在企业数据架构中,PostgreSQL凭借其强大的扩展性、事务一致性以及对JSON、GIS、时序数据的原生支持,已成为常见的开源数据库之一。然而,真正的挑战并非PostgreSQL本身的性能,而是如何高效、实时地将MySQL、TiDB、SQL Server、API等多源数据聚合到PostgreSQL中,构建统一、可信、可分析的数据资产。ETLCloud通过"ETL+CDC(Change Data Capture)"双轮驱动,将传统的T+1批量同步升级为分钟级甚至秒级的增量pipeline,让PostgreSQL成为企业实时数据版图的核心枢纽。
一、PostgreSQL的通用性:一库多用的全能选手
PostgreSQL它原生支持JSON/JSONB文档模型,无需额外的NoSQL数据库即可存储和查询半结构化数据;内置PostGIS扩展,轻松处理空间地理信息;TimescaleDB插件让其摇身一变成为高性能时序数据库;数组、范围类型、自定义操作符和函数,更是为复杂业务场景提供了无限可能。一份PostgreSQL实例,同时支撑OLTP交易、OLAP分析、时序数据、GIS服务、JSON文档和键值缓存,真正做到了"一库多用",避免了技术栈的碎片化,显著降低了运维复杂度和总体拥有成本。
二、ETLCloud聚合多源数据:拖拽之间,异构统一
面对MySQL、TiDB、SQL Server、Oracle、REST API、Excel、CSV、MongoDB等30余种数据源,ETLCloud提供了"数据源中心"这一统一入口。