一、算力芯片类型
根据技术架构和应用场景,算力芯片主要分为GPU、FPGA、ASIC三大类,各具技术特点与适用领域:
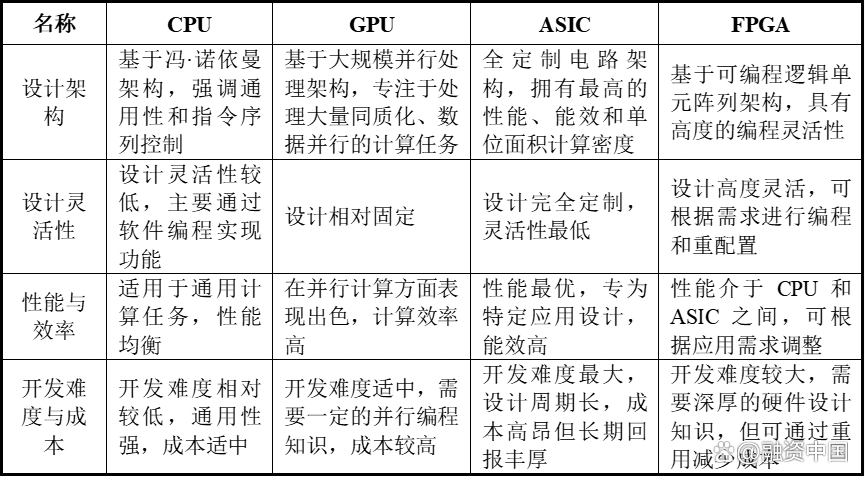
1、GPU(图形处理器)
- 技术特点 :以高并行架构为核心,支持海量数据同时处理;高内存带宽加速数据吞吐;通用性强(如CUDA框架成熟),但功耗较高。
- 应用场景 :
- 消费级:游戏显卡、图形渲染。
- 专业级:AI训练与推理、自动驾驶芯片。
- 代表厂商 :
- 海外:英伟达(主导AI训练市场)、AMD、英特尔、高通、苹果。
- 国内 :海思、海光信息(DCU兼容CUDA生态)、景嘉微、摩尔线程、壁仞科技(BR100芯片FP32算力超1000T)。
2、FPGA(现场可编程逻辑门阵列)
- 技术特点:半定制芯片,通过编程逻辑单元(CLB)实现功能配置;可重构性强(部署后仍可修改硬件逻辑),灵活性高;低延迟、功耗较低。
- 应用场景:物联网、通信基站、边缘计算、工业控制。
- 代表厂商 :
- 海外:赛灵思(AMD收购)、Altera(英特尔收购)、Lattice、Microchip。
- 国内:紫光同创(紫光国微)、复旦微电、安路科技、高云半导体。
3、ASIC(专用集成电路)
- 技术特点 :针对特定应用定制,固化硬件逻辑实现极致性能;专用度高(灵活性差),但高性能与低功耗(无冗余逻辑,能效比高);开发成本高,适合大规模量产。
- 细分类型 :
- TPU(张量处理器) :专为深度学习张量运算设计,适用于AI训练(如谷歌TPU)。
- DPU(数据处理器) :聚焦数据管理,适用于AI训练/推理中的数据搬运与预处理。
- NPU(神经网络处理器) :模拟人类神经元,适用于移动端/边缘实时推理(如华为昇腾NPU)。
- LPU(语言处理单元):专为自然语言处理定制,适用于大语言模型实时推理。
- 代表厂商 :
- 海外 :谷歌(TPU)、博通(ASIC市占率55-60%)、Marvell(Tranium2/AxionCPU)、亚马逊、AWS。
- 国内 :寒武纪**(云边端产品矩阵)** 、云天励飞、平头哥(阿里含光800)、昆仑芯(百度)、黑芝麻、地平线、中昊芯英。
二、主流芯片架构对比
除算力芯片类型外,芯片底层架构(指令集)也影响性能与应用,主流架构包括X86、ARM、RISC-V、MIPS:
- X86架构
- 特点:复杂指令集(CISC),性能强、兼容性好,但功耗较高。
- 应用场景:PC、服务器、高性能计算。
- 代表厂商:英特尔、AMD。
- ARM架构
- 特点:精简指令集(RISC),低功耗、高能效,适合移动设备。
- 应用场景:智能手机、平板电脑、嵌入式系统。
- 代表厂商:苹果、高通、华为海思。
- RISC-V架构
- 特点:开源指令集,模块化设计,灵活性强,成本低。
- 应用场景:物联网、边缘计算、AI加速器。
- 代表厂商:平头哥(阿里)、芯来科技、赛昉科技。
- MIPS架构
- 特点:精简指令集(RISC),高性能但生态较小。
- 应用场景:网络设备、嵌入式系统。
- 代表厂商:Wave Computing、龙芯中科(部分产品)。
三、技术趋势与厂商布局
- GPU主导AI训练市场:英伟达凭借CUDA生态垄断80%以上AI芯片份额,国内海光信息DCU通过兼容CUDA生态降低迁移成本。
- ASIC崛起于推理场景:谷歌TPU、博通ASIC芯片在数据中心推理中表现优异,国内寒武纪、华为昇腾加速布局。
- FPGA适配边缘计算:赛灵思(AMD)、紫光同创在工业控制、通信基站领域持续渗透。
- 架构融合创新:RISC-V架构与ASIC定制化结合,推动低功耗AI芯片发展(如平头哥含光800)。
四、GPU指令集
GPU指令集的设计与功能与传统CPU的指令集存在显著差异,主要服务于图形渲染、并行计算等特定场景。以下是详细分析:
