说到微服务改造,估计很多同学都有这样的困惑:手头这个跑了好几年的老系统,虽然毛病不少,但好歹还能用,要不要冒险改成微服务?改了会不会更麻烦?
微服务这个概念其实并不新鲜,它的出现主要是为了解决单体应用的维护难题。想象一下,一个系统几百万行代码,十几个团队在上面开发,每次发版都要协调半天,出个问题半天找不到根源在哪里,这种情况确实让人头疼。
微服务就是把这个"大怪物"拆成一堆小服务,每个服务管好自己的一亩三分地,互不干扰。听起来简单,实际操作起来需要不少技巧。
今天就用一个房地产公司的真实改造案例,来聊聊这个从单体到微服务的"变形记"。
1. 为什么要进行微服务改造
1.1 老系统的那些糟心事
接触过这么多公司的老系统,发现问题都差不多:
• 代码堆成山 :几年下来代码越写越多,里面一堆没用的垃圾代码,删都不敢删
• 改一处动全身 :想改个小功能,结果发现牵扯到七八个模块,改完这个那个又坏了
• 发版如临大敌 :每次部署都要全公司待命,测试要测一周,上线还要半夜操作
• 扛不住大流量 :一到促销活动系统就卡死,想单独给某个功能加机器都做不到
• 维护成本爆炸:出个问题要好几个人一起查,新人上手要培训好几个月
老系统确实有不少让人头疼的地方:
• 改个功能复杂 :想加个小功能,结果发现要改十几个文件,还得担心影响其他模块
• 发版风险高 :每次上线都要全量发布,一个小bug就得整个系统回滚
• 扩容困难 :用户量上来了,只能整个系统一起扩,浪费资源
• 团队协作效率低:A团队改完了,B团队还在测试,大家都得等着一起发版
1.2 微服务的好处在哪里
把大系统拆成小服务,好处还真不少:
• 各自为政 :每个服务自己管自己,开发测试部署都不用等别人
• 技术自由 :用户服务用Java,搜索服务用Go,支付服务用Python,各取所需
• 故障不传染 :一个服务挂了不影响其他服务,至少用户还能正常浏览
• 小团队作战 :3-5个人负责一个服务,沟通成本低,效率高
• 想扩就扩:哪个服务压力大就给哪个加机器,不用整个系统一起扩容
2. 改造策略:怎么下手不踩坑
踩过这么多坑,总结出几个关键策略:
2.1 先搞清楚改什么
别贪心,挑软柿子捏
改造可不是推倒重来,得有策略:
• 先拿边缘业务练手,别一上来就动核心功能
• 优先改那些天天要改需求的模块,改完立马见效
• 选择边界清晰的业务,别选那种和其他模块纠缠不清的
团队分工要明确
• 专门组个改造小组,别让人家兼职搞,那样永远搞不完
• 谁负责拆分、谁负责测试、谁负责部署,分工明确
• 定个时间表,不然这事能拖到天荒地老
2.2 功能逐步剥离
服务拆分原则
在拆分服务时,我们遵循以下原则:
• 业务导向 :按照业务边界进行拆分,而不是技术边界
• 数据独立 :每个服务拥有独立的数据存储
• 接口清晰 :服务间通过明确的API进行通信
• 渐进式拆分:先拆分边缘服务,再逐步向核心业务扩展
代理机制实现
在改造过程中,代理机制是实现新旧系统平滑过渡的关键技术。通过在原有系统前增加一层代理服务,我们可以根据业务规则将请求智能路由到新服务或旧系统,实现渐进式的功能迁移。
如上图所示,代理层作为流量分发的核心,可以根据预设的策略(如用户ID、时间窗口、功能开关等)决定请求的路由方向。这种方式的优势在于:
• 风险可控 :可以从小比例流量开始,逐步扩大新服务的覆盖范围
• 快速回滚 :一旦发现问题,可以立即将流量切回旧系统
• 数据对比:可以同时调用新旧系统,对比结果验证新服务的正确性
java
@RestController
@RequestMapping("/api")
public class ProxyController {
@Autowired
private LegacySystemService legacyService;
@Autowired
private NewMicroService newService;
@GetMapping("/users/{id}")
public ResponseEntity<User> getUser(@PathVariable Long id) {
// 根据配置决定调用新服务还是旧系统
if (shouldUseNewService(id)) {
return newService.getUser(id);
} else {
return legacyService.getUser(id);
}
}
private boolean shouldUseNewService(Long id) {
// 灰度发布逻辑,可以基于用户ID、时间等条件
return id % 10 < 3; // 30%的流量切换到新服务
}
}2.3 数据解耦策略
数据库拆分
数据解耦是微服务改造的关键环节:
• 垂直拆分 :按业务领域拆分数据库
• 水平拆分 :按数据量进行分片
• 读写分离:提高数据访问性能
java
@Service
