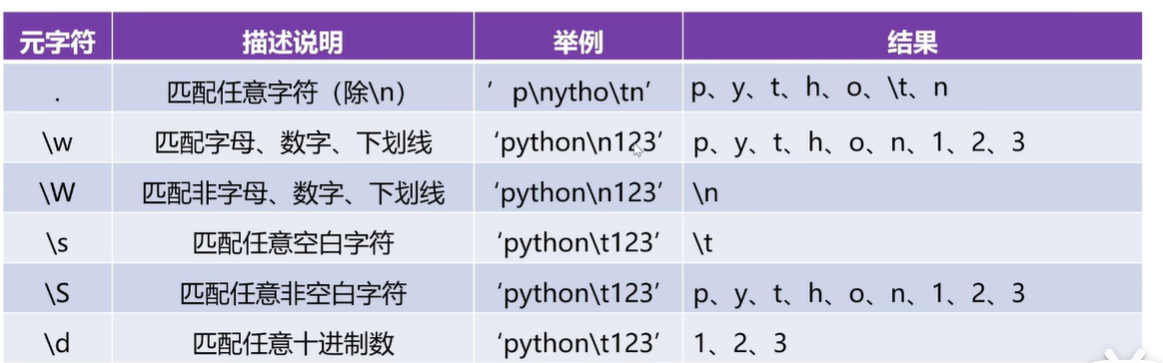
1、正则表达式常用符号
**元字符:**具有特殊意义的专用字符
例如使用 ^和 $ 分别匹配开始和结束
限定符 :用于限定匹配次数qit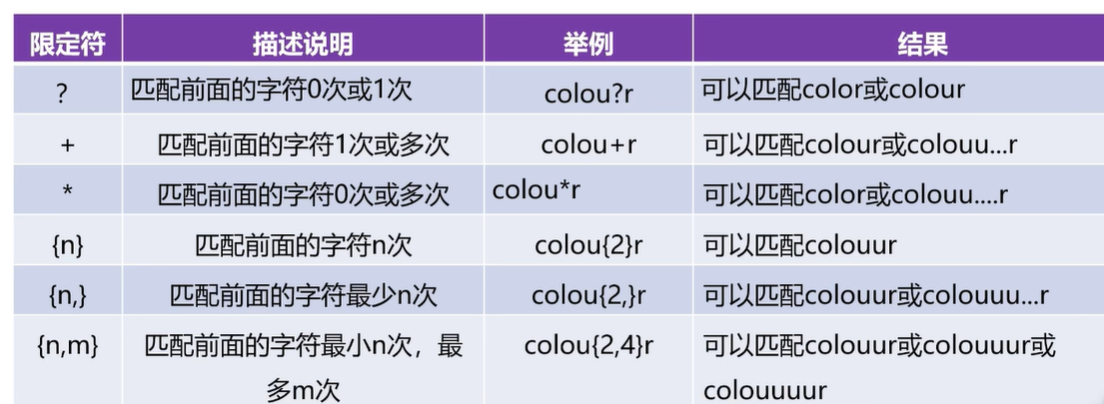
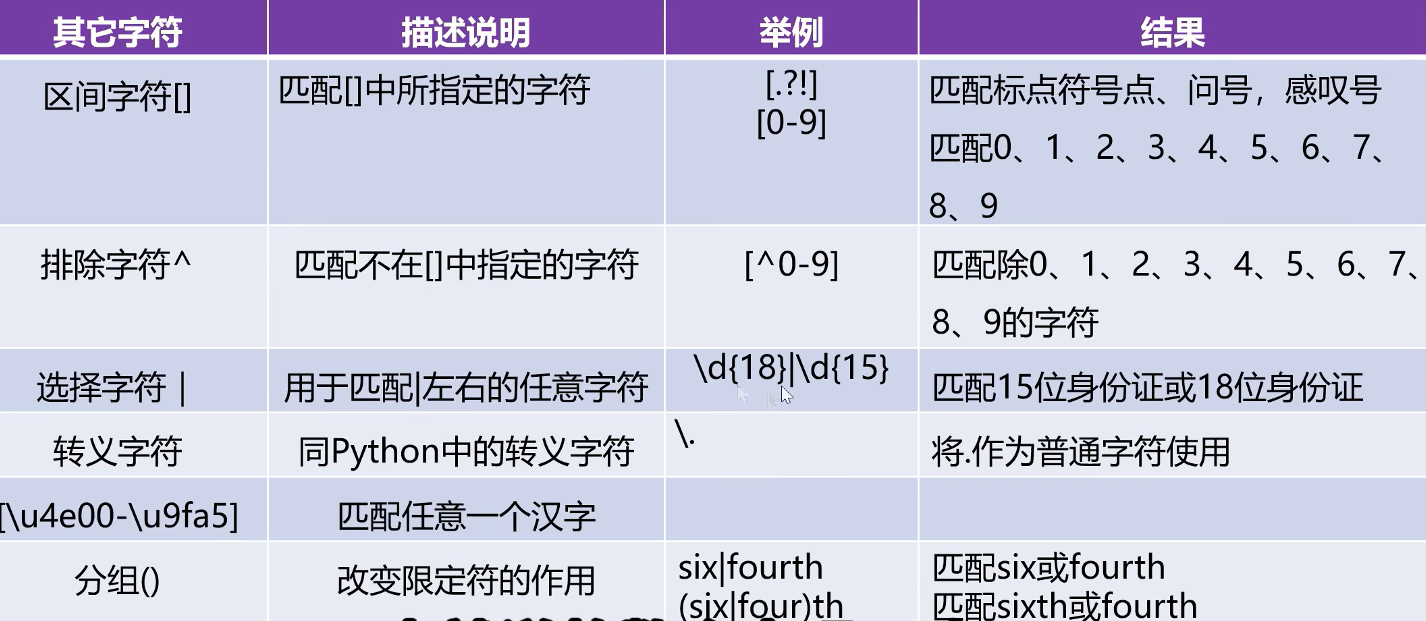
其他字符
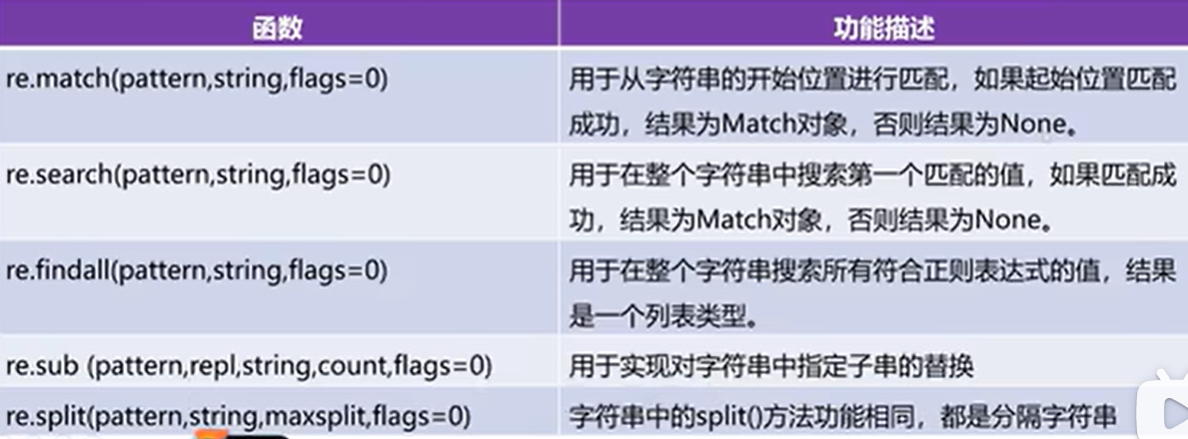
2、re模块介绍使用
用于实现python中的表达式
2.1、re.match()函数的使用
pattern是匹配格式,string是字符串,使用时需要从起始位置匹配成功才能争取匹配。匹配对象有相应方法可以返回初始、结束数据的位置,匹配返回范围的返回、匹配数据返回
示例:将数字类似于3.1...的数据匹配
python
import re
str = "I studay python 3.11 everyDay"
# /d 0-9 +匹配前面的数字出现1次或者多次
patten = "\d\.\d+"
# 从字符串开始位置匹配,如果起始匹配成功则match对象,否则返回为None
match = re.match(patten,str)
# None
print(match)
# 修改字符串方式可匹配
str1 = "3.11 python I studay everyday "
match1= re.match(patten,str1)
# 输出:<_sre.SRE_Match object; span=(0, 4), match='3.11'>
print(match1)
print("匹配的起始位置:",match1.start())
print("匹配的结束位置:",match1.end())
print("匹配区间相同的位置",match1.span())
print("待匹配的字符串:",match1.string)
print("匹配的数据:",match1.group())输出
Matlab
None
<_sre.SRE_Match object; span=(0, 4), match='3.11'>
