2025年9月,Arm发布了其最新的处理器架构。今年,Arm抛弃了原有的X系列和A系列命名规则,采用了新的的命名规则,叫C1系列,包括了C1-Ultra、C1-Premium、C1-Pro、C1-Nano等产品。名称上感觉更像手机的命名系列,并且微架构新全新升级到了Armv9.3-A。此外,今年的GPU的新架构叫做GPU Mali G1。
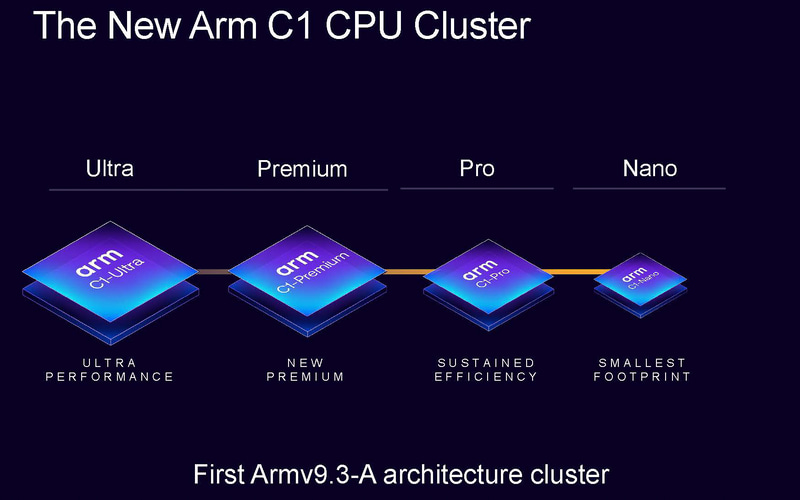

除了微架构的名称变化,Arm还为每个目标市场都创建了完整的品牌名称:
- Neoverse 用于服务器
- Zena 用于汽车
- Lumex 用于移动设备
- Niva 用于个人电脑
- Orbis 用于物联网
值得一提是有一个新的PC品牌Niva,推测对Windows有更好的支持。除了Qualcomm's Snapdragon X 系列处理器,我们有望看到更多的Arm处理器运行Windows系统。

今年用于手机处理器的C1系列和G1系列则属于Lumex套件,全称叫做Arm Lumex CSS Platform。那么Lumex里面都包含什么?根据Arm的资料,Lunux包含CPU、GPU、System等IP设计,还包含了3nm等工艺节点的物理实现,以及一些生态的支持,例如Pre-silicon的平台指导、安卓16支持、SME2的应用等等,可以帮助芯片厂商更快的完成芯片设计。

