
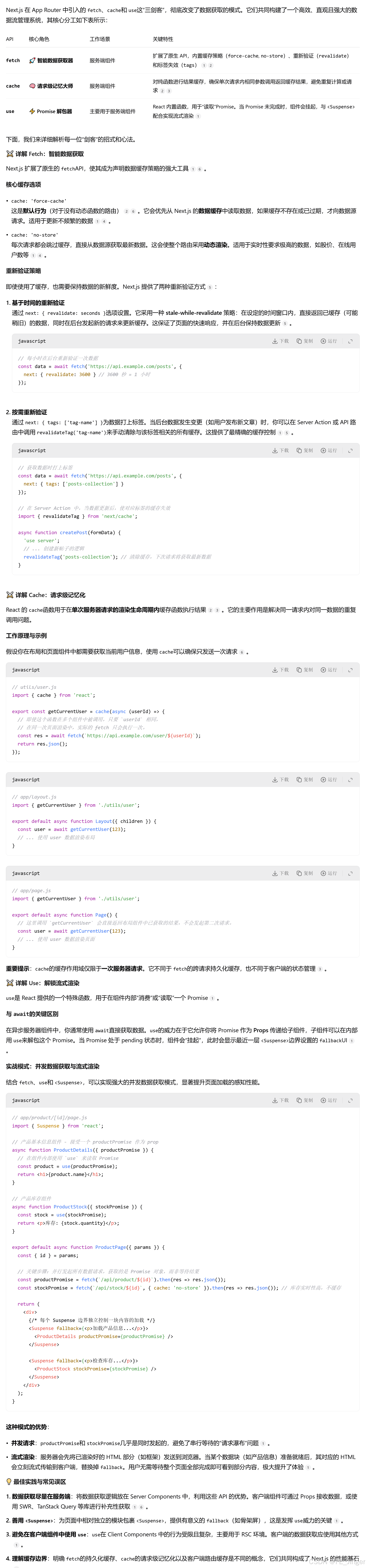
Next.js 数据获取方式的演变,深刻反映了现代前端框架对于性能、开发者体验和渲染模式的持续探索。其核心脉络是从"页面级"的渲染策略,走向更细粒度、更集成的"组件级"数据获取。下面这张表格清晰地勾勒出了这一演进历程的主要阶段和特点。
| 发展阶段 | 核心架构 | 主要数据获取方法 | 关键特性 | 主要优势 |
|---|---|---|---|---|
| 早期 Pages Router | 基于页面的路由 | getServerSideProps, getStaticProps, getInitialProps |
页面级渲染、混合渲染 | 概念清晰,SEO友好,支持多种渲染模式 |
| 现代 App Router | 基于服务器组件 (RSC) | 组件内 fetch、cache()、use() |
组件级数据获取、请求去重、集成缓存 | 更优性能,更少客户端JS,更佳开发者体验 |
