✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
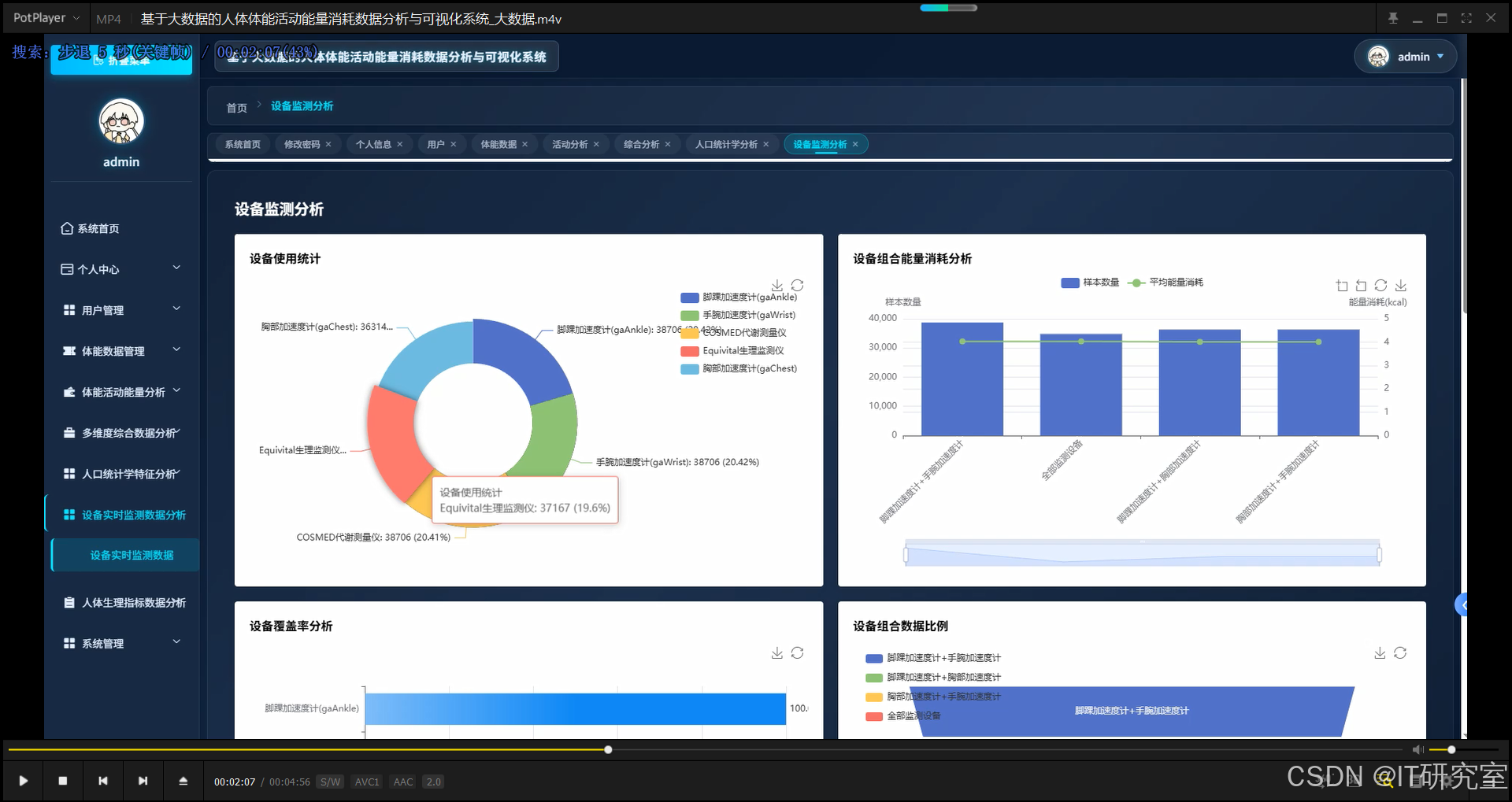
本系统是一个基于大数据技术的人体体能活动能量消耗数据分析与可视化平台,采用Hadoop+Spark分布式计算框架对EEHPA(老年人体能活动能量消耗)数据集进行深度挖掘与分析。系统后端采用Django/Spring Boot双框架支持,利用Spark SQL进行大规模数据查询与统计计算,结合Pandas和NumPy进行科学计算与数据处理。前端基于Vue+ElementUI构建响应式交互界面,使用Echarts实现多维度数据可视化展示,包括人口统计学特征分析、体能活动能量消耗对比、生理指标关联分析、设备监测数据评估等核心功能模块。系统通过对性别、年龄、BMI、心率、呼吸指标、活动类型等多维度特征的综合分析,揭示不同人群在各类活动中的能量消耗规律,为老年人健康管理、运动处方制定、可穿戴设备校准提供数据支撑。平台支持大屏可视化展示,能够直观呈现能量消耗趋势、生理指标相关性、活动类型分布等关键信息,为科研人员和健康管理从业者提供实用的数据分析工具。
选题背景
随着全球人口老龄化进程加快,老年人群的健康管理成为公共卫生领域的重要课题。准确评估老年人日常活动的能量消耗对于制定个性化运动方案、预防慢性疾病、改善生活质量具有重要价值。传统的能量消耗评估方法主要依赖标准代谢当量表,但这些标准值多基于年轻成年人群建立,对于生理机能逐渐衰退的老年群体存在较大误差。近年来可穿戴设备和传感器技术的发展,使得持续监测人体生理指标成为可能,但如何从海量的生理监测数据中提取有价值的信息,建立适用于老年人群的能量消耗评估模型,仍然面临技术挑战。同时,不同性别、年龄段、体重状况的老年人在相同活动下的能量消耗差异显著,需要通过大规模数据分析来揭示这些个体化差异规律。大数据技术的成熟为处理和分析多维度、大规模的人体活动数据提供了技术基础,使得构建精准的能量消耗分析系统成为可能。
选题意义
从实际应用层面来看,本系统能够为社区健康管理机构和养老服务中心提供一个相对实用的数据分析工具。通过对不同老年人群体能活动数据的统计分析,可以帮助健康管理人员更好地了解服务对象的活动特征和能量消耗情况,从而制定更加合理的运动建议和健康干预方案。系统对性别、年龄、BMI等人口统计学特征与能量消耗关系的分析,能够为不同类型老年人提供更具针对性的活动参考值,避免运动强度过高或过低带来的健康风险。同时,系统对心率、呼吸等生理指标与能量消耗相关性的研究,可以为可穿戴设备的能量消耗估算算法提供一定的数据支持,提高日常监测的准确性。从技术角度来说,本系统将大数据处理技术应用于健康数据分析场景,探索了Hadoop和Spark在处理多维度生理监测数据方面的可行性,为后续相关领域的系统开发积累了一些经验。作为一个毕业设计项目,它也帮助我们将课堂学习的大数据理论知识与实际健康数据分析需求结合起来,提升了综合运用技术解决实际问题的能力。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的人体体能活动能量消耗数据分析与可视化系统界面展示:
