目录
[Related Work](#Related Work)
[Methodology and the Bit-Flip-Spark+Chain-of-Reasoning Format](#Methodology and the Bit-Flip-Spark+Chain-of-Reasoning Format)
[Preprocessing and Dataset Construction](#Preprocessing and Dataset Construction)
[Fine-tuning and Inference Pipeline](#Fine-tuning and Inference Pipeline)
[Discussion and Future Work](#Discussion and Future Work)
Abstract
生成新颖且富有创意的科学假设,是实现通用人工智能的核心基石。大型语言与推理模型有望助力系统化地创建、筛选和验证基于科学依据的假设。然而,当前的基础模型往往难以产出既新颖又可行的科学构想 。其中一个原因,便是缺乏专门的数据集 ,无法将科学假设生成(SHG)任务视作自然语言生成(NLG)任务来处理。
为此,本文首次提出了HypoGen数据集------该数据集包含约5500组结构化的问题-假设配对 ,均摘自顶级计算机科学会议,并采用"比特翻转-灵感火花"框架进行组织:其中,"比特"代表传统假设 ,"灵感火花"则是核心洞见或概念性飞跃 ,而"翻转"则指由此产生的反向提案 。HypoGen的独特之处在于,它明确融入了链式推理环节,完整呈现了从"比特"到"翻转"的思维过程。
我们证明,**将假设生成问题转化为条件语言建模任务,并在"比特-翻转-灵感火花"及链式推理框架上对模型进行微调(且在推理阶段仅提供"比特"信息),能够显著提升所生成假设的整体质量。**我们的评估方法结合了自动化指标与大模型评委的排名,以全面衡量假设的质量。实验结果表明,通过在HypoGen数据集上进行微调,我们有效提升了所生成假设的新颖性、可行性以及整体质量。目前,HypoGen数据集已公开发布于Hugging Face平台:
huggingface.co/datasets/UniverseTBD/hypogen-dr1
Introduction
大多数研究工作都指出了当前模型在应用于开放性研究问题时的局限性,尤其是在生成新颖、富有创意、多样化、可行、可操作、有趣且有用的想法或假设方面存在不足。
大型语言模型在应用于科学构思时面临重大挑战。这些模型容易出现幻觉现象,由于其基于标记概率最大化的目标,常常生成不实内容。此外,基于概率最大化的解码策略(如贪婪搜索或高束搜索)可能导致生成的文本缺乏词汇多样性,这一问题即便在拥有数千亿参数的模型中依然存在。
为了有效,科学假设不仅需要基于对当前领域广泛理解而产生的创造性洞察力,还必须扎根于现有文献,以确保其新颖性和相关性。此外,自动判断某一想法在文献中已存在的程度颇具难度,这一点尤为棘手,因为大型语言模型在生成内容时往往倾向于复制其训练数据中的子集。鉴于验证是科学方法的核心环节,大型语言模型的"黑箱"特性要求我们采取审慎而细致的方法,以确保其结果具有可重复性和稳健性。
