遗留系统,每个程序员都有话要说。这些老系统虽然能正常运行,甚至承载着公司的核心业务,但维护起来确实是个挑战------代码结构复杂,改个小功能都需要谨慎考虑。
我曾经接手过一个用Perl写的网站,已经运行了十几年,代码风格比较随意。虽然为公司创造了不少价值,但每次修改都需要格外小心,担心影响到其他功能。最后在微服务改造的趋势下,这个老系统完成了它的历史使命。
1. 实战案例:房产信息搜索平台改造
这里分享一个房产信息搜索平台的改造经历------300万行代码最后精简到50万行,这个过程有不少值得总结的经验。
1.1 改造前的系统状况
这个房产搜索平台是典型的遗留系统,存在多个问题:
代码规模庞大:300万行代码,包含房源管理、用户系统、搜索引擎、推荐算法、支付模块等各种功能,结构比较复杂。
技术栈陈旧:使用的框架版本较老,官方已停止维护,第三方库存在安全漏洞,安全扫描报告经常出现警告。
修改风险高:要修改功能时,需要先分析代码和各模块的关系,然后谨慎修改,避免影响其他功能。
性能瓶颈明显:搜索和用户管理共享资源,高峰期搜索响应慢,用户注册也会受影响,难以单独优化某个模块。
部署复杂:每次发版都需要整个系统重新部署,出问题时回滚时间较长,运维压力比较大。
1.2 改造目标与策略
面对这些问题,我们制定了几个改造目标:
提升开发效率 :将各个模块拆分,让不同团队可以独立开发和部署,减少相互等待
改善系统性能 :为不同模块配置合适的资源,搜索使用专用服务器和缓存,用户管理使用适合的配置
降低维护成本 :简化代码结构,删除冗余代码,让新同事能够快速理解系统
增强系统稳定性:实现服务隔离,一个服务出问题不影响其他服务,保证核心功能可用
1.3 改造实施过程
第一步:搜索服务拆分
搜索是这个平台的核心功能,用户主要是来找房子的,对响应速度要求很高。我们决定先把搜索功能从单体系统中拆分出来:
java
// 原始的搜索功能(简化版)
public class LegacySearchService {
public SearchResult search(SearchRequest request) {
// 用户权限验证
validateUser(request.getUserId());
// 搜索条件解析
SearchCriteria criteria = parseSearchCriteria(request);
// 数据库查询
List<Property> properties = queryDatabase(criteria);
// 结果排序和过滤
List<Property> filteredProperties = filterAndSort(properties, criteria);
// 构建返回结果
return buildSearchResult(filteredProperties);
}
}
java
// 拆分后的新搜索服务
@RestController
@RequestMapping("/api/search")
public class SearchController {
@Autowired
private SearchService searchService;
@Autowired
private UserServiceClient userServiceClient;
@PostMapping("/properties")
public ResponseEntity<SearchResponse> searchProperties(
@RequestBody SearchRequest request) {
try {
// 通过用户服务验证权限
UserValidationResponse validation =
userServiceClient.validateUser(request.getUserId());
if (!validation.isValid()) {
return ResponseEntity.status(HttpStatus.UNAUTHORIZED)
.body(SearchResponse.error("Invalid user"));
}
// 执行搜索
SearchResponse response = searchService.search(request);
return ResponseEntity.ok(response);
} catch (Exception e) {
logger.error("Search failed", e);
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(SearchResponse.error("Search service unavailable"));
}
}
}第二步:用户服务独立
用户管理模块相对独立,复杂度比搜索低一些,接下来对它进行拆分:
java
// 用户服务的实现
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public UserValidationResponse validateUser(Long userId) {
// 先从缓存查询
String cacheKey = "user:" + userId;
User cachedUser = (User) redisTemplate.opsForValue().get(cacheKey);