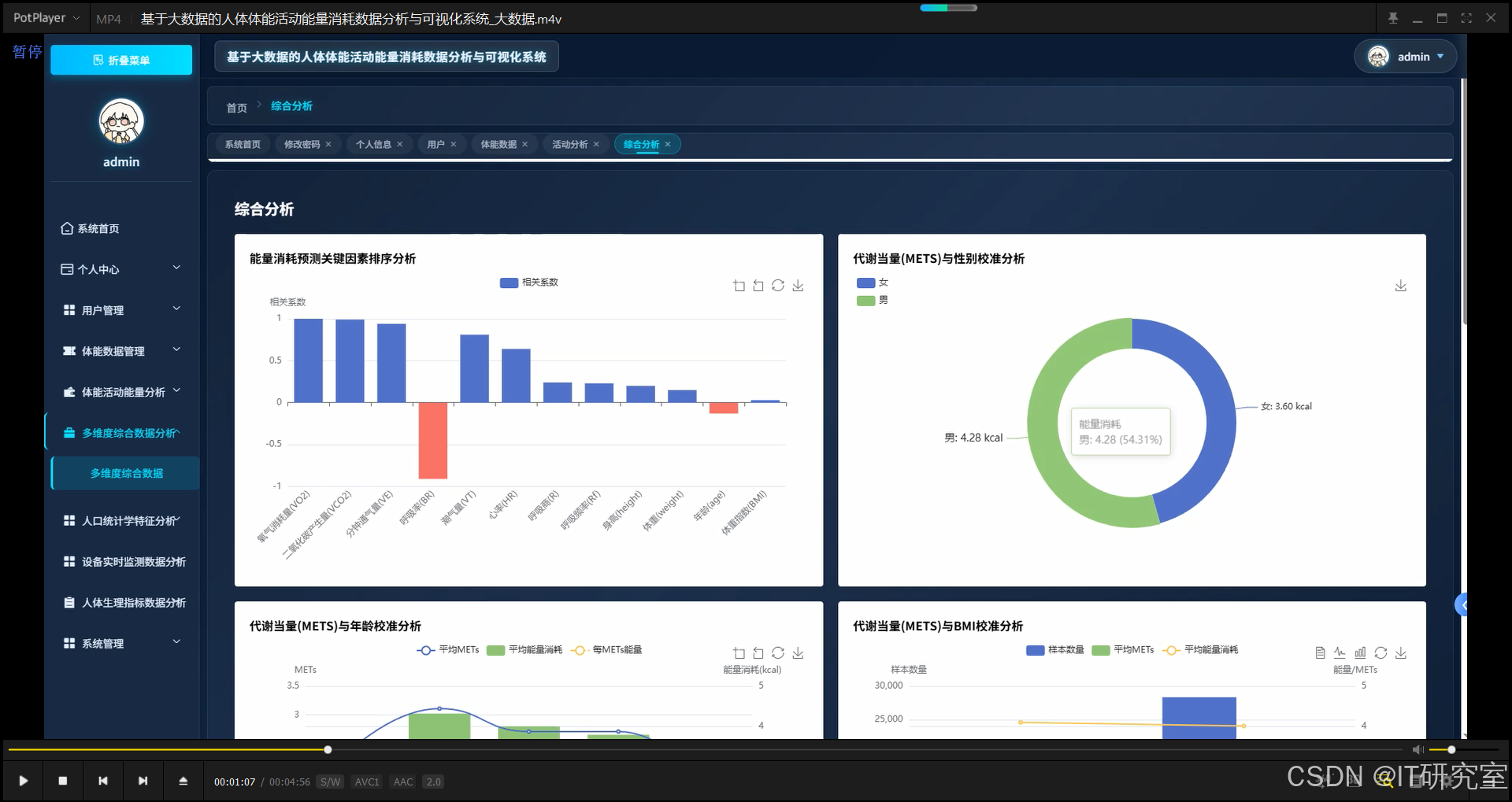
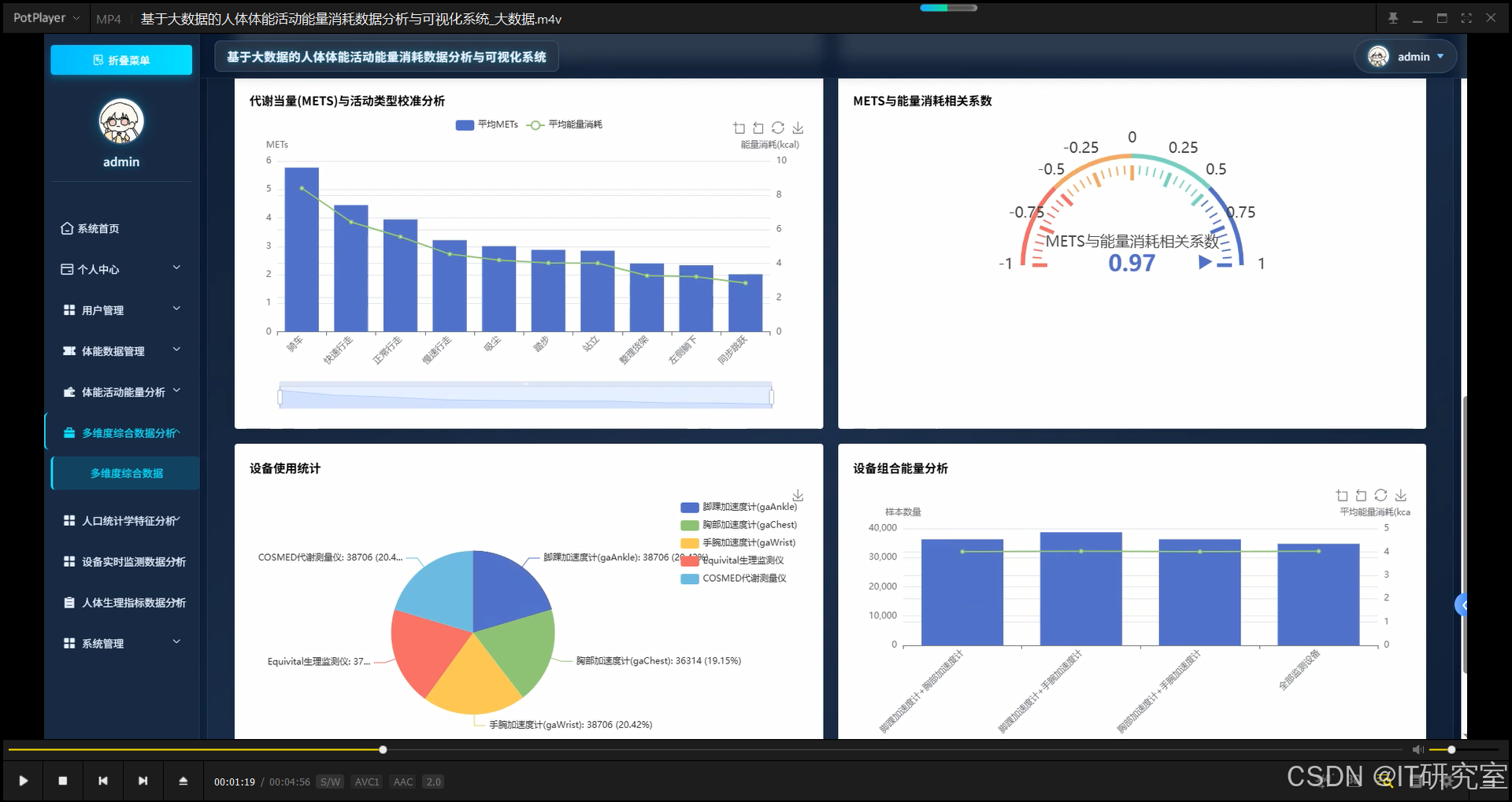
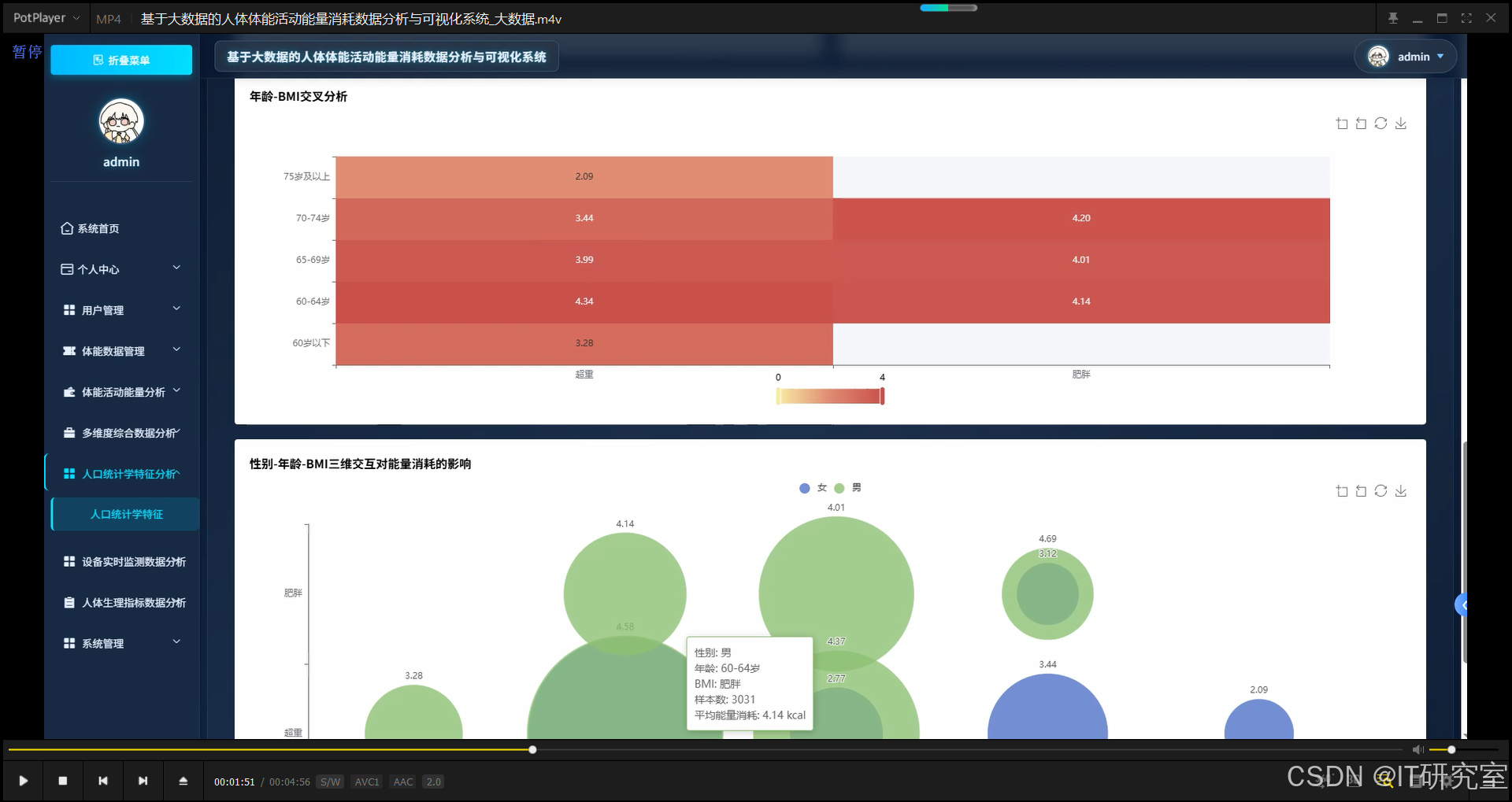
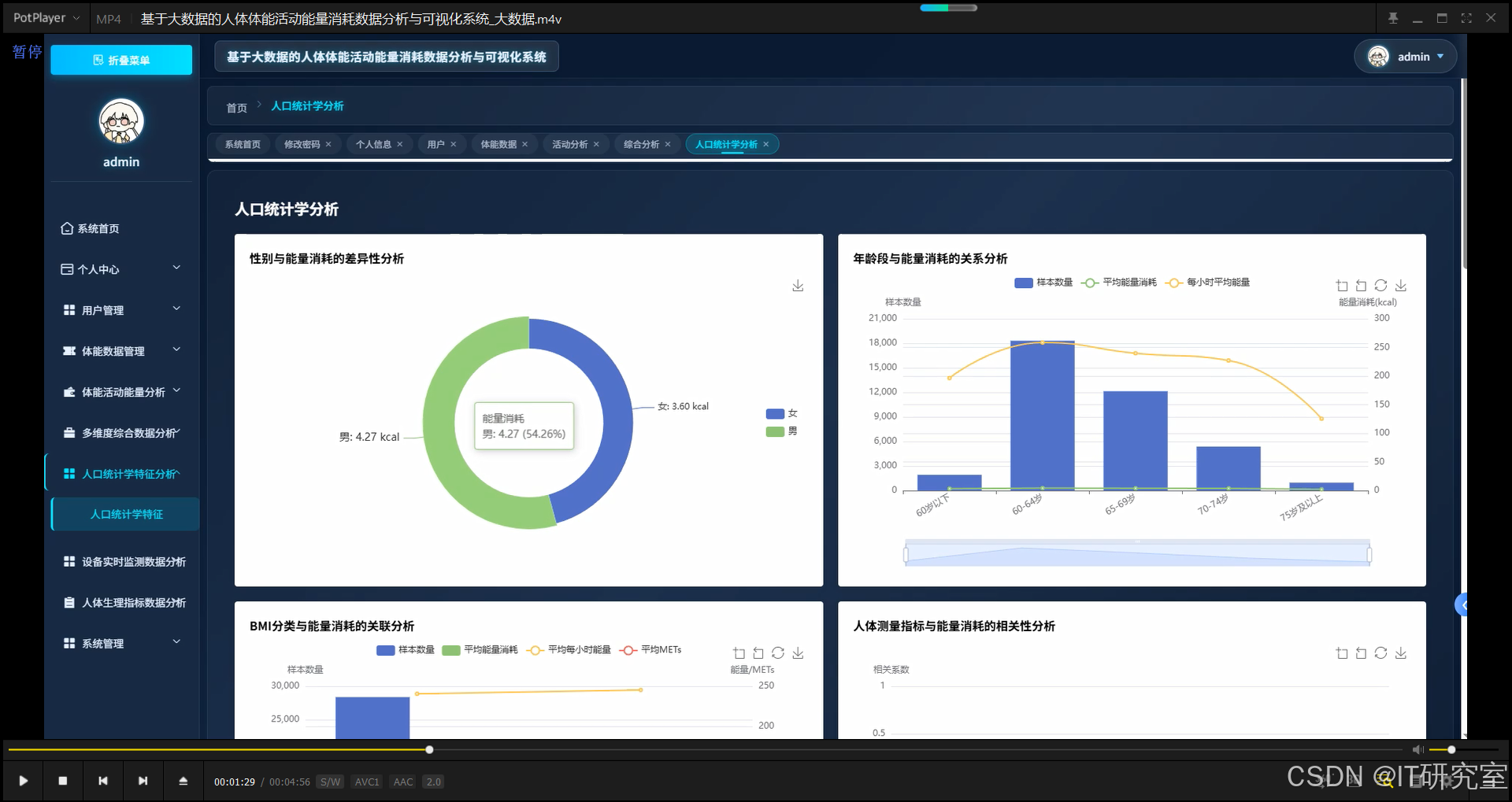
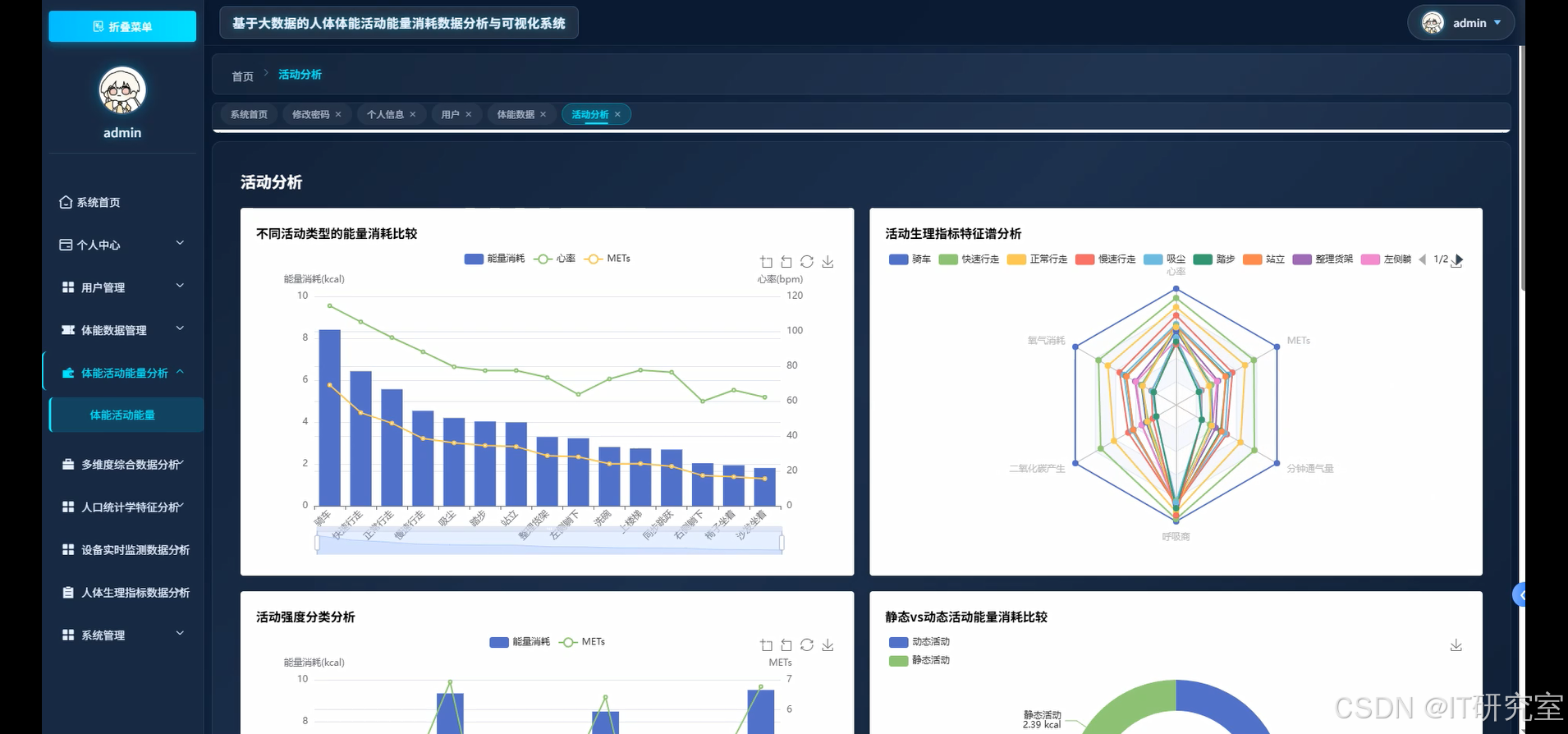
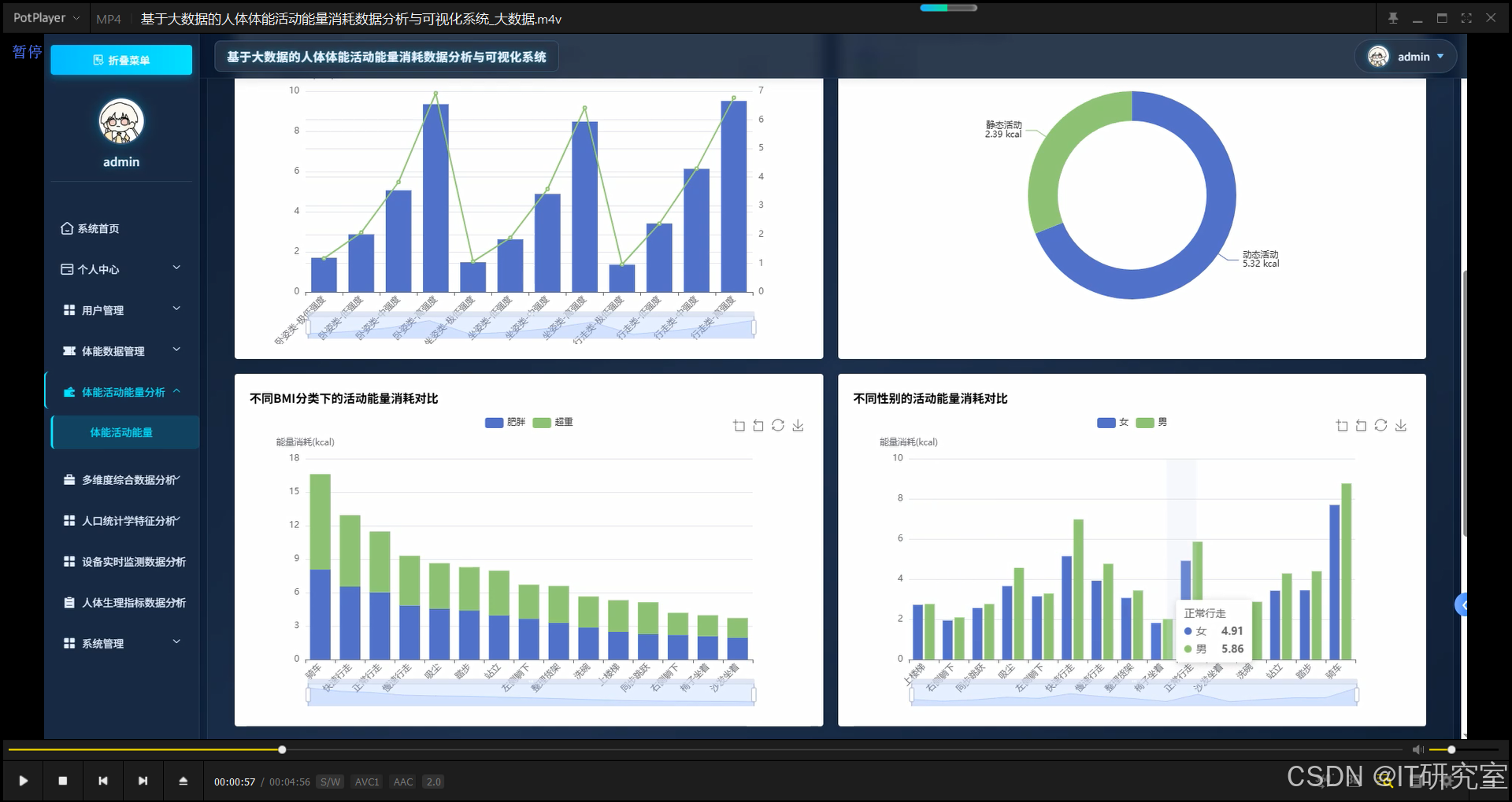
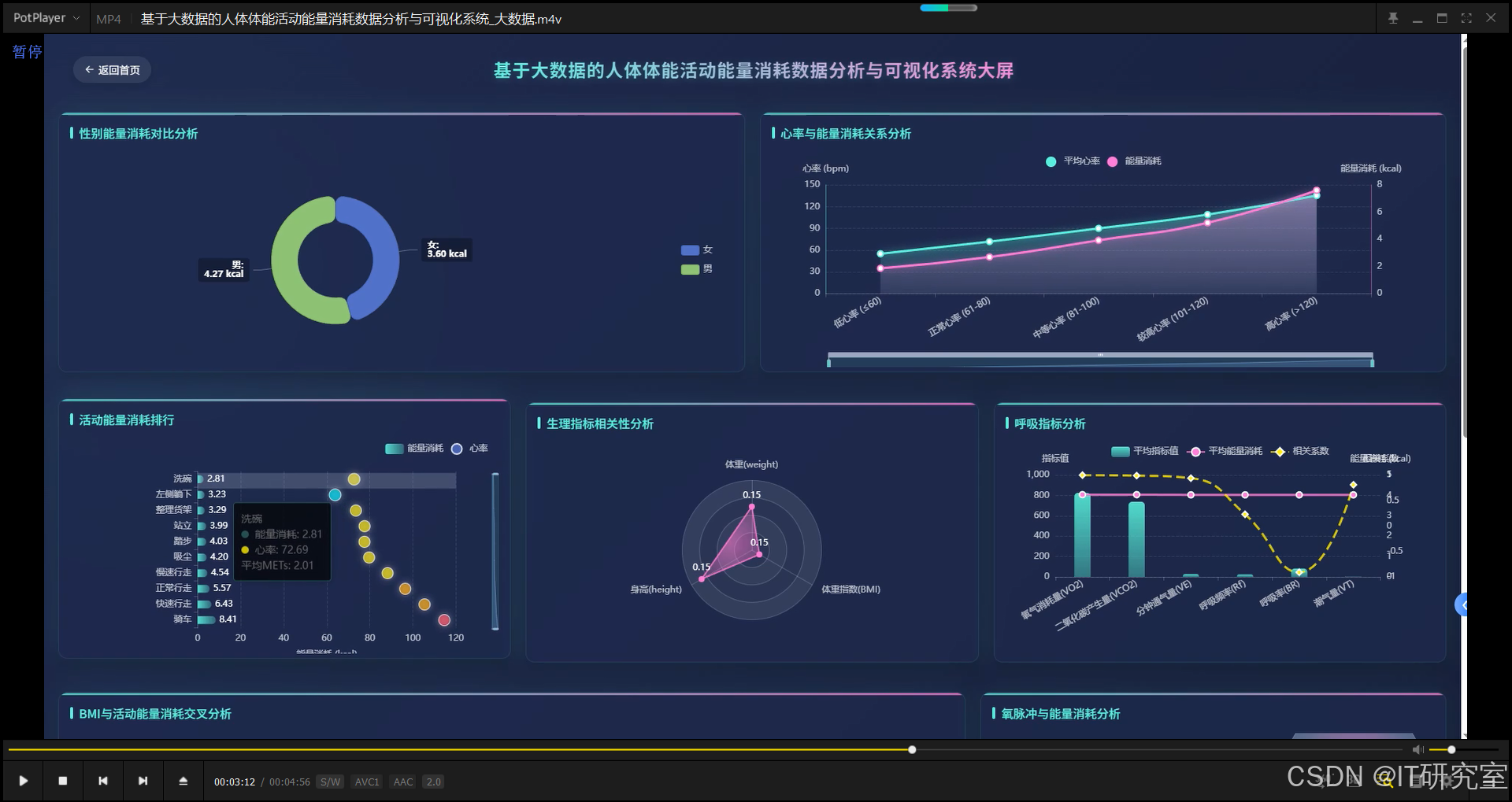
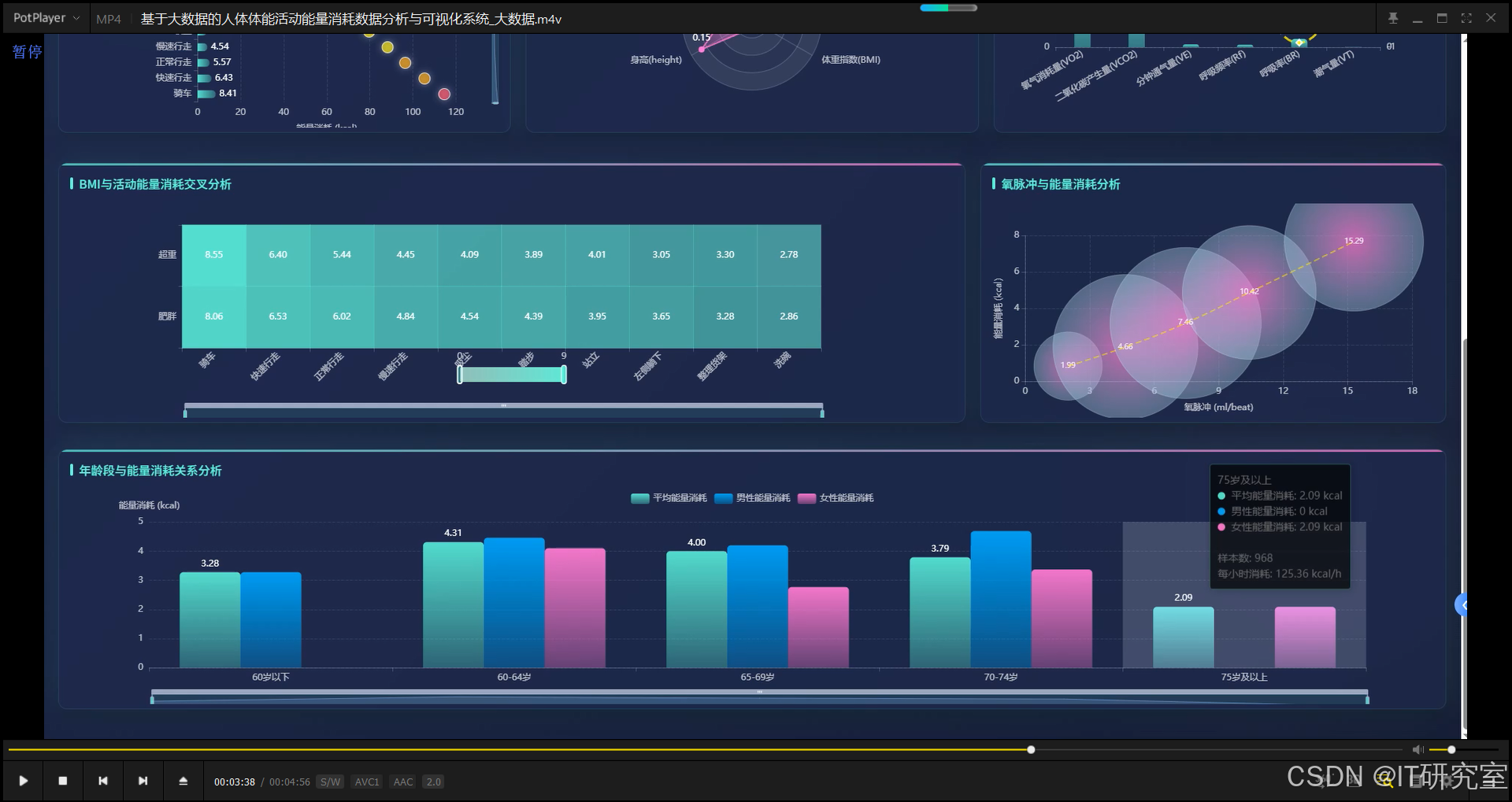
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, stddev, corr, when, concat_ws, round as spark_round
from pyspark.sql.window import Window
from pyspark.sql.types import StringType
import pandas as pd
import numpy as np
from django.http import JsonResponse
from django.views.decorators.http import require_http_methods
spark = SparkSession.builder.appName("EnergyExpenditureAnalysis").config("spark.sql.shuffle.partitions", "8").config("spark.executor.memory", "2g").getOrCreate()
@require_http_methods(["POST"])
def analyze_demographic_energy_consumption(request):
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("hdfs://localhost:9000/data/EEHPA.csv")
df = df.filter(col("EEm").isNotNull() & col("age").isNotNull() & col("gender").isNotNull() & col("bmi").isNotNull())
gender_analysis = df.groupBy("gender").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(stddev("EEm"), 2).alias("stddev_energy"), count("*").alias("sample_count"))
