前言 双层 OFD 作为我国自主文档标准,以 "图像层 + 文本层" 结构广泛应用于政务公文、电子归档、档案数字化等场景,兼具视觉还原与文本检索能力,适配国产化生态。与双层 PDF 相比,OFD 无国外专利依赖,安全合规性更强,中文排版还原更精准,文件体积小、解析效率高;而 PDF 存在格式兼容壁垒与数据安全风险,跨平台显示及中文排版易出偏差,OFD 已成为政企构建自主可控文档体系的优选。
图片转双层 OFD 开发中,OCR 识别后的字符坐标解析、字号反推及 TextCode 坐标精准定位,是影响文档还原精度的核心问题。我们依托 C# 技术栈形成成熟方案,可高效解决这一系列技术痛点。
转换后效果图,精准1:1匹配

技术实现步骤:
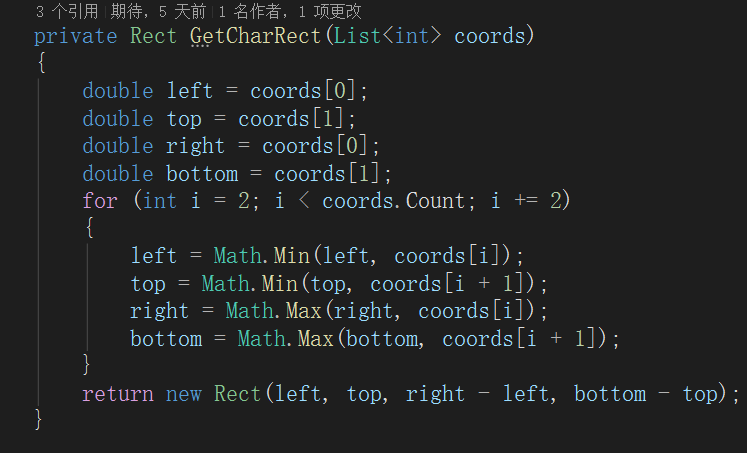
1 针对 OCR 输出的字符四点坐标,我们搭建了精准的几何计算模型:通过解析四点构成的字符包围盒,结合像素与物理尺寸的映射关系,先计算出字符实际显示尺寸;再基于不同字体(如宋体、黑体)的 fontsize 与字形大小的对应规则,反向推导符合 OFD 标准的字号参数,解决了不同字体、不同分辨率下字号匹配偏差的问题。
2 在 TextCode 坐标计算环节,我们深度结合 baseline(基线)特性,突破传统仅依赖包围盒中心定位的局限:以基线为参照基准,结合字符行高、字间距等参数,精准计算出 OFD 文档中 TextCode 的 x、y 坐标,确保还原后的文本位置与原图完全契合。
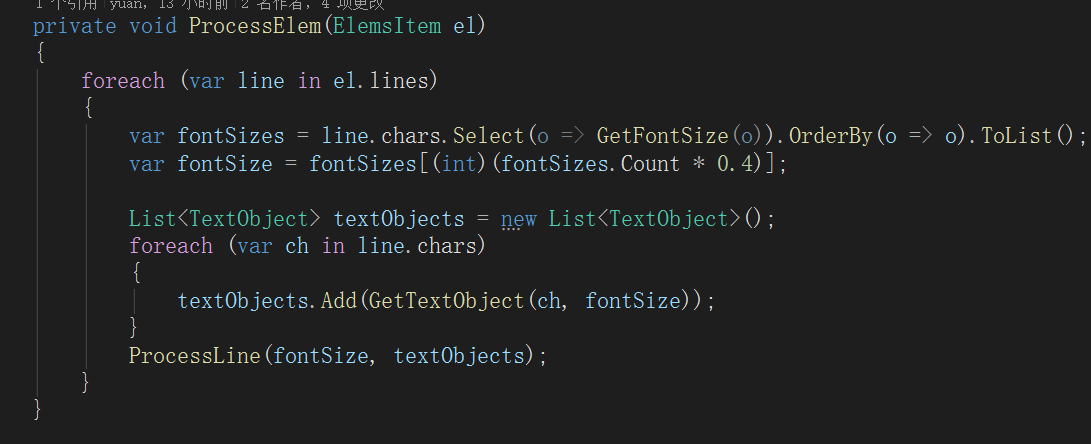
整套方案基于 C# 全栈开发,兼容主流 OCR 引擎(如 Tesseract、百度 OCR)的输出格式,可直接集成到双层 OFD 生成系统中。无论是扫描件数字化、公文 OFD 转换,还是批量文档处理场景,都能实现字符尺寸、坐标的精准解析与还原,解决了行业内常见的文本错位、字号不符等问题。
我们凭借对 OFD 格式规范、OCR 字符解析的深度理解,已为多家政企单位落地相关技术方案,大幅提升了双层 OFD 文档的生成精度与效率。若您有图片转双层 OFD 的技术需求,我们可提供定制化开发、技术对接等全流程服务,助力解决字符解析与文本定位的核心难题。