匹配的起始位置: 0
匹配的结束位置: 4
匹配区间相同的位置 (0, 4)
待匹配的字符串: 3.11 python I studay everyday
匹配的数据: 3.112.2、seach()和findall()函数使用
python
import re
pattern ="\d\.\d+"
s = "I study Python 3.11 every day Python 2.7 I love you"
# 返回第一个符合格式的字符串,无则返回None,只有一个
match1 = re.search(pattern,s)
print(match1)
print(match1.group())
# 查找所有符合匹配格式的结果,返回类型为字符串
match2 = re.findall(pattern,s)
print(match2)输出
Matlab
<_sre.SRE_Match object; span=(15, 19), match='3.11'>
3.11
['3.11', '2.7']2.3、sub()替换
re.sub(pattern,repl,string),pattern是被匹配的正则,repl是需要替换成的内容,string是需要被匹配的字符串。
示例:将字符串中包含黑客或者破解或者反爬替换成xxx
python
import re
pattern = "黑客|破解|反爬"
s = "我想学习python,破解一些VIP视频,可以用python实现反爬吗?"
new_s = re.sub(pattern,"xxx",s)
print(new_s)输出:
我想学习python,xxx一些VIP视频,可以用python实现xxx吗?
2.4、split()函数
匹配字符串中想要分割的符号,返回内容是已经被分割的列表,
python
import re
s2 = "https://www.baidu.com/s?wd=csdn&rsv_spt=1"
pattern2 = "[?|&]"
new_s2 = re.split(pattern2,s2)
print(new_s2 )输出:
'https://www.baidu.com/s', 'wd=csdn', 'rsv_spt=1'