为应对这些挑战,我们提出 HypoGen,一个包含约5500个结构化问题-假设配对的数据集,这些配对均摘自顶级计算机科学会议。该数据集标志着将科学假设生成建模为条件语言建模问题的重要一步。通过将假设条件化为对问题的清晰表述(即 位)
HypoGen 包含一个详细的推理链一种叙事,它映射了人类科学家从传统智慧迈向创新性反向提案的迭代与反思过程,从而提升所生成假设的质量与可信度。
我们的主要贡献包括开发了 HypoGen 数据集,以及将科学假设生成新颖地构想为一种带有显式推理链 的条件语言建模问题。我们展示了基于LLaMA的模型在经过针对假设生成任务微调后,在该任务上的基准性能指标。 HypoGen数据集。我们采用了一种简洁的评估框架,从新颖性和可行性 两个维度对假设进行评价,并结合自动化指标与大模型(LLM)的判断 。通过捕捉完整的推理链条,我们的方法能够深入揭示科学发现背后的思想过程,提供宝贵见解。
Related Work
几种方法将决策过程分解为多个子阶段。
在提案阶段 ,通常会运用推理,有时还会结合检索,以生成候选行动或假设。
随后,在评估阶段 ,系统会对这些候选方案进行打分(例如,采用困惑度指标Ahn等,2022或学习到的奖励函数Yao等,2020),从而筛选出最具潜力的方案。
此外,像ToT(Yao等,2023)和RAP(Hao等,2023)这样的技术,更是通过树状搜索范式,以结构化的方式同时提出并评估多种解决方案路径。而Shinn等(2023)和Lindes & Peter(2023)提出的反思性方法,则明确引入了对假设行动的迭代自我修正机制。周等(2024a)的研究进一步扩展了这一流程,利用迭代强化学习,并结合人类反馈,实现了更高效的科学假设生成。
这些进展凸显了构建基准测试的重要性,这些基准需真实反映大型语言模型在生成、验证及优化科学假设方面的能力。
然而,目前仍缺乏专门针对智能体AI系统的假设生成能力进行评估的标准化"前沿"基准测试,尤其是考虑到这类系统依赖高度互联的模块,需要复杂的推理能力。
HypoGen特别强调"推理链":每个假设都附带一条透明的溯因逻辑路径,完整还原了人类专家的思维过程 。我们的方法采用了一种结构化的"位翻转-火花+推理链"格式,清晰地展现了从初始问题陈述(Bit)到关键洞察(Spark),再到最终完善构想(Flip)的概念演进脉络 。通过融入详尽的推理链条,HypoGen有效降低了幻觉风险,同时为研究人员提供了一份可重复的、逐步展示新想法诞生过程的笔记本式文档。
Methodology and the Bit-Flip-Spark+Chain-of-Reasoning Format
图1展示了HypoGen 1的整体流程,该流程旨在利用Bit-Flip-Spark+推理链格式,从科学论文中提取结构化信息。
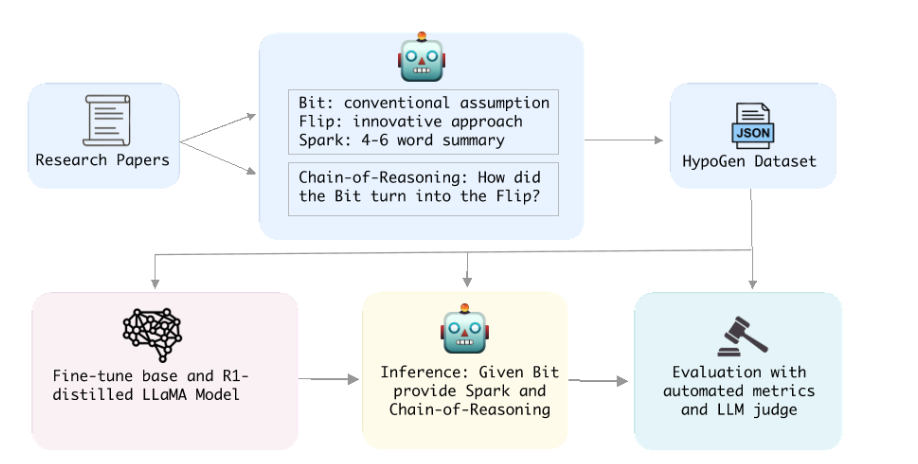
