炒股为什么要找箱体?
在量化选股、趋势策略里,"箱体"是一个常见但简单有效的结构模型。箱体意味着价格在一定区间内来回震荡,有明确的支撑和阻力,这对于捕捉突破、做区间震荡交易、止盈止损都很有帮助。
传统上,我们常靠人工目测或滑窗高低点极值来画箱体。但这方式主观性强、不易批量化。若把箱体识别流程自动化、可程序化,就能跑批量股票、回测验证、嵌入策略。
这里,我想尝试一种「聚类」的思路 ------ 用 DBSCAN(密度聚类) 来辅助识别箱体。核心想法是:在价格-时间平面中,价格点集合可能在箱体区间内"密集",而在跳跃、突破、离群价等处"稀疏"或被视为噪声。以此来识别出箱体区间边界。
接下来花姐给大家讲清楚 DBSCAN 的原理、怎么用它做箱体识别、再说实战注意事项。
第一部分:DBSCAN 原理简介
为了不丢基础,这里简要回顾 DBSCAN 的基本原理。理解得透,才能在金融数据里做适配。
什么是 DBSCAN
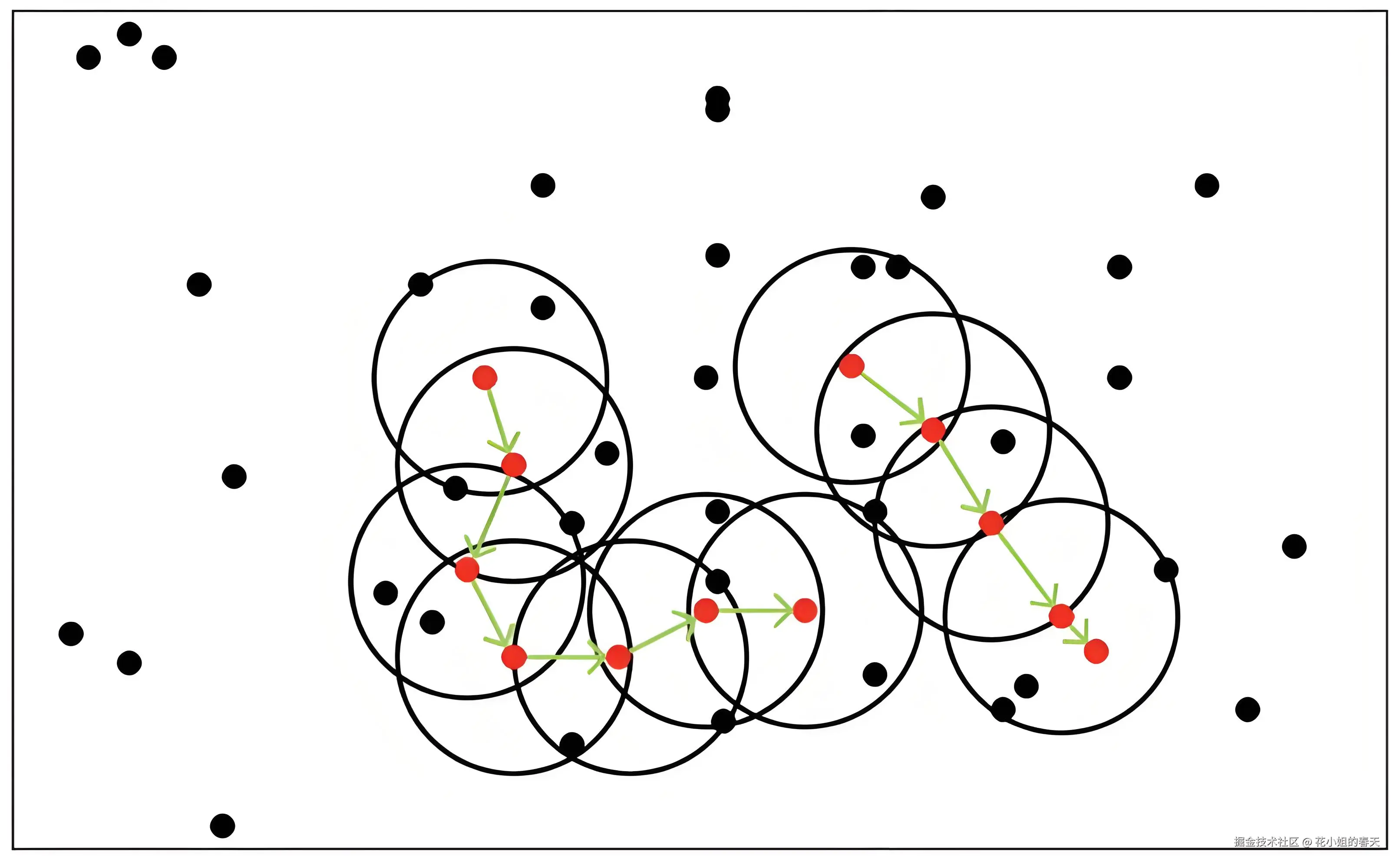
DBSCAN 全称是 Density-Based Spatial Clustering of Applications with Noise,直译就是"基于密度的聚类方法,可识别噪声点"。它有几个核心概念:
-
ε(eps):在空间中,两个点之间的最大距离阈值。如果一个点 B 在 A 的 ε 半径内,则 B 被认为是邻居。
-
MinPts(最小点数):在该 ε 半径内,若某个点的邻居数 ≥ MinPts,则这个点是一个 "核心点"。
-
直接密度可达 / 间接密度可达 等关系:
- 如果点 B 在 A 的 ε 邻域内,则 B 与 A 是"直接密度可达"的。
- 若存在一条点链 A → ... → C → B,每一步都是某点在前一点 ε 邻域内,则 B 对 A 是"密度可达"的。
- 最终:从一个核心点出发,遍历所有密度可达的点,就构成一个簇(cluster)。
-
噪声点:不属于任何簇的点被标为 noise(标签常标 -1)。
DBSCAN 的优点包括:
- 不需要预先指定簇数(不像 KMeans 那样要给 K)。
- 能识别任意形状的簇(不局限圆形/凸形)。
- 能把离群点、噪声点自然划出簇外。
缺点也必须注意:
- 对参数敏感,特别是 ε 的取值,对结果影响大。
- 在不同密度簇混杂时效果不好(不同簇的内部密度差异大时,标准 DBSCAN 很难同时兼顾)。
- 计算复杂度在点很多时可能不低(尤其在二维/高维空间上要做邻域搜索)。
在金融时间序列里,用 DBSCAN 要格外小心:数据的尺度、单位(价格 vs 时间)不同,噪声多,点密度不均等。调参、预处理非常重要。
第二部分:怎么用 DBSCAN 找箱体
下面介绍一种思路,你可以在这个基础上改进、调参。
思路梗概
- 数据点构造:把价格-时间空间看成二维点集。每个交易日(或每根 K 线点)视作一个点,横坐标是时间索引(可以是天数、序号、分钟级别也行),纵坐标是价格(可以是收盘价或高低区间点)
- 标准化:因为时间尺度和价格尺度量纲差别大,需要标准化、缩放,使两维差不致极端失衡。
