
旧版本:可以看到,requestId是在每一次调用unlockAsync0时就会创建一次 记住这个点
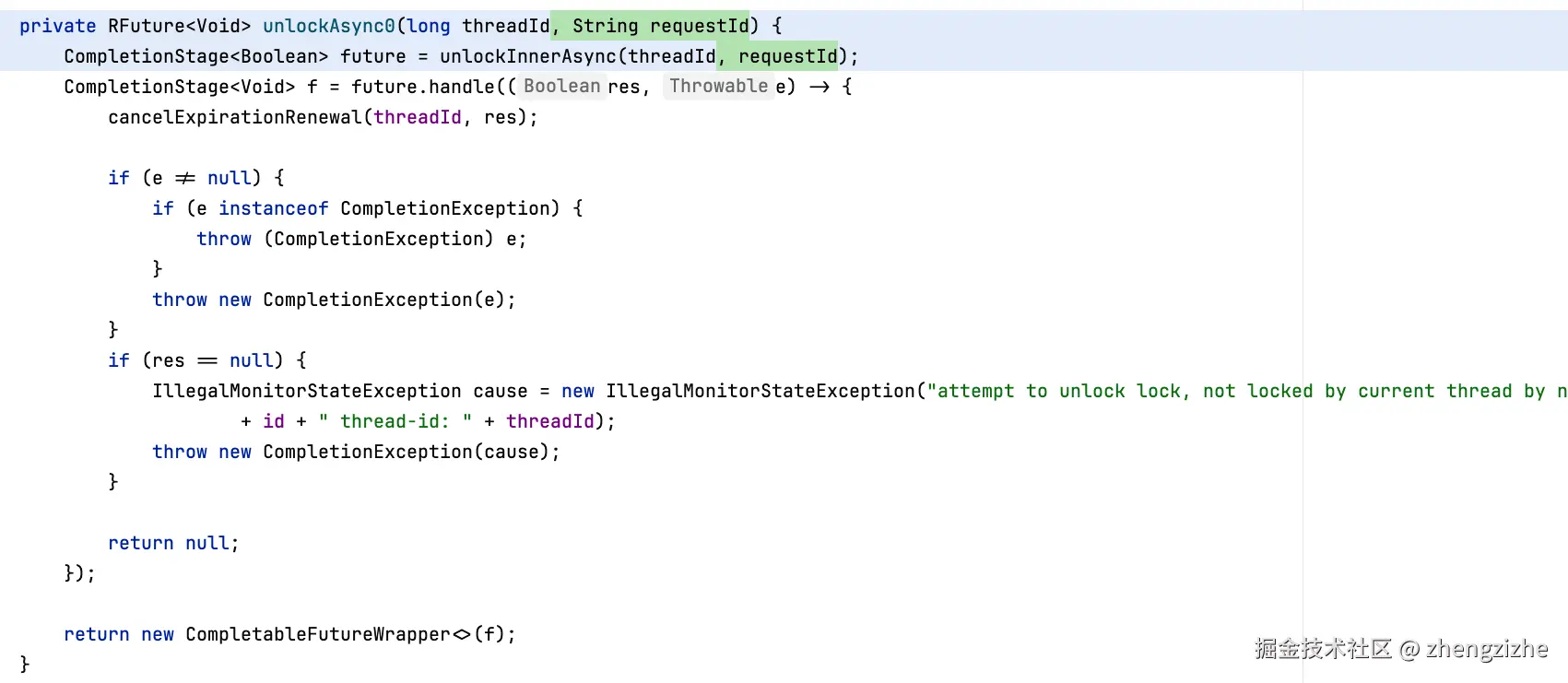
最终会执行到
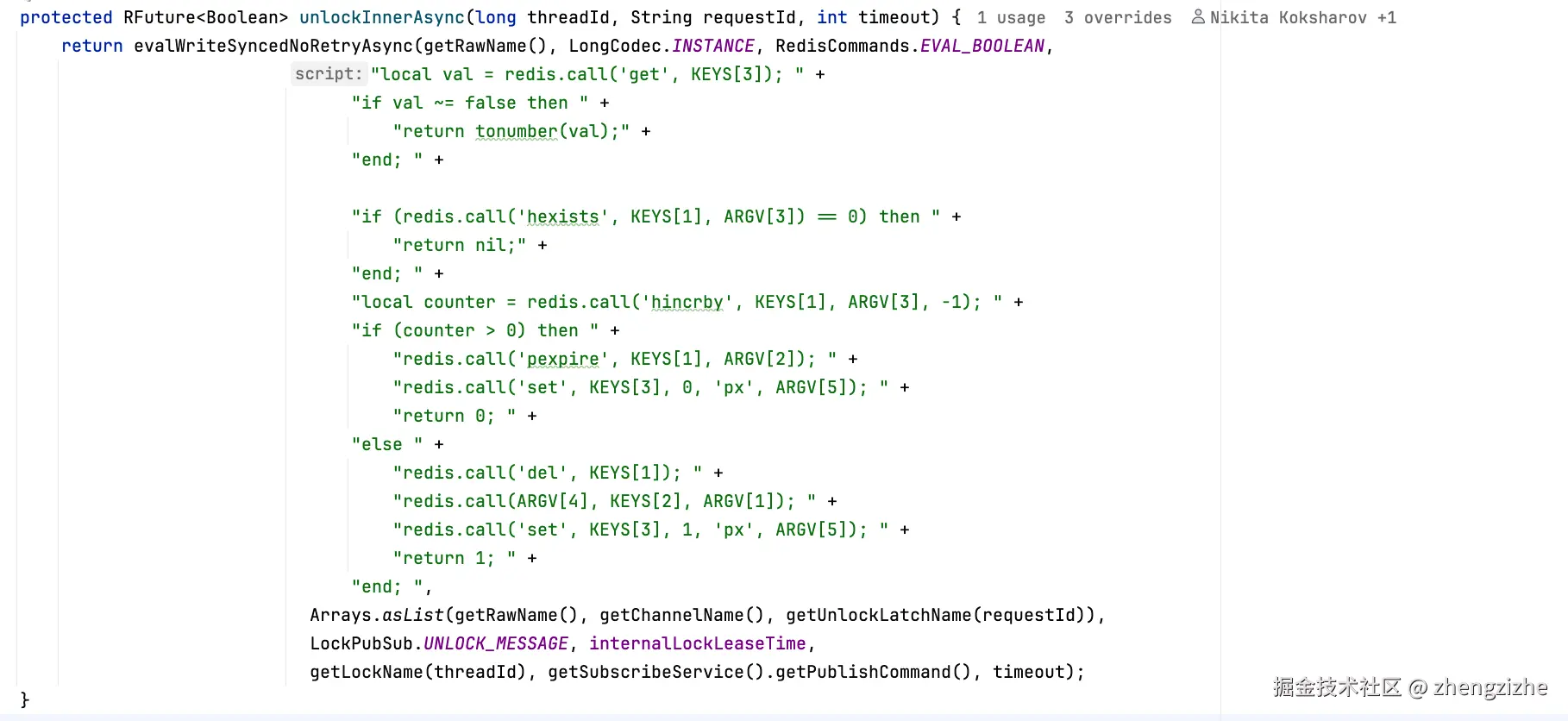


2.通过请求id来获取看本次请求id是否执行过,如果执行过,就不在执行脚本,反之
3.校验是否当前线程持有
返回值
执行真正的解锁
1 → true :这次调用导致完全释放、
**0**** → false:这次调用只是部分释放**
**nil**** → null:当前线程不是持有者 会抛异常**
注意包装方法
太几把长了,看不懂 总之就是先探测、再执行、再校验副本同步
什么时候会失败(抛异常)
只有以下同时满足才会失败:
| 条件 | 说明 |
|---|---|
isCheckLockSyncedSlaves == true |
默认开启 |
Redis 分片上有从节点(availableSlaves > 0 ) |
有副本可用 |
WAIT / WAITAOF 返回同步成功数 = 0 |
所有副本都没确认这次写入 |
此时抛 NoSyncedSlavesException,被上层 ServiceManager.execute(...) 捕获后延迟重试。
ini
private <T> RFuture<T> syncedEval(long timeout, SyncMode syncMode, boolean retry, String key, Codec codec, RedisCommand<T> evalCommandType,
String script, List<Object> keys, Object... params) {
if (getServiceManager().getCfg().isSingleConfig()
|| this instanceof CommandBatchService
|| (waitSupportedCommands != null && waitSupportedCommands.isEmpty() && syncMode == SyncMode.AUTO)
|| (waitSupportedCommands != null && !waitSupportedCommands.contains(RedisCommands.WAIT.getName()) && syncMode == SyncMode.WAIT)
|| (waitSupportedCommands != null && !waitSupportedCommands.contains(RedisCommands.WAITAOF.getName()) && syncMode == SyncMode.WAIT_AOF)
) {
if (retry) {
return evalWriteAsync(key, codec, evalCommandType, script, keys, params);
}
return evalWriteNoRetryAsync(key, codec, evalCommandType, script, keys, params);
}
