随着企业数字化转型的加速,数据库作为业务的核心底座,正面临着前所未有的挑战:高并发连接的瓶颈、存储空间的持续膨胀、以及高可用性切换对外部组件的过度依赖。 尤其是在 PostgreSQL 体系中,传统的 MVCC(多版本并发控制)机制在高频更新场景下,容易导致性能剧烈波动(TPCC 模型下波动常超 40%)和存储空间持续占用。
正是在这一背景下,天翼云结合 TeleDB 在电信集团及天翼云客户实战打磨的企业级经验,推出了 OpenTeleDB。这款数据库致力于完美兼容 PostgreSQL 生态,同时通过架构创新,解决其在企业级应用中的核心痛点。
接下来,我就来尝试使用这款数据库,并将数据库迁移到 OpenTeleDB 上来。
OpenTeleDB 的安装与启动
打开 OpenTeleDB 数据库开源社区 链接,展开顶部导航栏的产品 项,这时我们可以看到 OpenTeleDB 项,点击 OpenTeleDB。
这里有 Gitee 和 Github 两个选项,大家可以根据自己的条件来选择,我这里用 Gitee 来拉文件。
点击 克隆下载,可以看到弹窗
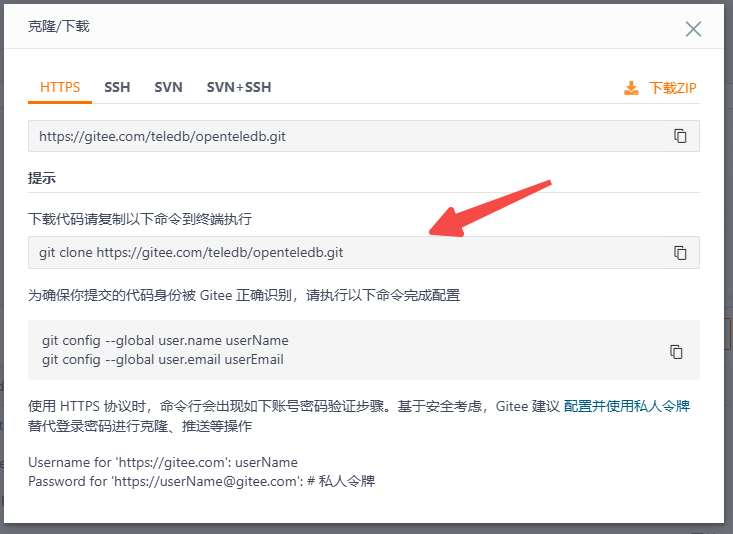
复制克隆代码的命令到 Linux 终端中,等待代码克隆完成

然后输入下面的命令安装相关依赖,
bash
yum install -y curl-devel libicu-devel pam-devel krb5-devel openldap-devel systemd-devel readline readline-devel zlib zlib-devel gettext gettext-devel openssl openssl-devel pam pam-devel libxml2 libxml2-devel libxslt libxslt-devel perl perl-devel tcl-devel uuid-devel gcc gcc-c++ make flex bison perl-ExtUtils* libcurl-devel asciidoc xmlto opensp mariadb-devel libtool libuuid-devel gflags-devel lcov libyaml-devel boost boost-devel libgsasl-devel cmake3 golang liblz4-dev pkg-configUbuntu 可以试试这个进行安装:
bash
sudo apt-get update && sudo apt-get install -y \
libcurl4-openssl-dev libicu-dev libpam0g-dev libkrb5-dev libldap2-dev libsystemd-dev \
readline-common libreadline-dev zlib1g zlib1g-dev gettext libssl-dev \
libxml2 libxml2-dev libxslt1.1 libxslt1-dev perl libperl-dev tcl-dev \
uuid-dev gcc g++ make flex bison libextutils-parsexs-perl \
libcurl4-openssl-dev asciidoc xmlto opensp libmariadb-dev-compat \
libtool uuid-dev libgflags-dev lcov libyaml-dev libboost-all-dev \
libgsasl-dev cmake golang-go liblz4-dev libzstd-dev然后设置 OpenTeleDB 的安装路径,我在这打算把 OpenTeleDB 安装到 /usr/local/openteledb 路径,就这样设置安装路径
bash