- 用 DBSCAN 聚类:选一个 ε、MinPts,对这些点做聚类。簇聚集在密集的箱体区间内部;突破/非箱体行为往往是噪声或被分出簇外。
- 解析聚类结果,提取箱体边界:对于每个簇,计算其价格的上下界(max, min),把簇的时间跨度作为箱体的持续期。可能有多个并列簇,或者簇之间有重叠,需做合并策略或筛选(如去掉跨度太短/高度太小的簇)。
- 验证与后处理:进一步过滤那些"伪箱体"(如价格波动太小、持续期太短、被中断太多的簇),最终得到一组"候选箱体"。
下面的代码包括了计算箱体和可视化代码:
python
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
def detect_dbscan_boxes(
df,
price_col='close',
time_col=None,
eps=0.1,
min_samples=5,
min_span=5,
min_height=0.02
):
"""
基于 DBSCAN 算法识别股票价格箱体区间
参数说明:
----------
df : pd.DataFrame
包含时间和价格的行情数据
price_col : str
价格列名(默认为 'close')
time_col : str or None
时间列名,如为 None 自动使用索引序号
eps : float
DBSCAN 邻域半径(标准化空间下)
min_samples : int
DBSCAN 最小样本点数(核心点判定阈值)
min_span : int
箱体最小时间跨度(单位:时间索引)
min_height : float
箱体最小高度(价格比例)
返回:
----------
boxes : list[dict]
每个箱体的信息(时间区间、价格上下界、高度等)
df_out : pd.DataFrame
含 cluster 标签的 DataFrame,可用于可视化或后续分析
"""
df = df.copy()
# 确定时间索引列
if time_col is None:
df['time_idx'] = np.arange(len(df))
time_col = 'time_idx'
# 构造特征矩阵并标准化
X = df[[time_col, price_col]].values.astype(float)
Xs = StandardScaler().fit_transform(X)
# 运行 DBSCAN 聚类
db = DBSCAN(eps=eps, min_samples=min_samples)
labels = db.fit_predict(Xs)
df['cluster'] = labels
# 识别箱体簇
boxes = []
for lbl in sorted(set(labels)):
if lbl == -1:
continue # 忽略噪声点
sub = df[df['cluster'] == lbl]
t_min, t_max = sub[time_col].min(), sub[time_col].max()