Arm期望通过CSS套件将这些IP以套装打包起来售卖以提升产品竞争力,提升整体性价比,提升对客户的吸引力,从而提升Arm的销售额。打个比方,这就类似麦当劳更喜欢卖套餐,而不是单卖汉堡。
我们用一个表格,直观的展示这5年来Arm微架构演进迭代的情况
|----------------|---------------|-----------------|-----------------|-----------------|-------------|
| 平台 | Lumex CSS 平台 | 客户 CSS | TCS23 | TCS22 | TCS21 |
| 发布年份 | 2025 | 2024 | 2023 | 2022 | 2021 |
| CPU指令集 | Armv9.3-A | Armv9.2-A | Armv9.2-A | Armv9-A | Armv9-A |
| 扩展指令(SVE/SVE2) | ○ | ○ | ○ | ○ | ○ |
| 扩展指令(SME2) | ○ | - | - | - | - |
| CPU Prime 核心 | C1-Ultra | Cortex-X925 | Cortex-X4 | Cortex-X3 | Cortex-X2 |
| CPU次级核心 | C1-Premium | - | - | - | - |
| CPU高性能核心 | C1-Pro | Cortex-A725 | Cortex-A720 | Cortex-A715 | Cortex-A710 |
| CPU高效核心 | C1-Nano | Cortex-A520 | Cortex-A520 | Cortex-A510 | Cortex-A510 |
| DSU | C1-DSU | DSU-120 | DSU-120 | DSU-110 | DSU-110 |
| GPU (最高配置) | Mali G1-Ultra | Immortalis-G925 | Immortalis-G720 | Immortalis-G715 | Mali-G10 |
| 工艺 | 3纳米 | 3纳米 | 4纳米 | 4纳米 | 5纳米 |
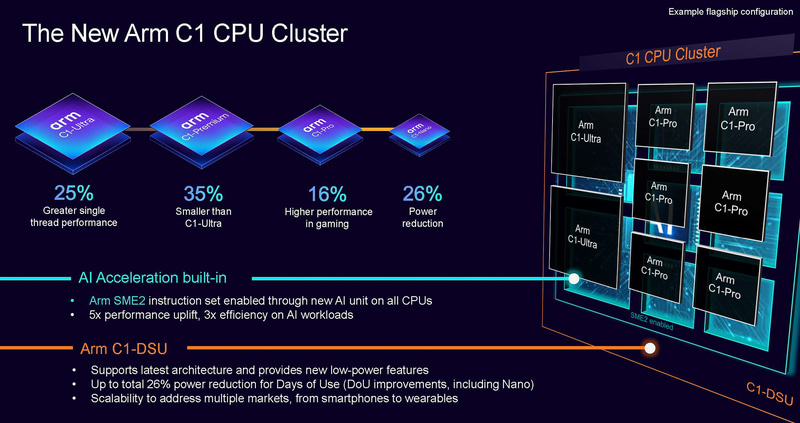
上面这张图包含了今年新C1架构的核心参数指标参数的变化,后面我们会看具体的变化。
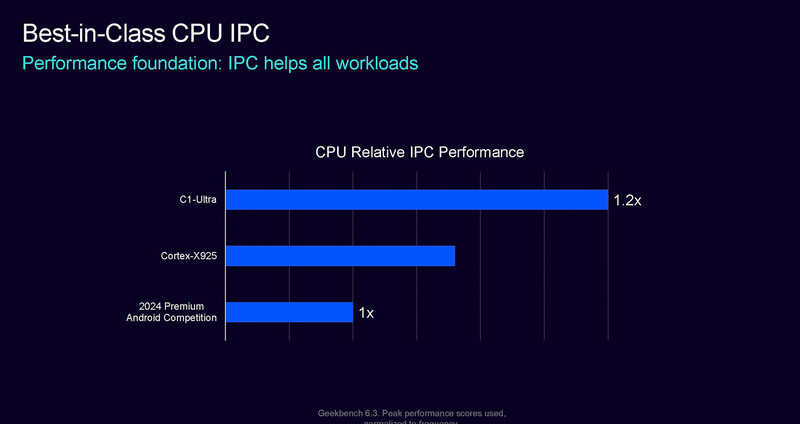
首先看一下C-Ultra相比上一代X925的性能提升。C1-Ultra的IPC性能,从Arm给出的数据看,比上一代的X925要提升12%左右,前期有预测过C1-Ultra可能会采用12路decoder设计,现在看来应该没有用12路这么激进,不然性能应该能有20%以上的提升。图中下面2024年的安卓旗舰竞品,应该是指用了X4核心的处理器8Gen3处理器。
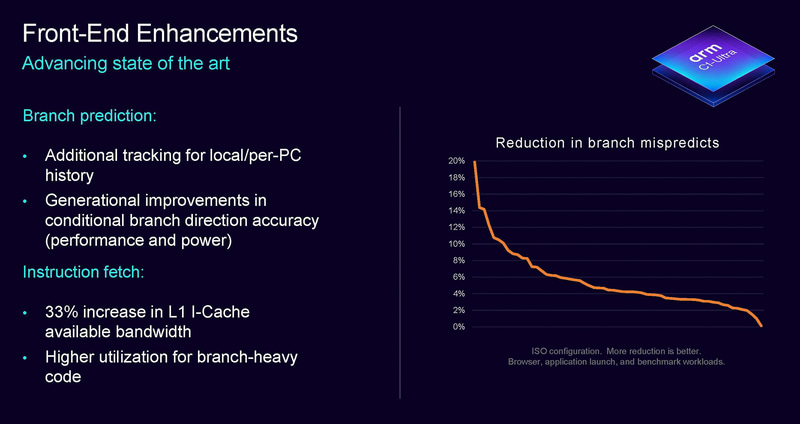
在前端设计上,C1-Ultra和上一代X925的核心参数decoder宽度,ALU数量,FPU数量等基本相同。C1-Ultra主要优化是提升分支预测性能,增加记录预测历史的空间,从而提升分支预测的准确性,对性能和功耗都有帮助。此外,一个明显的变化是,L1指令缓存的带宽提升了33%,以实现更快的指令获取速度。