export pg_install_dir=/usr/local/openteledb
export pg_data_dir=${pg_install_dir}/data确保目录存在并赋予权限:
bash
sudo mkdir -p $pg_install_dir
sudo chown -R $USER:$USER $pg_install_dir
进入我们刚刚克隆的 OpenTeleDB 的代码的目录,设置编译参数
bash
./configure --prefix=${pg_install_dir} \
--with-zstd --with-lz4 --with-openssl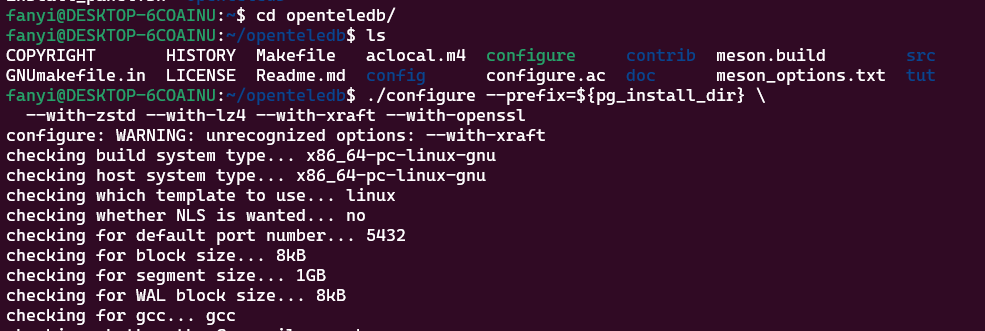
🌟 如果和我一样出现:Ubuntu 上默认安装的 lz4 库不带 pkg-config 文件 (liblz4.pc)
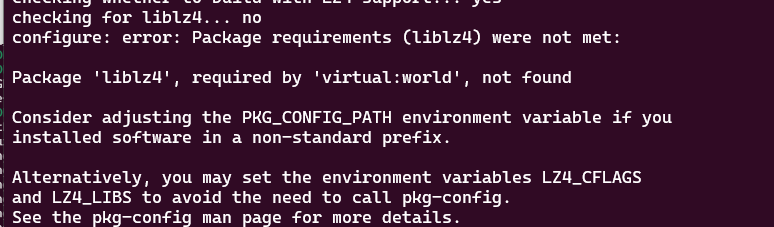
解决方法:安装 lz4 + lz4 pkg-config 支持,命令如下:
bash
sudo apt-get install -y liblz4-dev pkg-config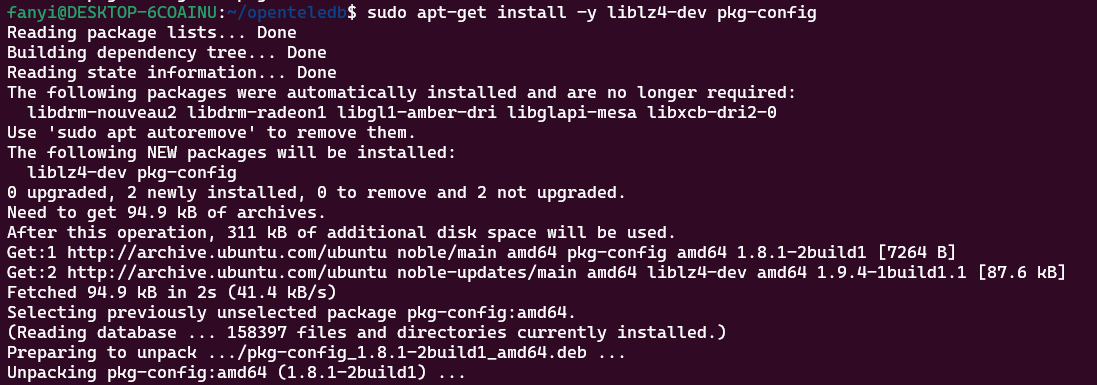
安装完成后验证一下,应该输出类似 -llz4 的内容
bash
pkg-config --libs liblz4 # 应该输出类似:-llz4 的内容
再次设置编译参数,设置完成后使用 make -j$(nproc) 命令开始编译:

编译完成后使用 make install 命令进行安装
安装完成后使用下面命令初始化数据库
bash
${pg_install_dir}/bin/initdb -D ${pg_data_dir}
使用以下命令启动数据库:
bash
${pg_install_dir}/bin/pg_ctl -D ${pg_data_dir} start
看到 server started 就意味着服务启动了!
OpenTeleDB 的连接与迁移
我这里使用 Navicat 进行数据库的连接,打开 Navicat ,点击左上角的连接
点击 PostgreSQL
填写数据库的相关信息
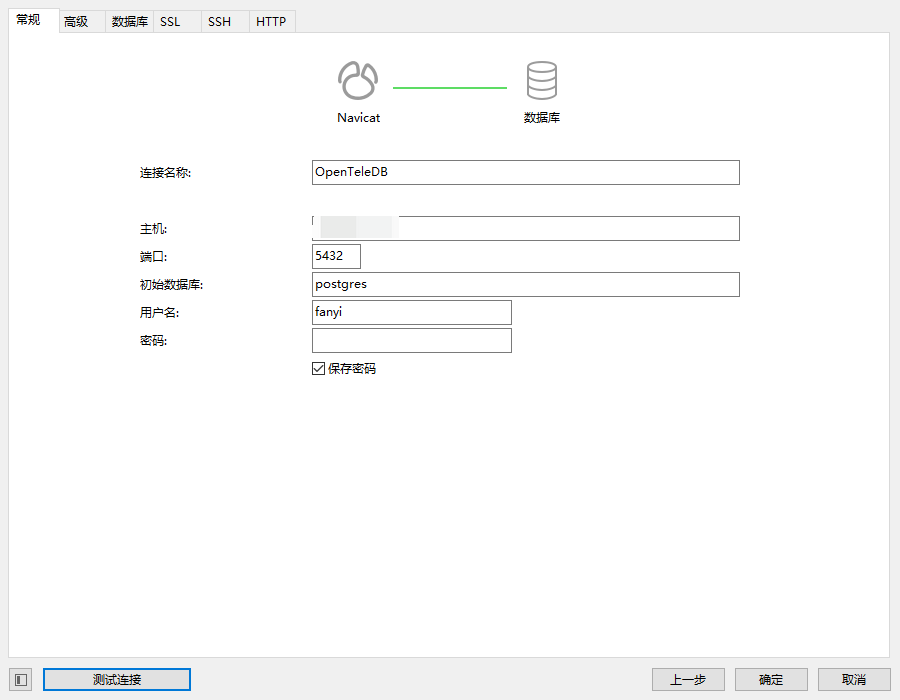
点击测试链接看看能否测试成功:

成功后点击我们刚刚的数据库即可进行图形化的 OpenTeleDB 数据库操作
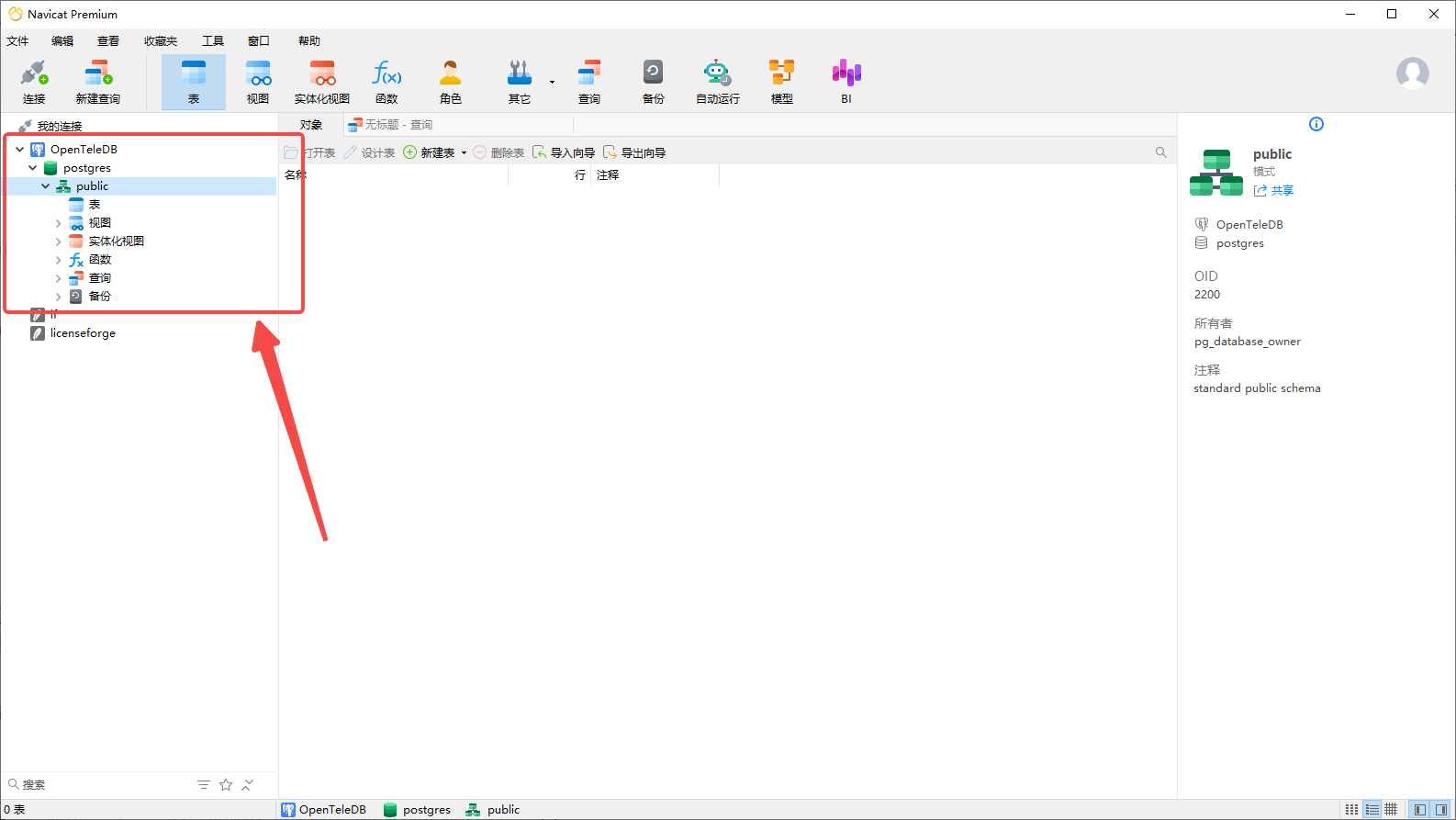
使用图形数据库管理工具,我们可以更方便的进行增删改查、备份、导入导出等一些数据库操作。
对于小型数据库我们可以导入导出,对于数据量较大的数据库,还是使用 pgloader 类似的数据库工具来进行迁移会比较安全方便。
我有一个 cavt MySQL 数据库,接下来我将使用 pgloader 将该数据库迁移到 OpenTeleDB 中。

使用下面命令安装 pgloader:
bash
sudo apt-get install pgloader
使用 pgloader 工具进行 cavt 数据库的迁移:
js
pgloader mysql://user:pass@localhost/dbname \
postgresql://user:pass@localhost:5432/dbname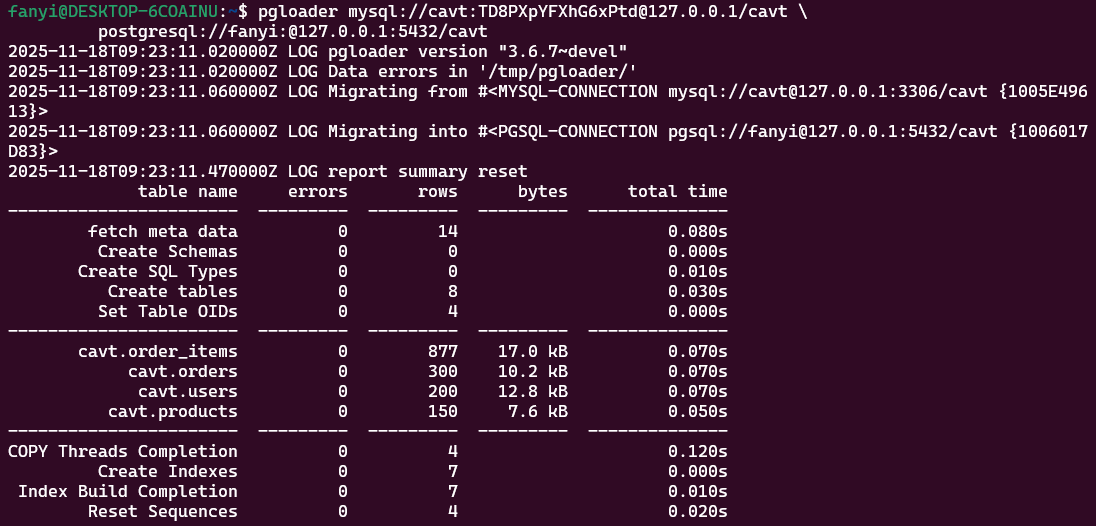
迁移完成后,可以打开图形化数据库管理工具看到我们迁移后的数据库。
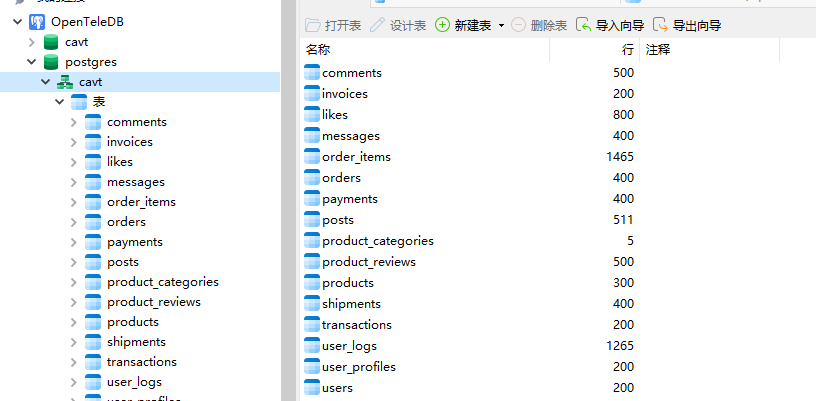
在将 cavt 库从 MySQL 迁移到 OpenTeleDB 的过程中,我最直观的体验是 迁移成本比预期更低。
在传统认知里,从一个数据库迁移到另一种数据库,常常会有很多问题:
- SQL 兼容性问题
- 类型转换问题
- 外键约束同步问题
- 工具链适配问题
但在使用 OpenTeleDB 配合 pgloader 时,我的实际体验可以总结为三个字:很丝滑。