| 未来方向 | 并发渲染与边缘计算 | 流式渲染、部分预渲染 (PPR) | 更快的初始加载,动态静态内容混合 | 极致性能,更优用户体验 |
接下来,我们将深入每个阶段,探究其背后的设计逻辑与实现细节。
🔮 Pages Router:基于页面的数据获取
Next.js 早期版本的核心思想是页面级渲染。数据获取与页面路由紧密绑定,通过特定的生命周期函数来实现。
-
核心方法
getStaticProps(静态生成, SSG):在构建时运行,获取的数据将用于生成静态HTML文件。适用于内容相对固定的页面,如博客、文档、营销页面,能带来极致的加载速度和缓存体验。getServerSideProps(服务端渲染, SSR) :在每次页面请求时运行,在服务器端获取数据并生成HTML。适用于数据高度动态或个性化的页面,如实时仪表盘、用户个人页面,确保每次返回的都是最新数据。getStaticPaths(静态路径) :为动态路由页面(如pages/posts/[id].js)指定在构建时需要预生成哪些路径的静态页面。
-
演进与优化:增量静态再生 (ISR)
ISR 是 Next.js 一个重要的创新,它允许在构建后更新或创建静态页面 。你可以为静态页面设置一个重新验证时间(
revalidate),在时间过期后,首次请求会触发在后台重新生成页面,后续请求继续使用新的静态页面。这完美结合了 SSG 的性能和 SSR 的动态性。 -
局限性
Pages Router 的模型虽然清晰,但随着应用复杂度的提升,也暴露出一些限制:
- 数据获取与组件分离 :数据获取逻辑(
getServerSideProps等)和页面组件定义在不同的函数中,尤其是在需要复杂数据传递时,组织代码会变得繁琐。 - "请求瀑布"问题:在同一页面内,如果多个数据获取函数存在依赖关系,必须串行执行,会延长页面整体响应时间。
- 布局与数据获取耦合:难以在布局(Layout)层面进行数据获取并传递给子页面,限制了布局的复用能力。
- 数据获取与组件分离 :数据获取逻辑(