只需一次注册,平台自动管理JDBC/HTTP连接池、SSL证书和字符集编码。拖拽式的"输入组件"让数据工程师告别了繁琐的FDW、外部表和触发器,字段映射、数据类型转换、主键冲突处理、分区路由等操作全部可视化配置。十分钟内,即可将异构数据源的结构与PostgreSQL的模型对齐,且全程支持一键回滚,让试错成本趋近于零。
三、CDC实时捕获
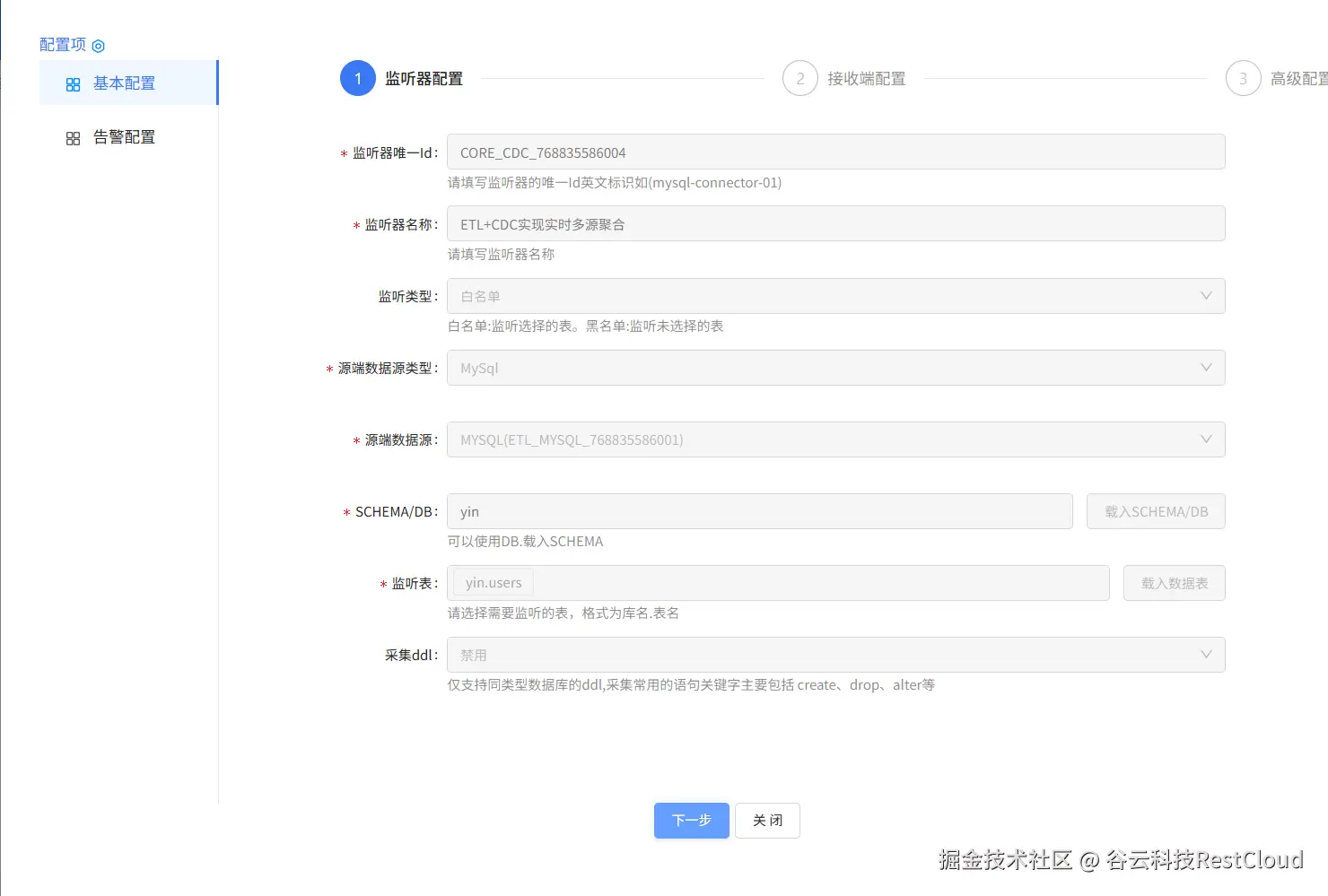