span = t_max - t_min
p_min, p_max = sub[price_col].min(), sub[price_col].max()
height = (p_max - p_min) / p_min
if span >= min_span and height >= min_height:
boxes.append({
'label': lbl,
't_min': t_min,
't_max': t_max,
'p_min': p_min,
'p_max': p_max,
'height': height,
'count': len(sub)
})
return boxes, df
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def plot_dbscan_boxes(df, boxes, price_col='close', date_col='date',
figsize=(12,6), show_labels=True):
"""
绘制收盘价与识别出的箱体区域
参数说明:
----------
df : pd.DataFrame
含日期与价格列的数据
boxes : list[dict]
detect_dbscan_boxes() 返回的箱体信息列表
price_col : str
价格列名(默认 'close')
date_col : str
日期列名(默认 'date')
figsize : tuple
图像大小
show_labels : bool
是否在图上标注箱体编号
"""
# 设置全局字体
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'WenQuanYi Zen Hei'] # 多个备选字体
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots(figsize=figsize)
# 绘制价格线
ax.plot(df[date_col], df[price_col], color='black', linewidth=1.2, label='Close Price')
# 绘制每个箱体
for box in boxes:
# 提取箱体信息
t_min, t_max = int(box['t_min']), int(box['t_max'])
p_min, p_max = box['p_min'], box['p_max']
# 时间转成 x 轴坐标(日期)
x0 = df.iloc[t_min][date_col]
x1 = df.iloc[t_max][date_col]
# 用 fill_between 在时间范围内画矩形,不涉及时间加法
ax.fill_between(
[x0, x1],
p_min, p_max,
color='lightskyblue',
alpha=0.3,
edgecolor='dodgerblue'
)
if show_labels:
ax.text(x0, p_max, f"#{box['label']}",