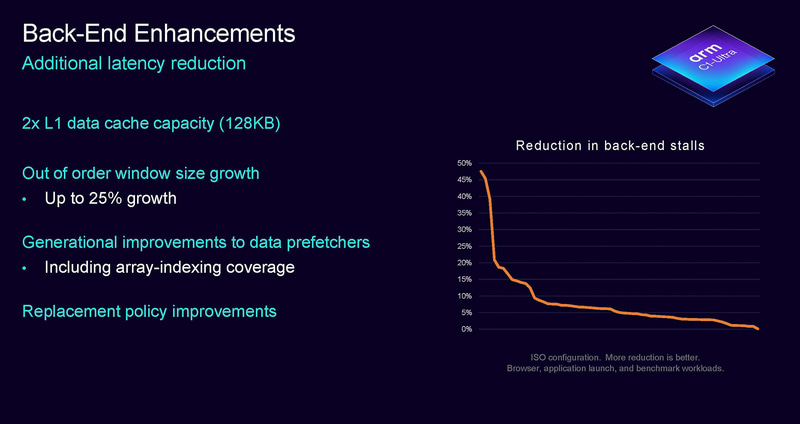
在后端设计上,C1-Ultra的L1数据缓存容量从64KB提升到128KB,这个大小要超出高通Oryon的96KB,可惜L1指令缓存还是大小还是64KB,不如Oryon的192KB。这也是多年来Arm第一次在旗舰核心上增加L1缓存的容量。
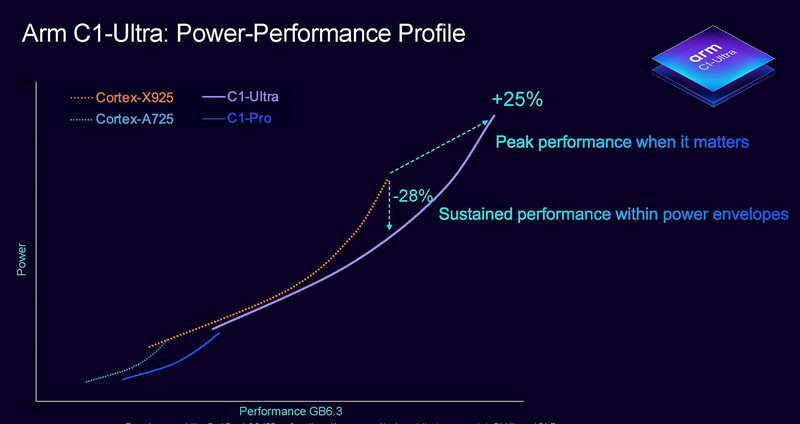
性能和功耗指标上,C1-Ultra比X925,峰值性能提升了25%,同性能下功耗则降低了28%,在工艺没有变化,都是3nm的情况下,性能的提升主要通过优化微架构和提升频率。至于功耗,需要注意C1-Ultra的极限功耗是增加的,但是得益于微架构的优化和缓存的提升,原来X925极限性能的高能效区间在这一代同性能频率可以跑的更低。在C1-Ultra的使用上,建议多使用这段高能效的区间,以达到最经济的能效使用。
下面用一个表格总结了Arm旗舰核心在过去六年里的发展变化:
|-----------------|-----------|-------------|---------------|-----------|-----------|-----------|
| Prime 核心 | C1-Ultra | Cortex-X925 | Cortex-X4 | Cortex-X3 | Cortex-X2 | Cortex-X1 |
| 年份 | 2025 | 2024 | 2023 | 2022 | 2021 | 2020 |
| 指令集 | Armv9.3-A | Armv9.2-A | Armv9.2-A | Armv9-A | Armv9-A | Armv8.3-A |
| 扩展指令(SVE/SVE2) | ○ | ○ | ○ | ○ | ○ | - |
| 扩展指令(SME2) | ○ | - | - | - | - | - |
| 目标频率 | 4.1GHz或更高 | 3.6GHz或更高 | 3.3GHz | 3.2GHz | 3GHz | 3GHz |
| decode宽度 | 10 | 10 | 10 | 6 | 5 | 5 |
| Dispatch/ Cycle | 10 | 10 | 10 | 8 | 8 | 8 |
| ALU | 8 | 8 | 8 | 6 | 4 | 4 |
| FP/SIMD | 6 | 6 | 4 | 4 | 4 | 4 |
| L1数据 | 128KB | 64KB | 64KB | 64KB | 64KB | 64KB |
| L1命令 | 64KB | 64KB | 64KB | 64KB | 64KB | 64KB |
| L2 | 2MB/3MB | 2MB/3MB | 512KB/1MB/2MB | 512KB/1MB | 512KB/1MB | 512KB/1MB |
| L3 | 0~32MB | 0~32MB | 0~32MB | 0~16MB | 0~16MB | 0~16MB |
在这几年中,变化最大的演进是2023年的Cortex-X4,其decoder宽度从6路提升到10路,ALU也从6个增加到8个,性能提升明显,典型处理器代表是MTK的天玑9300和高通的骁龙8Gen3处理器。