CompletionStage<BatchResult<?>> waitFuture = CompletableFuture.completedFuture(null);
if (waitSupportedCommands == null) {
CommandBatchService ee = createCommandBatchService(BatchOptions.defaults());
ee.writeAsync(key, RedisCommands.WAIT, 0, 0);
ee.writeAsync(key, RedisCommands.WAITAOF, 0, 0, 0);
waitFuture = ee.executeAsync();
}
CompletionStage<T> resFuture = waitFuture.handle((r2, ex2) -> {
if (ex2 != null) {
List<String> commands = new ArrayList<>(Arrays.asList(RedisCommands.WAITAOF.getName(), RedisCommands.WAIT.getName()));
List<String> msgs = new ArrayList<>(2);
if (ex2.getCause() != null) {
msgs.add(ex2.getCause().getMessage());
} else {
msgs.add(ex2.getMessage());
}
for (Throwable throwable : ex2.getSuppressed()) {
if (throwable.getCause() != null) {
msgs.add(throwable.getCause().getMessage());
} else {
msgs.add(throwable.getMessage());
}
}
for (String msg : msgs) {
Iterator<String> iterator = commands.iterator();
while (iterator.hasNext()) {
String command = iterator.next();
if (msg.startsWith("ERR unknown command")
&& msg.toUpperCase().contains(command)) {
iterator.remove();
break;
}
}
}
if (commands.size() == 2) {
throw new CompletionException(ex2);
} else {
waitSupportedCommands = commands;
}
if (commands.isEmpty()) {
CompletionStage<T> f = evalWriteAsync(key, codec, evalCommandType, script, keys, params);
return f;
}
}
if (waitSupportedCommands == null) {