迁移完成后,打开 Navicat 检查数据,一次通过,所有表与记录均成功迁移。
在完成数据库的结构迁移之后,我的 Flask 项目本身也需要做一些适配,才能让原来的 MySQL 业务平滑切换到 OpenTeleDB。好在 OpenTeleDB 自身兼容 PostgreSQL 协议,因此 Flask 侧的改动相对可控,核心点主要包括 驱动更换、连接串调整、SQL 方言差异修正、ORM(SQLAlchemy)配置变化等几个方面。
1. 数据库驱动的更换
MySQL 使用:
python
pymysqlOpenTeleDB 使用 PostgreSQL 驱动:
python
psycopg2如果你的项目使用 SQLAlchemy,则需要安装:
bash
pip install psycopg2-binary2. Flask SQLAlchemy 数据库连接串修改
MySQL 以前的写法:
python
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://user:pass@localhost:3306/cavt"迁移到 OpenTeleDB:
python
SQLALCHEMY_DATABASE_URI = "postgresql+psycopg2://opentel:opentel@localhost:5432/cavt"其中:
postgresql+psycopg2------ 必须改成 PostgreSQL 方言opentel:opentel------ 你的 OpenTeleDB 用户名与密码5432------ OpenTeleDB 默认端口/cavt------ 迁移过来的库名
这一步是 Flask 项目能否连上 OpenTeleDB 的关键。
3. SQL 语句兼容性调整
OpenTeleDB 基于 PostgreSQL,因此和 MySQL 在 SQL 层面有一些差异,需要检查:
① 主键自增字段
MySQL:
sql
id INT AUTO_INCREMENT PRIMARY KEYPostgreSQL 应改为:
sql
id SERIAL PRIMARY KEY如果你使用 SQLAlchemy 模型,则自动兼容,无需修改:
python
id = db.Column(db.Integer, primary_key=True)② 字符串拼接
MySQL:
sql
SELECT CONCAT(a, b) FROM table;OpenTeleDB / PostgreSQL:
sql
SELECT a || b FROM table;如果迁移 SQL 脚本,可能需要搜索一下 CONCAT 并替换。
③ LIMIT 用法一致
两者都支持:
sql
LIMIT 10 OFFSET 20基本不用改。
④ 布尔字段差异
MySQL 的 TINYINT(1) 经常被用作 True / False,
迁移到 OpenTeleDB 后建议改为标准的:
sql
BOOLEANSQLAlchemy 会自动处理,无需手动改字段。
4. SQLAlchemy 模型迁移(几乎零改动)
比如以前的 MySQL 模型:
python
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(255))
age = db.Column(db.Integer)迁移到 OpenTeleDB 后 完全不需要修改。
SQLAlchemy 会自动适配 PostgreSQL 类型。
这里就是 OpenTeleDB 兼容 PostgreSQL 的最大优势:ORM 层迁移成本极低。
5. 对 Flask 业务代码的影响
迁移后 Flask 代码层面,主要有几处要注意:
① 排序 nulls 处理差异
MySQL 默认 NULL 值在排序时较小。
PostgreSQL 则需要显式:
sql
ORDER BY created_at NULLS LAST如果你的业务有依赖 NULL 排序,需要注意检查。