再来看一下C1-Premium,面积比C1-Ultra减少35%,主要是减少了矢量单元和L2缓存,并优化了物理实现。如果说是减少了FPU,推测其性能和X4的差不多。今年的天玑9500信息提到了一颗Travis和三颗Alto,应该是一颗超大C1-Ultra加三颗C-Premium来实现。

C1-Pro是高性能大核心,相比上一代游戏性能提升了16%,正统A725的继承者。A725的能效相当不错,也期待C1-Pro在今年处理器的表现,天玑9500剩余的4颗Gales,应该是C1-Pro。
C1-Nano是功耗核心,A520的下一代,功耗降低26%,性能稍弱,应该还是三路decoder的非乱序执行,在高端处理器中已经见不到身影,主要用于中低端处理器,可以做小芯片面积。
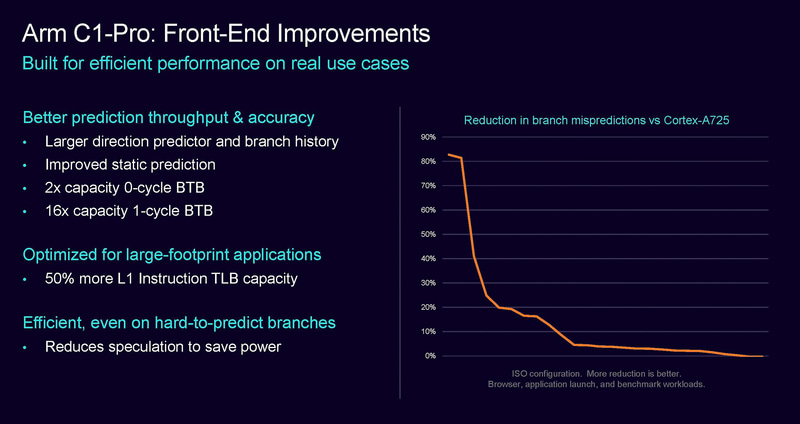
C1-Pro在前端设计上重点优化了分支预测的吞吐率和准确性,L1指令的TLB容量提升了50%,并且降低了分支预期的功耗。
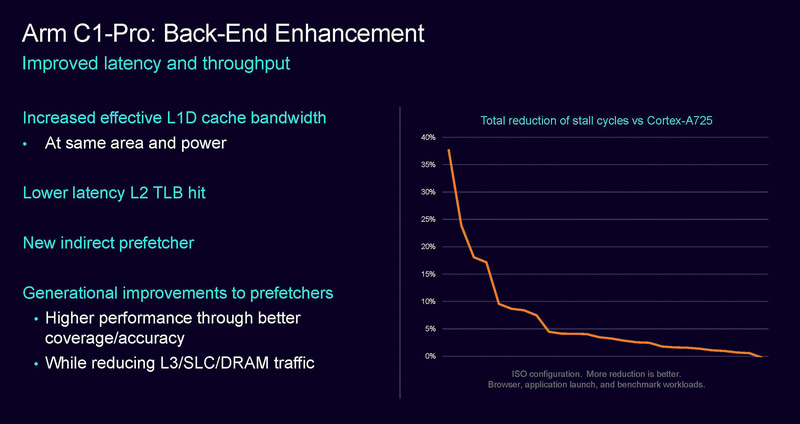
C1-Pro在后端上提升了数据L1缓存的带宽,优化L2的TLB延迟,新增了间接预期器,提升预取的性能和减少L3到SLC和内存的数据拥塞。
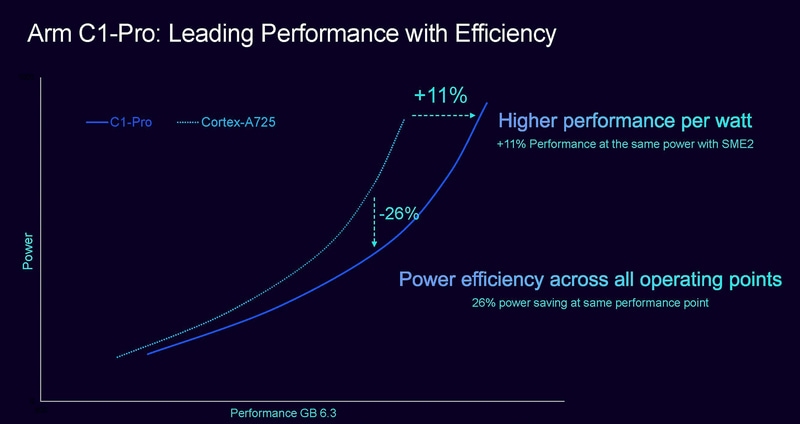
性能功耗上,C1-Pro相比A725,峰值功耗差异不大的情况下,性能提升了11%,相同性能下功耗则降低了26%。A725已经是一颗能效优秀的大核心处理器,从这个数据看非常期待C1-Pro的市场表现。