color='blue', fontsize=8, va='bottom')
ax.set_title("DBSCAN 箱体识别结果")
ax.set_xlabel("日期")
ax.set_ylabel("价格")
ax.legend()
plt.grid(True, alpha=0.3)
plt.show()
from xtquant import xtdata
def get_hq(code,start_time,end_time):
'''
基于xtquant下载股票的历史行情
'''
xtdata.enable_hello = False
xtdata.download_history_data(stock_code=code,
period='1d',
start_time=start_time,
end_time=end_time)
history_data =xtdata.get_market_data_ex(['open','high','low','close','volume','amount','preClose'],
stock_list= [code],
period='1d',
start_time= start_time,
end_time=end_time,
dividend_type='front_ratio',
fill_data=False)
df = history_data[code]
df.index = pd.to_datetime(df.index.astype(str), format='%Y%m%d')
df['date']= df.index
return df
# 示例数据
data = get_hq(code='002617.SZ',start_time='20240101',end_time='20250901')
# 调用函数
boxes, df_with_labels = detect_dbscan_boxes(
data, price_col='close', eps=0.11, min_samples=5, min_span=10, min_height=0.02
)
# 绘制结果
plot_dbscan_boxes(df_with_labels, boxes, price_col='close', date_col='date')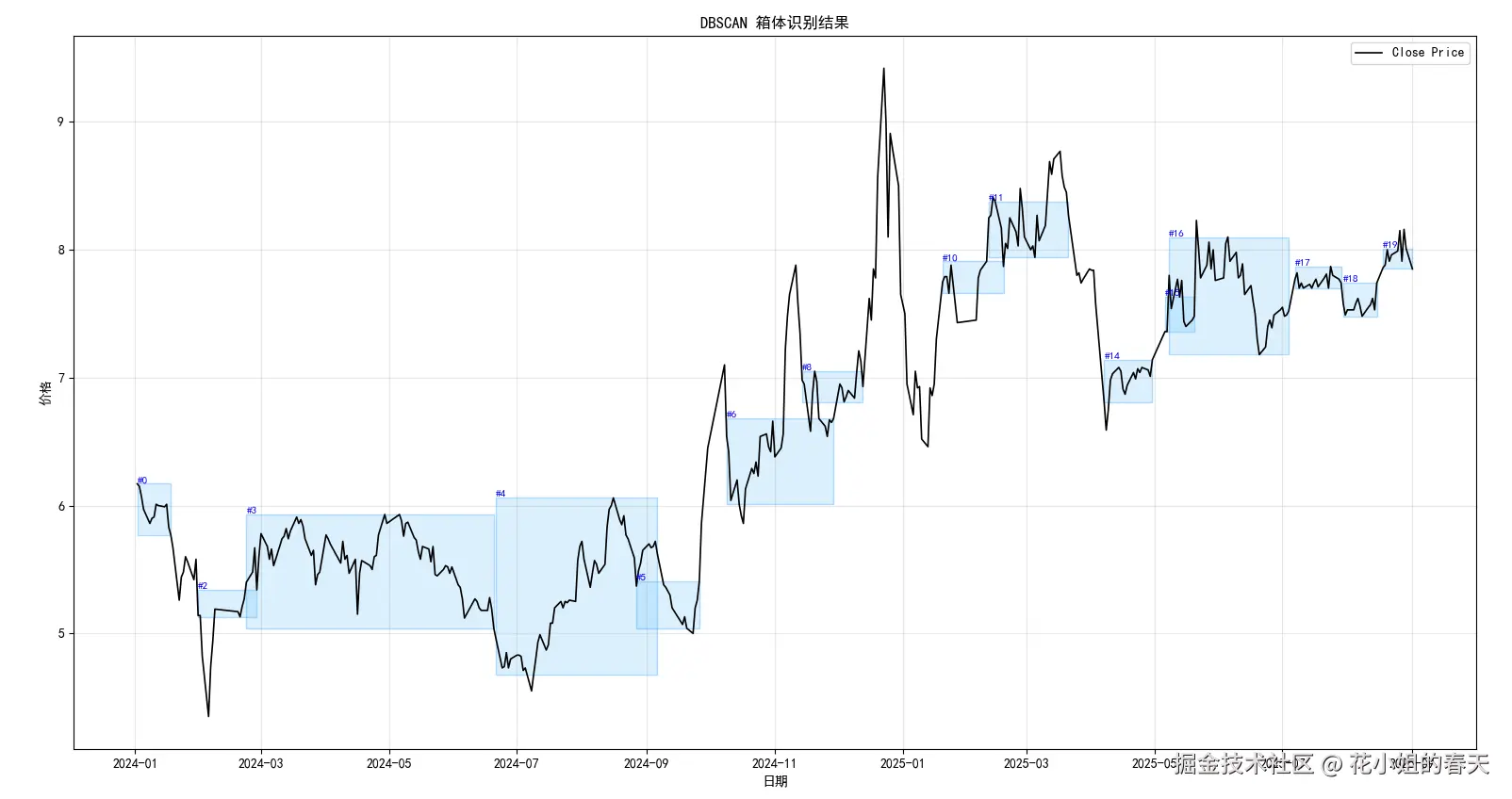
箱体的绘制方法,有很多地方可以优化:
- eps 的选择:这是最关键的一步。一般需要先做一些可视化探索(比如把标准化后的点画散点图、看密集程度)或用 k-distance 图(排序每点到第 k 近邻距离,看 elbow 点)来估计一个合适 eps。
- min_samples:对密度敏感性。设得太小,容易把噪声点做成簇;设得太大,很多簇会被判为噪声。
- 时间尺度 vs 价格尺度的缩放比:StandardScaler 是对两个维度同样缩放(除以标准差),但在金融情景中可能底层你要人为加权(比如价格维度比时间维度权重大一些)