图1:HypoGen流程始于输入的论文摘要,OpenAI的o1模型从中提取出结构化的"Bit"(问题)、"Flip"(解决方案)和"Spark"(关键洞察)。论文主体内容则由o1模型提炼出推理链条。这些输出结果被用于微调基于LLaMA的模型,随后该模型根据提供的"Bit"生成假设。最后,由Claude 3.7 Sonnet构成的评审模块,依据假设的新颖性和可行性对其整体质量进行评估。
斯坦福大学的Bit-Flip框架2是一种简洁而规范的假设提出技术,专门用于概括研究论文的核心学术贡献。其中,"Bit"指出了当前研究领域中被论文试图挑战的主流观点或假设 ;而**"Flip"则清晰地阐述了论文为推动学科发展所提出的创新方法或反驳论点** 。此外,我们还引入了一个全新概念------"Spark",它精准捕捉了"思想的精髓",并以一种概念性飞跃的形式加以呈现。我们在附录A中提供了来自Bahdanau等人(2015年)的一个示例,以及生成这一表述所需的完整提示内容。
目标是将论文中复杂的思想提炼为一种简洁而严谨的表述,从而清晰地传达所要解决的问题(Flip)以及提出的解决方案(Bit)。这种方法立足于这样的认知:一个表达清晰的假设,正是推动研究产生深远影响的基石。尽管这种结构化的假设呈现方式带有一定主观性,且仅是众多选择之一,但我们发现,它非常适用于根据特定问题(即Bit)生成相应的解决方案(即Flip)。最后,推理链以详尽的叙述形式,完整记录了科学家从发现问题到提出解决方案的整个思维过程,巧妙地将Bit与Flip紧密相连。
Bit:传统神经机器翻译将整个源句子编码为一个固定长度的单一向量。然而,这种方法存在瓶颈------关键的上下文信息可能在压缩过程中丢失。
Spark:通过软对齐实现灵活翻译。
Flip:我们提出了一种创新思路,使模型能够在每个解码步骤中自动寻找源句子中与当前目标词最相关的部分。这种机制摒弃了对单一固定长度表示的依赖,转而采用一种动态聚焦于重要源信息的软对齐机制,从而显著提升了翻译的质量与灵活性。
Chain-of-Reasoning:我首先思考到,传统神经机器翻译通常依赖于一个固定长度的单一向量来编码整个源句子,然后再生成目标序列;但这种僵化的瓶颈可能导致重要上下文信息的流失,进而限制了翻译的质量与灵活性。因此,我开始质疑,是否需要一种更动态的方式来捕捉上下文线索,尤其是在处理较长序列时。为此,我引入了一种可学习的(软)搜索机制,使目标词能够动态地与源句子中最相关的内容相匹配,彻底摆脱了固定长度编码的束缚,从而更加灵活地关注上下文,最终生成质量更高的译文。我还基于大规模双语语料库训练了一个双向编码器-解码器模型,选用三万个词汇的词表,并通过小批量梯度方法进行优化,同时测试了不同大小的隐藏层结构。那么,我们如何验证新方法确实能准确识别出正确的对齐关系呢?我通过可视化对齐权重发现,解码器能够有选择地聚焦于源句中的关键词汇,显著提升了译文的清晰度与准确性。随后,我又进一步探讨了如何应对未知或罕见词汇的问题,这促使我深入研究更多提升词汇覆盖率的策略。正是在某个关键时刻,我意识到软注意力机制能够有效保留短文本和长文本输入中的核心细节,确保翻译质量的稳定提升。最后,我在独立的测试集上验证了模型的表现,结果表明,该模型不仅媲美甚至超越了基于短语的基准系统,而且在处理长句时依然表现出卓越的稳健性。这一整合式的推理过程,成功弥合了传统方法的局限性与动态对齐理念之间的差距,为实现更具上下文感知能力的神经翻译技术铺平了道路。