传统批量同步的高延迟、高负载已成为历史。ETLCloud基于binlog、ticdc、WAL逻辑复制槽,实现对Insert/Update/Delete事件的秒级捕获。增量事件首先写入内置Kafka,支持断点续传和位点回溯,即使下游PostgreSQL停机维护,也能在重启后从断点继续传输,确保数据零丢失。
四、实操:MySQL→PostgreSQL增量链路
流程设计
1.库表输入-MySQL
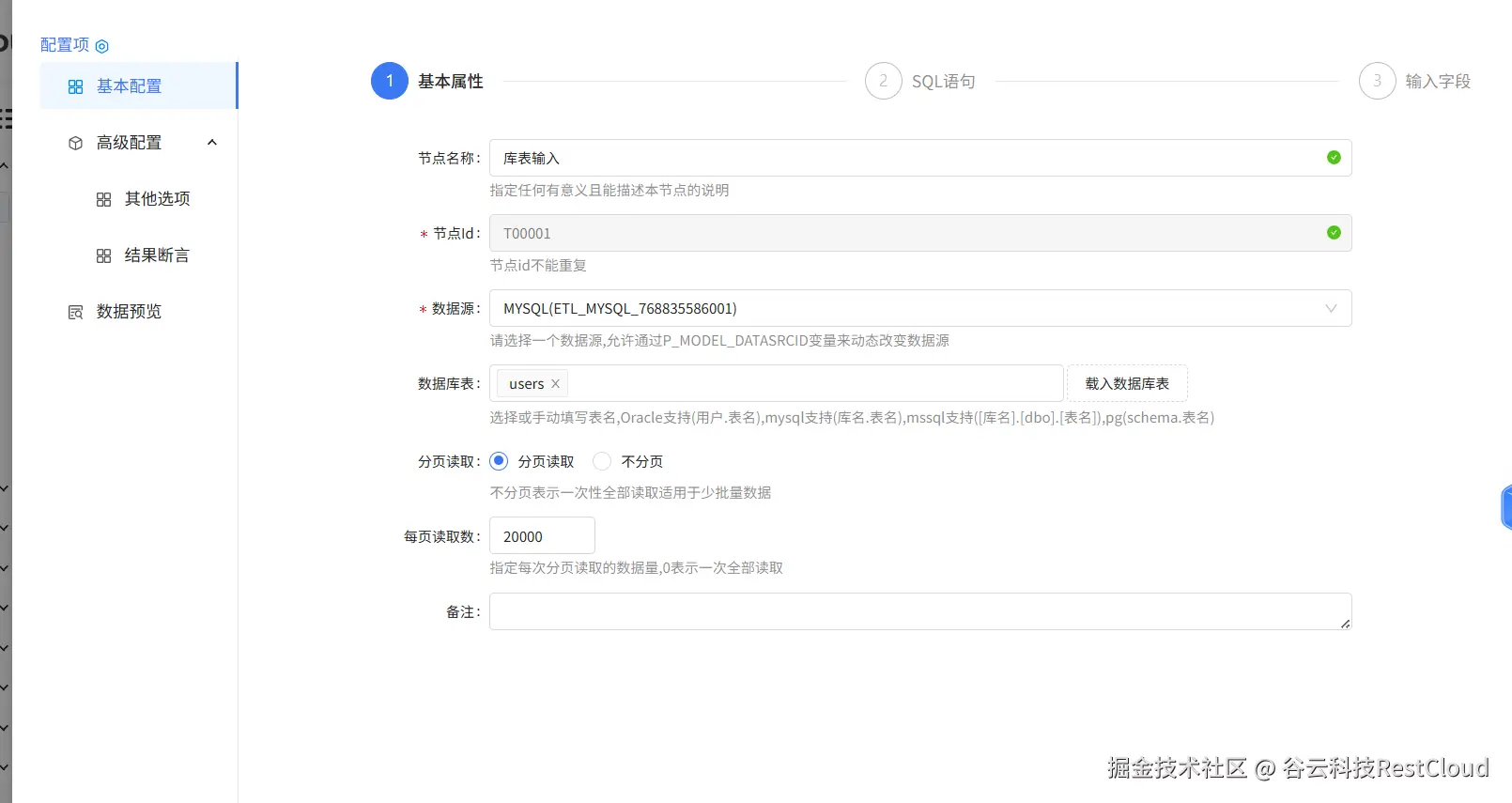
