引言:

在日常后端开发中,Redis 凭借其高性能与多样的数据结构,几乎成为系统缓存和分布式架构中的标配。然而,随着业务数据量的持续增长与系统高可用需求的提升,单机版 Redis 的性能瓶颈与单点故障问题逐渐显现。为了解决这些问题,Redis 官方推出了 Redis Cluster(集群模式) ------ 一种支持自动分片与高可用的分布式部署方案。
本文将通过通俗易懂的讲解与实际示例,带你深入理解 Redis Cluster 的工作原理:它是如何将数据分布到不同节点的?客户端又是如何知道该访问哪个节点?当节点出现故障时,Redis Cluster 又如何自动完成故障转移?无论你是刚接触 Redis 的初学者,还是希望系统化掌握分布式缓存机制的后端开发者,相信这篇文章都能帮你彻底搞懂 Redis Cluster 的核心机制。
一、为什么需要 Redis Cluster?
在单机模式下,Redis 性能非常高,但存在以下瓶颈:
-
内存容量限制:单机 Redis 受限于服务器内存,无法存储更大数据量。
-
性能瓶颈:所有请求都集中在一个实例上,吞吐量受限。
-
单点故障风险:主节点宕机会导致服务不可用。
-
扩展性差:水平扩展困难。
Redis Cluster(集群模式) 的目标就是:
-
自动分片(sharding):把数据自动分散到多个节点上。
-
高可用(HA):部分节点宕机时仍可继续提供服务。
-
无中心架构:没有"中心节点",所有节点平等,去中心化管理。
二、Redis Cluster 的基本结构
Redis Cluster 通常由多个节点组成,每个节点可能是:
-
主节点(Master):存放实际数据。
-
从节点(Slave):主节点的备份,用于容灾和高可用。
例如,一个典型的 6 节点集群:
3 个主节点(M1, M2, M3)
3 个从节点(S1, S2, S3)S1 是 M1 的从节点,S2 是 M2 的从节点,S3 是 M3 的从节点。
三、数据分片机制(slot 槽)
Redis Cluster 把整个数据空间划分为 16384 个槽(hash slots)。
-
每个主节点负责管理一部分槽(比如 M1 管理 0~5460,M2 管理 5461~10922,M3 管理 10923~16383)。
-
每条数据(key)通过以下算法映射到具体槽位:
slot = CRC16(key) mod 16384
这样就能知道某个 key 应该放在哪个节点上。
四、Redis Cluster 的工作流程(核心原理)
示例场景:一个三主三从的 Redis Cluster
假设我们有一个 6 节点的 Redis 集群:
| 节点角色 | IP 地址 | 负责的哈希槽范围 |
|---|---|---|
| 主节点 M1 | 192.168.1.10:6379 | 0 ~ 5460 |
| 主节点 M2 | 192.168.1.11:6379 | 5461 ~ 10922 |
| 主节点 M3 | 192.168.1.12:6379 | 10923 ~ 16383 |
| 从节点 S1 | 192.168.1.13:6379 | M1 的从节点 |
| 从节点 S2 | 192.168.1.14:6379 | M2 的从节点 |
| 从节点 S3 | 192.168.1.15:6379 | M3 的从节点 |
Step 1:客户端启动并连接集群
Java 程序中创建 JedisCluster(或 LettuceClusterClient)对象,连接任意节点即可:
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.1.10", 6379)); // 随便一个节点即可
JedisCluster cluster = new JedisCluster(nodes);客户端会在启动时:
-
连接到任意节点(比如 M1);
-
发送命令
CLUSTER SLOTS; -
获取整个集群的槽分配表(slot map):