if (cachedUser != null) {
return UserValidationResponse.valid(cachedUser);
}
// 缓存未命中,查询数据库
Optional<User> userOpt = userRepository.findById(userId);
if (userOpt.isPresent()) {
User user = userOpt.get();
// 更新缓存
redisTemplate.opsForValue().set(cacheKey, user, Duration.ofMinutes(30));
return UserValidationResponse.valid(user);
} else {
return UserValidationResponse.invalid("User not found");
}
}
}第三步:数据同步机制
拆分服务相对容易,但数据同步是个关键问题。用户在一个服务中更新了信息,其他服务也需要及时获取最新数据,保证数据一致性:
java
// 数据同步服务
@Component
public class DataSyncService {
@Autowired
private RabbitTemplate rabbitTemplate;
@EventListener
public void handleUserUpdate(UserUpdateEvent event) {
// 发送用户更新消息
UserSyncMessage message = UserSyncMessage.builder()
.userId(event.getUserId())
.operation("UPDATE")
.timestamp(Instant.now())
.data(event.getUserData())
.build();
rabbitTemplate.convertAndSend("user.sync.exchange", "user.update", message);
}
@RabbitListener(queues = "search.user.sync.queue")
public void handleUserSyncMessage(UserSyncMessage message) {
try {
// 更新搜索服务中的用户信息缓存
searchCacheService.updateUserCache(message.getUserId(), message.getData());
logger.info("User cache updated for user: {}", message.getUserId());
} catch (Exception e) {
logger.error("Failed to sync user data", e);
// 发送到死信队列进行重试
throw new AmqpRejectAndDontRequeueException("Sync failed", e);
}
}
}1.4 改造成果
经过18个月的改造,取得了比较好的效果:
代码精简 :300万行代码减少到50万行,删除了大量重复和冗余代码
性能提升 :搜索响应时间从2秒优化到200毫秒,用户体验明显改善
部署效率 :发版频率从每月一次提升到每周多次,部署风险大幅降低
故障恢复 :故障修复时间从4小时缩短到30分钟,系统可用性提高
开发效率:新功能开发时间减少60%,团队生产力明显提升
1.5 关键经验总结
改造过程中积累了一些重要经验:
渐进式改造 :从相对独立且有价值的模块开始拆分,避免一次性大规模改动
数据同步重要性 :建立可靠的数据同步机制,这是微服务架构成功的关键
小步迭代 :采用小步快跑的方式,避免推倒重来的高风险做法
监控体系 :完善的监控体系是发现和解决问题的基础
团队协作:跨团队的紧密配合对改造成功至关重要
遗留系统改造确实需要谨慎规划,选择合适的策略和方法才能降低风险,取得理想效果。
2. 遗留系统特征分析
2.1 遗留系统的定义
遗留系统是指那些技术相对陈旧但仍在运行的系统------虽然年代久远,技术栈过时,但由于承载着重要业务,仍需要继续使用。就像一台使用多年的老设备,虽然性能不如新设备,但在关键时刻仍然发挥作用。
这些系统的共同特点是:设计时可能采用了当时的先进技术,但随着时间推移,现在看来已经比较落后。
2.2 遗留系统的主要问题
• 单体架构庞大 :系统规模不断增长,最终变成一个复杂的单体应用,修改风险很高
• 代码修改困难 :要修改功能时需要格外谨慎,担心影响其他模块,开发效率较低
• 维护成本高 :查找问题比较困难,运维复杂,监控工具难以集成
• 知识传承困难 :老员工离职后,新人难以快速理解系统架构和业务逻辑
• 测试覆盖不足:自动化测试较少,主要依靠人工测试,质量保证困难
这些问题会逐渐累积,最终影响整个团队的开发效率和系统稳定性。因此,适时进行系统改造是必要的。
2.3 遗留系统的具体问题
维护成本高
在大规模代码库中定位问题比较困难,就像在复杂的系统中寻找特定的组件。每次修改代码都需要谨慎分析影响范围,避免引发连锁反应。
技术债务累积
java
// 典型的遗留代码示例
public class OrderService {
// 一个方法包含了订单创建、库存检查、支付处理、邮件发送等所有逻辑
public void processOrder(Order order) {
// 500行代码...