df = df.withColumn("age_group", when(col("age") < 60, "60岁以下").when((col("age") >= 60) & (col("age") < 65), "60-64岁").when((col("age") >= 65) & (col("age") < 70), "65-69岁").when((col("age") >= 70) & (col("age") < 75), "70-74岁").otherwise("75岁及以上"))
age_analysis = df.groupBy("age_group").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("HR"), 2).alias("avg_heart_rate"), spark_round(avg("METS"), 2).alias("avg_mets"), count("*").alias("sample_count")).orderBy("age_group")
df = df.withColumn("bmi_category", when(col("bmi") < 18.5, "偏瘦").when((col("bmi") >= 18.5) & (col("bmi") < 24), "正常").when((col("bmi") >= 24) & (col("bmi") < 28), "超重").otherwise("肥胖"))
bmi_analysis = df.groupBy("bmi_category").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("weight"), 2).alias("avg_weight"), spark_round(avg("height"), 2).alias("avg_height"), count("*").alias("sample_count"))
correlation_metrics = df.select(corr("weight", "EEm").alias("weight_corr"), corr("height", "EEm").alias("height_corr"), corr("bmi", "EEm").alias("bmi_corr"), corr("age", "EEm").alias("age_corr"))
gender_bmi_analysis = df.groupBy("gender", "bmi_category").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), count("*").alias("sample_count")).orderBy("gender", "bmi_category")
age_gender_analysis = df.groupBy("age_group", "gender").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("METS"), 2).alias("avg_mets"), count("*").alias("sample_count")).orderBy("age_group", "gender")