public class UserDataMigrationService {
@Autowired
private LegacyUserRepository legacyRepo;
@Autowired
private NewUserRepository newRepo;
@Transactional
public void migrateUserData(Long userId) {
try {
// 从旧系统读取数据
LegacyUser legacyUser = legacyRepo.findById(userId);
// 数据转换
User newUser = convertToNewFormat(legacyUser);
// 写入新系统
newRepo.save(newUser);
// 记录迁移日志
logMigration(userId, "SUCCESS");
} catch (Exception e) {
logMigration(userId, "FAILED: " + e.getMessage());
throw new DataMigrationException("用户数据迁移失败", e);
}
}
private User convertToNewFormat(LegacyUser legacyUser) {
return User.builder()
.id(legacyUser.getId())
.name(legacyUser.getName())
.email(legacyUser.getEmail())
.createdAt(legacyUser.getCreateTime())
.build();
}
}2.4 数据同步机制
在改造过程中,需要保证新旧系统的数据一致性:
java
@Component
public class DataSyncService {
@EventListener
public void handleUserUpdate(UserUpdateEvent event) {
// 异步同步数据到旧系统
CompletableFuture.runAsync(() -> {
try {
syncToLegacySystem(event.getUser());
} catch (Exception e) {
// 记录同步失败,后续重试
recordSyncFailure(event.getUser().getId(), e);
}
});
}
private void syncToLegacySystem(User user) {
// 将新系统的数据同步回旧系统
LegacyUser legacyUser = convertToLegacyFormat(user);
legacyUserRepository.save(legacyUser);
}
}3. 房地产CRM系统改造实战
3.1 房地产行业的痛点
房地产这个行业有个特点,就是开盘那几天人山人海,过了这阵子就门可罗雀。这种"过山车"式的流量模式确实很考验系统,为了应付那几天的高峰,平时得养着一大堆服务器,成本压力不小。
更关键的是,现在客户都习惯了线上操作,不愿意跑售楼处,都想在网上看房选房。传统的IT系统很难承受这种突发流量冲击,一搞活动就容易卡顿,客户体验很差。
3.2 这个老系统有多惨
我们接手的这个CRM系统,就是个典型的"老古董"------传统的三层架构,MySQL数据库,跑在几台老服务器上,性能表现不佳。
最大的问题是,每次搞活动都要临时采购一批服务器,活动结束后这些机器就闲置了,资源浪费严重,成本控制困难。运维团队压力也很大,需要时刻监控这些老旧设备,担心随时可能出现故障。
3.3 看看这些吓人的数据
我们花了不少时间摸底,发现这个系统的问题确实严重:
• 代码规模庞大 :100万行代码,测试覆盖率仅10%,完整测试需要一个月
• 准备周期长 :活动准备需要提前一个月采购和配置机器
• 上线周期慢 :新功能上线需要半年时间,响应速度跟不上业务需求
• 技术栈复杂 :上百种业务逻辑,2-3种开发语言混合使用
• 人员配置多:运维团队20多人,工作负荷仍然很重
这些数据背后的问题,相信很多团队都遇到过:
代码质量堪忧:几年积累下来,代码中存在大量冗余内容,不敢轻易删除,担心影响其他功能。测试覆盖率偏低,问题排查困难。
资源利用率低:每次活动都要采购新设备,部署测试,准备周期长,活动结束后设备闲置,成本浪费严重。
开发效率不高:修改功能需要多个团队协作,沟通成本高,开发周期长。
运维成本高:20多人的运维团队,工作量仍然饱和,问题处理需要多人协调,效率有待提升。
3.4 怎么改造这个老系统
拆分思路
既然这个大系统维护困难,那就按照业务功能将其拆分成几个独立的小服务:
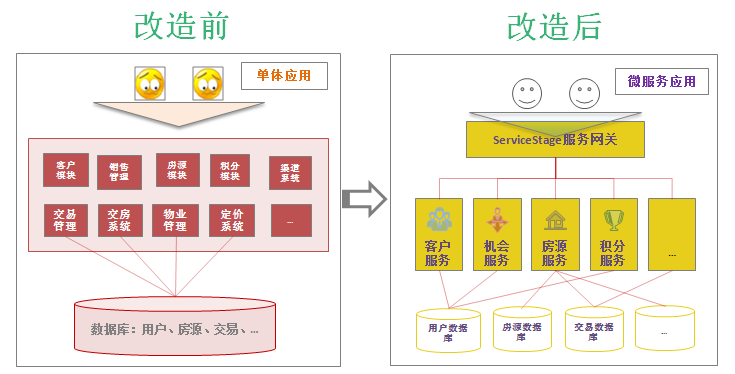
从架构图可以看出,我们把这个大系统拆分成了几个专业化的服务:
• 服务网关 :统一入口,负责请求路由、负载均衡和安全检查
• 客户服务 :专门管理客户信息,包括客户档案、购房记录等
• 房源服务 :管理房源信息,提供搜索、推荐等功能
• 机会服务 :跟踪销售线索,管理客户意向和跟进状态
• 积分服务:处理营销活动、积分兑换,提升客户粘性
改造步骤
按照前面的策略,我们采用了以下步骤:
划分边界:将原来的大系统按业务功能进行拆分,每个服务负责独立的业务领域。
逐步剥离:采用渐进式改造,一个模块一个模块地从老系统中拆分出来,先拆网关,再拆客户服务,循序渐进。
数据拆分:为每个服务分配独立的数据库,不再共享一个大数据库,避免数据耦合。
保持同步:新老系统并行运行期间,确保数据同步,保证系统稳定性。
技术选型
技术选型方面,我们选择了以下成熟的技术栈:
• 微服务框架 :ServiceComb Java Chassis(华为开源框架,稳定性好)
• 服务注册发现 :ServiceComb Service Center(实现服务间的自动发现)
• 配置管理 :Spring Cloud Config(集中管理配置文件)
• 负载均衡 :Ribbon(智能请求分发,避免单点过载)
• 熔断器 :Hystrix(故障隔离,防止级联失败)
• API网关 :ServiceComb Edge Service(统一入口管理)
• 数据库 :MySQL + Redis(主存储 + 缓存优化)
• 消息队列 :RabbitMQ(异步处理,流量削峰)
• 容器化 :Docker + Kubernetes(容器化部署,自动扩缩容)
• 云平台:华为ServiceStage(一站式微服务管理平台)
改造过程中,我们利用ServiceComb实现了流量切换,逐步将请求从老系统迁移到新服务上,确保平滑过渡。
微服务搭建流程
微服务的搭建其实并不复杂,使用ServiceComb框架,只需要4个步骤:
- 添加依赖:引入ServiceComb相关的jar包
- 定义接口:明确服务对外提供的功能
- 配置文件:设置服务启动参数
- 添加注解:在启动类上添加相应标记
结合Docker插件,可以快速将服务打包成镜像,实现跨环境部署。
配合ServiceStage平台,微服务治理、监控、扩容等运维工作都可以自动化处理,大大降低了运维复杂度。
3.5 具体实施过程
第一阶段:基础设施准备
yaml
# docker-compose.yml
version: '3.8'
services:
eureka-server:
image: eureka-server:latest
ports:
- "8761:8761"
environment:
- SPRING_PROFILES_ACTIVE=docker
config-server:
image: config-server:latest
ports:
- "8888:8888"
depends_on:
- eureka-server
api-gateway:
image: api-gateway:latest
ports:
- "8080:8080"
depends_on:
- eureka-server
- config-server第二阶段:用户服务拆分
java
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/{id}")
public ResponseEntity<UserDTO> getUser(@PathVariable Long id) {
try {
UserDTO user = userService.getUserById(id);
return ResponseEntity.ok(user);
} catch (UserNotFoundException e) {
return ResponseEntity.notFound().build();
}
}
@PostMapping
public ResponseEntity<UserDTO> createUser(@RequestBody @Valid CreateUserRequest request) {
UserDTO user = userService.createUser(request);
return ResponseEntity.status(HttpStatus.CREATED).body(user);
}
@PutMapping("/{id}")
public ResponseEntity<UserDTO> updateUser(
@PathVariable Long id,
@RequestBody @Valid UpdateUserRequest request) {
UserDTO user = userService.updateUser(id, request);
return ResponseEntity.ok(user);
}
}第三阶段:数据迁移
java