下面我们来看一下C1-Nano核心,这也是一颗Armv9.3-A架构的处理器。Arm宣称C1-Nano相比A520提升了26%的效能,并有效减少L3到内存的拥塞。性能上,在不到2%的核心面积增加下(小核心很在意核心面积),性能可以提升5.5%。还通过解耦预测和取指流水线,提升了指令预取的性能。

DSU是连接多个处理器核心的关键模块,这一代的新DSU命名为C1-DSU。这一代的C1-DSU,Arm宣称功耗可以节省11%,Quick Nap内存(L3支持的功能)功耗可以降低7%。
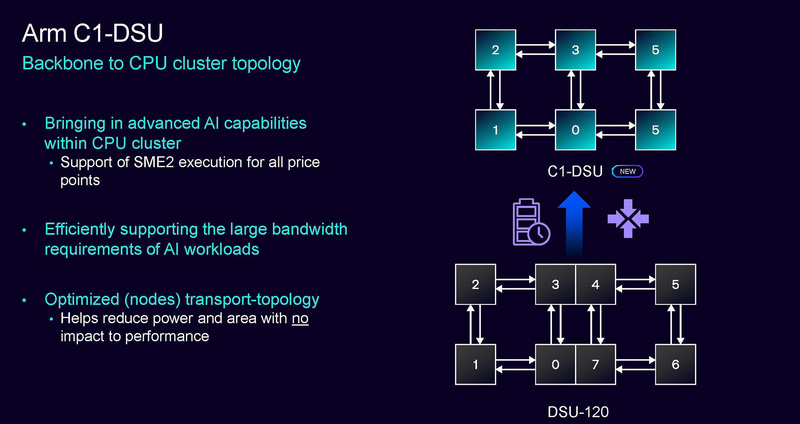
新一代的C1-DSU相比DS120,调整了CPU连接的拓扑结构,提供优秀的AI能力支持,支持新的SME2扩展指令集,并且在不影响性能的情况下降低了功耗和面积。

C1-DSU还更新了L3的Quick Nap支持。Quick Nap是系统在进入低功耗状态前,L3缓存会标记高频率访问的数据(如进程上下文),在唤醒时通过硬件级数据预取功能(如SME2),直接从L3恢复关键数据,降低系统延迟。C1-DSU通过把L3缓存进行切片,只需唤醒需要数据所在的区片,进一步降低了系统延迟和功耗。
下面是一个L3 Quick Nap和传统深度休眠的数据对比:
|--------|--------------|----------|
| 特性 | L3 Quick Nap | 传统深度休眠 |
| 唤醒延迟 | <10μs | 50-100μs |
| 功耗 | 中等(依赖负载) | 极低 |
| 适用场景 | 高频间歇任务 | 长期待机 |

