念。我听说过监督学习、无监督学习和强化学习,但具体怎么操作还是模糊的。我还记得看到过一些模型,比如神经网络,但不清楚它们是如何训练起来的。可能需要找一个具体的项目来实践,逐步了解这些概念。另外,工具方面,像TensorFlow或PyTorch听起来很有用,但我不太清楚哪个更适合我,或者如何安装和使用它们。
然后是搭建自己的模型,这听起来有点复杂。听说可以通过开源库来实现,比如训练一个分类器,但实际操作起来可能需要处理大量数据和调参,这些我都不是很清楚该怎么开始。可能需要寻找一些教程或案例研究,一步步跟着走。
最后,关于AI的应用和伦理问题,我也感到好奇。我知道大模型被用来回答问题和生成内容,但它们在安全性和隐私方面可能会有问题。我得学习相关的伦理规范,确保我的使用符合道德标准,避免滥用这些技术。
总的来说,我需要系统地学习基础知识,逐步掌握编程技能,了解机器学习和深度学习的概念,并尝试实际操作来应用这些知识。同时,关注当前的研究和实践,保持对新知识的更新也是很重要的。
</think>
学习人工智能大模型可以从以下三个步骤开始:
1. **建立基础知识**:
- 学习数学:从基础的代数、微积分和统计学入手,理解线性代数、微积分和概率论在AI中的应用。
- 掌握编程:选择Python作为学习语言,掌握数据结构、算法和基础编程概念。可以通过在线课程或书籍逐步学习。
2. **了解机器学习与深度学习**:
- 学习概念:研究监督学习、无监督学习和强化学习的基本原理,理解神经网络和深度学习的运作机制。
- 实践操作:尝试构建一个简单的分类模型,使用TensorFlow或PyTorch进行数据处理和模型训练。
3. **实践与应用**:
- 开发项目:利用开源库构建和训练模型,如训练一个分类器或生成式AI工具。
- 关注前沿:追踪AI研究进展,了解大模型的最新发展和应用案例,确保理解和应用符合伦理规范。
=== LLMChain版输出 ===
D:\a-pythonProject\ai-langchain\main.py:355: LangChainDeprecationWarning: The class `LLMChain` was deprecated in LangChain 0.1.17 and will be removed in 1.0. Use :meth:`~RunnableSequence, e.g., `prompt | llm`` instead.
llm_chain = LLMChain(
<think>
好,我现在需要回答用户的问题:"零基础如何学习AI大模型?"按照要求,我需要用三个步骤来详细解释。让我仔细思考一下应该如何组织这些建议。
首先,我想第一步应该是关于基础知识的学习。因为AI大模型建立在很多技术的基础之上,所以必须先打好这些基础。数学和编程是关键,特别是线性代数、概率统计等数学知识对理解机器学习算法很重要。编程语言方面,Python是最常用的,因为它有丰富的库和支持社区,所以需要掌握基础语法和常用库的使用。
接下来是实践操作,也就是搭建AI大模型的项目。只有实际动手做,才能真正理解和应用所学知识。可以选择一些开源框架,比如TensorFlow或PyTorch,从简单的分类任务开始,逐步尝试改进模型性能。通过自己的项目积累经验,同时参考优秀案例和教程,可以更快地提升技能。
最后是持续学习和优化阶段。AI领域发展迅速,需要不断更新知识和工具。了解最新的技术趋势,如大语言模型的发展、模型压缩等,并将这些新知识应用到实际项目中。定期回顾并优化自己的模型,保持模型性能的竞争力。
现在,我应该把这些思路整理成三个步骤,每一步下面加上详细说明,确保内容清晰易懂。
</think>
零基础学习AI大模型可以分为以下三个步骤:
1. **打好数学和编程基础**
- 学习线性代数、概率统计、微积分等数学知识。
- 掌握Python编程,了解数据结构、算法和库如NumPy、Pandas的使用。
2. **实践操作,搭建AI模型项目**
- 利用开源框架(如TensorFlow、PyTorch)开始小规模项目,如文本分类或图像识别。
- 参考教程和案例,逐步学习构建和优化模型。
3. **持续学习与优化模型**
- 关注新技术如大语言模型进展、模型压缩等。
- 不断优化模型性能,并将新知识应用到实际项目中,提升模型效果。
Process finished with exit code 05. 旧版Chain vs 新版LCEL核心差异
为了帮助大家快速选择,整理两者的关键差异如下表:
| 对比维度 | 旧版Chain(如LLMChain) | 新版LCEL(LangChain 0.3+) |
|---|---|---|
| 构建方式 | 类继承(需实例化Chain子类) | 声明式管道(` |
| 代码简洁度 | 繁琐(需显式封装Chain) | 极简(一行串联多个组件) |
| 流式响应 | 不支持 | 原生支持(stream()方法) |
| 异步调用 | 需用arun(),接口不统一 |
原生支持(ainvoke()/astream()) |
| 组件兼容性 | 仅支持Chain子类 | 支持所有实现Runnable协议的组件 |
| 高级功能 | 无(需手动实现重试、并行) | 内置调试、重试、并行调用 |
| 适用场景 | 入门学习、简单单步任务 | 生产级应用、复杂多步骤流程 |
6. 总结
6.1 核心总结
- Chain的本质:组件的有序串联,解决多步骤AI任务的流程化问题;
- LLMChain定位:基础入门链,适合理解"模板+模型"的简单组合,已逐步被LCEL替代;
- LCEL优势 :LangChain 0.3+的推荐范式,用
|简化组装,支持流式、异步,适合生产场景。
如果本文对你有帮助,欢迎点赞+关注,后续会持续更新LangChain进阶实战内容!如有问题,也欢迎在评论区留言讨论~
