📘 Day 45 实战作业:给模型装上仪表盘 ------ TensorBoard 实战
1. 作业综述
核心目标:
- 环境搭建:安装并启动 TensorBoard。
- 指标监控 (Scalar) :不再盯着控制台刷屏,而是画出漂亮的 Loss 和 Accuracy 曲线,对比训练集和测试集的差异。
- 模型透视 (Graph):可视化神经网络的结构图 (Computational Graph)。
- 视觉验证 (Images):在 TensorBoard 里直接查看模型预测错误的图片。
涉及知识点:
- SummaryWriter: TensorBoard 的核心记录员。
- add_scalar: 记录数字指标。
- add_image: 记录图像数据。
- add_graph: 记录模型结构。
- Magic Command: 在 Jupyter 里直接嵌入 TensorBoard。
场景类比:
- Print 日志: 像是医生的手写病历,枯燥且难以分析趋势。
- TensorBoard: 像是ICU里的心电监护仪,实时跳动,一目了然。
步骤 1:初始化记录员 (Writer Setup)
核心概念 :
TensorBoard 的工作原理是:
- Python 代码往一个文件夹(比如
runs/experiment_1)里写日志文件。 - TensorBoard 程序读取这个文件夹,并在网页上渲染出图表。
任务:
- 定义 CIFAR-10 的数据管道(复用 Day 44 的极速版配置)。
- 初始化
SummaryWriter。
py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models, utils
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter # 核心组件
import numpy as np
import matplotlib.pyplot as plt
# 1. 准备数据 (复用 Day 44 极速版配置)
IMG_SIZE = 112
BATCH_SIZE = 64
transform = transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=2)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. 初始化 TensorBoard 记录器
# log_dir 是日志存放的路径,每次实验建议改个名字,比如 'runs/exp1', 'runs/exp2'
writer = SummaryWriter('runs/cifar10_resnet_experiment')
print("✅ TensorBoard Writer 已就绪!日志将写入 runs/cifar10_resnet_experiment")✅ TensorBoard Writer 已就绪!日志将写入 runs/cifar10_resnet_experiment步骤 2:可视化模型结构与图片
任务 :
在开始训练前,我们先往 TensorBoard 里存点东西看看效果。
- 看图: 把一个 Batch 的图片拼成网格,存进去。
- 看模型: 把 ResNet18 的结构图存进去。
py
# 1. 获取一个 Batch 的数据
images, labels = next(iter(train_loader))
# 2. 写入图片网格 (add_image)
# make_grid 会把 64 张图拼成一张大图
img_grid = utils.make_grid(images)
# 反归一化以便显示正常颜色 (可选)
img_grid_show = img_grid * 0.5 + 0.5
writer.add_image('CIFAR10_Input_Images', img_grid_show)
# 3. 写入模型结构 (add_graph)
# 需要传入模型实例和一个样例输入 (input_to_model)
model = models.resnet18(pretrained=False) # 演示用,不加载权重也没事
model.fc = nn.Linear(512, 10)
model = model.to(device)
# 注意:add_graph 需要输入也在对应的 device 上
dummy_input = images.to(device)
writer.add_graph(model, dummy_input)
print("✅ 图片和模型结构已写入!请稍后在 TensorBoard 查看。")e:\Anaconda\envs\test\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
e:\Anaconda\envs\test\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
✅ 图片和模型结构已写入!请稍后在 TensorBoard 查看。步骤 3:在训练循环中埋点
核心逻辑 :
我们需要在 train 和 test 的循环里插入 writer.add_scalar。
- tag (标签) : 比如
'Loss/train','Accuracy/test'。TensorBoard 会根据标签自动分组。 - scalar_value (数值): y 轴的值。
- global_step (步数): x 轴的值(通常是 epoch 或 iteration)。
任务 :
修改训练循环,实时记录 Loss 和 Accuracy。
py
# 重新定义一个简单的训练函数,集成 TensorBoard
def train_with_tensorboard(model, epochs=5):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 记录全局步数 (iteration)
step = 0
for epoch in range(epochs):
print(f"Epoch {epoch+1}/{epochs} starting...")
# --- 训练阶段 ---
model.train()
running_loss = 0.0
for i, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
# [埋点 1] 每 100 个 Batch 记录一次训练 Loss
# x轴使用 step (平滑连续),而不是 epoch
if i % 100 == 99:
writer.add_scalar('Loss/train', running_loss / 100, global_step=step)
running_loss = 0.0
step += 1
# --- 测试阶段 (每个 Epoch 结束后测一次) ---
model.eval()
correct = 0
total = 0
test_loss = 0.0
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100. * correct / total
avg_test_loss = test_loss / len(test_loader)
# [埋点 2] 记录测试集的 Accuracy 和 Loss
# x轴使用 epoch
writer.add_scalar('Accuracy/test', acc, global_step=epoch)
writer.add_scalar('Loss/test', avg_test_loss, global_step=epoch)
print(f"Epoch {epoch+1} finished. Test Acc: {acc:.2f}%")
# 开始训练 (演示跑 3 轮即可)
train_with_tensorboard(model, epochs=3)
# 记得关闭 writer,否则部分数据可能还没写进硬盘
writer.close()Epoch 1/3 starting...
Epoch 1 finished. Test Acc: 62.03%
Epoch 2/3 starting...
Epoch 2 finished. Test Acc: 69.76%
Epoch 3/3 starting...