[ [0,5460, "192.168.1.10",6379], [5461,10922, "192.168.1.11",6379], [10923,16383, "192.168.1.12",6379] ] -
客户端缓存该表,用于后续路由。
Step 2:客户端写入数据(SET 命令)
客户端执行:
SET user:1001 "Tom"流程如下:
-
客户端计算槽号:
slot = CRC16("user:1001") % 16384 = 7000 -
查 slot 表,发现槽 7000 在范围
5461~10922→ 属于节点 M2。 -
客户端直接向
192.168.1.11:6379(M2) 发送命令:SET user:1001 "Tom" -
M2 存储键值对
{user:1001 -> Tom}并返回 OK。 -
M2 自动将数据同步到它的从节点 S2(主从复制)。
结果:
-
M2 存有数据;
-
S2 有一份副本;
-
其他节点无此数据。
Step 3:客户端读取数据(GET 命令)
执行:
GET user:1001-
客户端再次计算 slot = 7000;
-
发现 M2 负责;
-
直接向 M2 发送
GET; -
M2 返回
"Tom"。
正常返回结果,无需中转或重定向。
Step 4:如果客户端访问了错误的节点
假设客户端因为缓存的 slot 表过期,错误地向 M1 发请求:
GET user:1001M1 检查发现:
-
key 的 slot(7000)不在自己负责范围(0~5460)。
-
于是返回重定向响应:
MOVED 7000 192.168.1.11:6379
客户端收到后:
-
更新 slot 表;
-
下次请求直接发往 M2。
这就是 Redis Cluster 的自动路由机制。
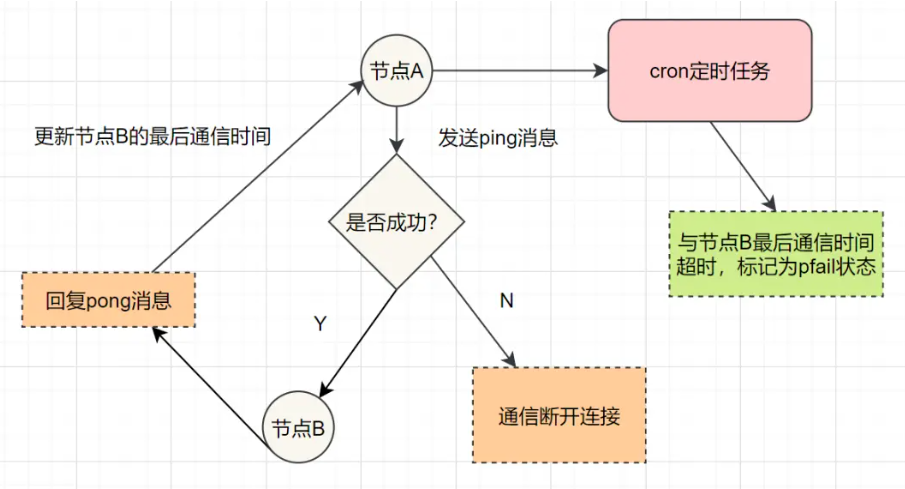
Step 5:集群节点之间的通信
每个节点之间通过 Gossip 协议 定期交换状态消息(默认每秒 10 次):
-
M1 向 M2、M3 发送
PING; -
M2 回复
PONG; -
这些消息包含节点状态、槽分配、故障信息等。
目的:
-
确保节点间状态同步;
-
检测故障;
-
传播集群配置变化。
Step 6:节点出现故障
假设主节点 M2 宕机。
-
其他节点检测到 M2 无响应,发出
PFAIL标记; -
多个节点达成共识 → 将其标记为
FAIL; -
其从节点 S2 发起选举,成为新的主节点;
-
集群广播消息更新:
槽 5461~10922 现在由 192.168.1.14:6379 负责 -
客户端收到 MOVED 信息后更新路由:
MOVED 7000 192.168.1.14:6379 -
客户端重新向 S2(新主)发送请求,服务恢复。
Redis Cluster 实现了自动故障转移,无需人工干预。
Step 7:节点恢复后重新加入
当 M2 修复重启后:
-
发送命令:
CLUSTER MEET 192.168.1.14 6379 -
加入集群;
-
被设置为 S2 的从节点;
-
开始同步数据;
-
集群恢复到原有结构。
流程总结图(文字描述版)
客户端 → 连接任意节点
↓
获取槽分配信息(16384个slot)
↓
根据 key 算 slot → 定位主节点
↓
向对应节点发送命令(SET/GET等)
↓
若访问错误 → MOVED/ASK 重定向
↓
节点间Gossip通信保持一致
↓
故障自动检测 + 从节点选举接管总结
| 阶段 | 动作 | 说明 |
|---|---|---|
| 启动阶段 | 客户端获取 slot 分布表 | 从任意节点获取 |
| 写入阶段 | 客户端计算槽并路由 | CRC16(key) % 16384 |
| 访问错误 | 节点返回 MOVED 或 ASK | 客户端更新路由表 |
| 节点通信 | Gossip 协议 | 保持节点状态一致 |
| 故障恢复 | 自动主从切换 | 无需人工干预 |
五、节点之间如何通信?
