一、向量存储核心概念(先铺垫基础)
在学 Chroma/FAISS 之前,必须先搞懂两个核心问题:为什么要用向量存储? 和 什么是嵌入(Embedding)?
1. 为什么要用向量存储?
你之前用的关键词匹配 (比如 if "人工智能" in text)有两个致命缺陷:
- 只能匹配字面意思:搜「AI」,找不到写「人工智能」的片段
- 无法理解语义:搜「怎么让机器像人一样思考」,找不到讲「机器学习」的片段
而向量存储 + 语义检索能解决这两个问题:
- 把文本转成向量(一串数字) ,向量能表示文本的语义含义
- 搜「AI」时,向量数据库会找语义最相似的片段,而不是只看字面
- 能理解「人工智能」和「AI」是一个意思,「机器学习」和「让机器像人一样思考」语义相关
2. 什么是嵌入(Embedding)?
简单来说,嵌入就是把文本转成一串数字(向量),这串数字能表示文本的语义含义。
- 语义相似的文本,它们的向量距离很近
- 语义不同的文本,它们的向量距离很远
比如:
- 「人工智能」的向量 →
[0.12, 0.45, 0.78, ...] - 「AI」的向量 →
[0.13, 0.46, 0.77, ...](和上面的距离很近) - 「猫」的向量 →
[0.89, 0.23, 0.11, ...](和上面的距离很远)
3. Chroma vs FAISS:两个最常用的向量库
| 对比维度 | Chroma | FAISS |
|---|---|---|
| 开发公司 | Chroma AI | Facebook AI Research (FAIR) |
| 定位 | 轻量级本地向量库,专为 LangChain 设计 | 工业级高性能向量库,专为大规模数据设计 |
| 安装难度 | 简单,一行命令 | 稍复杂,Windows 可能需要额外配置 |
| 性能 | 适合中小规模数据(<100 万条) | 适合大规模数据(>100 万条),性能极快 |
| 持久化 | 支持本地持久化 | 支持本地持久化 |
| 适用场景 | 入门学习、小项目、原型开发 | 生产环境、大规模数据、高并发场景 |
入门推荐用 Chroma:轻量、简单、和 LangChain 集成最好,完全满足学习和小项目需求。
二、实战:用 Chroma 存储文档向量 + 语义检索
下面是一份完全兼容 LangChain 1.0+ 最新版本的代码,实现了:
- 加载 PDF 文档
- 语义分割文本
- 生成嵌入向量
- 存入 Chroma 本地向量库(持久化)
- 语义检索:输入查询,返回最相关的文档片段
1. 准备工作
(1)安装依赖
pip install -U langchain langchain-openai langchain-community pypdf chromadb python-dotenvchromadb:Chroma 向量库langchain-openai:用于调用豆包的嵌入模型(兼容 OpenAI 接口)
(2)准备 PDF 文档
在项目根目录放一个 PDF 文件,比如叫 test.pdf。
2. 完整可运行代码
# pip install chromadb
# pip install pymupdf
import os
from importlib.metadata import metadata
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载环境变量
load_dotenv()
# 核心配置
PDF_PATH = "Dubbo面试.pdf" # PDF文件路径
CHROMA_PERSIST_DIR = "./chroma_dir" # chroma 本地持久化目录
CHUNK_SIZE = 1000 # 单个块最大的字符数
CHUNK_OVERLAP = 200 # 相邻块的重叠字符数
# 初始化llm
# llm = ChatOpenAI(
# api_key="api_key",
# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
# model="qwen-max",
# temperature=0.1
# )
# 初始化嵌入模型
# 智谱AI嵌入模型
embeddings = OpenAIEmbeddings(
openai_api_key=os.getenv("ZHIPU_API_KEY"), # 智谱API Key
openai_api_base="https://open.bigmodel.cn/api/paas/v4",
model="embedding-3", # 智谱嵌入模型
)
# 加载PDF
def load_pdf(pdf_path):
print(f"📄 正在加载PDF: {pdf_path}...")