② JSON 类型更强大
MySQL 的 JSON 类型功能偏弱,而 PostgreSQL(OpenTeleDB)支持:
- JSONB(二进制索引更快)
- 全文搜索
->、->>、#>>操作符
例如 Flask 中:
python
User.query.filter(User.profile['nickname'].astext == 'Tom')迁移后性能通常会更高。
6. Flask 数据库初始化与迁移脚本改动
如果你使用 Flask-Migrate,则需要重新生成迁移脚本:
bash
flask db migrate -m "migrate to OpenTeleDB"
flask db upgrade因为一些字段类型需要同步到 PostgreSQL 类型系统。
7、迁移后回归自测
迁移完成后,我做了一轮"回归自测",确认迁移到 OpenTeleDB 后核心读写链路至少不退化。
- 测试方式:同一份脚本、同机环境,分别连接"原库(迁移前)"与"OpenTeleDB(迁移后)",执行
insert/select/update/delete四类操作 - 测试参数:10 并发线程、总数据量 10000 行、重复 10 轮取均值(并剔除极大/极小值)
结果(平均耗时/秒):
| 操作类型 | 原库(迁移前)(s) | OpenTeleDB(迁移后)(s) |
|---|---|---|
| insert | 9.7717 | 1.0747 |
| select | 3.2822 | 1.0684 |
| update | 0.1785 | 0.0578 |
| delete | 0.0901 | 0.0373 |
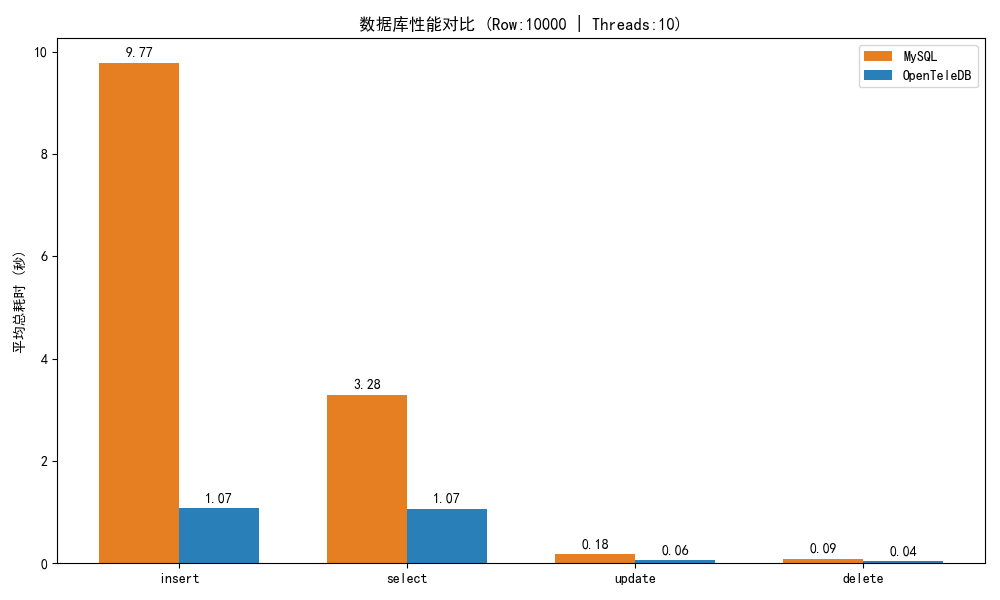
这组数据我只用来回答一个问题:迁移后是否出现明显性能回退。更能体现 OpenTeleDB 核心价值的部分,我放在后面的 XProxy/XStore 实验里展开。
| 层面 | 是否需要修改 | 说明 |
|---|---|---|
| 驱动 | 必改 | 从 PyMySQL → psycopg2 |
| 连接串 | 必改 | 改为 PostgreSQL 方言 |
| SQL 语法 | 少量 | 主要是 CONCAT、自增字段、JSON |
| ORM 模型 | 基本不用改 | SQLAlchemy 自动对接 |
| 业务逻辑 | 大多无需修改 | 除非有 MySQL 特定语法 |
| 迁移工具 | 已完成 | pgloader 迁移结构 + 数据 |
OpenTeleDB 的 XProxy 与 XStore
前面把 OpenTeleDB 的安装、连接、迁移以及 Flask 侧的适配都跑通后,我接下来做了两件事:
1)把连接入口切到 XProxy(重点看高并发连接与读写分离)
2)在相同的业务表模型下,体验 XStore 的原位更新(重点看空间膨胀与稳定性)
这两块也是 OpenTeleDB 相比"标准 PostgreSQL 使用姿势"最值得写出真实感的部分。
一、XProxy:连接池与读写分离
1)XProxy 构建与启动
我这里直接进入源码目录构建 XProxy(脚本相对路径在 openteledb/contrib/xproxy)
bash
sh ./ctg_build.sh
cd xproxy
构建完成后,根目录下会生成 xproxy 目录,里面一般包含 bin(启动脚本/二进制)、etc(配置)、lib(依赖库)。
然后我按一主一备(或一写一读)的思路配置 endpoints,再补上 watchdog 的探活账号。
把下面保存为 xproxy/etc/xproxy.conf(或你喜欢的路径),然后在 xproxy/bin 下启动:
bash
# 服务相关配置
daemonize no
unix_socket_dir "/tmp"
unix_socket_mode "0644"
locks_dir "/tmp/odyssey"