Redis Cluster 的节点之间使用 Gossip 协议 通信。


每个节点周期性地向其他节点发送消息,类型包括:
| 消息类型 | 作用 |
|---|---|
PING |
探测节点是否在线 |
PONG |
对 PING 的响应 |
MEET |
新节点加入集群 |
FAIL |
节点被判定为失败 |
PUBLISH |
集群广播消息(可用于 pub/sub) |
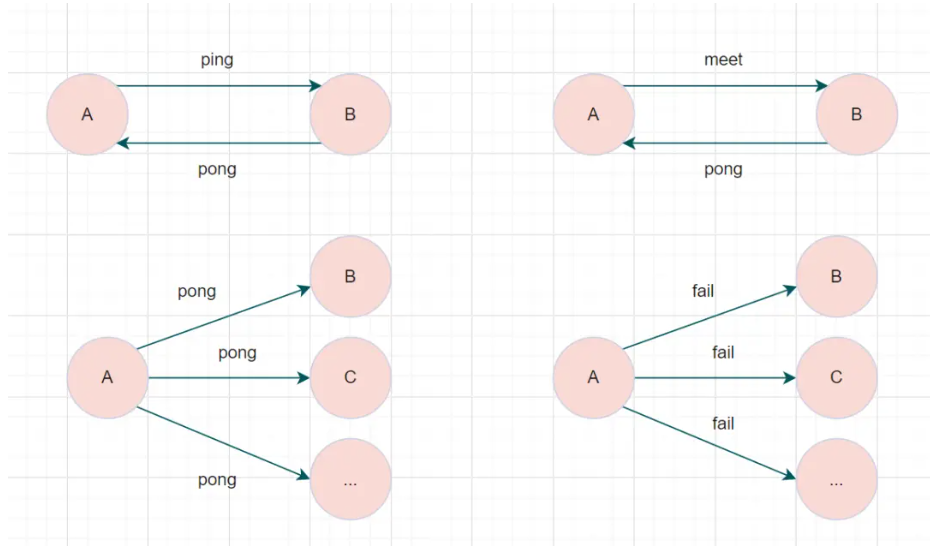
通信特点:
-
基于 TCP(默认端口号 + 10000,比如 Redis 端口是 6379,集群通信端口是 16379)。
-
去中心化,每个节点都知道其他节点信息。
-
通过定期 PING-PONG 交换来维护节点状态。
六、故障转移机制(Failover)
Redis Cluster 的高可用核心机制就是:主从复制 + 自动故障转移。
故障检测
-
如果一个主节点被多数节点标记为"主观下线(PFAIL)";
-
多数节点达成一致后,会将其标记为"客观下线(FAIL)"。
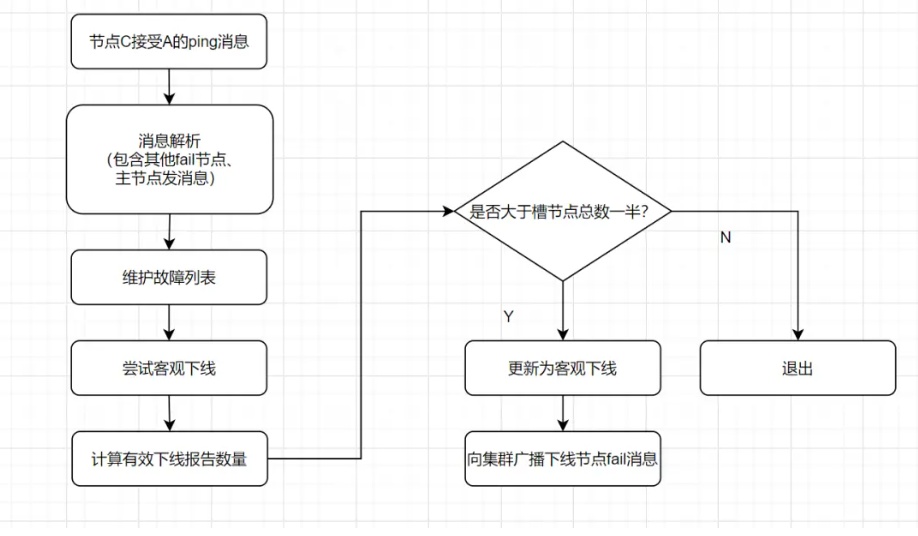
故障转移步骤
-
该主节点的从节点(slave)会自动发起选举(failover);
-
被选中的从节点提升为新的主节点;
-
集群广播通知,更新槽分配信息;
-
客户端收到 MOVED 后自动重定向请求到新主节点。
整个过程几乎可以自动完成,客户端无需人工干预。
七、Redis Cluster 的特点与限制
优点:
-
自动分片与负载均衡;
-
高可用;
-
无中心架构;
-
客户端自动感知集群变化。
限制:
-
不支持多键跨 slot 的事务(除非所有 key 落在同一 slot 上,可以使用
hash tag)。 -
不支持
keys *等全局命令。 -
部署复杂度比单机更高。