- 后处理:多个簇可能重叠、跨越、碎片化。你要有逻辑合并相邻簇、剔除一些劣质簇(持续期太短、幅度太小、被打断多次)
- 滑窗 / 滚动识别:你可能希望不只识别整个历史,而是在最近 N 天做滚动箱体识别,以便策略能自适应箱体结构变化。
箱体的几何含义
最终识别到的箱体,是一种"价格上下界 + 时间跨度"的矩形结构:
- 上界:p_max
- 下界:p_min
- 起始时间:t_min
- 结束时间:t_max
你可以把每个箱体看作"在 t_min, t_max 这个时间窗里,价格主要在 p_min, p_max 之间来回震荡"的状态。
然后在策略里,你可以定义:
- 在箱体内部:做区间震荡策略(在靠近下界买入,靠近上界卖出)
- 突破判断:价格突破上界(或下界)视为可能箱体失效 / 趋势信号
- 箱体切换:若新的点跳出旧箱体、形成新的簇,就切换箱体
第四部分:如何让箱体画的更合理
在不改变原有代码的基础上,我们可以通过调节参数eps, min_samples, min_span, min_height的取值来使得箱体绘制的更符合我们的主观判断。
1、参数作用
| 参数 | 作用 | 调整方向 | 影响 |
|---|---|---|---|
eps |
DBSCAN 聚类半径(标准化空间) | 增大 → 箱体更宽更长,容易合并小簇;减小 → 箱体更窄、碎 | 最关键参数,控制簇连通性 |
min_samples |
最小样本点数 | 增大 → 只保留稠密簇(丢掉小簇/噪声);减小 → 接受稀疏簇 | 控制簇稳定性和可靠性 |
min_span |
后处理最小时间跨度 | 增大 → 去掉短箱体;减小 → 接受短箱体 | 控制横向长度 |
min_height |
后处理最小价格高度 | 增大 → 去掉窄箱体;减小 → 接受小震荡 | 控制纵向高度 |
- 想箱体更高、更长、更稳 → 增大 eps / min_samples / min_span / min_height
- 想多箱体、碎一点 → 减小 eps / min_samples / min_span / min_height
2、调参顺序(实战建议)
2.1 先确定 DBSCAN 的核心半径 eps
-
方法 1:经验法,先用当前价格数据和标准化后 eps=0.12 看箱体数量。
-
方法 2:k-distance 图法,选 eps 对应拐点距离。
pythonfrom sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors=min_samples).fit(Xs) distances, _ = nbrs.kneighbors(Xs) k_dist = np.sort(distances[:, min_samples-1]) plt.plot(k_dist); plt.show()拐点位置就是 eps 的参考值。
2.2 min_samples 影响簇稠密度
- 先固定 eps,逐步调 min_samples(3~8),观察箱体是否太碎。
- 高 min_samples → 小簇被过滤,剩下的箱体更稳定。