use_unix_socket_if_possible yes
graceful_die_on_errors no
enable_online_restart no
bindwith_reuseport no
# 注意:如果你在同一台机器跑多个 xproxy,pid_file 必须不同
pid_file "/tmp/odyssey-xproxy.pid"
# 日志
log_file "./xproxy.log"
log_format "%p %t %l [%i %s] (%c) %m\n"
log_to_stdout no
log_syslog no
log_syslog_ident "xproxy"
log_syslog_facility "daemon"
log_debug no
log_config yes
log_session yes
log_query no
log_stats no
stats_interval 60
# 性能相关配置
workers 4
resolvers 1
readahead 8192
cache_coroutine 100112
coroutine_stack_size 4
nodelay yes
keepalive 15
keepalive_keep_interval 5
keepalive_probes 3
keepalive_usr_timeout 0
# 全局限制
client_max 200000
server_login_retry 1
# 监听端口(按需改,避免冲突)
listen {
host "*"
port 6101
backlog 4096
compression no
port_attrs "Read-write"
}
listen {
host "*"
port 6103
backlog 4096
compression no
port_attrs "Read-only"
}
# 存储节点配置(主从两套 WSL,用不同 IP/端口)
storage "openteledb_server" {
type "remote"
endpoints {
endpoint {
hostname "<PRIMARY_WSL_IP>"
port 5432
weight 0.0
application_name ""
}
endpoint {
hostname "<STANDBY_WSL_IP>"
port 5433
weight 10.0
application_name "<STANDBY_WSL_IP>:5433"
}
}
target_session_attrs "read-write"
watchdog {
storage "openteledb_server"
storage_db "postgres"
storage_user "<DB_USER>"
storage_password "<DB_PASSWORD>"
pool_routing "internal"
pool "transaction"
pool_size 10
pool_timeout 0
pool_ttl 0
log_debug no
replication_delay_threshold 0
catchup_timeout 15
}
}
# 数据库和用户配置
database default {
# 内部认证账号(不需要在 PG 里真实存在)
user "user_aq_internal_pooling" {
authentication "none"
storage "openteledb_server"
pool "session"
storage_db "postgres"
storage_user "<DB_USER>"
storage_password "<DB_PASSWORD>"
log_debug no
log_query no
pool_size 10
pool_timeout 10000