@Service
public class UserMigrationService {
private static final int BATCH_SIZE = 1000;
@Autowired
private LegacyUserRepository legacyRepo;
@Autowired
private UserRepository userRepo;
@Scheduled(fixedDelay = 60000) // 每分钟执行一次
public void migrateUsers() {
List<LegacyUser> legacyUsers = legacyRepo.findUnmigratedUsers(BATCH_SIZE);
for (LegacyUser legacyUser : legacyUsers) {
try {
migrateUser(legacyUser);
legacyRepo.markAsMigrated(legacyUser.getId());
} catch (Exception e) {
log.error("用户迁移失败: {}", legacyUser.getId(), e);
legacyRepo.markMigrationFailed(legacyUser.getId(), e.getMessage());
}
}
}
private void migrateUser(LegacyUser legacyUser) {
User user = User.builder()
.id(legacyUser.getId())
.username(legacyUser.getUsername())
.email(legacyUser.getEmail())
.phone(legacyUser.getPhone())
.status(UserStatus.valueOf(legacyUser.getStatus()))
.createdAt(legacyUser.getCreateTime())
.updatedAt(legacyUser.getUpdateTime())
.build();
userRepo.save(user);
}
}第四阶段:灰度发布
java
@Component
public class GrayReleaseFilter implements Filter {
@Value("${gray.release.percentage:10}")
private int grayPercentage;
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
String userId = httpRequest.getHeader("User-Id");
if (shouldUseNewService(userId)) {
httpRequest.setAttribute("use-new-service", true);
}
chain.doFilter(request, response);
}
private boolean shouldUseNewService(String userId) {
if (userId == null) {
return false;
}
// 基于用户ID的哈希值决定是否使用新服务
int hash = Math.abs(userId.hashCode());
return (hash % 100) < grayPercentage;
}
}3.6 改造效果评估
以前为了应对开盘高峰期,需要提前一个月采购机器、部署环境、进行各种测试,人力物力消耗巨大,机器利用率也很低。
现在采用ServiceStage的容器技术,系统可以根据访问量自动扩缩容,实现秒级响应,有效应对突发流量冲击。
改造成果总结:
• 运维团队精简 :从20多人优化到4人,运维效率显著提升
• 资源利用率提升 :服务器成本节省50%
• 监控能力增强 :每秒可分析上万次调用,问题定位更精准
• 迁移平滑 :老系统无缝迁移,用户体验无影响
• 业务创新加速:新功能从设计到上线,周期大幅缩短
理论上,经过不断地迭代,逐渐完成业务功能解耦,新服务构建,遗留系统最终会被完全替换掉。
4. 改造要点与关键实践
在改造的整个过程中,我们总结出以下几个关键要点:
4.1 基础设施必须自动化
以前在数据中心部署服务,流程复杂,需要层层审批,效率很低。现在我们用自动化工具替代了这些繁琐流程。通过华为ServiceStage平台,团队可以自主管理资源,按需创建和销毁,大大提高了灵活性。
随着微服务数量增加,如果没有自动化,仅部署工作就会消耗大量人力。有了自动化工具,我们节省了大量时间。公司还专门成立了小组研究ServiceStage和DevOps工具,提升团队使用效率。
目前市面上有很多优秀的云平台,都能有效解决基础设施自动化问题。