result_data = {"gender_stats": gender_analysis.toPandas().to_dict(orient='records'), "age_stats": age_analysis.toPandas().to_dict(orient='records'), "bmi_stats": bmi_analysis.toPandas().to_dict(orient='records'), "correlations": correlation_metrics.toPandas().to_dict(orient='records')[0], "gender_bmi_cross": gender_bmi_analysis.toPandas().to_dict(orient='records'), "age_gender_cross": age_gender_analysis.toPandas().to_dict(orient='records')}
return JsonResponse({"status": "success", "data": result_data, "message": "人口统计学特征与能量消耗关系分析完成"})
@require_http_methods(["POST"])
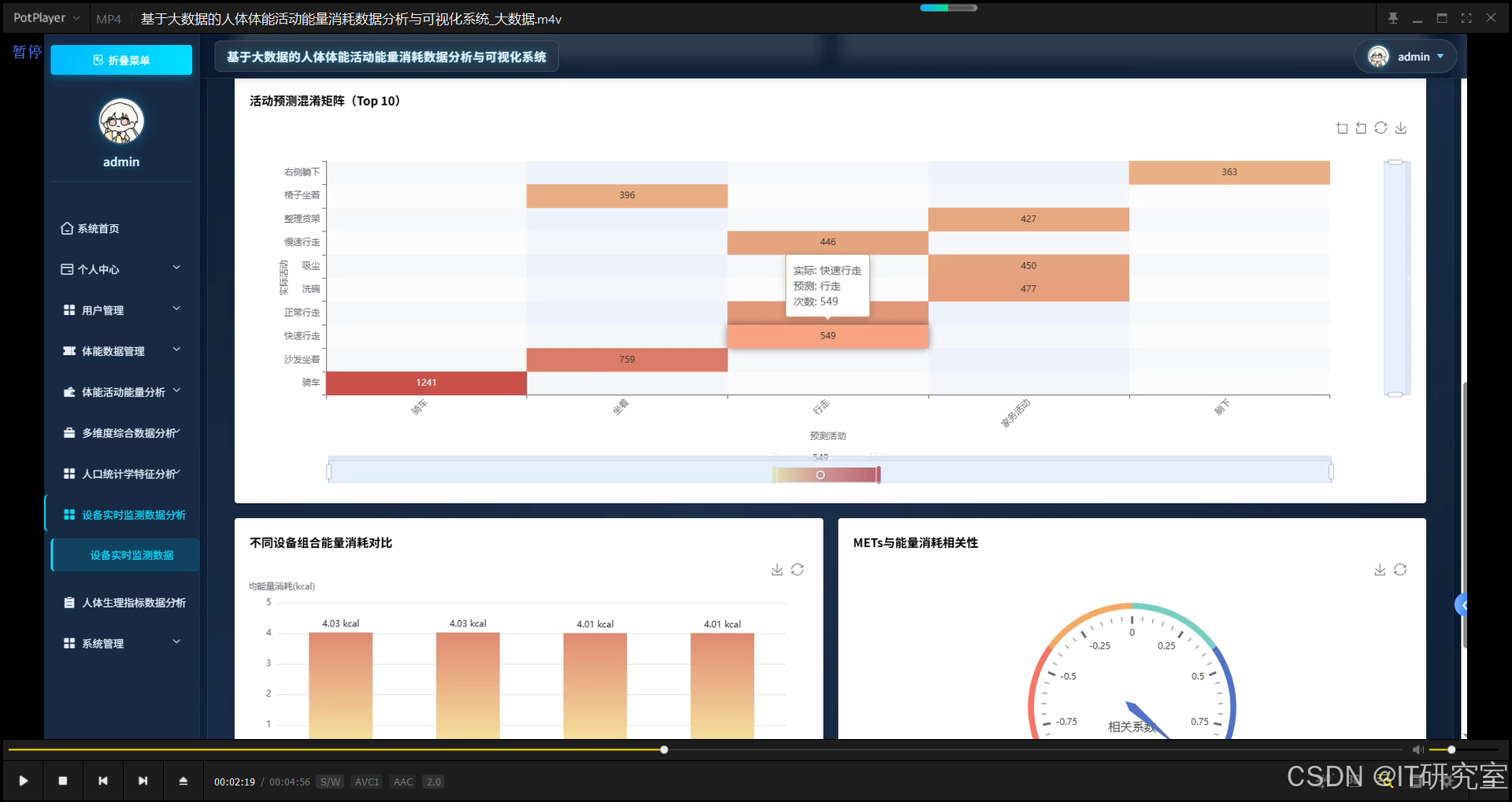
def analyze_activity_energy_patterns(request):
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("hdfs://localhost:9000/data/EEHPA.csv")
df = df.filter(col("EEm").isNotNull() & col("original_activity_labels").isNotNull() & col("METS").isNotNull())
activity_energy_analysis = df.groupBy("original_activity_labels").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("HR"), 2).alias("avg_heart_rate"), spark_round(avg("METS"), 2).alias("avg_mets"), spark_round(stddev("EEm"), 2).alias("stddev_energy"), count("*").alias("sample_count")).orderBy(col("avg_energy").desc())
static_activities = ["sitting", "lyingDown", "lyingDownLeft", "lyingDownRight"]