Preprocessing and Dataset Construction
我们从被顶级计算机科学会议NeurIPS 2023(3218篇论文)和ICLR 2024(2260篇论文)录用的论文中整理出数据集,最终得到5478个独特样本。随后,我们使用了OpenAI的 o1 用于结构化提取步骤的模型。对于每篇论文,我们首先提取出 位,翻转,和 Spark 来自抽象的组件。我们进行了提示 o1识别传统假设、创新方法,以及核心洞察的精炼4至6字概括。随后,我们采用了一种稳健的并行处理方法,并内置重试机制,每次提取最多尝试三次,以确保输出的高质量。
Fine-tuning and Inference Pipeline
我们的基线模型包括Meta LLaMA 3.1 8B和R1精炼版LLaMA 3.1 8B。这些模型在包含128,000个标记的广泛语料库上进行训练,并采用字节对编码进行标记化处理。(森里奇等人, 2015; 工藤与理查森, 2018),包含一个128,000个标记的词汇表。R1精炼版的LLaMA 3.1 8B模型是一种专门化模型,其知识源自参数规模达6710亿的更大规模DeepSeek-R1模型。这一大规模预训练赋予了模型强大的语言理解能力,这对于科学假设的生成至关重要。
我们利用精心构建的结构化问题-假设配对数据集进行微调,并采用因果语言建模目标。整个过程使用了4块NVIDIA H100 GPU,每块配备80GB显存。此外,我们实施了4位量化技术,并部署了LoRA模型。(胡等人, 2021) 带有超参数: α = 16 以及0.1的丢弃率。模型以4位精度进行基础加载,并根据需要采用适当的计算精度(在支持的情况下使用bf16,否则使用fp16)。我们还采用了8位的AdamW优化器。(洛什奇洛夫 & 胡特, 2017) 具有0.01的权重衰减、32的批量大小以及2的学习率 × 10−4. 训练过程采用线性学习率调度器,包含5个预热步,总训练步数约为60步,并在每一步进行日志记录。在推理阶段,仅使用 位 被提供给模型。随后,模型生成相应的 Spark 以及一份详细的 推理链. 我们使用 Ollama 用于LLaMA单次推理的LLM框架。
Evaluation
评估专为生成科学假设而设计的生成模型是一项充满挑战的任务,因为科学研究本身具有高度的主观性。在本文中,我们提出了一种双层评估框架,主要结合了传统的自动化指标与基于大语言模型的评判器。
我们的评估策略依托于一个由50个假设组成的测试集,这些假设均摘自2024年和2025年近期发表的文献。该框架将自动化指标与一个LLM评判模块相结合,通过两两比较的方式,从新颖性、可行性及整体质量等方面对假设进行综合评估。此外,我们还使用第二个LLM评判器进一步验证了这一方法的稳健性。对于评估集中的部分样本,我们还采用了人工评估,以检验在HypoGen数据集上微调LLaMA-base模型是否能有效提升生成假设的质量。