2.3 min_span 控制时间长度
- 先观察箱体的横向跨度,如果太短 → 增大 min_span,例如 5 → 10 → 15。
- 如果你想捕捉短期箱体 → 可降低 min_span。
2.4 min_height 控制价格区间高度
- 看箱体纵向高度是否符合你策略需求(支撑/压力幅度)
- 小于策略预期 → 减小 min_height
- 太窄 → 增大 min_height
3、 实用调参策略
3.1 箱体太小(碎片多、横向短、纵向窄):
- eps *= 1.2~1.5
- min_samples += 1~2
- min_span += 5~10
- min_height += 0.01~0.02
3.2 箱体太少或太大(覆盖全局、失去分辨率):
- eps = 0.8~0.9
- min_samples -= 1~2
- min_span -= 2~5
- min_height -= 0.005~0.01
3.3 调试技巧:
- 每次只调一个参数,观察变化,避免多参数同时调整导致混乱。
- 可记录每次组合下箱体数量、跨度、平均高度,选择最符合策略的组合。
- 对高波动股票可适当降低 min_height 或增大 eps;对低波动股票可适当降低 eps 或增大 price_weight。
4、 可视化辅助
调参时强烈建议每次都画图,观察箱体:
python
boxes, df_with_labels = detect_dbscan_boxes(
data, price_col='close', eps=0.12, min_samples=5, min_span=10, min_height=0.02
)
plot_dbscan_boxes(df_with_labels, boxes)通过图能直观判断:
- 箱体横向长度
- 箱体高度
- 簇分布和碎片情况
5、 推荐调参顺序(实战简化版)
text
1️⃣ 先调整 eps → 控制簇连通性
2️⃣ 调整 min_samples → 控制簇稠密度
3️⃣ 调整 min_span → 控制横向长度
4️⃣ 调整 min_height → 控制纵向幅度
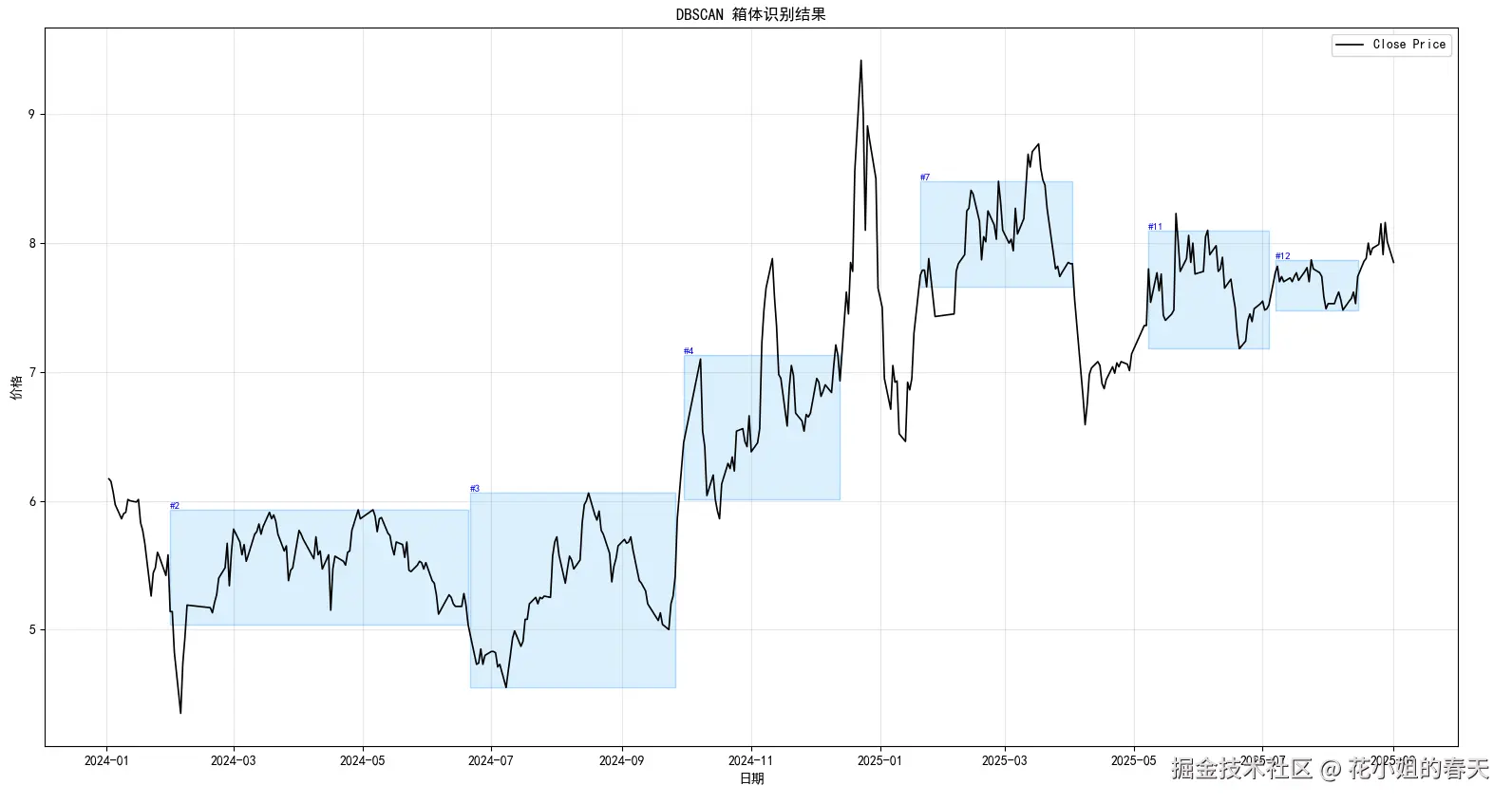
5️⃣ 可选:price_weight、平滑窗口、合并临近箱体根据上面的方法,我把参数调整了下看起来效果好多了
之前的参数
python
boxes, df_with_labels = detect_dbscan_boxes(
data, price_col='close', eps=0.11, min_samples=5, min_span=10, min_height=0.02
)现在的参数
python
boxes, df_with_labels = detect_dbscan_boxes(
data, price_col='close', eps=0.12, min_samples=5, min_span=18, min_height=0.04
)
第五部分:箱体识别在实战中的应用、挑战与建议