2.库表输入
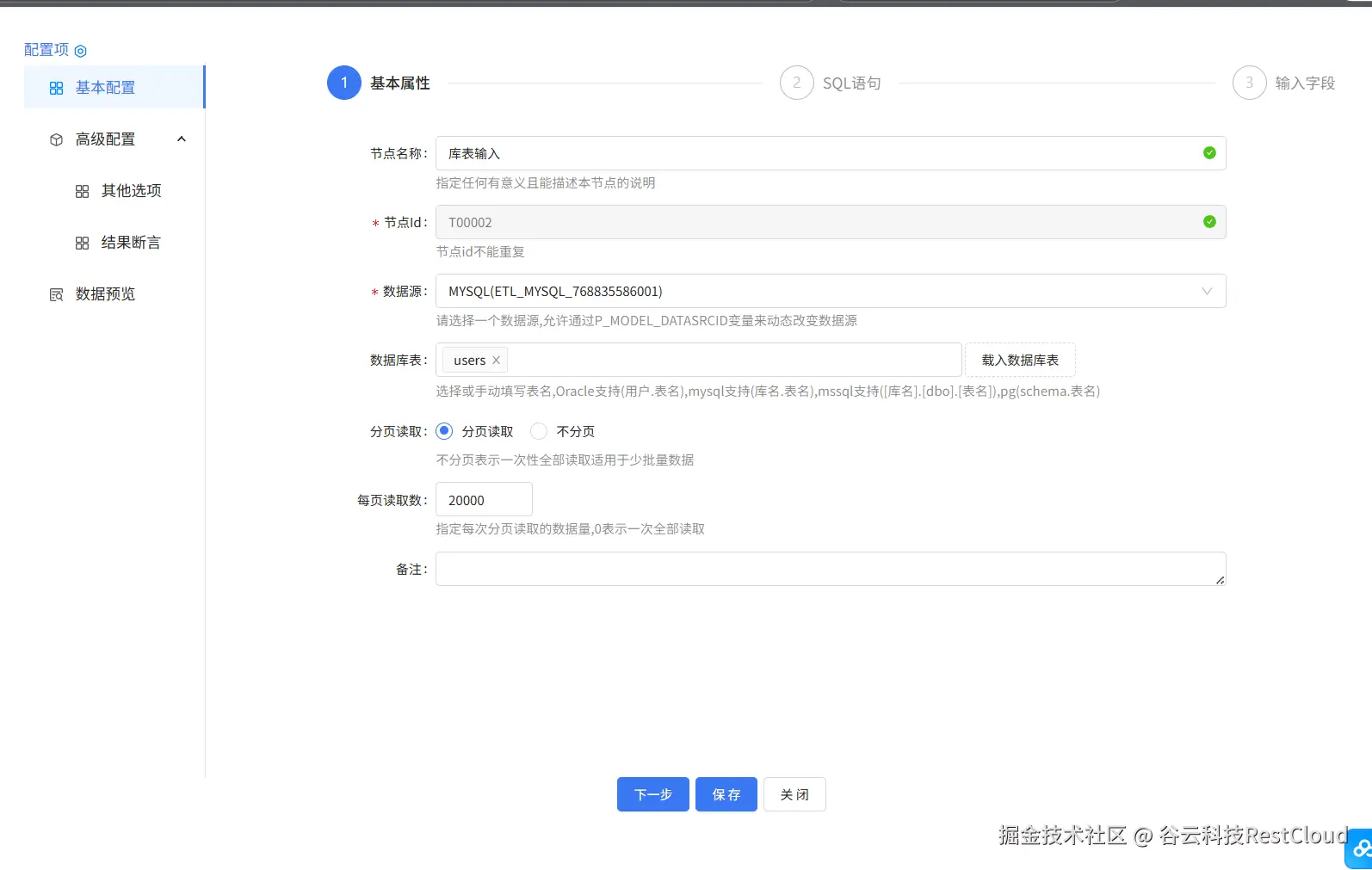
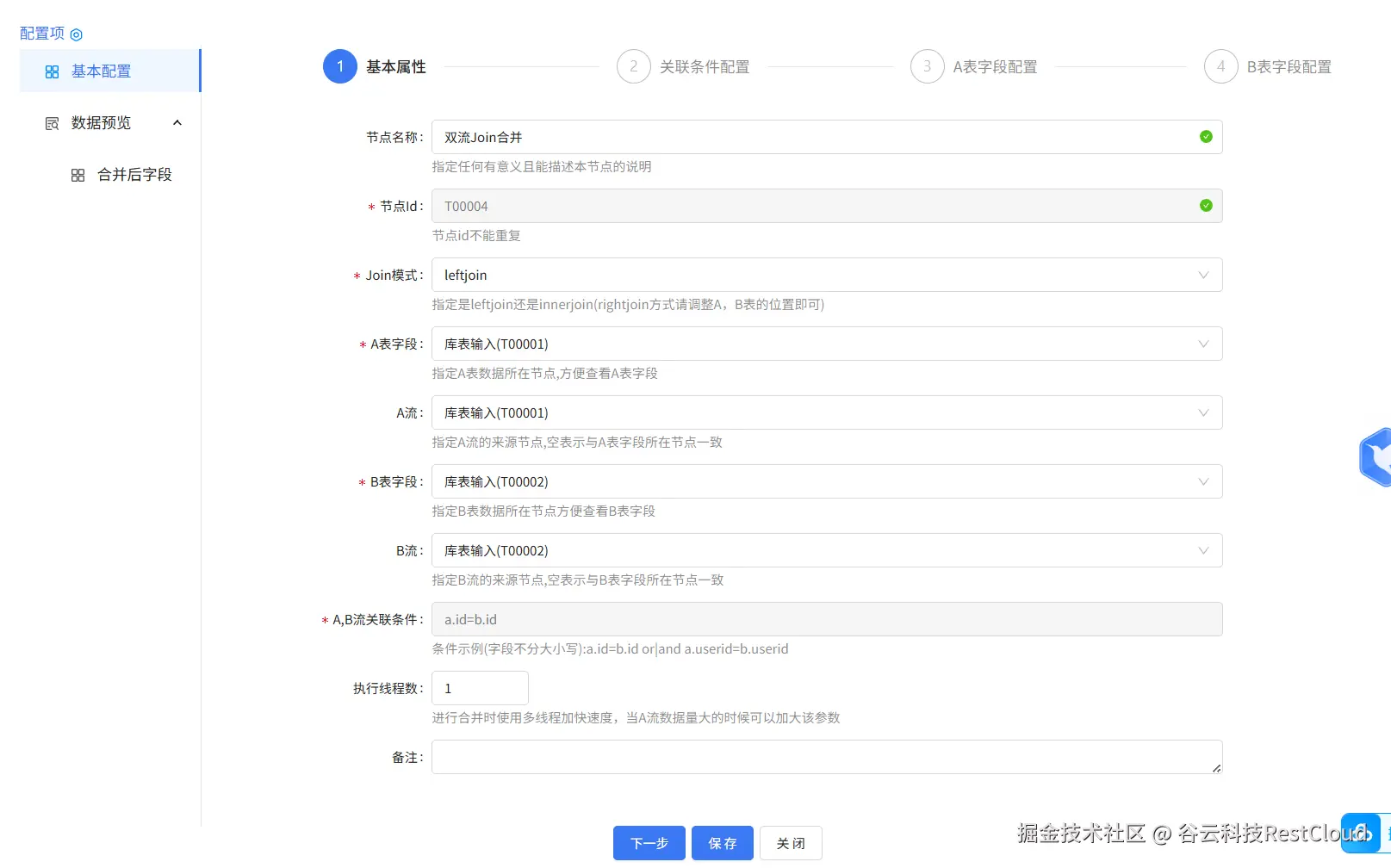
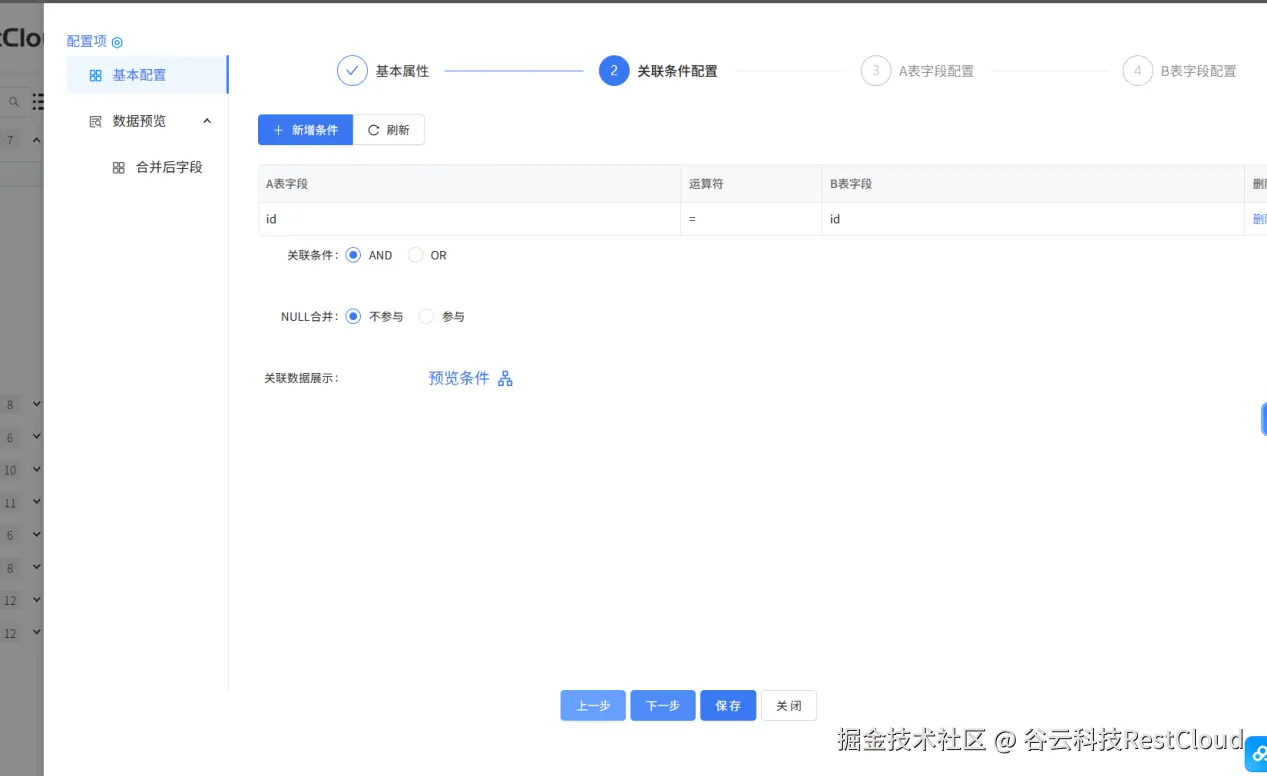
3.双流 Join聚合
4.库表输出
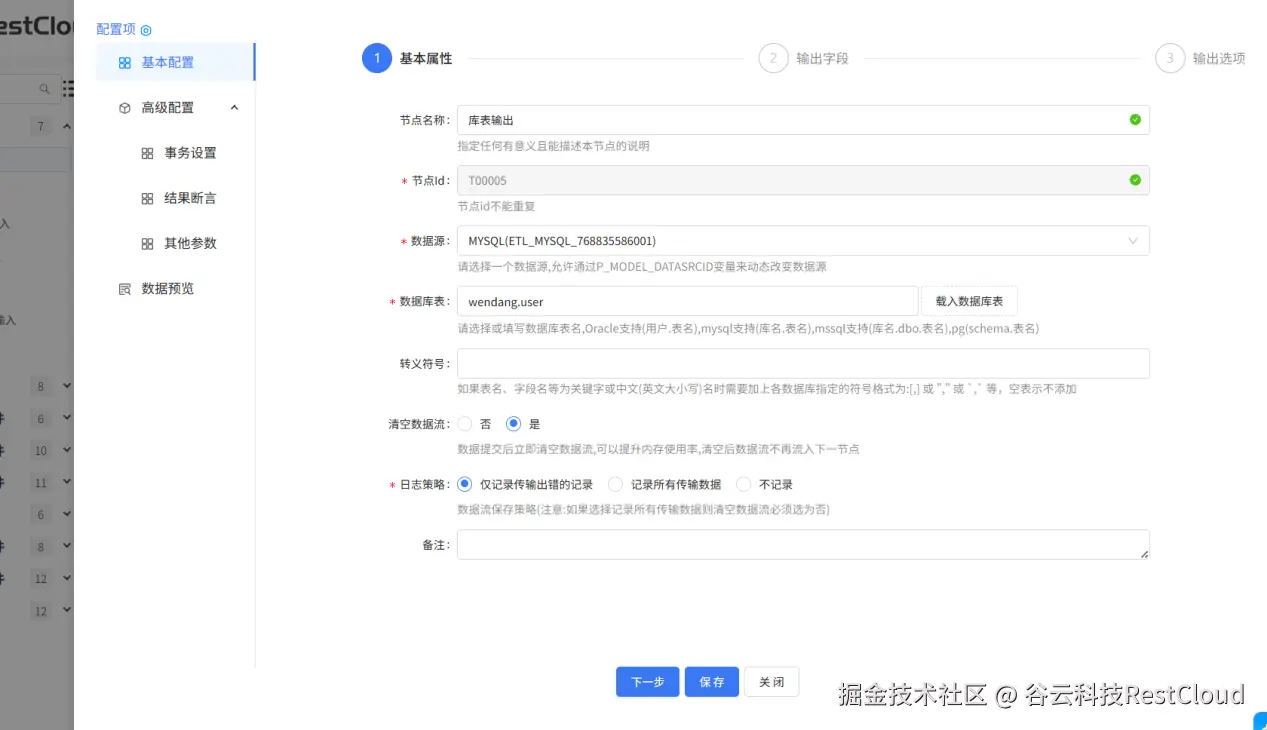
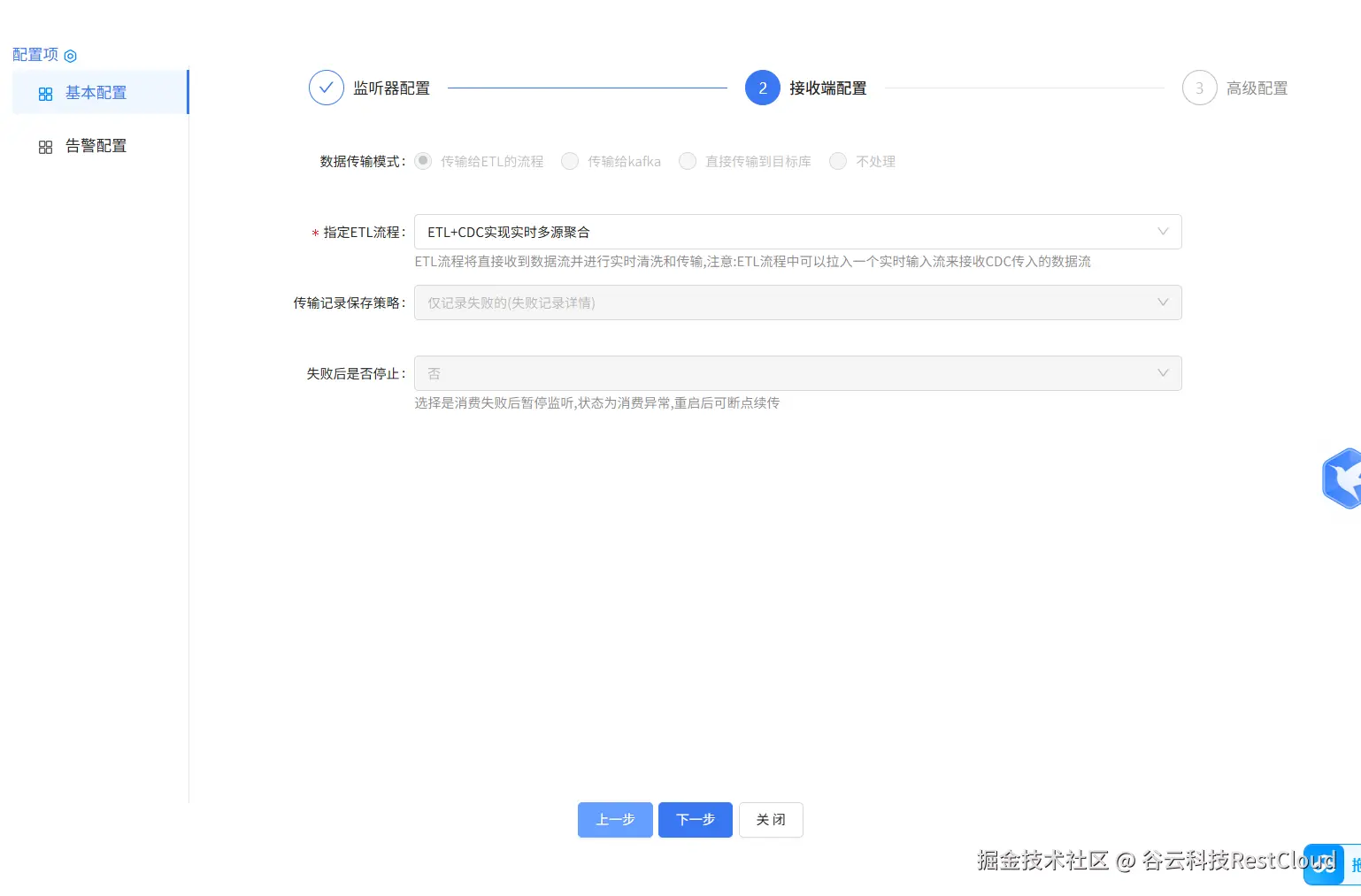