// 各种if-else嵌套
// 硬编码的业务规则
// 没有异常处理
}
}扩展性限制
快速迭代比较困难,部署需要较长时间,可能影响业务连续性。这种情况下,系统的敏捷性受到很大限制。
2.4 推倒重来的风险
面对这些问题,很多团队会考虑完全重写系统。虽然这个想法很直接,但实际操作中存在很多风险。
需求变更难以应对
重写过程中,业务需求可能会持续变化。这时候要么暂停新需求(影响业务发展),要么同时维护新老系统(增加开发成本)。
影响范围复杂
老系统往往与多个其他系统有依赖关系,完全重写需要评估和处理大量的集成点,这个过程可能非常耗时。
知识传承困难
改造周期较长时,可能面临人员流动的问题,导致项目进度受影响,甚至出现知识断层。
因此,完全推倒重来虽然看起来简单直接,但实际风险很高。我们需要寻找更稳妥的改造方法。
3. 遗留系统改造策略
既然推倒重来风险较高,我们需要寻找更稳妥的改造方法。改造遗留系统就像给运行中的系统更换组件------既要保证系统正常运行,又要完成技术升级。虽然有一定挑战,但确实有成熟的方法可以参考。
根据实践经验,主要有几种比较可行的改造策略:
• 演进式改造 :渐进式拆分,避免大规模变动
• 绞杀者模式 :新老系统并存,逐步替换
• 挎斗模式:在现有系统基础上增加新功能
3.1 演进式改造
这种方法的核心思想是渐进式改进,避免大规模变动。就像分阶段完成一个大项目,每次只处理一小部分,逐步达到目标。
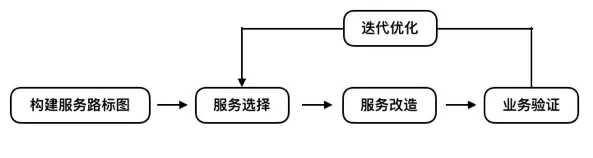
3.1.1 制定改造路线图
开始改造前,需要明确改造方向和目标架构。绘制服务架构图,规划各个服务及其关系。这个规划不需要一开始就很完美,可以在实施过程中不断完善。
java
// 分析现有系统的模块结构
// 电商系统示例
com.company.ecommerce
├── user // 用户管理
├── product // 商品管理
├── order // 订单处理
├── payment // 支付处理
├── inventory // 库存管理
└── notification // 消息通知3.1.2 选择改造起点
制定路线图后,需要选择合适的改造起点。建议优先考虑以下类型的模块:
• 相对独立的模块 :与其他模块耦合度较低的,改造风险小,成功率高
• 变更频繁的模块 :这些模块拆分后可以独立部署,能够快速体现改造价值
• 资源消耗大的模块:计算密集型任务拆分后可以单独优化,性能提升明显
3.1.3 实施改造
选定目标模块后开始具体实施。这个过程中需要重点关注两个问题:
• 数据处理 :新老系统的数据结构可能不同,需要建立数据同步机制
• 安全拆分:采用渐进式拆分,确保系统稳定性
具体的实施方法会根据不同场景有所差异,后续会详细介绍几种常见情况。
3.1.4 验证和优化
新服务上线后,需要持续监控一段时间,确保功能正常、性能达标后,再清理老系统中的相关代码。这个过程类似于系统迁移,需要确保新系统稳定运行后再完全切换。
3.1.5 迭代改造
完成一个模块的改造后,继续下一个模块。通过多轮迭代,逐步完成整个系统的改造。这是一个持续的过程,需要耐心和坚持。
3.2 绞杀者模式
这种模式采用渐进式替换的方法,通过在新老系统之间建立中间层,逐步将流量从老系统迁移到新系统。这个概念最初来源于"抽象分支"的软件重构方法:
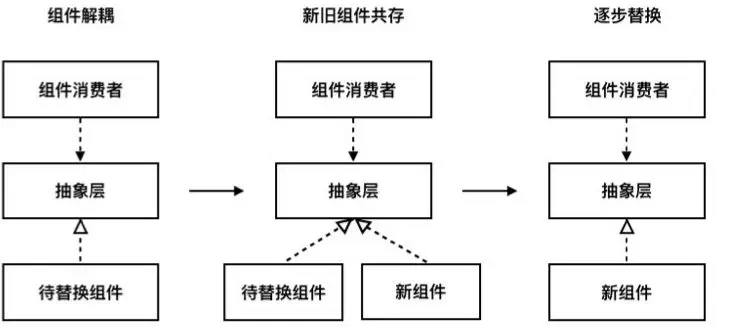
建立中间层:在老组件和调用方之间增加一个抽象层,实现解耦。
新老并存:新组件和老组件同时运行,新组件初期只处理少量请求,用于验证功能。
逐步替换:随着新组件稳定性提升,逐渐增加其承担的流量,最终完全替代老组件。老组件下线后,中间层也可以移除。
在微服务改造中,这个中间层通常是一个独立的网关服务,负责根据规则将请求路由到新系统或老系统。
改造过程中,新老系统并行运行,共同提供服务。随着改造进展,新系统承担的功能和流量逐渐增加,最终完全替代老系统。当老系统完全下线后,网关服务也可以简化或移除。
这种平滑过渡的方法称为"绞杀者模式",老系统被逐步"绞杀"的过程如下图所示:
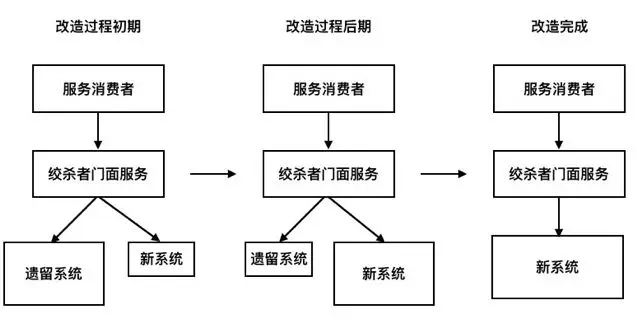
绞杀者模式特别适合改造复杂的大型遗留系统,但实施时需要注意几个关键点:
• 数据同步机制 :确保新老系统的数据保持一致,避免数据不一致问题
• 网关性能:网关服务不能成为性能瓶颈或单点故障
3.2.1 实现方法
绞杀者模式的核心是API网关,它充当智能路由器的角色,根据预设规则决定每个请求的目标系统。
主要组件:
• API网关 :所有请求的"门卫",负责分流
• 路由规则 :定义什么请求走新系统,什么请求还走老系统
• 监控日志 :盯着迁移进度和系统状态
• 紧急回滚:出问题了能快速切回老系统
java
// 网关路由配置示例
@RestController
public class GatewayController {
@Autowired
private LegacySystemClient legacyClient;
@Autowired
private NewUserService newUserService;
@Autowired
private RoutingService routingService;
@GetMapping("/api/users/{id}")
public User getUser(@PathVariable Long id) {
// 根据路由规则决定调用哪个系统
