定制request
传递URL
有params = param_data , 这个就是传入一些,用户密码之类的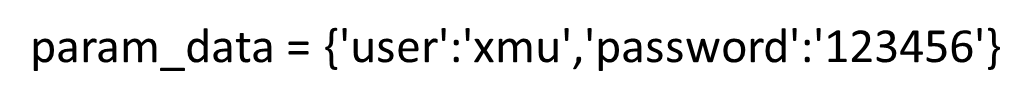
定制请求头
无法访问时候,就是页面禁止爬取,此时要定制Headers
获取方法 :
进入网页-->点鸡network 选项卡-->刷新-->找到Doc-->点鸡name 下方的网址-->
然后复制User-Agent (Hoysst)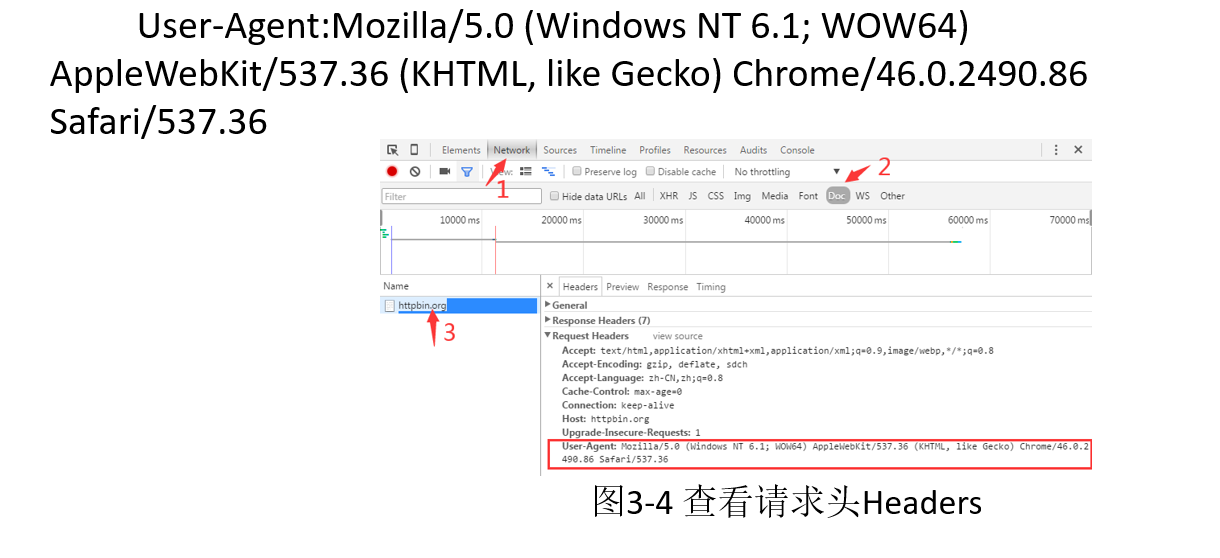

先写base_url 然后加入headers 参数是headers = headers ,一样是写成字典的形式
网络超时
为request的 timeout参数设置等待描述,如果服务器在指定时间之内没有应答就返回异常

解析网页
BeautifulSoup 简介
bs用来解析网页,支持CSS 选择器,Python 标准库中的HTML 解析器
from bs4 import BeautifulSoup
soup = BeautifulSoup("<html>A Html Text</html>","html.parasr")
两个参数:第一个是文本,第二个是解释器
soup.prettify() 格式化输出BeautifulSoup 四大对象
BeautifulSoup 将HTML 文档转换成一个复杂的树形结构,每个节点都是一个Pyhton 对象
它们分别是:tag, NavigableString, BeautifulSoup, Comment
Tag:

有两个属性: name 和attrs
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>
tag.name
# 'b'
tag['class']
# 'boldest'
tag.attrs
# {'class': 'boldest'}
type(tag.attrs)
# <class 'dict'>NavigableString
bs 用NavigableString 来包装夹在tag 中间的的字符串。
但是字符串中间不能包含其他的tag
soup = BeatutifulSoup('<b class="boldest">Extremely bold</b>')
s = soup.b.string
print(s) # Extremely bold
print(type(s)) # <class 'bs4.element.NavigableString'>
这个 s 就是一个 NavigableString 对象BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象。但是 BeautifulSoup 对象并不是真正的 HTM L或 XML 的 tag,它没有attribute属性,name 属性是一个值为"document"的特殊属性。
Comment
一般表示 文档的注释部分
soup = BeautifulSoup("<b><!--This is a comment--></b>")
comment = soup.b.string
print(comment) # This is a comment
print(type(comment)) # <class 'bs4.element.Comment'>