df = df.withColumn("activity_type", when(col("original_activity_labels").isin(static_activities), "静态活动").otherwise("动态活动"))
static_dynamic_analysis = df.groupBy("activity_type").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("VO2"), 2).alias("avg_vo2"), spark_round(avg("VCO2"), 2).alias("avg_vco2"), count("*").alias("sample_count"))
mets_intensity_analysis = df.withColumn("intensity_level", when(col("METS") < 2, "极低强度").when((col("METS") >= 2) & (col("METS") < 3), "低强度").when((col("METS") >= 3) & (col("METS") < 6), "中等强度").otherwise("高强度")).groupBy("original_activity_labels", "intensity_level").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("METS"), 2).alias("avg_mets"), count("*").alias("sample_count")).orderBy("original_activity_labels", col("avg_energy").desc())
activity_gender_analysis = df.groupBy("original_activity_labels", "gender").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), count("*").alias("sample_count")).orderBy("original_activity_labels", "gender")
df = df.withColumn("bmi_category", when(col("bmi") < 18.5, "偏瘦").when((col("bmi") >= 18.5) & (col("bmi") < 24), "正常").when((col("bmi") >= 24) & (col("bmi") < 28), "超重").otherwise("肥胖"))
activity_bmi_analysis = df.groupBy("original_activity_labels", "bmi_category").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("METS"), 2).alias("avg_mets"), count("*").alias("sample_count")).orderBy("original_activity_labels", "bmi_category")