请求瀑布:它指的是在页面加载过程中,多个本可独立发起的API调用或数据获取请求,由于设计或代码结构的原因,像瀑布一样依次串行执行,而非并行执行。后一个请求必须等待前一个请求完成后才能开始,导致不必要的等待时间累积,页面渲染被延迟
解决:
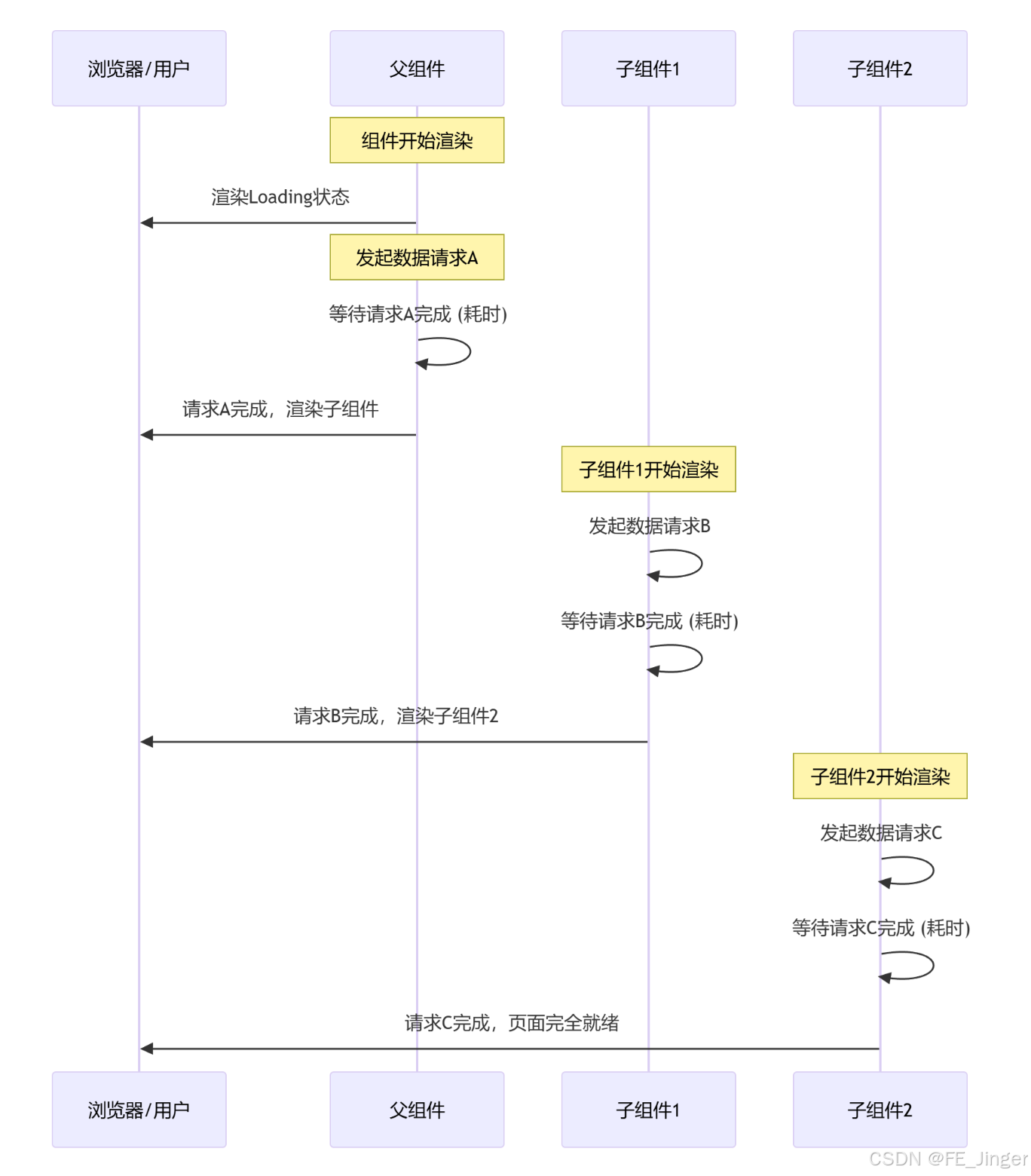
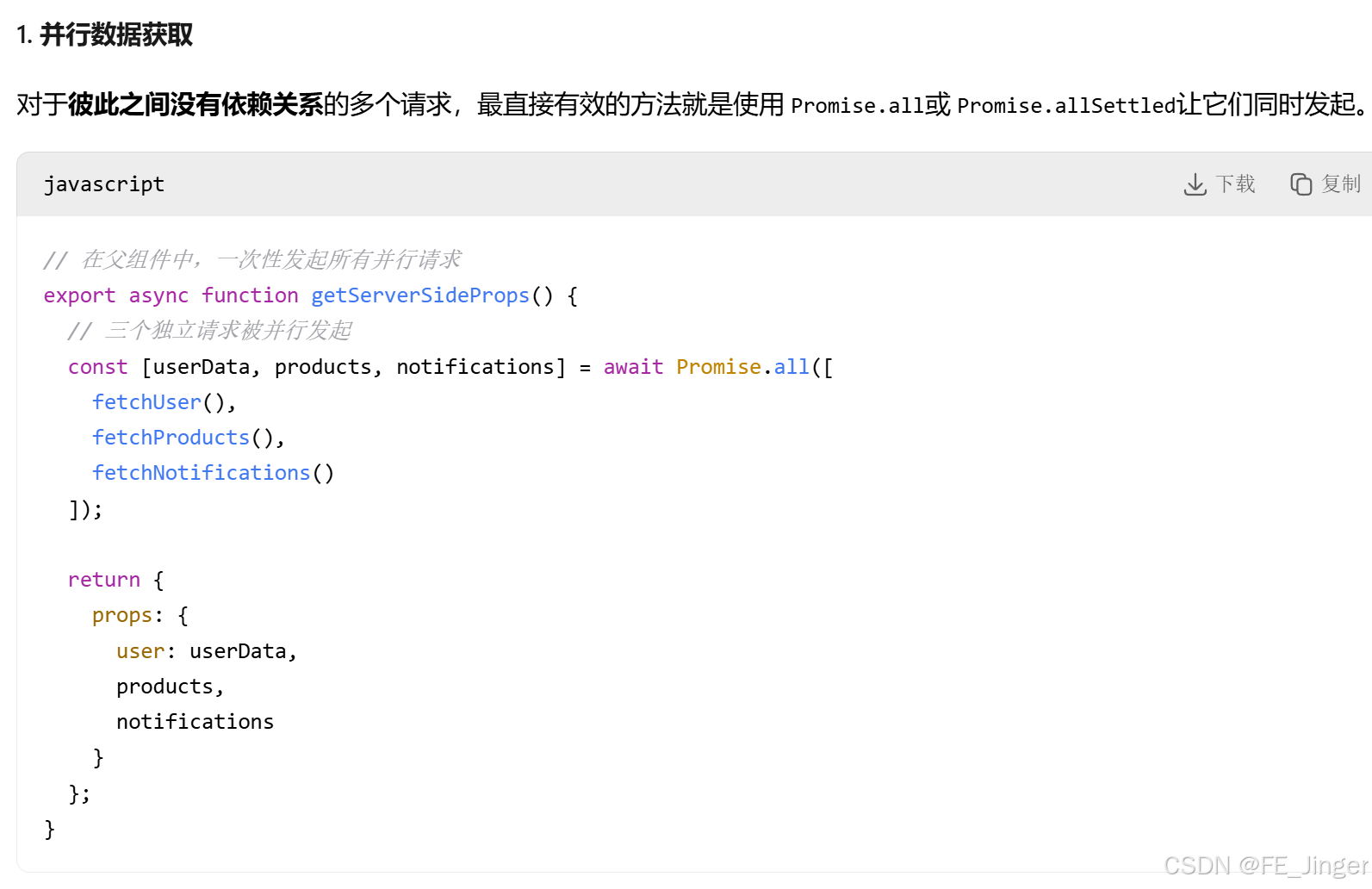


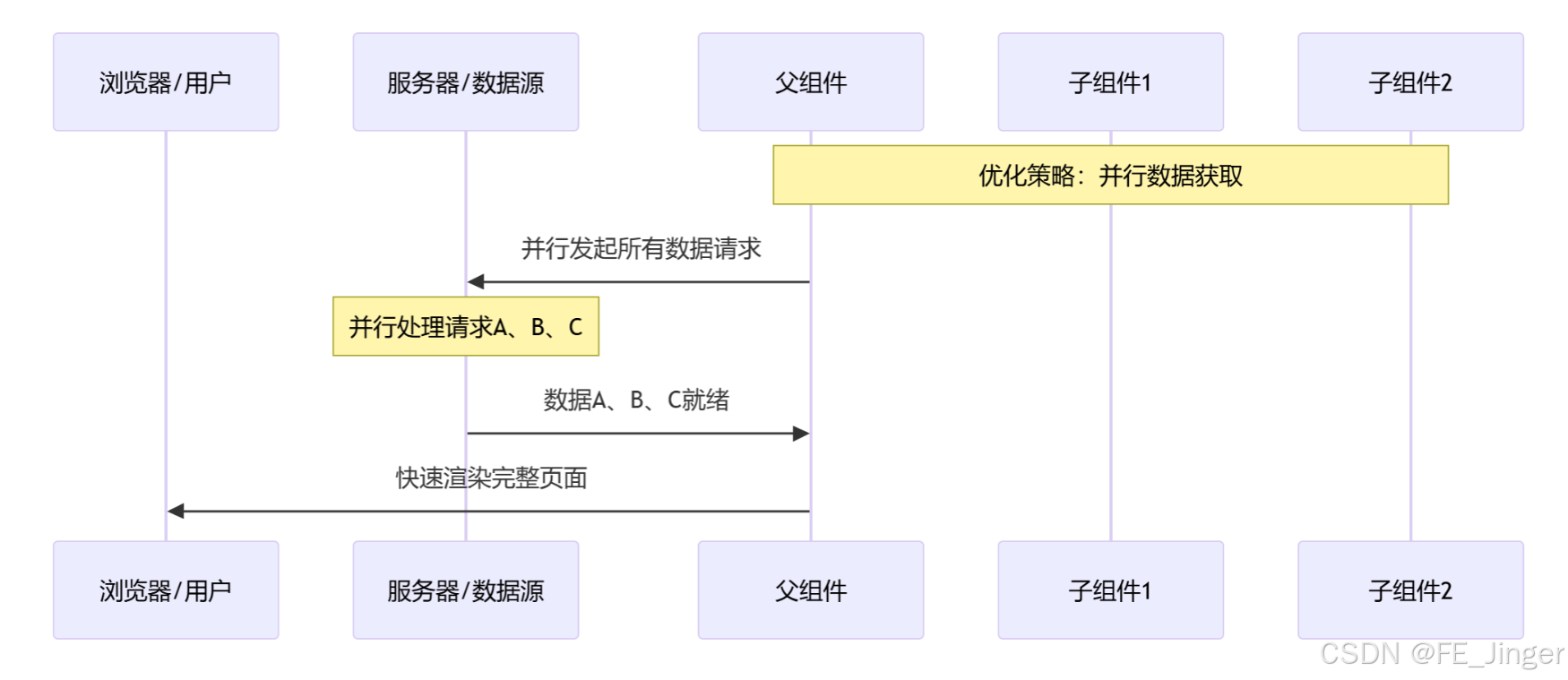
⚡ App Router:组件级的数据获取革命
Next.js 13 引入的 App Router 是基于 React 服务端组件 的范式转移。数据获取的核心变成了一个简单的原则:在服务器组件中,直接使用异步函数获取数据。
-
核心变革:
服务器组件与异步组件在
app/目录下,React 组件默认是服务器组件,它们可以直接是async函数。你可以在组件内部直接使用await获取数据,使数据获取逻辑与 UI 逻辑更紧密地结合在一起,代码更直观。