作为初步评估指标,我们采用了困惑度(Perplexity),用于衡量所生成假设的流畅性和连贯性(Chen et al., 1998)。困惑度被定义为给定标记序列X的负对数似然平均值的指数函数。
IAScore用于量化LLM生成的假设与专家提出的研究思路之间的契合度。对于每篇论文j,IAScore通过IdeaMatcher(IM)模型(Kumar等,2024),计算作者提出的未来研究思路(AP-FRIj)与每项生成想法Iij之间的平均契合度:
随后,针对整个领域的模型M,IAScore通过将所有P篇论文的得分取平均来计算:
Kumar等人(2024)之所以选用GPT作为IdeaMatcher,正是因为它在判断生成的想法是否包含于作者提案中的表现更为出色------准确率达到91.8%,远超基于RoBERTa MNLI和BERTScore的自然语言推理方法。因此,较高的IAScore值表明LLM生成的想法与作者视角在整个领域内具有更强的一致性。
此外,Idea Distinctiveness Index则通过嵌入式相似度而非表面文本差异,评估所生成假设之间的语义多样性。具体而言,对于一组想法I,每个想法idi都会被转换为向量vi,方法是利用预训练的BERT模型(Kumar等,2024)。其中,idi与idj之间的区分度定义为Dij = 1 − sim(vi, vj),而sim表示余弦相似度。最终,整组n个想法的整体区分度计算公式如下:
为了衡量模型在特定领域内的表现,我们可针对模型M为每篇论文p生成的所有想法,分别计算其Idea Distinctness Index DIpM,再对全部m篇论文的结果取平均值:
较高的Ddomain,M值意味着更高的想法多样性,反映出该模型能够在领域内生成语义各异的研究假设的能力。
为了评估我们评测集中的假设质量,我们采用了Anthropic的Claude 3.7 Sonnet-Thinking模型作为自动化评估工具。在每个数据集中,我们对50道题目进行了两两对比评估:每项评估实验均由两个大语言模型分别生成的一组配对解决方案构成。我们共设计了九个实验,具体包括:LLaMA 3.1-8B-FT(简称为LLaMA-8B-FT)与人类的对比;LLaMA 3.1-8B-FT(LLaMA-8B-FT)与单样本o1模型的对比;随后是R1精馏版LLaMA-3.1-8B-FT(R1-distilled-LlaMA-FT)与人类、以及与o1-1shot的对比;LLaMA-8B-FT与R1精馏版LLaMA-8B-FT的对比;人类与o1-1shot的对比;R1精馏版LLaMA-8B-1shot与R1精馏版LLaMA-8B-FT的对比;LLaMA-8B-1shot与LLaMA-8B-FT的对比;以及LLaMA-8B-1shot与R1精馏版LLaMA-8B-1shot(R1-distilled-LlaMA-1shot)的对比。我们的实验结果如图2所示。其中,人类生成的假设即为基于评测集生成的o1结构化假设。
对于每个问题,LLM评估器被要求判断哪一种方案(Spark + 链式推理)在新颖性和可行性方面提供了更优的整体建议。