5.创建 CDC 任务
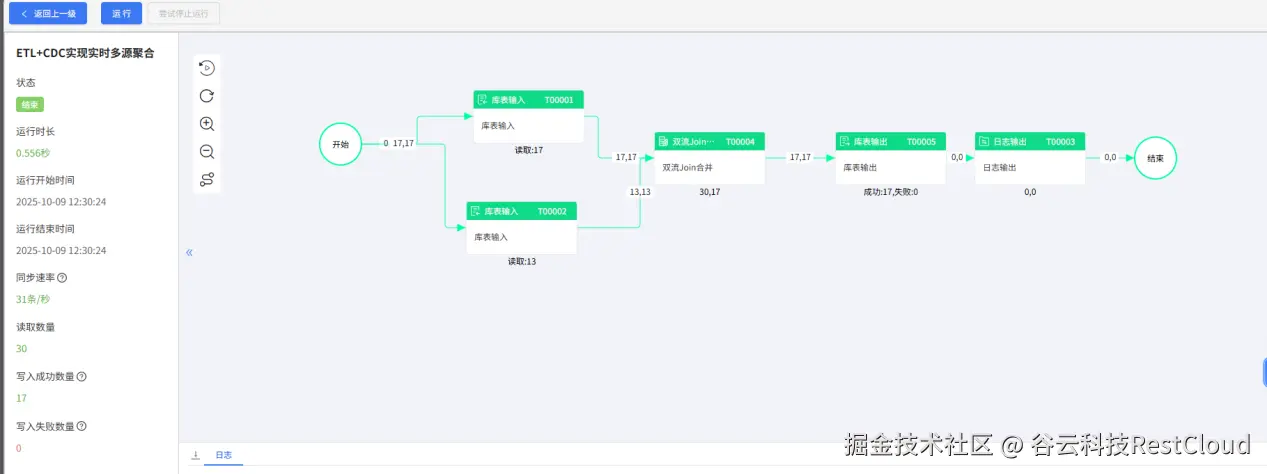
运行结果:
最后
ETLCloud通过自动化数据集成,能帮助企业快速的进行数据聚合操作,提高数据处理效率和准确性。利用ETLCloud,用户可以摆脱传统方式繁琐的数据聚合步骤,实现数据处理流程的可控和可管理,并结合CDC,能够使数据能及时准确的聚合使用。ETL能够帮助您实现目标,提升数据管理的效率和效果