top_activities = activity_energy_analysis.limit(10).toPandas().to_dict(orient='records')
result_data = {"activity_ranking": top_activities, "static_vs_dynamic": static_dynamic_analysis.toPandas().to_dict(orient='records'), "intensity_analysis": mets_intensity_analysis.toPandas().to_dict(orient='records'), "gender_differences": activity_gender_analysis.toPandas().to_dict(orient='records'), "bmi_activity_patterns": activity_bmi_analysis.toPandas().to_dict(orient='records')}
return JsonResponse({"status": "success", "data": result_data, "message": "活动类型与能量消耗特征分析完成"})
@require_http_methods(["POST"])
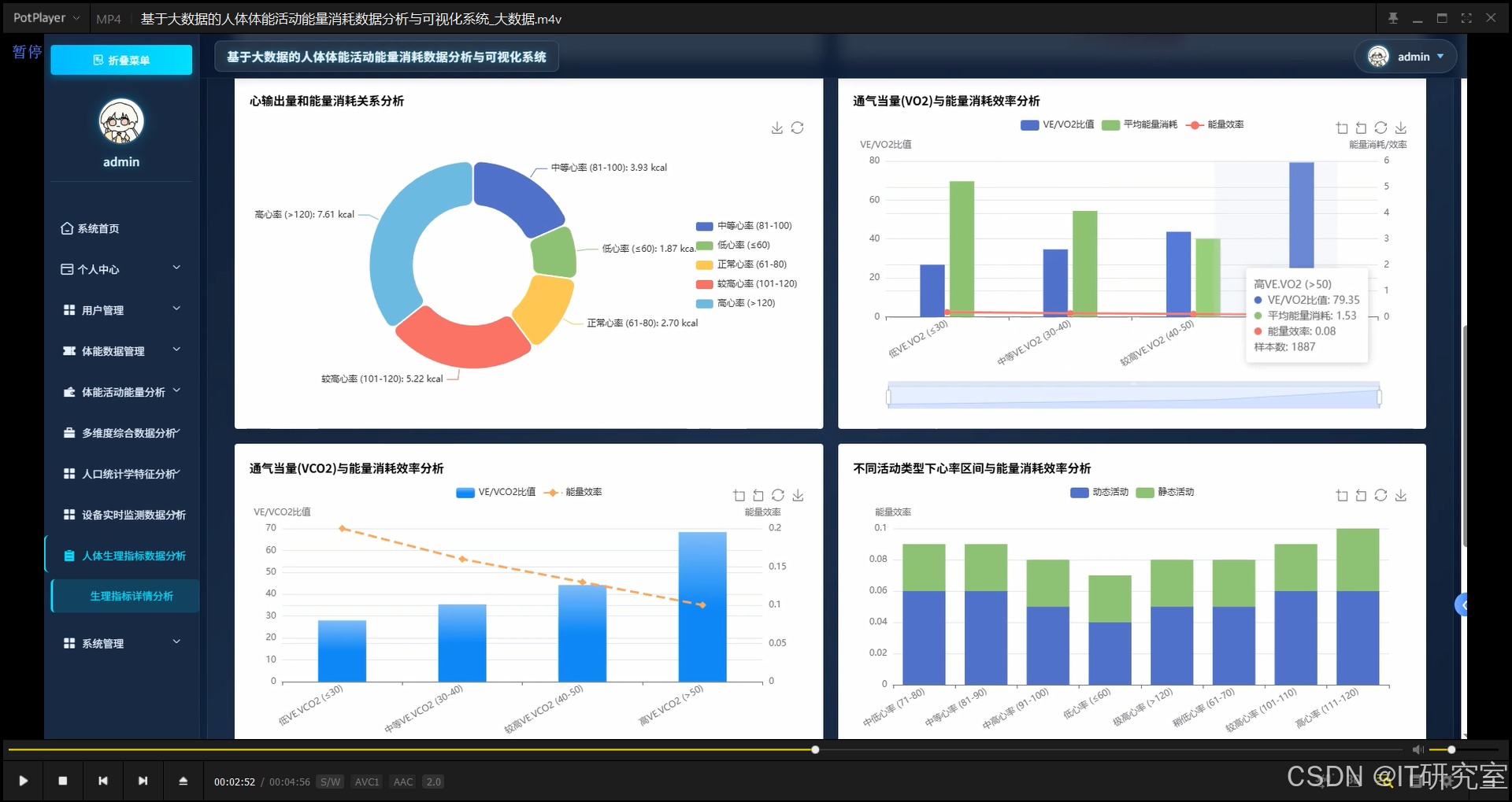
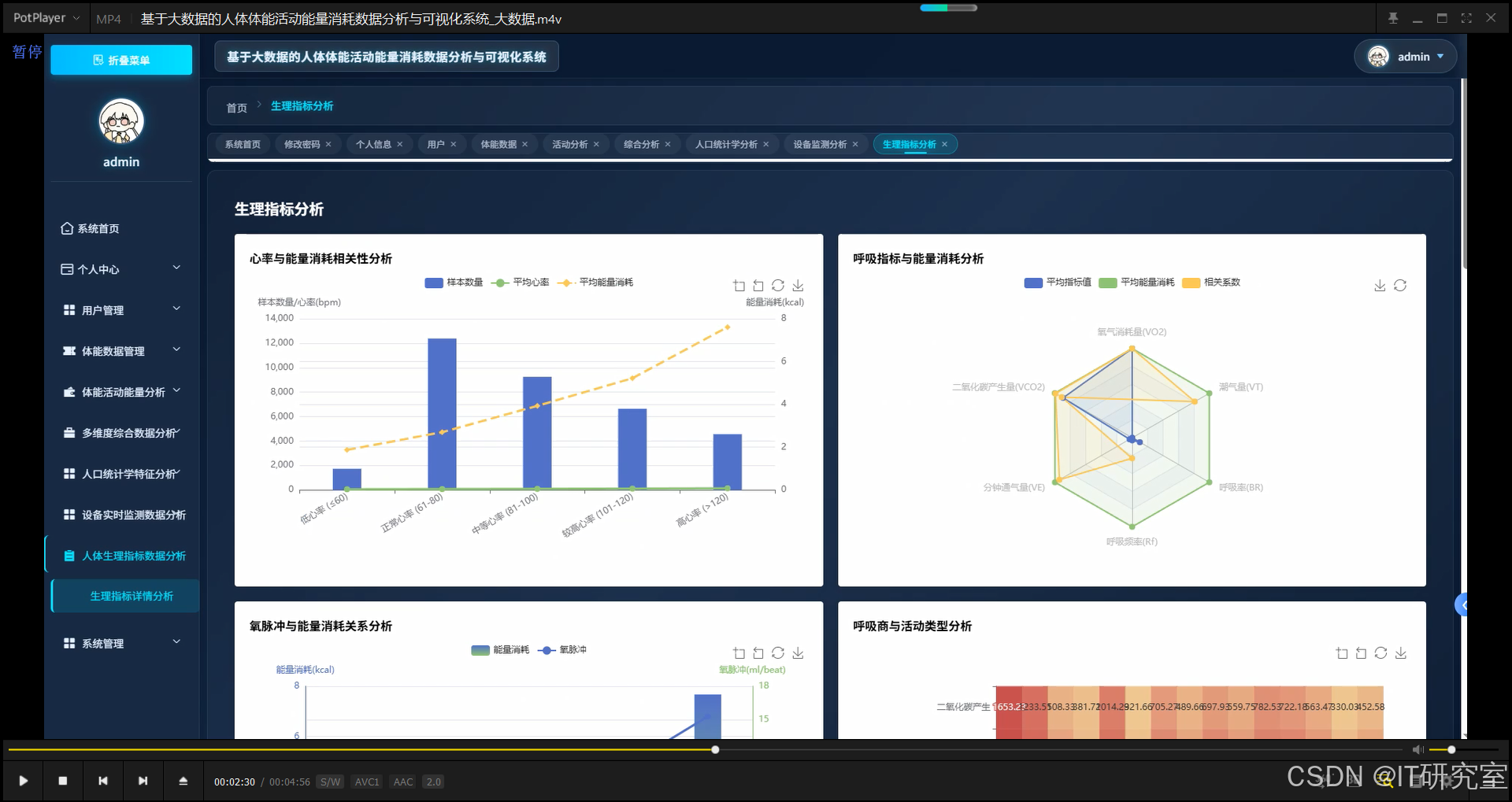
def analyze_physiological_energy_correlation(request):
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("hdfs://localhost:9000/data/EEHPA.csv")
df = df.filter(col("EEm").isNotNull() & col("HR").isNotNull() & col("VO2").isNotNull() & col("VCO2").isNotNull() & col("VE").isNotNull())
hr_correlation = df.select(corr("HR", "EEm").alias("hr_energy_corr"))
hr_energy_analysis = df.withColumn("hr_zone", when(col("HR") < 60, "低心率(<60)").when((col("HR") >= 60) & (col("HR") < 80), "正常心率(60-80)").when((col("HR") >= 80) & (col("HR") < 100), "中等心率(80-100)").when((col("HR") >= 100) & (col("HR") < 120), "较高心率(100-120)").otherwise("高心率(≥120)")).groupBy("hr_zone").agg(spark_round(avg("EEm"), 