waitSupportedCommands = Arrays.asList(RedisCommands.WAIT.getName(), RedisCommands.WAITAOF.getName());
}
MasterSlaveEntry e = connectionManager.getEntry(key);
if (e == null) {
throw new CompletionException(new RedisNodeNotFoundException("entry for " + key + " hasn't been discovered yet"));
}
CompletionStage<Map<String, String>> replicationFuture;
int slaves = e.getAvailableSlaves();
if (slaves != -1) {
Map<String, String> map = new HashMap<>(2);
map.put("connected_slaves", "" + slaves);
if (e.isAofEnabled()) {
map.put("aof_enabled", "1");
} else {
map.put("aof_enabled", "0");
}
replicationFuture = CompletableFuture.completedFuture(map);
} else {
replicationFuture = writeAsync(e, StringCodec.INSTANCE, RedisCommands.INFO_ALL);
}
CompletionStage<T> resultFuture = replicationFuture.thenCompose(r -> {
int availableSlaves;
boolean aofEnabled;
if (waitSupportedCommands.contains(RedisCommands.WAIT.getName())) {
availableSlaves = Integer.parseInt(r.getOrDefault("connected_slaves", "0"));
} else {
availableSlaves = 0;
}
if (waitSupportedCommands.contains(RedisCommands.WAITAOF.getName())) {
aofEnabled = "1".equals(r.getOrDefault("aof_enabled", "0"));
} else {
aofEnabled = false;
}
e.setAvailableSlaves(availableSlaves);
e.setAofEnabled(aofEnabled);
CommandBatchService executorService = createCommandBatchService(availableSlaves, aofEnabled, timeout);
RFuture<T> result = executorService.evalWriteAsync(key, codec, evalCommandType, script, keys, params);
