OCR 数据流转就是从"图像 → 文字 → 数据 → 应用"的流水线过程,核心目标是让图片里的信息自动化地进入业务系统,减少人工录入和传递。
OCR 数据流转,一般是指 光学字符识别(Optical Character Recognition, OCR)处理后的数据在系统或业务流程中的传递、加工、利用的全过程。
整个OCR数据流转通常包含以下六个核心阶段,如下图所示:
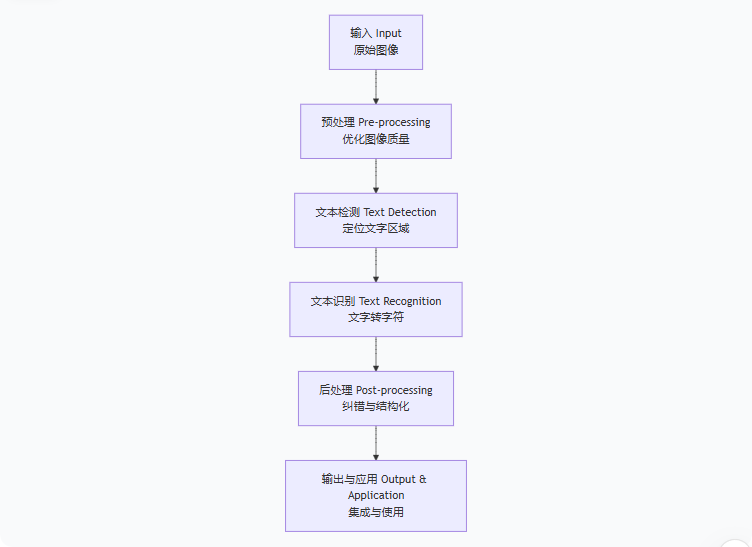
第一阶段:输入 (Input) - 获取原始图像
这是数据流的起点。原始图像可以通过多种方式获取:
-
扫描仪扫描:获取高分辨率、平整的文档图像,如合同、书籍。
-
手机/相机拍摄:便捷,但容易受到光照、角度、遮挡等因素影响,质量不稳定。
-
程序生成:直接接收PDF文件、截图或其他软件生成的图像。
-
网络爬虫抓取:从互联网上爬取得到的验证码、带有文字的网络图片等。
该阶段的数据形态 : JPG, PNG, PDF, TIF 等图像文件。
第二阶段:预处理 (Pre-processing) - 优化图像质量
这个阶段的目标是净化图像,消除噪音,为后续的识别步骤提供最清晰的"原料",极大提升识别准确率。关键技术包括:
-
灰度化/二值化:将彩色图像转为灰度图,或进一步转为只有黑白的二值图像,减少计算量。
-
噪声去除:消除图像上的斑点、杂色、划痕等。
-
倾斜校正:自动检测并矫正歪斜的文档。
-
透视矫正:将用手机拍摄的带有透视效果的文档(非正对拍摄)拉平为矩形。
-
对比度增强:调整亮度和对比度,使文字与背景分离更明显。
该阶段的数据形态 : 经过优化处理的图像矩阵数据。
第三阶段:文本检测 (Text Detection) - 定位文字区域
这个阶段的核心问题是 "文字在哪里?" 。系统需要在图像中找出所有包含文本的区域(文本框),并确定其位置和边界。主要技术:
-
传统方法:基于连通域分析、滑动窗口、手工设计特征等。
-
深度学习方法 :使用目标检测模型 (如YOLO, Faster R-CNN)或语义分割模型来精准定位文本行或单词级别的边界框(Bounding Box)。
该阶段的数据形态 : 一组坐标信息 ,例如 [x1, y1, x2, y2, ...],表示每个文本框的位置。
第四阶段:文本识别 (Text Recognition) - 文字转字符
在确定了文本位置后,这个阶段要回答 "这是什么文字?" 。系统将裁剪出的文本框图像转换为对应的字符编码(如UTF-8)。这是OCR的核心。
-
传统方法:模板匹配、特征提取+分类器等(现已较少使用)。
-
深度学习方法 :主流方法是使用CRNN(CNN+RNN+CTC) 模型。
-
CNN(卷积神经网络):提取图像特征。
-
RNN(循环神经网络):处理序列特征,捕捉字符间的上下文关系。
-
CTC(连接时序分类):将RNN的输出解码为最终的字符序列,无需预先分割字符。
-
-
基于注意力机制(Attention)的Seq2Seq模型:另一种主流方法,尤其擅长处理弯曲文本。
该阶段的数据形态 : 从图像块识别出的字符串 ,例如 "发票", "123.45元"。
第五阶段:后处理 (Post-processing) - 纠错与结构化
原始识别结果通常存在错误,且是零散的文本行。后处理旨在提升数据质量和可用性。
-
纠错:
-
基于词典:检查单词是否在预定义的词典中,如果不是,则用最相似的词典词替换(例如,"Go0d" -> "Good")。
-
基于语言模型:利用N-gram或神经网络语言模型,根据上下文语义纠正错误,例如"I loVe you" -> "I love you"。
-
-
结构化(关键信息抽取):
-
对于特定文档(如发票、身份证、名片),需要从识别出的文本中提取出关键字段。
-
通过自然语言处理(NLP) 、正则表达式 或基于模板的规则,将无结构的文本转换为结构化的数据。
-
示例 :从大段文字中识别出"日期:2023-10-27",并提取出键值对
{"Date": "2023-10-27"}。
-
该阶段的数据形态 : 从原始的识别文本 ["发票", "日期:", "2023-10-27"] 变为结构化的 JSON/XML/字典 或存入数据库的字段: {"document_type": "发票", "issue_date": "2023-10-27"}。
第六阶段:输出与应用 (Output & Application) - 集成与使用
这是数据流的终点,也是数据的价值体现。处理好的数据会被输送到各个下游系统或应用中。
-
输出格式:TXT文本、CSV表格、PDF可搜索文档、JSON/XML接口数据、直接写入数据库等。
-
应用场景:
-
办公自动化:将纸质文档电子化,便于存档和检索。
-
金融与财务:自动录入发票、报销单、银行流水,实现智能审核。
-
物流:自动识别面单上的寄送信息,实现分拣自动化。
-
身份认证:自动识别身份证、护照、驾驶证信息,快速完成实名认证。
-
移动应用:翻译软件中的即时翻译、扫描全能王等工具。
-
该阶段的数据形态 : 可供其他系统直接使用的业务数据。
总结
OCR数据流转是一个环环相扣的管道,每个阶段都承上启下。随着深度学习、尤其是多模态大模型(如GPT-4V)的发展,OCR的精度、特别是对复杂版面和手写体的理解能力正在飞速提升,这使得OCR数据流最终产出的结构化数据越来越准确和智能,成为连接物理世界与数字世界的重要桥梁。