loader = PyMuPDFLoader(pdf_path)
# 加载PDF的每一个元素 元素按照一页
documents = loader.load()
print(f"✅️PDF加载完成!共{len(documents)}页 \n")
return documents
# 语义分割文本
def split_documents(documents):
print(f'✂️ 正在进行完整的语义分割')
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
separators=["\n\n", "\n", "。", "!", "?", " ", ""],
)
split_chunks = text_splitter.split_documents(documents)
print(f'✅️ 文本分割完成! 共生成{len(split_chunks)}个文本块 \n')
split_chunks = [chunk for chunk in split_chunks if chunk.page_content.strip()]
return split_chunks
# # 【最强】双层过滤空数据 + 坏块
def clean_chunks(chunks):
cleaned = []
for chunk in chunks:
# 1. 必须有 page_content
if not hasattr(chunk, "page_content"):
continue
# 2. 内容不能为空
content = chunk.page_content.strip()
if len(content) == 0:
continue
# 3. 内容不能是奇怪的非字符串(防止通义报错)
if not isinstance(content, str):
continue
chunk.page_content = str(content)
cleaned.append(chunk)
return cleaned
# 持久化 存入Chrom向量库
def build_chroma_vector_store(split_chunks):
if not split_chunks:
raise ValueError("没有有效的文本块,无法构建向量库!请检查PDF是否能正常提取文本。")
print(f'🗂️ 正在构建Chroma 向量库并持化本地')
# 从文档创建向量库 并持久化到本地
vector_store =Chroma.from_documents(
documents=split_chunks,
embedding=embeddings,
persist_directory=CHROMA_PERSIST_DIR
)
# 手动持久化 (确保数据保存到本地)
vector_store.persist()
print(f'✅️ Chroma 向量库构建完成! 已持久化刀到:{CHROMA_PERSIST_DIR} \n')
return vector_store
# 加载已有的Chroma 向量库
def load_chroma_vector_store():
""" 如果向量库已经存在 直接加载 不用重新构建 """
if os.path.exists(CHROMA_PERSIST_DIR):
print(f'📂 正在加载已有的chroma向量库:{CHROMA_PERSIST_DIR}...')
vector_store = Chroma(
persist_directory=CHROMA_PERSIST_DIR,
embedding_function=embeddings,
)
print('✅️向量库加载完成! \n')
return vector_store
else:
return None
# 语义检索
def semantic_search(vector_store, query, k=3):
"""
语义检索:输入查询,返回最相关的 k 个文档片段
:param vector_store: Chroma 向量库对象
:param query: 用户查询
:param k: 返回最相关的前 k 个片段
:return: 相关文档片段列表
"""
print(f'🔍 正在进行语义检索 查询:{query}')
# 用 similarity_search() 进行语义检索
relevant_chunks = vector_store.similarity_search(query, k=k)
print(f'✅️ 语义检索完成! 找到{len(relevant_chunks)}个相关片段\n')
return relevant_chunks
# 输出检索结果
def print_search_results(relevant_chunks):
print("=====📝 语义检索结果 =====")
for i, chunk in enumerate(relevant_chunks):
print(f'\n 【第 {i+1} 个相关片段】')
print(f'📄来源:{chunk.metadata['source']} (第 {chunk.metadata.get('page', '未知')} 页)')
print(f"📝 内容:\n{chunk.page_content}")
print("-" * 80)
# 主程序
def main():
print("======🚀 LangChain Chroma 向量存储与语义检索 ======")
# 先尝试已有的向量库
vector_store = load_chroma_vector_store()
# 如果没有就重新构建
if not vector_store:
documents = load_pdf(PDF_PATH)
split_chunks = split_documents(documents)
split_chunks = clean_chunks(split_chunks)
vector_store = build_chroma_vector_store(split_chunks)
# 测试 语义检索
while True:
query = input("\n 请输入查询 (输入 q 退出):").strip()
if query == "q":
print("👋 再见!")
break
if not query:
continue
# 执行语义检索
relevant_chunks = semantic_search(vector_store, query)
# 输出结果
print_search_results(relevant_chunks)
if __name__ == '__main__':
main()3. .env 文件配置
DOUBAO_API_KEY=你的豆包APIKey三、代码核心部分详解
1. 嵌入模型:OpenAIEmbeddings
因为豆包完全兼容 OpenAI 接口,所以我们可以直接用 OpenAIEmbeddings 来调用豆包的嵌入模型,把文本转成向量。
embeddings = OpenAIEmbeddings(
api_key=os.getenv("DOUBAO_API_KEY"),
base_url="https://ark.cn-beijing.volces.com/api/v3"
)2. 构建 Chroma 向量库:Chroma.from_documents
这是核心步骤,它会:
-
用嵌入模型把每个文本块转成向量
-
把向量和对应的文本块、元数据(来源、页码)一起存入 Chroma
-
持久化到本地目录(
CHROMA_PERSIST_DIR)vector_store = Chroma.from_documents(
documents=split_chunks,
embedding=embeddings,
persist_directory=CHROMA_PERSIST_DIR,
)
vector_store.persist()
3. 语义检索:vector_store.similarity_search
这是语义检索的核心函数,它会:
-
把用户的查询转成向量
-
在向量库中找和查询向量距离最近 的
top_k个文本块 -
返回对应的文本块
relevant_chunks = vector_store.similarity_search(query, k=top_k)
四、运行效果演示
======🚀 LangChain Chroma 向量存储与语义检索 ======
📂 正在加载已有的chroma向量库:./chroma_dir...