下面讲讲在实际研究/回测/实盘里对这套方法的观察和实战建议 💡
应用场景
-
突破策略检测 当价格在箱体上界突破,可以作为"多头信号";在下界跌破,可以作为"空头信号"或止损信号。相比于单纯的高低点突破,箱体结构能给信号更多维度约束(持续时间、密度、强度)。
-
区间震荡策略 对于震荡偏强的品种(特别是股票、小盘股、波动性较大的股票),你可以在箱体内部做"低买高卖"策略,带有止盈止损。DBSCAN 找到的箱体在逻辑上自带"密集性"保证,理论上能减少跳动噪音造成的误交易。
-
箱体过滤 / 辅助选股 对于一桶候选股票,你可以先筛出"近期存在明确箱体结构"的股票作为优先研究对象,因为箱体结构往往意味着市场在这个阶段有明确的支撑-阻力区间,策略较易落地点。
-
多周期联动 / 套件策略 你可以在多个周期上都做箱体识别(如日线、小时线、30 分钟线),然后做多周期融合(比如小时级突破 + 日线箱体确认)来增强信号的可靠性。
实战挑战与可能的坑
- 参数敏感:eps、min_samples、尺度缩放比例这些超参稍有偏差就可能"箱体被打碎"或"簇被判为噪声"。你需要在回测/样本期里做网格搜索、交叉验证。
- 密度不均问题:有些股票在底部震荡很密集、在顶部波动稀疏,标准 DBSCAN 可能把顶部的行为划为噪声,无法形成簇。HDBSCAN 等扩展更具鲁棒性,可以考虑替代。
- 时间断裂 / 非连续性:在现实中,箱体内部可能有短暂的突破、回归、跳空、缺口。DBSCAN 会把这些断裂点判为噪声。后处理逻辑要能"容错"即容忍少量断裂。
- 边界模糊 / 重叠簇:不同箱体可能有重叠区域,簇边界可能模糊。你要设定清晰的合并、剔除、排序规则。
- 滑窗延迟 / 箱体切换滞后:在做滚动识别时,箱体延迟确认可能导致信号滞后或错过时机。你要合理设计滑窗长度、更新频率。
- 回测陷阱:用历史全样本构建箱体可能"未来函数"泄漏。你要在回测里 ensure 箱体识别只用当前可得历史,不拿未来价格做识别。
一个简单实战例子(思路演示)
假设我们用日线做箱体识别,进行一个突破策略:
- 用过去 60 天价格构造价格-时间点集,做 DBSCAN,识别若干箱体。
- 选最近一个箱体(例如跨度最长或时间最靠近末端的簇)作为当前箱体。
- 在未来日子里,如果收盘价突破该箱体上界(如以收盘价或高价突破),标记为多头开仓信号。
- 止损可以设在箱体下界或按回撤比例。
- 若突破信号失败,或者价格回落回箱体内部,视为信号失效。
- 同时,持续滚动滑窗更新箱体结构。
通过实盘或回测,你可以评估这种策略在样本里的胜率、利润因子、回撤、持仓期等。
总结 + 给大家的建议
- 用 DBSCAN 来辅助识别股票的箱体结构,是一种较为新颖、自动化、程序化的思路,可以把"视觉画箱子"这个半人工动作量化起来。
- 这种方法的核心挑战在于参数选取、尺度匹配、后处理逻辑。实战中必须做严谨的回测与验证。
- 对于密度不均的结构,可考虑使用 HDBSCAN 等更鲁棒的方法作为替代或补充。
- 在策略里,把箱体结构做为一个"特征 / 筛选维度"会比直接用它做信号更稳妥:比如先筛箱体结构稳定的股票,再在这些股票里做突破或区间策略。