if (executorService == this) {
return result;
}
RFuture<BatchResult<?>> future = executorService.executeAsync();
CompletionStage<T> sf = future.handle((res, ex) -> {
if (ex != null) {
if (ex instanceof RedisNoScriptException) {
MasterSlaveEntry entry = connectionManager.getEntry(key);
return loadScript(entry.getClient(), script).thenCompose(r3 ->
syncedEval(timeout, syncMode, retry, key, codec, evalCommandType, script, keys, params));
}
CompletableFuture<T> ef = new CompletableFuture<>();
ef.completeExceptionally(ex);
return ef;
}
if (res.getSyncedSlaves() < availableSlaves
|| res.getSyncedSlaves() > availableSlaves) {
e.setAvailableSlaves(-1);
}
if (getServiceManager().getCfg().isCheckLockSyncedSlaves()
&& res.getSyncedSlaves() == 0 && availableSlaves > 0) {
throw new CompletionException(
new NoSyncedSlavesException("None of slaves were synced. Try to increase slavesSyncTimeout setting or set checkLockSyncedSlaves = false."));
}
return result;
}).thenCompose(f -> f);
return sf;
});
return resultFuture;
}).thenCompose(f -> f);
return new CompletableFutureWrapper<>(resFuture);
}重新回到顶层看

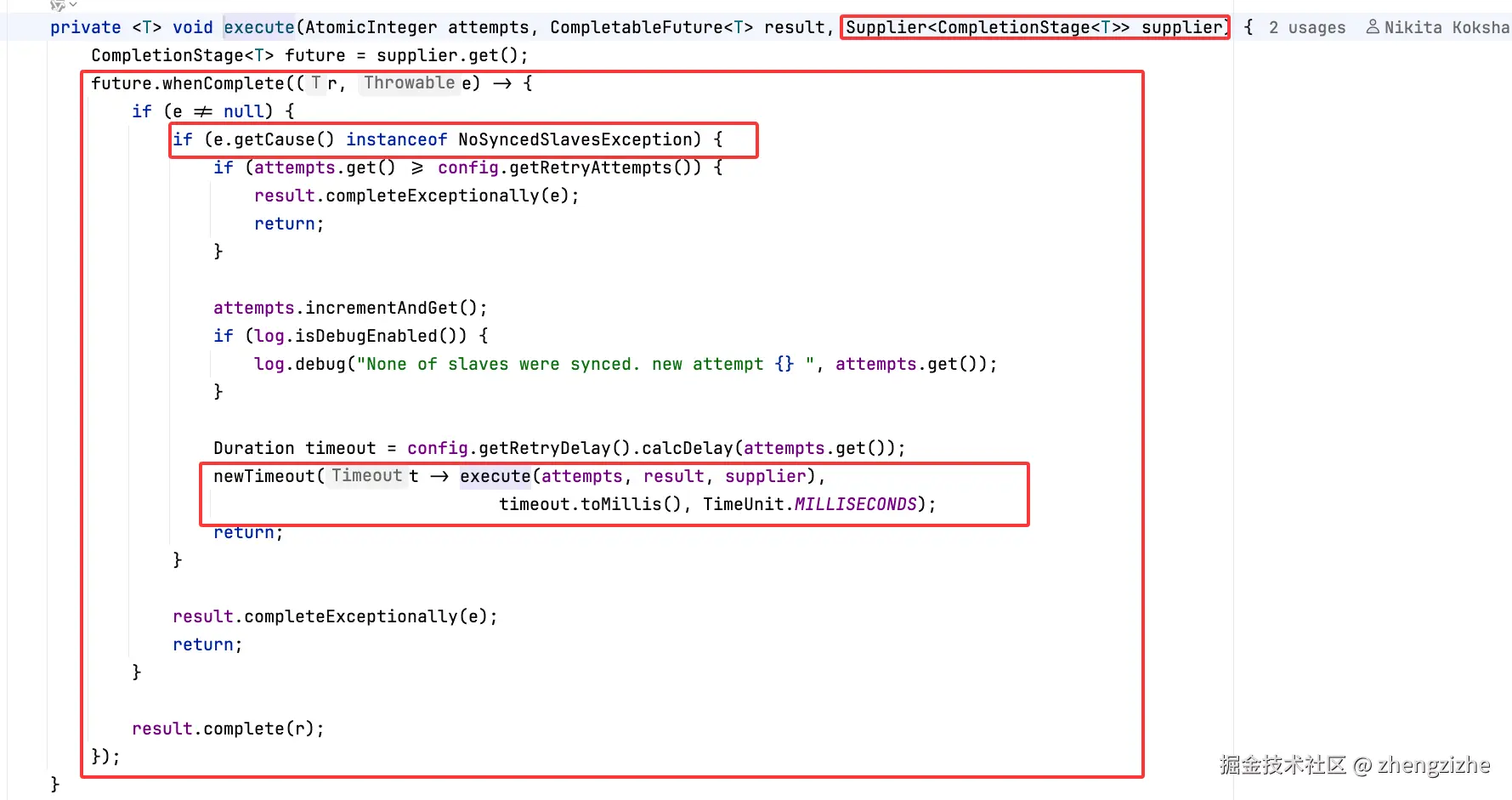
大体逻辑就是执行上序全部代码后,发现异常为NoSyncedSlavesException开始重试,
又因为
重试的请求id不一致,在执行解锁脚本时发现新请求id没执行过,再次执行,此时锁已不是自身线程,因此抛出异常 attempt to unlock lock, not locked by current thread by node id
新版本将请求id的生成放在顶层,不管重试多少次都是同一个请求id,脚本不会重试,可以防止因为同步问题导致的异常,
我想到的问题 假设不因同步问题导致即可能因为网络原因导致连主节点都没解锁成功,那脚本不会将请求id的值修改,自然第二次也会重试