CI/CD流水线
搭建了一套自动化发布流水线,实现从代码提交到上线的全程自动化:
• 持续集成 :代码提交后自动编译测试,及时发现问题
• 持续部署 :测试通过后自动发布,无需人工干预
• 一键回滚:出现问题时可快速回退到上个版本,降低风险
yaml
# .gitlab-ci.yml
stages:
- test
- build
- deploy
test:
stage: test
script:
- mvn clean test
- mvn sonar:sonar
coverage: '/Total.*?([0-9]{1,3})%/'
build:
stage: build
script:
- mvn clean package
- docker build -t $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA .
- docker push $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA
only:
- master
deploy:
stage: deploy
script:
- kubectl set image deployment/user-service user-service=$CI_REGISTRY_IMAGE:$CI_COMMIT_SHA
- kubectl rollout status deployment/user-service
only:
- master监控告警体系
微服务数量增多后,完善的监控体系变得至关重要:
• 全链路追踪 :清晰展示请求经过的服务路径、耗时分布和性能瓶颈
• 业务监控 :实时监控订单量、用户数等关键业务指标,及时发现异常
• 基础监控 :监控服务器CPU、内存、数据库连接数等基础设施指标
• 智能告警:利用机器学习减少误报,避免因正常流量波动产生无效告警
java
@Component
public class ServiceHealthMonitor {
private final MeterRegistry meterRegistry;
private final Counter requestCounter;
private final Timer responseTimer;
public ServiceHealthMonitor(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
this.requestCounter = Counter.builder("service.requests.total")
.description("Total number of requests")
.register(meterRegistry);
this.responseTimer = Timer.builder("service.response.time")
.description("Response time")
.register(meterRegistry);
}
@EventListener
public void handleRequest(RequestEvent event) {
requestCounter.increment(
Tags.of(
"service", event.getServiceName(),
"method", event.getMethod(),
"status", String.valueOf(event.getStatus())
)
);
responseTimer.record(event.getDuration(), TimeUnit.MILLISECONDS);
}
}4.2 微服务生态系统
微服务的生态系统是指微服务实施过程相关的协作部分,涉及部分较多,譬如测试机制、持续集成、自动化部署、细粒度监控、日志聚合、告警、持续交付,以及大家非常关注的服务注册、服务发现机制等。
这部分的灵活性比较大,因为目前如上说的每一个领域都有很多优秀的工具。譬如日志聚合目前业界的方案通常为ELK,监控的方案如Zabbix、NewRelic、CloudWatch等,成熟的监控工具都具有告警功能,PagerDuty也提供更专业的告警服务。服务注册和发现有ServiceComb框架的Service Center,Eureka,Consul,Zookeeper。大家可以在各自的团队中自由发挥。
4.3 开发框架的演进
开发框架是团队在构建微服务的过程中,不断总结,梳理出的快速开发微服务的相关工具和框架。
我们基于ServiceComb构建了快速开发框架,主要包括四部分,如下图所示:
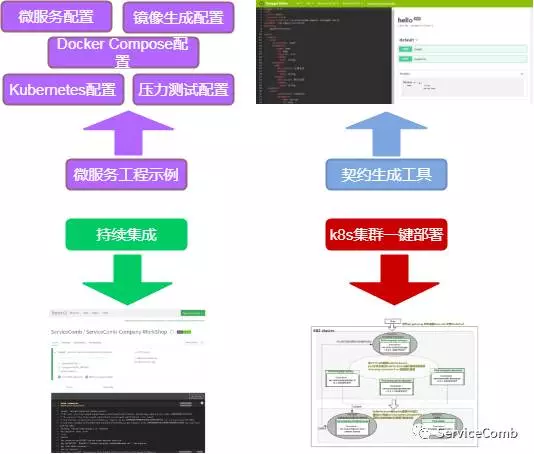
1. 微服务工程示例