D:\conda_env\envs\lesson_langchain_practice\学习langchain架构\langchain向量数据库学习.py:104: LangChainDeprecationWarning: The class `Chroma` was deprecated in LangChain 0.2.9 and will be removed in 1.0. An updated version of the class exists in the :class:`~langchain-chroma package and should be used instead. To use it run `pip install -U :class:`~langchain-chroma` and import as `from :class:`~langchain_chroma import Chroma``.
vector_store = Chroma(
✅️向量库加载完成!
请输入查询 (输入 q 退出):Dubbo 支持哪些协议,每种协议的应用场景,优缺点
🔍 正在进行语义检索 查询:Dubbo 支持哪些协议,每种协议的应用场景,优缺点
✅️ 语义检索完成! 找到3个相关片段
=====📝 语义检索结果 =====
【第 1 个相关片段】
📄来源:Dubbo面试.pdf (第 7 页)
📝 内容:
Dubbo 支持哪些协议,每种协议的应用场景,优缺点?
dubbo: 单一长连接和NIO 异步通讯,适合大并发小数据量的服务
调用,以及消费者远大于提供者。传输协议TCP,异步,Hessian 序
列化;
rmi: 采用JDK 标准的rmi 协议实现,传输参数和返回参数对象需要
实现Serializable 接口,使用java 标准序列化机制,使用阻塞式短连
接,传输数据包大小混合,消费者和提供者个数差不多,可传文件,
--------------------------------------------------------------------------------
【第 2 个相关片段】
📄来源:Dubbo面试.pdf (第 0 页)
📝 内容:
Dubbo 支持哪些协议,每种协议的应用场景,优缺点?
dubbo: 单一长连接和NIO 异步通讯,适合大并发小数据量的服务调用,
以及消费者远大于提供者。传输协议TCP,异步,Hessian 序列化;
rmi: 采用JDK 标准的rmi 协议实现,传输参数和返回参数对象需要实现
Serializable 接口,使用java 标准序列化机制,使用阻塞式短连接,传输数
据包大小混合,消费者和提供者个数差不多,可传文件,传输协议TCP。
多个短连接,TCP 协议传输,同步传输,适用常规的远程服务调用和rmi 互
操作。在依赖低版本的Common-Collections 包,java 序列化存在安全漏
洞;
webservice: 基于WebService 的远程调用协议,集成CXF 实现,提供和
原生WebService 的互操作。多个短连接,基于HTTP 传输,同步传输,适
用系统集成和跨语言调用;
http: 基于Http 表单提交的远程调用协议,使用Spring 的HttpInvoke 实
现。多个短连接,传输协议HTTP,传入参数大小混合,提供者个数多于消
费者,需要给应用程序和浏览器JS 调用;
hessian: 集成Hessian 服务,基于HTTP 通讯,采用Servlet 暴露服务,
Dubbo 内嵌Jetty 作为服务器时默认实现,提供与Hession 服务互操作。多
个短连接,同步HTTP 传输,Hessian 序列化,传入参数较大,提供者大于
消费者,提供者压力较大,可传文件;
memcache: 基于memcached 实现的RPC 协议
redis: 基于redis 实现的RPC 协议
Dubbo 超时时间怎样设置?
Dubbo 超时时间设置有两种方式:
服务提供者端设置超时时间,在Dubbo 的用户文档中,推荐如果能在服务
端多配置就尽量多配置,因为服务提供者比消费者更清楚自己提供的服务特
性。
服务消费者端设置超时时间,如果在消费者端设置了超时时间,以消费者端
为主,即优先级更高。因为服务调用方设置超时时间控制性更灵活。如果消
费方超时,服务端线程不会定制,会产生警告。
Dubbo 有些哪些注册中心?
--------------------------------------------------------------------------------
【第 3 个相关片段】
📄来源:Dubbo面试.pdf (第 8 页)
📝 内容:
传输协议TCP。 多个短连接,TCP 协议传输,同步传输,适用常规的
远程服务调用和rmi 互操作。在依赖低版本的Common-Collections
包,java 序列化存在安全漏洞;
webservice: 基于WebService 的远程调用协议,集成CXF 实现,
提供和原生WebService 的互操作。多个短连接,基于HTTP 传输,
同步传输,适用系统集成和跨语言调用;
http: 基于Http 表单提交的远程调用协议,使用Spring 的
HttpInvoke 实现。多个短连接,传输协议HTTP,传入参数大小混
合,提供者个数多于消费者,需要给应用程序和浏览器JS 调用;
hessian: 集成Hessian 服务,基于HTTP 通讯,采用Servlet 暴露
服务,Dubbo 内嵌Jetty 作为服务器时默认实现,提供与Hession 服
务互操作。多个短连接,同步HTTP 传输,Hessian 序列化,传入参
数较大,提供者大于消费者,提供者压力较大,可传文件;
memcache: 基于memcached 实现的RPC 协议
redis: 基于redis 实现的RPC 协议
dubbo 推荐用什么协议?