我们随机调整解决方案的呈现顺序,以减少顺序效应。每次评估实验结束后,我们会记录方案A在新颖性、可行性和整体表现上是否胜出,同时允许出现平局情况。此外,为了鼓励深入思考,我们还为模型提供了8000个token的"思考"预算。
基于大语言模型的评估方法具备一致性和可扩展性,但同时也牺牲了稳健性和可验证性。为应对这些挑战,我们使用OpenAI的o3-mini模型作为裁判,重新进行了实验分析,以检验两者的意见一致性程度。此外,我们还开展了盲法的人工评估,由一位作者对20组假设进行逐一评判。完整的提示内容请参见附录A。
自动化指标表1的结果显示,人类生成的假设困惑度值远高于其对应的大型语言模型(LLM)版本。尤其是,LLaMA基础模型的困惑度介于16.70到34.98之间,而人类生成的假设则高达89.31。这可能表明,人类生成的想法中蕴含着更强的语义创造力 。尽管整体困惑度仍较低,但经过微调后,LLaMA模型的困惑度得分有所上升,反映出其在构思阶段表现出更高的"不可预测性"。
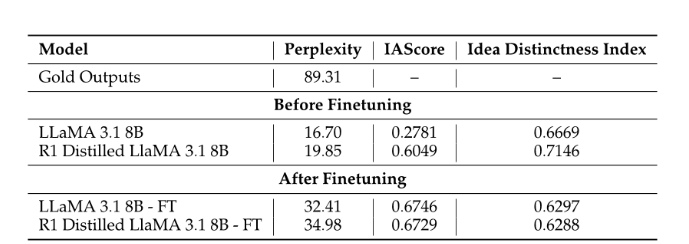
表1:比较不同模型输出的自动化评估指标。IAScore衡量的是观点与源材料的一致性,而观点独特性指数则用于量化生成假设的独特性。
其次,微调显著提升了模型与目标领域的契合度,这一点从标准LLaMA模型的IAScore大幅提高(从0.2781提升至0.6746)可见一斑。这一结果或许意味着,通过结构化的Bit-Flip-Spark+Chain-of-Reasoning训练方法,模型能够生成更贴近专家级科学思维的假设。值得注意的是,这种效果在经过蒸馏处理的LLaMA模型中并不明显,这可能暗示了知识迁移机制的有效性。
此外,IAScore的提升与Idea Distinctness Index的下降之间存在明显的反比关系------尤其在R1蒸馏版LLaMA模型中,该指数从0.7146显著降至0.6288。这一现象表明,模型在更好地贴合专家级科学思维模式的同时,可能会牺牲一定的语义多样性,从而导致输出内容的差异化程度降低。
如图2上半部分所示,LLM评委的两两比较结果显示,尽管微调版本在新颖性评分上有所下降,但其整体假设质量却始终优于同架构的一次性生成版本(偏好率高达86%-92%),这充分说明,在HypoGen数据集上的微调训练有效地引导模型生成更具实用价值的假设。
最后,LLM评估的第二组实验进一步揭示了不同实验中新颖性与可行性之间的权衡关系:那些在创造性指标上表现突出的模型,往往在可行性方面稍显不足;反之亦然。总体而言,由人类生成的假设在质量评估中全面胜出,占据了80%到90%的比较优势;然而,经过微调的模型则展现出与之相当的可行性评分。
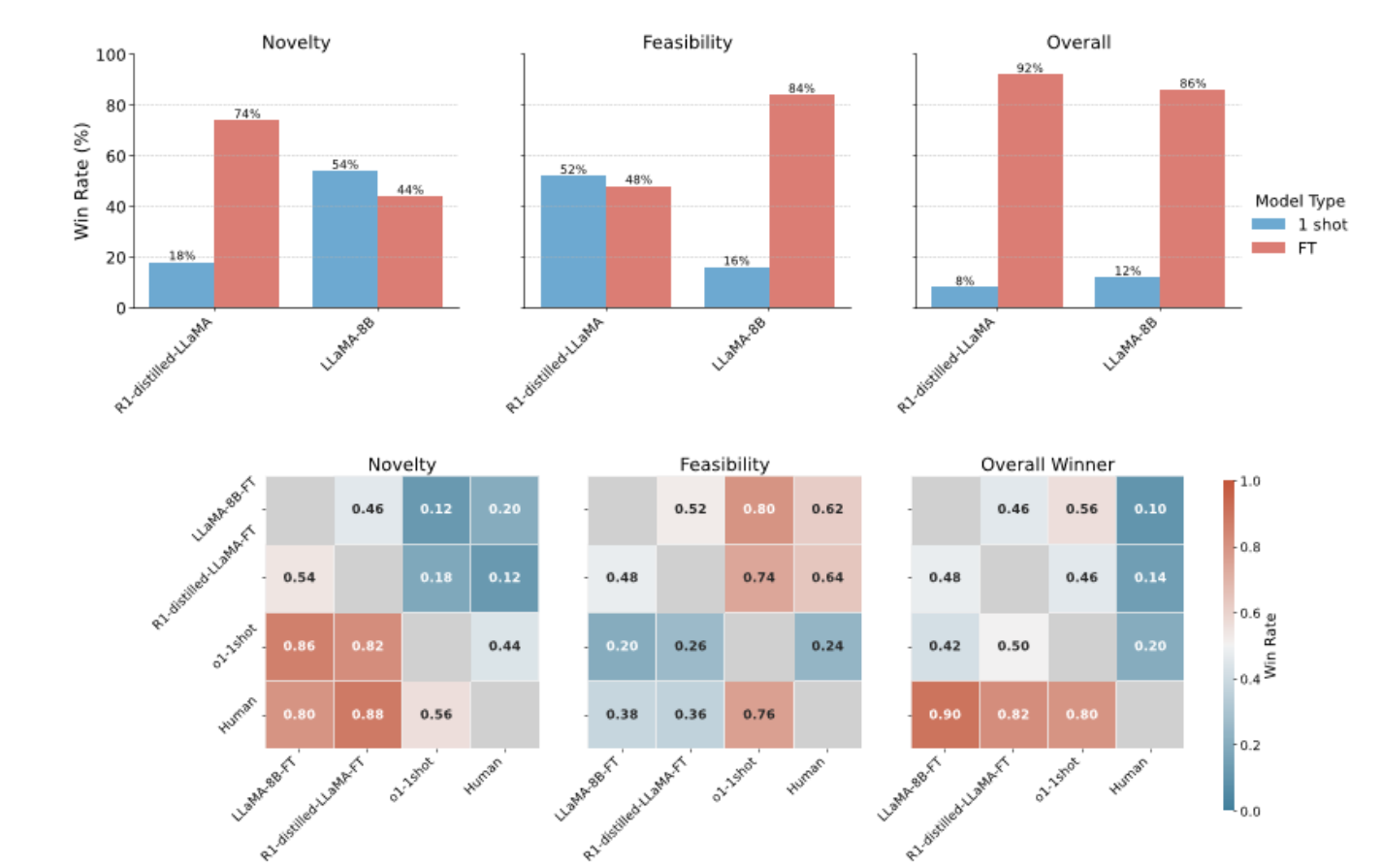