if (routingService.shouldUseNewSystem("user", id)) {
return newUserService.getUser(id);
} else {
return legacyClient.getUser(id);
}
}
}
// 路由规则服务
@Service
public class RoutingService {
@Value("${routing.new-system.percentage:10}")
private int newSystemPercentage;
@Value("${routing.new-system.user-ids:}")
private Set<Long> newSystemUserIds;
public boolean shouldUseNewSystem(String feature, Long userId) {
// 白名单用户优先使用新系统
if (newSystemUserIds.contains(userId)) {
return true;
}
// 按百分比分流
return userId % 100 < newSystemPercentage;
}
}```
#### 3.2.2 流量切换策略
流量切换需要采用渐进式策略,确保系统稳定性。常见的切换方式包括:
**按功能切换**:优先迁移简单功能,复杂功能后续处理。
```java
@Service
public class FeatureBasedRouting {
private Set<String> migratedFeatures = Set.of("user-profile", "user-settings");
public boolean shouldUseNewSystem(String feature) {
return migratedFeatures.contains(feature);
}
}按用户切换:选择特定用户群体作为新系统的早期使用者。
java
@Service
public class UserBasedRouting {
@Autowired
private UserService userService;
public boolean shouldUseNewSystem(Long userId) {
User user = userService.getUser(userId);
// 内部员工或VIP用户使用新系统
return user.isEmployee() || user.isVip();
}
}按比例切换:逐步增加新系统承担的流量比例。
java
@Service
public class PercentageBasedRouting {
@Value("${routing.new-system.percentage:0}")
private int percentage;
public boolean shouldUseNewSystem(String requestId) {
// 根据请求ID的哈希值决定
return Math.abs(requestId.hashCode()) % 100 < percentage;
}
// 动态调整流量比例
public void updateTrafficPercentage(int newPercentage) {
this.percentage = Math.min(100, Math.max(0, newPercentage));
}
}
yaml
# 配置文件示例
traffic:
routing:
user-service:
new-system-percentage: 10 # 新系统承担10%流量
canary-users: [1001, 1002] # 金丝雀用户
order-service:
new-system-percentage: 0 # 订单服务暂不切换3.3 挎斗模式
挎斗模式类似摩托车挎斗的结构,新服务与老系统并行工作,各自承担不同职责,通过协作提供完整的功能。
3.3.1 基本思路
在老系统旁边部署新服务,通过通信方式配合工作,为整个系统增加新能力。
协作方式:
• 并行运行 :新服务和老系统同时运行,互不干扰
• 功能补强 :新服务提供老系统缺失的功能,或优化现有功能
• 数据同步 :通过消息队列、API等方式保持数据一致性
• 渐进接管:随着新服务稳定性提升,可以承担更多职责
挎斗模式的优势在于风险可控,可以快速验证新技术和新想法,同时保证老系统稳定运行。
3.3.2 适用场景
这种模式特别适合以下场景:
• 功能扩展 :老系统难以修改时,通过新服务增加功能
• 数据分析和报表 :老系统专注业务处理,新服务负责数据分析
• 性能优化:新服务作为缓存层或计算层,提升整体性能
3.3.3 实现示例
java
// 老系统的订单服务
@Service
public class LegacyOrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private MessagePublisher messagePublisher;
public Order createOrder(OrderRequest request) {
// 创建订单的核心逻辑
Order order = new Order();
order.setUserId(request.getUserId());
order.setAmount(request.getAmount());