2).alias("avg_energy"), spark_round(avg("HR"), 2).alias("avg_heart_rate"), spark_round(avg("METS"), 2).alias("avg_mets"), count("*").alias("sample_count")).orderBy("hr_zone")
respiratory_correlations = df.select(corr("VO2", "EEm").alias("vo2_energy_corr"), corr("VCO2", "EEm").alias("vco2_energy_corr"), corr("VE", "EEm").alias("ve_energy_corr"), corr("R", "EEm").alias("r_energy_corr"))
vo2_hr_analysis = df.filter(col("VO2.HR").isNotNull()).select(corr("VO2.HR", "EEm").alias("vo2hr_energy_corr"), spark_round(avg("VO2.HR"), 2).alias("avg_vo2hr"))
respiratory_quotient_analysis = df.filter(col("R").isNotNull() & col("original_activity_labels").isNotNull()).groupBy("original_activity_labels").agg(spark_round(avg("R"), 3).alias("avg_respiratory_quotient"), spark_round(avg("EEm"), 2).alias("avg_energy"), count("*").alias("sample_count")).orderBy(col("avg_energy").desc())
cardiac_output_analysis = df.filter(col("Qt").isNotNull() & col("SV").isNotNull()).select(corr("Qt", "EEm").alias("qt_energy_corr"), corr("SV", "EEm").alias("sv_energy_corr"), spark_round(avg("Qt"), 2).alias("avg_qt"), spark_round(avg("SV"), 2).alias("avg_sv"))
ventilatory_efficiency = df.filter(col("VE.VO2").isNotNull() & col("VE.VCO2").isNotNull()).select(corr("VE.VO2", "EEm").alias("ve_vo2_corr"), corr("VE.VCO2", "EEm").alias("ve_vco2_corr"), spark_round(avg("VE.VO2"), 2).alias("avg_ve_vo2"), spark_round(avg("VE.VCO2"), 2).alias("avg_ve_vco2"))