提供微服务改造架构最佳实践参考工程Company,使能微服务改造或开发能复用其架构设计和配置,同时指导实现服务容器化和后续服务性能测试等提高服务可靠性。
2. 契约生成工具
ServiceComb采用了基于OpenAPI的服务契约,使业务逻辑与编程语言解耦,并可使用Swagger工具定义服务契约,自动生成契约对应的代码和文档。
3. 持续集成
持续集成使用了Jenkins,通过其配置文件定义主要的阶段:
• 验证 :运行单元测试,集成测试
• 构建 :构建可执行的jar部署包
• 部署:基于指定版本制作镜像,并推送到测试或生产环境下
利用这样的持续集成模板工程,花费很少的时间,就可以针对新建的微服务应用,快速配置其对应的持续集成环境。
4. Kubernetes集群一键部署
Kubernetes是谷歌开源的一个容器集群管理工具。基于Kubernetes,可实现微服务的快速部署及弹性伸缩。我们提供了一键部署脚本,部署时只需稍作修改即可通过一条命令,自动完成资源的创建、部署、弹性伸缩、金丝雀发布等。
4.4 团队运维自管理
这一部分涉及团队的文化管理,是对DevOPS理念的延伸,我们称为TMI(Team Managed Infrastructure)。
目标是将分析、开发、测试以及资源创建、销毁、自动化部署的权限下放给团队,由团队按需完成部署(结合看板流程管理,而非Scrum的固定迭代,可以实现一天多次部署)。
这个环节高度依赖成熟的监控和告警机制,当出现问题时,能够有效通知到责任人,实现快速反馈和修复。团队内部会定期轮换Pager(负责问题处理的人员),培养团队以服务可用性为共同目标,建立产品思维而非项目思维。
4.5 数据一致性保障
分布式事务处理
java
@Service
public class OrderService {
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
@Autowired
private SagaManager sagaManager;
public void createOrder(CreateOrderRequest request) {
SagaTransaction saga = sagaManager.begin("create-order")
.addStep("reserve-inventory",
() -> inventoryService.reserve(request.getProductId(), request.getQuantity()),
() -> inventoryService.release(request.getProductId(), request.getQuantity()))
.addStep("process-payment",
() -> paymentService.charge(request.getPaymentInfo()),
() -> paymentService.refund(request.getPaymentInfo()))
.addStep("create-order",
() -> createOrderRecord(request),
() -> cancelOrderRecord(request.getOrderId()));
saga.execute();
}
}4.6 服务治理
熔断降级
java
@Service
public class UserService {
@HystrixCommand(
fallbackMethod = "getUserFromCache",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50")
}
)
public User getUserById(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new UserNotFoundException("用户不存在: " + id));
}
public User getUserFromCache(Long id) {
// 从缓存获取用户信息
User cachedUser = redisTemplate.opsForValue().get("user:" + id);
if (cachedUser != null) {
return cachedUser;
}
// 返回默认用户信息
return User.builder()
.id(id)
.username("临时用户")
.status(UserStatus.INACTIVE)
.build();
}
}5. 总结
微服务改造是一个复杂的系统工程,涉及技术、管理、团队文化等多个层面。但只要规划得当,循序渐进,完善监控,持续优化,遗留系统完全可以重获新生。
这次改造取得了良好效果,不仅解决了技术债务问题,还显著提升了开发效率和系统稳定性。虽然过程中遇到了不少挑战,但最终都得到了妥善解决。