order.setStatus("CREATED");
Order savedOrder = orderRepository.save(order);
// 发布订单创建事件,让新服务知道
messagePublisher.publish("order.created", savedOrder);
return savedOrder;
}
}
// 新的推荐服务(挎斗)
@Service
public class RecommendationService {
@Autowired
private UserBehaviorRepository behaviorRepository;
@Autowired
private RecommendationEngine engine;
@EventListener
public void handleOrderCreated(OrderCreatedEvent event) {
// 记录用户行为
UserBehavior behavior = new UserBehavior();
behavior.setUserId(event.getUserId());
behavior.setAction("ORDER_CREATED");
behavior.setProductId(event.getProductId());
behaviorRepository.save(behavior);
// 更新推荐算法
engine.updateUserProfile(event.getUserId());
}
public List<Product> getRecommendations(Long userId) {
return engine.recommend(userId);
}
}4. 实战场景分析
实际改造过程中会遇到各种情况,每种都有不同的挑战。根据新老业务的关系,主要有这几种典型场景:
4.1 新业务独立运行
这是最理想的情况。新功能与老业务在数据层面基本独立,可以完全独立开发和部署。
新业务拥有独立的数据库,无需修改老系统数据结构,风险最小,成功率最高。
4.1.1 常见应用场景
• 用户反馈系统 :为电商平台增加评价功能
• 推荐引擎 :为内容平台增加"猜你喜欢"功能
• 消息通知系统 :增加邮件、短信发送功能
• 数据分析平台:增加报表和数据分析功能
4.1.2 实施策略
完全独立部署:新业务按照微服务标准构建,拥有独立的数据库、API接口、部署环境。
标准化接口对接:通过REST API或消息队列与老系统进行必要的数据交换。
渐进式上线:采用灰度发布策略,先向小部分用户开放,验证稳定性后再全量发布。
4.1.3 实战案例:积分系统集成
java
// 独立的积分服务
@RestController
@RequestMapping("/api/points")
public class PointsController {
@Autowired
private PointsService pointsService;
@PostMapping("/earn")
public ResponseEntity<PointsResponse> earnPoints(
@RequestBody EarnPointsRequest request) {
// 新业务逻辑,完全独立实现
PointsResponse response = pointsService.earnPoints(
request.getUserId(),
request.getAmount(),
request.getSource()
);
return ResponseEntity.ok(response);
}
}
java
// 遗留系统通过HTTP客户端调用新服务
public class LegacyOrderService {
private PointsServiceClient pointsClient;
public void completeOrder(Order order) {
// 保持原有的订单处理逻辑不变
processOrderInLegacyWay(order);
// 异步调用新的积分服务,避免影响主流程
CompletableFuture.runAsync(() -> {
try {
pointsClient.earnPoints(order.getUserId(),
order.getAmount() * 0.01, "ORDER_COMPLETE");
} catch (Exception e) {
// 记录异常日志,不影响订单主流程
logger.error("Failed to earn points", e);
}
});
}
}4.2 新业务需要读取老数据
这种情况相对复杂,新服务需要访问老系统的数据才能正常工作。由于新老系统的技术栈和数据格式可能存在差异,需要建立有效的数据访问机制。
4.2.1 典型应用场景
• 个性化推荐 :推荐服务需要读取用户的历史行为数据
• 数据报表 :报表系统需要汇总各个模块的业务数据
• 用户画像:用户分析服务需要整合多个系统的用户数据
4.2.2 主要技术挑战
数据格式不匹配 :老系统的数据结构可能不适合新业务需求
性能影响 :直接访问老数据库可能影响原有业务性能
数据一致性:如何保证读取到的数据是最新且准确的
4.2.3 解决方案
数据同步机制 :建立ETL流程,将老系统数据定期同步到新服务数据库
API封装层 :为老系统提供标准化API接口,新服务通过API访问数据