4.1、GPU指令集的核心特点
-
并行化设计
GPU指令集的核心目标是高效管理数千个并行线程(如CUDA核心),通过**单指令多线程(SIMT)**架构实现数据并行处理。例如,英伟达的PTX(Parallel Thread Execution)指令集采用虚拟指令架构,允许编译器将高级代码(如C++)转换为可并行执行的底层指令。
-
图形专用指令
早期GPU指令集(如NVIDIA的CG、AMD的HLSL)包含针对图形渲染的专用指令,例如:
- 纹理采样指令:加速纹理映射与过滤。
- 光栅化指令:将几何图形转换为像素。
- 着色器指令:支持顶点、像素、几何着色器的并行执行。
-
通用计算扩展
随着GPU通用计算(GPGPU)的发展,指令集逐步支持科学计算、AI训练等非图形任务。例如:
- CUDA指令集:英伟达通过CUDA扩展GPU指令集,支持双精度浮点运算、原子操作等。
- ROCm指令集:AMD的开放计算平台,提供类似CUDA的并行计算指令。
4.2、主流GPU厂商的指令集架构
- 英伟达(NVIDIA)
- PTX指令集 :虚拟指令架构,作为编译器中间层,兼容不同GPU硬件(如Turing、Ampere架构)。
- SASS指令集 :实际硬件指令集,直接控制GPU核心(如CUDA核心、Tensor Core)。
- CUDA生态 :通过指令集优化,支持Tensor Core(混合精度计算)和RT Core(光线追踪)。
- AMD
- GCN指令集:图形核心下一代架构,支持统一着色器模型。
- RDNA指令集:改进能效比,优化游戏与计算性能。
- ROCm指令集:开放计算平台,支持HIP(异构计算接口),兼容CUDA代码。
- 英特尔(Intel)
- Gen指令集 :用于集成显卡(如Iris Xe),支持媒体编码、显示输出。
- oneAPI指令集:跨架构编程模型,统一CPU、GPU、FPGA指令。
- 苹果(Apple)
- Metal指令集:专为Mac/iOS设计,优化图形渲染与Metal Performance Shaders(MPS)计算。
- AGX指令集:用于自研芯片(如M1/M2),集成GPU与神经引擎指令。
4.3、GPU指令集与CPU指令集的对比
| 特性 | GPU指令集 | CPU指令集(如x86、ARM) |
|---|---|---|
| 设计目标 | 并行计算、图形渲染 | 顺序执行、通用计算 |
| 线程管理 | 支持数千线程并行(SIMT) | 通常支持少量线程(SMT) |
| 指令类型 | 图形专用指令、并行计算指令 | 算术逻辑、分支跳转、系统调用 |
| 能效比 | 高并行性提升吞吐量,但单线程效率低 | 低并行性但单线程效率高 |
| 典型应用 | AI训练、游戏渲染、科学计算 | 操作系统、应用程序、通用计算 |
4.4、GPU指令集的技术演进
-
从固定功能到可编程
早期GPU指令集固定(如固定管线着色器),现代GPU通过可编程着色器(如Vertex/Pixel Shader)和通用计算指令(如CUDA)实现灵活性。
-
专用指令加速
针对AI训练,GPU引入Tensor Core指令(如英伟达的WMMA指令),支持混合精度矩阵运算,性能比传统CUDA核心提升数倍。
-
开放生态竞争
AMD通过ROCm指令集兼容CUDA生态,降低开发者迁移成本;英特尔通过oneAPI实现跨架构指令统一。
4.5、实例分析:英伟达GPU指令集
-
PTX到SASS的编译流程 :
开发者编写CUDA代码 → 编译器生成PTX虚拟指令 → 驱动将PTX转换为具体GPU硬件的SASS指令 → 执行于CUDA核心或Tensor Core。 -
指令集优化案例 :
在AI推理中,PTX指令集可通过半精度浮点(FP16)指令 和Tensor Core指令加速矩阵乘法,比CPU指令集(如AVX-512)效率高数十倍。