Epoch 3 finished. Test Acc: 75.44%步骤 4:启动仪表盘
两种方式:
-
命令行 (推荐):打开 Anaconda Prompt 或终端,进入当前代码目录,输入:
bashtensorboard --logdir=runs然后浏览器访问
http://localhost:6006。 -
Jupyter 魔术命令:直接在 Notebook 里显示(如下所示)。
py
# 加载 TensorBoard 扩展
%load_ext tensorboard
# 启动 TensorBoard,指定日志目录
# 端口设为 6006 (默认)
%tensorboard --logdir=runs --port=6006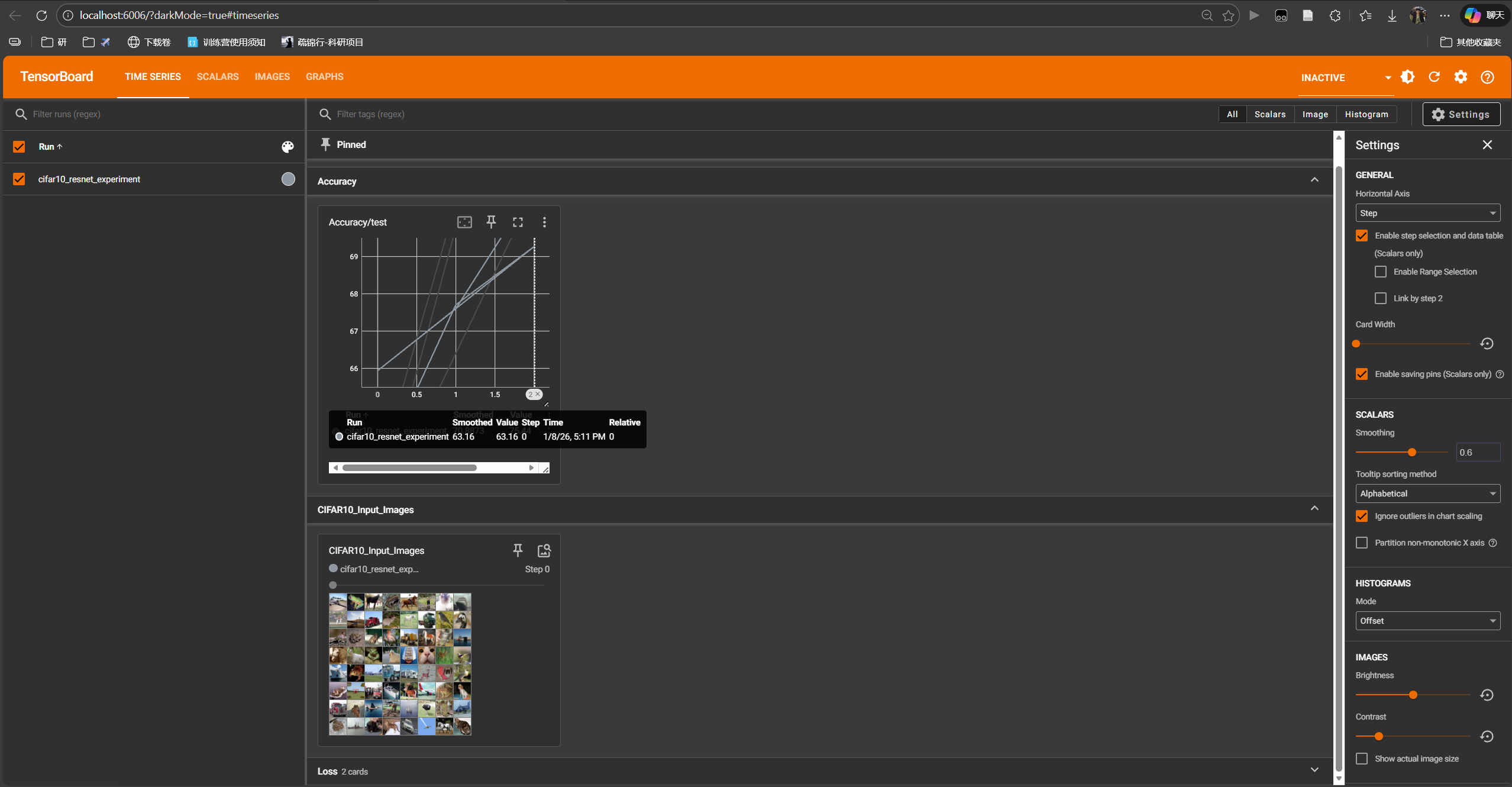
🎓 Day 45 总结:可视化分析
今天我们给 AI 模型装上了"眼睛"。通过 TensorBoard,你应该能看到:
- SCALARS: 随着训练进行,Loss 曲线在震荡中下降,Accuracy 曲线在上升。如果 Loss 曲线长时间不下降,或者 Test Loss 开始上升,你就知道该调整学习率或早停了。
- GRAPHS: 帅气的 ResNet18 流程图,展示了数据是如何一层层流动的。
- IMAGES: 我们喂给模型的图片长什么样。
工业界经验:
- 永远不要只看最后的 Acc。Loss 曲线的斜率、震荡幅度 包含了关于学习率是否合适、Batch Size 是否合理的巨大信息量。
- 同时记录
Train Loss和Test Loss,看它们何时分叉,那是过拟合 (Overfitting) 开始的信号。
Next Level :
到今天为止,我们的深度学习基础篇 (CV 方向) 已经非常扎实了。
明天(Day 46),我们将迈出最后一步 ------ 模型部署 (Deployment)。我们要把训练好的模型打包成一个 Web 服务,让别人通过浏览器就能上传图片并得到识别结果!