缓存优化:使用Redis等缓存技术,减少对老系统的直接访问
4.2.4 实战案例:用户数据同步
java
// 数据同步服务实现
@Component
public class UserDataSyncService {
@Autowired
private LegacyUserRepository legacyRepo;
@Autowired
private NewUserRepository newRepo;
@Autowired
private MessageQueue messageQueue;
// 监听遗留系统的数据变更事件
@EventListener
public void handleLegacyUserUpdate(UserUpdateEvent event) {
try {
// 从遗留系统获取最新用户数据
LegacyUser legacyUser = legacyRepo.findById(event.getUserId());
// 转换为新系统的数据格式
NewUser newUser = convertToNewFormat(legacyUser);
// 同步数据到新系统
newRepo.save(newUser);
// 发送同步成功通知
messageQueue.send(new UserSyncSuccessEvent(event.getUserId()));
} catch (Exception e) {
// 同步失败处理:记录日志并安排重试
logger.error("User sync failed for user: " + event.getUserId(), e);
scheduleRetry(event);
}
}
private NewUser convertToNewFormat(LegacyUser legacyUser) {
return NewUser.builder()
.id(legacyUser.getId())
.username(legacyUser.getUsername())
.email(legacyUser.getEmail())
.createdAt(legacyUser.getCreateTime())
.build();
}
}4.2.5 数据一致性保障
java
// 双写策略确保数据一致性
@Service
@Transactional
public class UserService {
public void updateUser(Long userId, UserUpdateRequest request) {
try {
// 1. 优先更新遗留系统(作为主数据源)
legacyUserService.updateUser(userId, request);
// 2. 同步更新新系统(作为从数据源)
newUserService.updateUser(userId, request);
} catch (Exception e) {
// 新系统更新失败时,记录补偿任务
compensationTaskService.scheduleUserSync(userId);
throw e;
}
}
}4.3 业务模块拆分重构
这是最具挑战性但也最有价值的改造方式。需要将老系统中的某个业务模块完整拆分出来,构建为独立的微服务。成功实施后,系统的可维护性和扩展性将显著提升。
4.3.1 典型拆分场景
• 用户管理模块 :将注册、登录、权限管理等功能独立部署
• 订单处理系统 :将订单创建、支付、物流跟踪等拆分为独立服务
• 商品管理:将商品信息、库存管理、价格策略等功能独立运行
4.3.2 主要技术难点
业务边界划分 :如何准确识别业务模块边界,避免过度拆分或拆分不足
数据迁移 :需要将相关数据从老系统安全迁移到新服务
事务处理复杂化 :原本单一事务需要改为分布式事务处理
依赖关系梳理:需要清晰理解与其他模块的依赖关系
4.3.3 实施步骤
深度业务分析 :全面分析目标业务模块的功能、数据结构、依赖关系
新架构设计 :设计新的微服务架构,包括API接口、数据模型等
并行开发 :在不影响现有业务的前提下开发新服务
渐进式切换 :采用绞杀者模式逐步将流量从老系统迁移到新服务
系统清理:确认新服务稳定运行后,清理老系统中的相关代码和数据
4.3.4 实战案例:订单服务拆分
java
// 原遗留系统中的订单处理逻辑(简化版)
public class LegacyOrderProcessor {
public void processOrder(OrderRequest request) {
// 1. 用户身份验证
validateUser(request.getUserId());
// 2. 库存可用性检查
checkInventory(request.getItems());
// 3. 订单金额计算
BigDecimal totalPrice = calculatePrice(request.getItems());
// 4. 订单记录创建
Order order = createOrder(request, totalPrice);
// 5. 库存数量扣减
reduceInventory(request.getItems());
// 6. 支付流程处理
processPayment(order);
// 7. 通知消息发送
sendNotification(order);
}
}
java
// 拆分后的新订单服务实现
@Service
public class NewOrderService {