javascript// app/products/page.js async function ProductsPage() { // 直接在服务器组件内获取数据 const res = await fetch('https://api.example.com/products'); const products = await res.json(); return ( <ul> {products.map((product) => ( <li key={product.id}>{product.name}</li> ))} </ul> ); } -
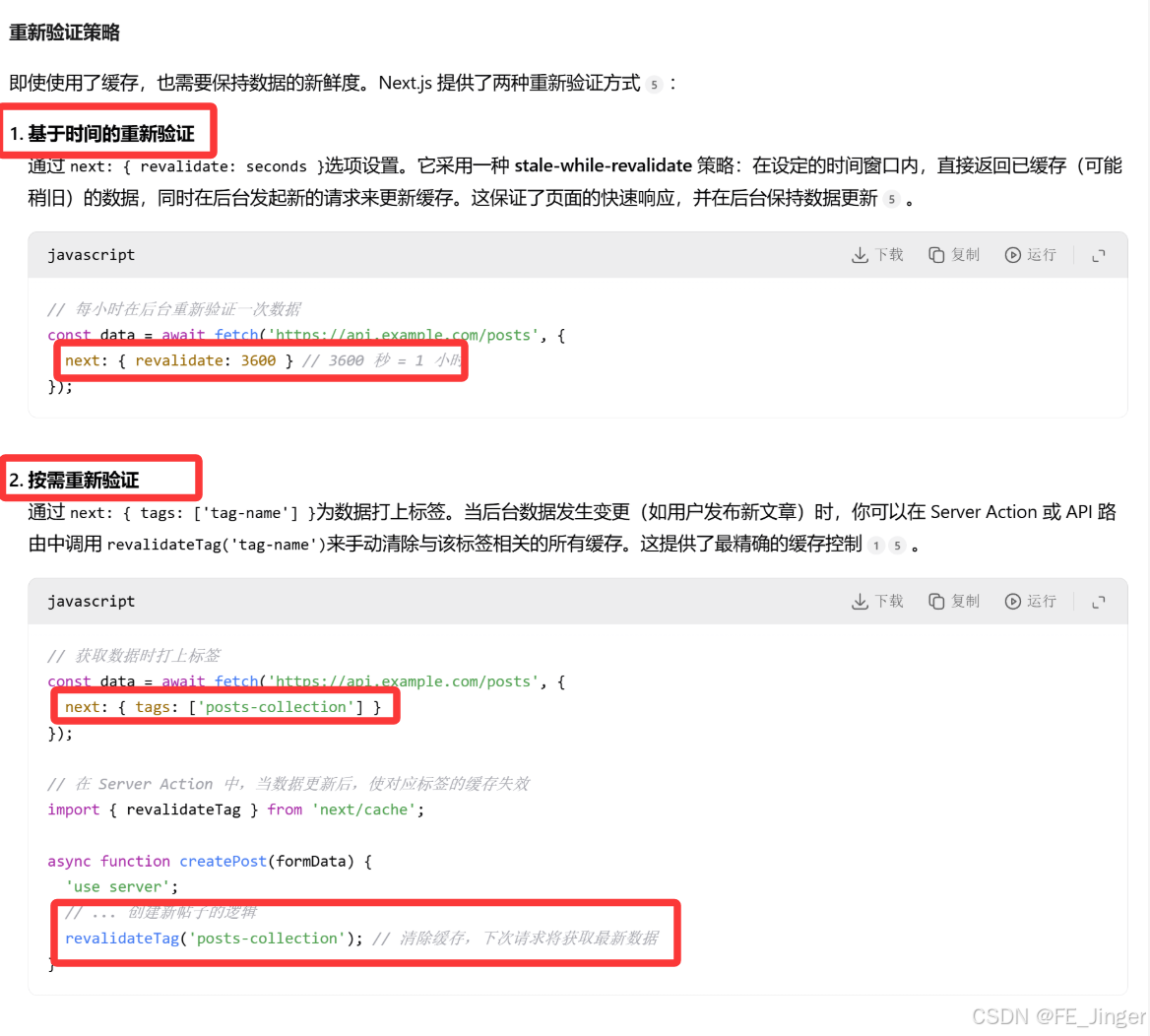
增强的 Fetch API 与缓存机制Next.js 扩展了原生的
fetchAPI,为其赋予了强大的缓存和重新验证能力,成为数据获取的基石。- 自动缓存(默认) :相同的
fetch请求在构建和请求时会被自动去重和缓存。 - 数据缓存:获取的数据会被持久化到文件系统中,跨部署持久化,极大提升性能。
- 灵活的缓存控制 :