和上一代一样,C1-DSU最多可以支持14个处理器核心的组合,并且可以实现不同C1处理器的组合,除了最初级的2核心配置,其余都可以支持SME2。
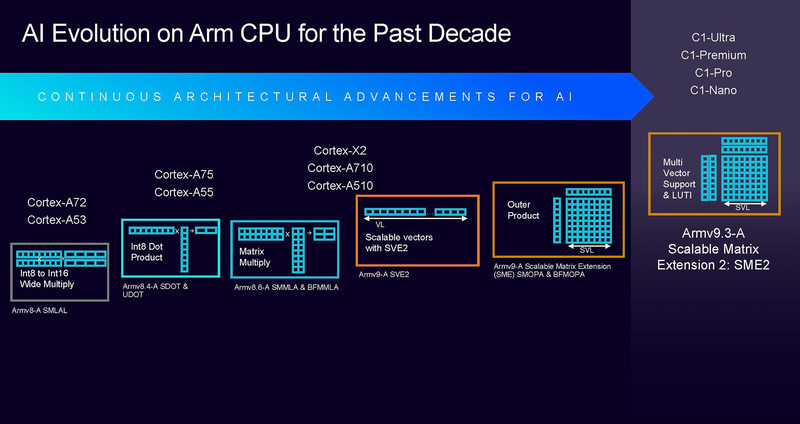
2025年新Arm架构的一个特征就是采用了新的Armv9.3-A指令集,并且支持SME2扩展指令集,我们来看一下SME2的特点。
SME(Scalable Matrix Extension,可扩展矩阵扩展)是Armv9架构引入的指令集,虽然SME指令集在2021年就提出了,但是Arm的Cortex-X系列处理器从X925才开始支持第一代的SME指令集,苹果公司的M4处理器和今年的A19处理器也支持第一代的SME指令集,最新的高通的8 Elite 2处理器也可以支持SME指令集。今年的Arm C1系列则全面升级到了SME2指令集。
|-------------|------|--------------|
| 芯片 | 支持版本 | 关键特性 |
| Cortex-X925 | SME | 3nm |
| C1-Ultra | SME2 | 3nm |
| 骁龙8 Elite 2 | SME | 3nm,5GHz主频 |
| 苹果M4 | SME | 3nm,48%单核提升 |
| 苹果A19 | SME | 3nm,第三代N3P工艺 |

SME2是第二代SME指令集,Arm宣称其专为加速AI/ML工作负载设计,通过矩阵运算优化提升能效比。相比SME,SME2引入了多矢量指令和动态去量化等技术,可以显著提升矩阵运算效率。SME2采用可变长度寄存器架构(128-2048位),支持流式SVE模式和高吞吐量矩阵数据处理。

在性能表现上,Arm宣称SME2对性能上有显著帮助,例如在AI任务中,SME2可使CPU集群的AI性能提升5倍,同时实现了3倍的能效提升。由于AI类计算需要调用非常多的矩阵计算,因此SME2在AI类应用中尤为有效。
在开发上,SME2对开发者也会非常友好,Arm宣称,很多应用程序开发都集成了Arm的开发套件KleidAI来辅助执行AI处理,在这种情况下,用户只要讲KleidiAI更新到支持SME2的版本即可。另外。多数情况,用户只需要修改少量代码,即可实现兼容,同时也支持C语言用内联函数intrinsics预言开发。
在应用场景上,SME2可以广泛应用在端侧AI,大模型推理,智能助手,计算机视觉等场景。
总结
如果不想看前面的文章,可以快速跳转到这一部分。这次的总结部分用简洁整理,让大家可以快速了解今年Arm的处理器升级点。
- 2025年Arm处理器采用新的架构命名体系,CPU新架构叫做C1系列,GPU新架构叫做G1,手机处理器平台套件叫做Lumex。
- CPU家族包含C1-Ultra、C1-Premium、C1-Pro、C1-Nano四款产品。
- C1-Ultra对标原来的Cortex-X系列,峰值性能提升25%,IPC性能提升12%,同性能下功耗降低28%。
- C1-Premium是新出的次旗舰核心,面积比C1-Ultra小35%,性能参考Cortex-X4。
- C1-Pro是A725的升级,峰值功耗差异不大的情况下,性能提升了11%,相同性能下功耗则降低了26%。
- C1-Nano是A520的升级,相比A520提升了26%的效能。
- C1-DSU是DSU120的升级,功耗可以节省11%,提供优秀的AI能力支持,支持新的SME2扩展指令集。
- C1家族全新支持SME2扩展指令集,全面面向AI矩阵运算优化性能和功耗,在AI任务中,SME2可使CPU集群的AI性能提升5倍,同时实现了3倍的能效提升。
虽然2025年Arm的发布会姗姗来迟,但是一口气发布的这么多款产品也是可圈可点的,整体也有比较明显的提升,让我们期待今年搭载最新Arm C1家族处理器的旗舰芯片的体验!