@Autowired
private UserServiceClient userService;
@Autowired
private InventoryServiceClient inventoryService;
@Autowired
private PaymentServiceClient paymentService;
@Autowired
private NotificationServiceClient notificationService;
public OrderResponse processOrder(OrderRequest request) {
try {
// 1. 用户身份验证(调用用户服务)
UserValidationResponse userValidation =
userService.validateUser(request.getUserId());
if (!userValidation.isValid()) {
throw new InvalidUserException("Invalid user");
}
// 2. 库存可用性检查(调用库存服务)
InventoryCheckResponse inventoryCheck =
inventoryService.checkAvailability(request.getItems());
if (!inventoryCheck.isAvailable()) {
throw new InsufficientInventoryException("Insufficient inventory");
}
// 3. 订单记录创建
Order order = Order.builder()
.userId(request.getUserId())
.items(request.getItems())
.totalPrice(inventoryCheck.getTotalPrice())
.status(OrderStatus.PENDING)
.createdAt(Instant.now())
.build();
order = orderRepository.save(order);
// 4. 异步处理后续业务流程
processOrderAsync(order);
return OrderResponse.builder()
.orderId(order.getId())
.status(order.getStatus())
.message("Order created successfully")
.build();
} catch (Exception e) {
logger.error("Order processing failed", e);
throw new OrderProcessingException("Failed to process order", e);
}
}
@Async
private void processOrderAsync(Order order) {
try {
// 库存数量扣减
inventoryService.reduceInventory(order.getItems());
// 支付流程处理
PaymentResponse payment = paymentService.processPayment(
order.getId(), order.getTotalPrice());
if (payment.isSuccess()) {
order.setStatus(OrderStatus.PAID);
orderRepository.save(order);
// 发送订单确认通知
notificationService.sendOrderConfirmation(order);
} else {
// 支付失败时恢复库存
inventoryService.restoreInventory(order.getItems());
order.setStatus(OrderStatus.FAILED);
orderRepository.save(order);
}
} catch (Exception e) {
logger.error("Async order processing failed for order: " + order.getId(), e);
// 触发补偿处理机制
compensationService.handleOrderFailure(order);
}
}
}5. 总结与建议
遗留系统改造是一项既需要技术深度又需要耐心坚持的工程。没有万能的解决方案,只有通过持续的努力和实践才能取得成功。
5.1 关键成功要素
从简单场景开始 :优先选择风险较低的模块进行改造,积累经验和建立信心
采用渐进式策略 :避免大规模重构,通过小步迭代的方式稳步推进
建立完善监控 :没有监控就无法及时发现问题,监控体系是改造成功的基础
重视团队协作:改造工作需要跨团队密切配合,良好的沟通协作至关重要
5.2 风险控制建议
• 制定详细的回滚计划 :确保在出现问题时能够快速恢复
• 建立数据备份机制 :在数据迁移过程中做好充分的备份准备
• 进行充分的测试验证 :包括功能测试、性能测试、兼容性测试等
• 保持业务连续性:改造过程中确保核心业务不受影响
参考:https://servicecomb.apache.org/cn/docs/how-to-reform-a-legacy-system/