{ cache: 'force-cache' }: 强制缓存(默认行为)。{ cache: 'no-store' }: 完全动态,不缓存,每次都会重新获取。{ next: { revalidate: 60 } }:设置 ISR,指定缓存多少秒后失效。
- 自动缓存(默认) :相同的
-
新"三剑客":
fetch,cache,useApp Router 提供了更精细的数据处理工具。
fetch:作为数据获取的主力,集成了缓存语义。cache:一个 React 函数,用于手动包装任何函数(如数据库查询),对其结果进行缓存,避免相同参数的重复计算。use:一个特殊的 React 函数,用于在组件内"消费" Promise。结合<Suspense>,可以实现组件级的流式渲染,允许页面的不同部分在数据准备好时逐步显示,极大优化了用户感知的加载速度。
🚀 演变背后的逻辑与最佳实践
-
性能优化演进
从页面到组件:缓存和渲染的粒度从整个页面细化到单个组件和数据请求。从全量到流式:支持逐步渲染,优先显示已有内容。减少客户端负担:服务端组件逻辑不发送至客户端,减小了 JavaScript 包体积。
-
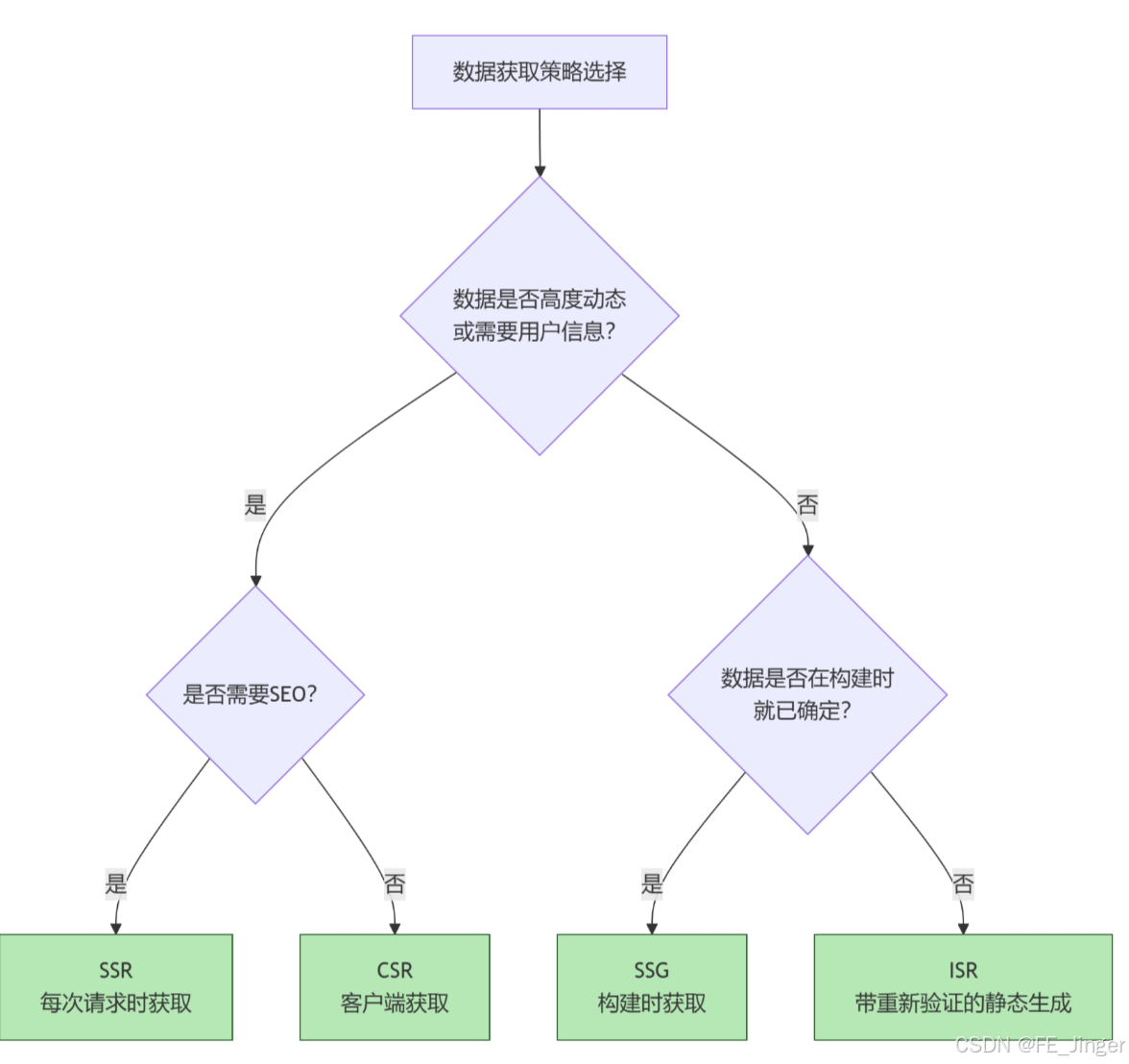
如何选择数据获取方法?
以下流程图可以帮助你根据应用场景做出决策:
-
实用建议
- 新项目 :强烈推荐从 App Router 开始,以利用最新的性能和开发体验优势。
- 现有项目迁移 :无需重写,可渐进采用。Next.js 允许
pages和app目录共存。 - 牢记边界 :明确组件的服务端/客户端边界(
'use client')。交互性强的部分用客户端组件,数据获取和静态内容优先用服务端组件。 - 善用缓存 :根据数据的实时性要求,为
fetch配置合适的cache和revalidate选项。
💎 总结
Next.js 数据获取的演变,是从关注渲染时机 走向关注数据本身的过程。App Router 和服务器组件通过更原生、更声明式的方式将数据获取集成到组件树中,通过精细的缓存和流式渲染,为实现最佳性能和开发体验铺平了道路。