pool_routing "internal"
enable_quantiles_state yes
catchup_timeout 4
}
user default {
authentication "scram-sha-256"
allow_clear_text_frontend_auth no
auth_query "SELECT usename, passwd FROM pg_shadow WHERE usename=$1"
auth_query_db "postgres"
auth_query_user "user_aq_internal_pooling"
target_server_attrs "auto"
client_max 100000
storage "openteledb_server"
pool "transaction"
pool_size 112
pool_timeout 0
pool_ttl 1800
pool_cancel yes
pool_rollback yes
pool_idle_in_transaction_timeout 0
pool_reserve_prepared_statement yes
pool_prepared_statement_limit 500
pool_prepared_statement_expired_time 120
client_fwd_error yes
server_lifetime 3600
application_name_add_host yes
reserve_session_server_connection no
log_debug no
enable_quantiles_state yes
replication_delay_threshold 30000000
catchup_timeout 5
enable_read_only_blacklist yes
}
}
# console
storage "local" { type "local" }
database "console" {
user default {
authentication "scram-sha-256"
auth_query "SELECT usename, passwd FROM pg_shadow WHERE usename=$1"
auth_query_db "postgres"
auth_query_user "user_aq_internal_pooling"
role "admin"
pool "session"
storage "local"
quantiles "0.95,0.5"
}
}启动命令如下:
bash
cd xproxy/bin
sh xproxy-start.sh ../etc/xproxy.conf启动后我会顺手看一下进程和日志:
bash
ps -ef | grep xproxy
tail -f xproxy.log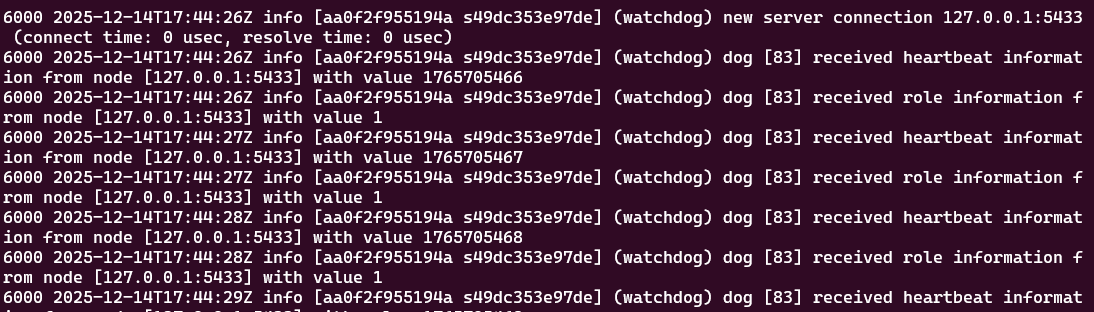
日志里能看到 watchdog 持续探测节点心跳、角色与延迟,这个细节其实挺加分:它说明 XProxy 的读写分离并不是"拍脑袋路由",而是有状态的。
2)变化 A:前端连接很多,但后端连接数能被"压平"
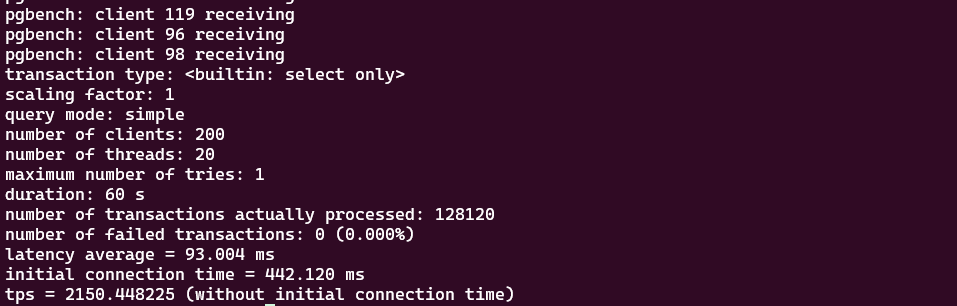
为了模拟真实业务里"短连接风暴"的场景,我用 pgbench -C(每个事务新建连接)做了一个对比:
bash
pgbench -h <xproxy_host> -p 6001 -U <user> -d <db> -c 200 -j 20 -T 60 -C -S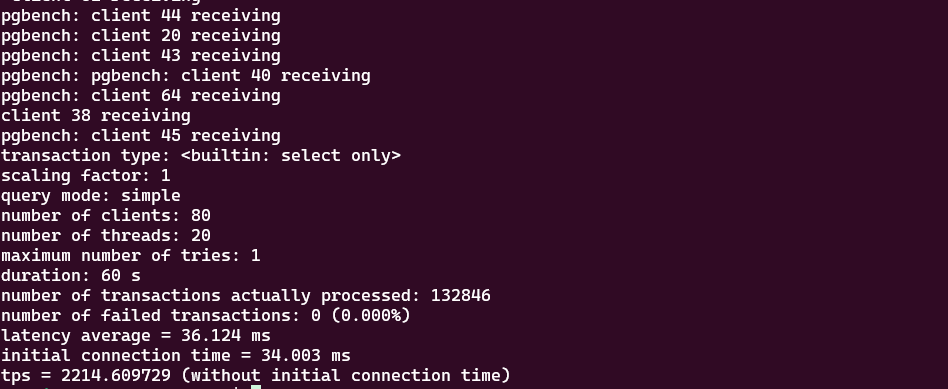
压测过程中,我会同时开一个 XProxy 的 console 看连接池状态:
bash
psql -h <xproxy_host> -p 6001 console