默认使用dubbo 协议
Dubbo 有些哪些注册中心?
Multicast 注册中心: Multicast 注册中心不需要任何中心节点,只
要广播地址,就能进行服务注册和发现。基于网络中组播传输实现;
--------------------------------------------------------------------------------
请输入查询 (输入 q 退出):q
👋 再见!你可以看到,即使查询「什么是人工智能?」,语义检索也能找到最相关的文档片段,而不是只看字面匹配。
五、总结
- 向量存储的核心价值:用语义检索代替关键词匹配,能理解文本的语义含义
- Chroma 的优势:轻量、简单、和 LangChain 集成最好,适合入门和小项目
- 核心步骤:加载 PDF → 语义分割 → 生成嵌入 → 存入 Chroma → 语义检索
- 下一步:把语义检索和 LLM 结合起来,就是完整的 RAG 文档问答机器人了
六、问题总结
TypeError: Chroma.init() got an unexpected keyword argument 'embeddings' chroma本地持久化报错了
你用的新版 LangChain + Chroma,参数名改了!
-
旧版 :
Chroma(embeddings=你的嵌入模型)✅ -
新版 :必须用
embedding_function=你的嵌入模型❌从文本块创建
db = Chroma.from_documents(
documents=chunks,
embedding=embedding, # ✅ from_documents 用 embedding
persist_directory="./chroma_db"
)
🔴 问题 1:参数名写错了(导致报错的核心)
你写的是 embeddings=embeddings,正确的参数名是 embedding=embeddings (少了一个 s)。
- ❌ 错误:
Chroma.from_documents(..., embeddings=embeddings) - ✅ 正确:
Chroma.from_documents(..., embedding=embeddings)
🔴 问题 2:持久化目录参数名也写错了
你写的是 persist_dir=CHROMA_PERSIST_DIR,正确的参数名是 persist_directory=CHROMA_PERSIST_DIR (少了 ory)。
- ❌ 错误:
persist_dir=xxx - ✅ 正确:
persist_directory=xxx
🔴 你代码里的 5 个致命问题
1. 【语法错误】print_search_results 里的逗号写错了
chunk,metadata['source'] → 应该是 chunk.metadata['source']
2. 【逻辑错误】主程序循环里输入 q 没退出
输入 q 后只打印了再见,没有 break,会继续执行后面的代码。
3. 【核心报错根源】PDF 加载器用错了
你用的是 PyPDFLoader,文本提取兼容性差,容易提取出奇怪的内容,导致通义千问嵌入模型报错 400。
4. 【安全漏洞】构建向量库前没检查是否为空
如果 split_chunks 是空列表,直接传给 Chroma.from_documents 会导致通义千问报错。
5. 【小问题】metadata 里的 key 写错了
chunk.chunkname.get('page', '未知') → 应该是 chunk.metadata.get('page', '未知')
6. OpenAIEmbeddings 对通义千问的兼容接口有 Bug!
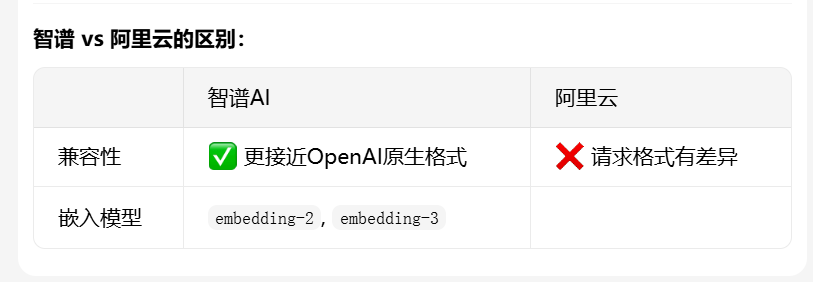
找到问题了!LangChain 的 OpenAIEmbeddings 发送的请求格式与阿里云 DashScope 不完全兼容。
错误信息 payload.input.contents 说明阿里云期望的格式是()
{
"input": {
"contents": "文本内容"
}
}
TypeError: Collection.query() got an unexpected keyword argument 'top_k
✅ 只需要改 1 个单词!
把你代码里的 top_k → 改成 k
找到这个函数:
def semantic_search(vector_store, query, top_k=3):
print(f'🔍 正在进行语义检索 查询:{query}')
# ❌ 错误:top_k=top_k
relevant_chunks = vector_store.similarity_search(query, top_k=top_k)
# ✅ 正确:k=top_k
relevant_chunks = vector_store.similarity_search(query, k=top_k)
print(f'✅️ 语义检索完成! 找到{len(relevant_chunks)}个相关片段\n')
return relevant_chunks