physiological_features = df.select("HR", "VO2", "VCO2", "VE", "R", "VO2.HR", "EEm").toPandas()
correlation_matrix = physiological_features.corr()["EEm"].drop("EEm").to_dict()
result_data = {"hr_correlation": hr_correlation.toPandas().to_dict(orient='records')[0], "hr_zone_analysis": hr_energy_analysis.toPandas().to_dict(orient='records'), "respiratory_correlations": respiratory_correlations.toPandas().to_dict(orient='records')[0], "vo2hr_analysis": vo2_hr_analysis.toPandas().to_dict(orient='records')[0] if vo2_hr_analysis.count() > 0 else {}, "respiratory_quotient": respiratory_quotient_analysis.toPandas().to_dict(orient='records'), "cardiac_output": cardiac_output_analysis.toPandas().to_dict(orient='records')[0] if cardiac_output_analysis.count() > 0 else {}, "ventilatory_efficiency": ventilatory_efficiency.toPandas().to_dict(orient='records')[0] if ventilatory_efficiency.count() > 0 else {}, "feature_importance": correlation_matrix}
return JsonResponse({"status": "success", "data": result_data, "message": "生理指标与能量消耗关联分析完成"})五、系统视频
基于大数据的人体体能活动能量消耗数据分析与可视化系统项目视频:
大数据毕业设计选题推荐-基于大数据的人体体能活动能量消耗数据分析与可视化系统-大数据-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的人体体能活动能量消耗数据分析与可视化系统-大数据-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