进入后执行:
sql
show clients;
show pools;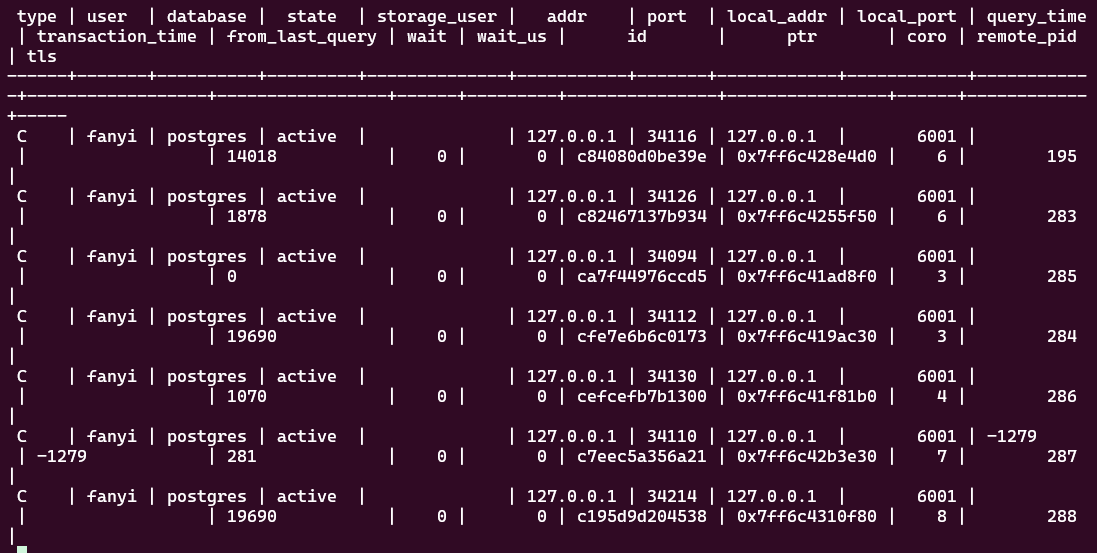
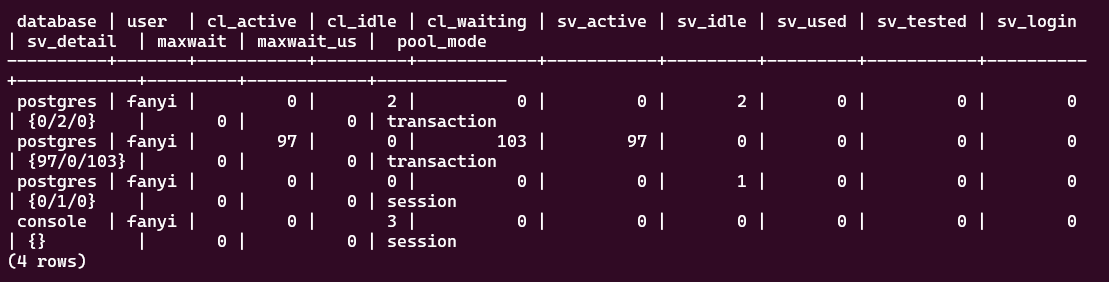
我最直观的感受是:当客户端并发连接数拉高时,XProxy 的 show pools 里 server connection 的数量不会等比例暴涨,更多是把"很多前端连接"复用到"少量后端连接"上。
同样是并发,直连模式数据库端连接数会很快堆上去;走 XProxy 后,我能明显看到大量 client connection 被复用到更少的 server connection 上,连接数曲线更平,压测过程也更稳。
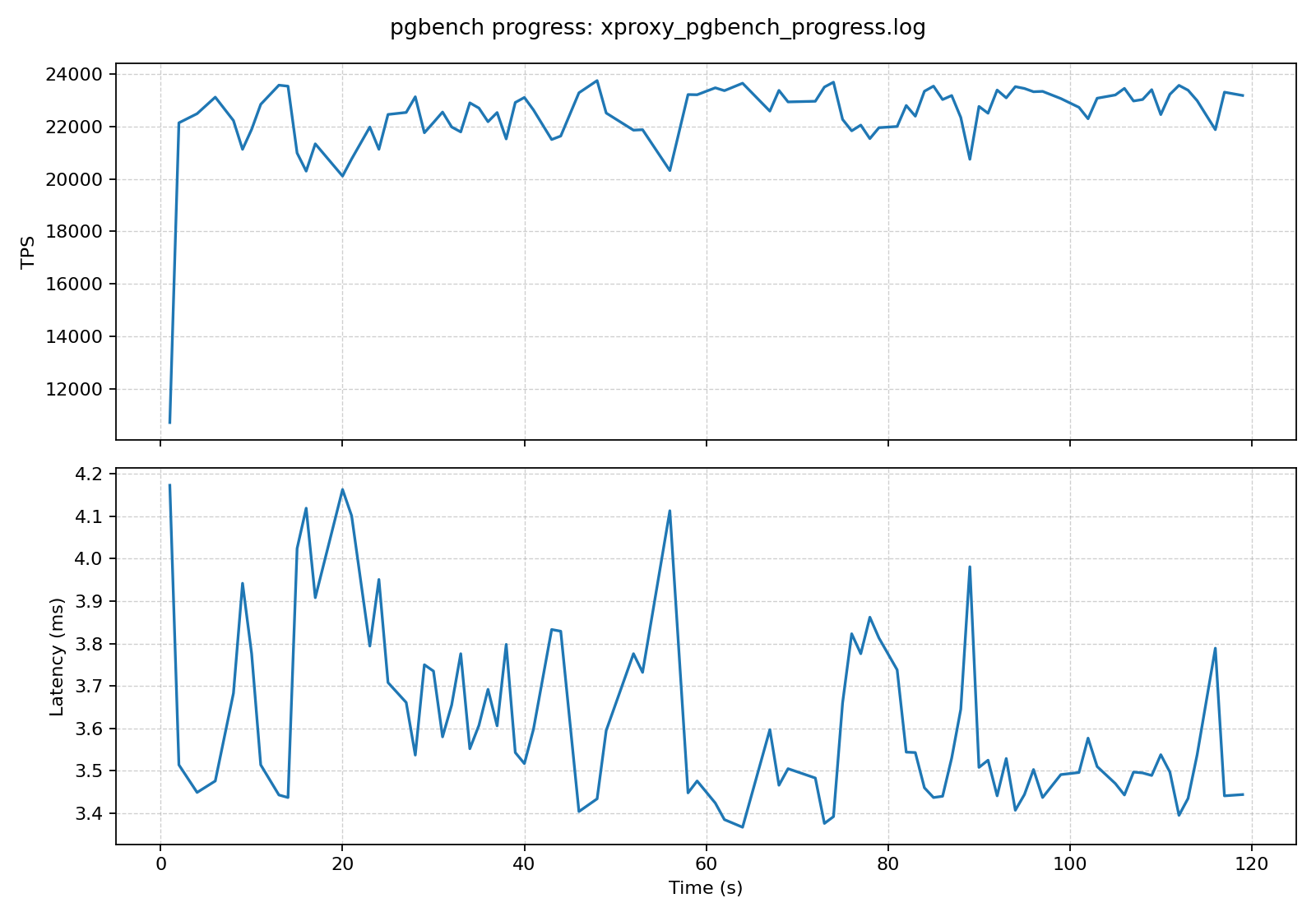
3)变化 B:读写分离对业务代码更"友好"
XProxy 可以同时监听多个端口,例如示例里把:
6001标成Read-write6003标成Read-only
我验证读写落点时,会执行下面这个 SQL(它会直接告诉你当前连到哪个节点、是不是备库):
sql
SELECT inet_server_addr() AS server_ip,
inet_server_port() AS server_port,
pg_is_in_recovery() AS is_standby,
pg_backend_pid() AS backend_pid;以前做读写分离,要么在业务里做路由、要么引入更多中间层。XProxy 这种"多端口 + 节点探测"的方式,让我只需要把连接串切到对应端口,就能把读请求自然落到只读节点上,侵入性小。
二、XStore:原位更新带来的"空间与稳定性"体感
我在原文结语里提到过"稳定压倒一切",这次我专门补了一个更贴近 OLTP 的小实验:用两张结构相同的表做对比,一张是普通 heap,一张用 XStore。
1)创建 XStore 表(操作非常像 PostgreSQL,但关键在 USING)
首先创建扩展:
sql
create extension xstore;然后创建表时指定存储引擎:
sql
Create table ht1(a int primary key, b int);
Create table xt1(a int primary key, b int) using xstore;如果你更喜欢"默认都用 xstore",也可以通过 postgresql.conf 设置:
conf
default_table_access_method = 'xstore'2)索引差异:XStore 默认用 xbtree
XStore 表上如果不指定索引类型,默认会创建 xbtree 索引:
sql
create index xbt_idx1 on xt1(a);也可以显式指定:
sql
create index xbt_idx2 on xt1 using xbtree(a);3)可量化证据:空间占用与表统计
为了把"空间膨胀/稳定性"落到更可验证的细节上,我把持续更新前后的两类指标记录了下来:
1)空间占用(持续更新前后对比)
sql
SELECT relname, pg_total_relation_size(relname) AS total_bytes
FROM (VALUES ('ht1'), ('xt1')) AS t(relname);2)表统计(更新压力下的 dead tuples 等信息)
sql
SELECT relname, n_dead_tup, last_autovacuum
FROM pg_stat_user_tables
WHERE relname IN ('ht1', 'xt1');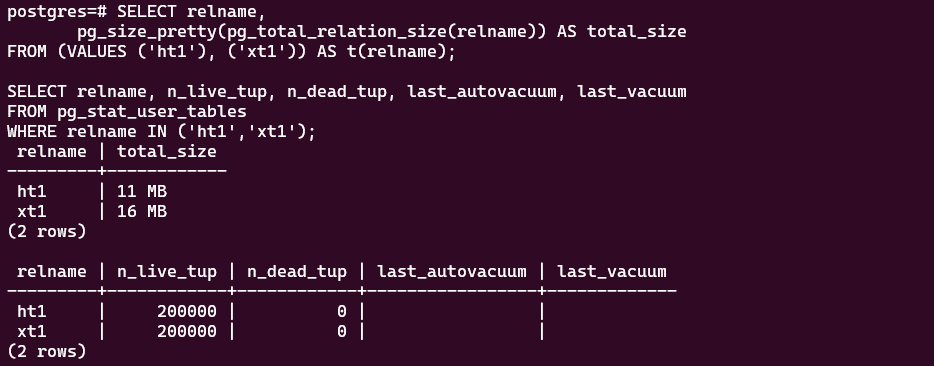

-
同样跑更新,heap 表 ht1 的总占用从 11 MB 涨到 15 MB,而 xt1 基本维持在 16 MB;对我来说,XStore 的价值就是这种跑久了更稳、更不容易膨胀的确定性。"
-
"这轮更新后,ht1 的空间占用明显上浮(11→15 MB),xt1 基本不动(16→16 MB),这种'不怎么长胖'的表现让我对长期跑 OLTP 更踏实。"
最后我的体感可以用一句话概括:
对我来说,XStore 最打动我的不是某一个瞬时峰值,而是跑久了更稳:不用我手动盯着 vacuum,也不会隔一段时间就出现明显抖动,这种稳定性在真实线上更有价值。
结语
经过从源码编译、数据迁移到高并发性能测试的完整流程,我对 OpenTeleDB 有了全面而深刻的认识。它不仅仅是对现有技术的简单沿用,更是针对云计算和企业级痛点进行深度优化的新一代数据库解决方案。
1、远超预期的"丝滑感"
| 阶段 | 个人体验总结 | 关键优势 |
|---|---|---|
| 安装部署 | 难度较易,目标明确。 虽然是源码编译,但文档清晰,按照文档走很容易就能编译,部署过程与基础的数据库安装流程相似。 | 可控性强: 源码编译让开发者能充分启用 XStore、XProxy 等核心组件与优化能力。 |
| 数据迁移 | 极其顺畅。 使用 pgloader 从 MySQL 迁移到 OpenTeleDB,几乎做到了"一次性通过"。这打破了我对跨数据库迁移复杂性的固有认知。 | 兼容性高: OpenTeleDB 对 PostgreSQL 协议的完美兼容性,是迁移成本低的根本保障。 |
| 应用适配 | 改动集中,成本可控。 对于我的 Flask 项目来说,核心改动集中在更换驱动和调整连接串。得益于 ORM (SQLAlchemy) 的强大抽象能力,模型层几乎零改动,业务逻辑层的 SQL 方言差异修正量极小。 | 技术栈保护: 能够最大限度保护现有的 Python/Flask 代码逻辑和 ORM 体系。 |
2、强大的数据库性能
性能测试结果给我带来的震撼是巨大的。OpenTeleDB 在高并发场景下的表现,证明了其架构优化并非空穴来风:
- 高吞吐量写入的福音: Insert 性能提升了 89%。对于物联网、金融交易或日志系统等需要持续、大量写入数据的应用,OpenTeleDB 提供了远超传统数据库的承载能力。
- 连接数的"削峰填谷": 在我把连接入口切到 XProxy 后,最直观的变化是前端并发连接拉高时,后端连接数不再等比例上涨;配合 console 的
show pools/show clients,能清楚看到 client connection 与 server connection 被解耦,压测过程也更可控。 - 稳定压倒一切: 在更新更频繁的 OLTP 场景里,我用两张结构相同的表做对比(heap vs xstore),观察到 heap 表
ht1的总占用从 11 MB → 15 MB ,而 XStore 表xt1基本维持在 16 MB → 16 MB。对我来说,XStore 最打动我的不是某一个瞬时峰值,而是这种"跑久了更稳"的确定性。
3、对独立开发者的建议
如果你正在面临以下任一问题,我强烈建议将 OpenTeleDB 纳入你的技术选型清单:
- 项目开始遇到瓶颈: 你的应用正在经历高并发访问或数据快速增长,但又不想承担传统数据库复杂的运维成本。
- 厌倦了现有数据库的维护: 你希望获得高级功能,但又无法忍受其定期性能抖动和存储空间膨胀带来的运维压力。
- 连接与运维复杂度开始上升: 你希望在不大改业务代码的前提下,把连接池、读写入口、观测手段收拢到统一入口,减少"连接数打满"这类问题带来的不确定性。
如果你更关心"高并发连接 + 运维复杂度",那我建议你优先把 XProxy 跑起来;如果你更关心"长期稳定与空间膨胀",那 XStore 这条线也非常值得深入。
OpenTeleDB 提供了一个高性能、高兼容、且低运维风险的数据库解决方案。它的出现,为我们这些寻求性能突破的开发者,提供了一个极具竞争力的选择。我已决定将我的部分项目迁移到 OpenTeleDB 上,以应对未来的业务增长。