图2:由LLM评测员Claude 3.7 Sonnet对九个实验中生成假设质量的对比分析。上图:比较未微调与微调后的LLaMA 3.1-8B(LlaMA-8B-FT)及R1精馏版LLaMA-3.1-8B(R1-distilled-8B-FT)模型在新颖性和可行性上的胜率,显示了两者之间的一致权衡------微调模型在可行性方面表现更佳(胜率74%-86%),而未微调版本则更具新颖性(胜率54%-86%)。下图:展示了人类专家、微调模型(LLaMA-8B-FT、R1-FT)以及单次提示模型(O1-1shot、LLaMA-8B-1shot、R1-1shot)在新颖性、可行性和整体质量三个维度上的两两胜率热图。其中,人类提出的假设稳居胜局(胜率82%-90%),而微调模型在可行性评分上与人类相当(62%-64% vs. 人类)。此外,微调模型在整体质量上优于其单次提示版本(胜率86%-92%)。
人类评估结果表明,小规模的人类评估验证了Claude 3.7 Sonnet思维模型所观察到的模式。在R1精馏版LLaMA的对比中,人类评估者更倾向于微调模型的输出 ,认为其在新颖性(95% vs. 5%)和可行性(70% vs. 30%)方面表现更优,且总体上更偏好微调模型的输出(微调模型偏好70%,平局25%,基础模型仅5%)。而在标准LLaMA-8B的对比中,微调模型的表现略显逊色,尽管仍保持一定的优势:在新颖性方面,微调模型略占上风(47.6% vs. 42.9%,9.5%为平局);在可行性方面,微调模型同样占据微弱优势(52.4% vs. 42.9%,4.8%为平局),导致整体偏好度更为接近(微调模型42.9%,单次提示模型33.3%,平局23.8%)。这一评估结果进一步证实,基于结构化Bit-Flip-Spark+Chain-of-Reasoning数据进行微调确实能有效提升假设的质量,尤其在R1精馏架构中,这种提升尤为显著。不过,目前仍需开展更多的人类评估工作以深入验证这些发现。
Discussion and Future Work
我们推出了HypoGen数据集,用于生成科学假设。该数据集在传统的Bit-Flip-Spark格式基础上,新增了详细的推理链组件。实验表明,在HypoGen上进行微调后,LLaMA 3.1-8B和R1-distilled-LLaMA 3.1-8B模型的假设能力均得到了显著提升。这充分证明了在创意构思的中间环节进行微调的有效性,能够进一步增强模型的 透明性与可解释性。我们以MIT许可证发布HypoGen,旨在推动人工智能代理的发展,使其能够协助人类专家完成创意构思过程。
HypoGen的主要局限在于,它采用大语言模型(LLM)来评估所生成的假设。尽管在特定条件下,以LLM为"裁判"的模块表现稳健(Lu et al., 2024a),但其训练方式仍可能以微妙而复杂的方式引入偏见。为缓解这些意想不到的影响,我们计划开展大规模的人工评估,以明确人类与LLM在特定判断上的一致程度。这些研究发现将指导我们构建更加稳健的奖励模型,使其更贴近人类的专业知识,从而进一步提升HypoGen在现实世界科学发现中的应用价值。
展望未来,我们希望探索HypoGen方法如何推广至其他科学领域。目前,我们的评估主要集中在计算机科学领域,但微调技术在一个领域的表现能否有效迁移到其他领域,仍是一个开放性问题。此外,我们还计划扩展数据集,涵盖天体物理学、生物学和材料科学等领域,因为这些领域中的假设生成有望加速各具特色的科学突破。这项工作致力于打造跨学科的人工智能伙伴,与人类专家携手应对极具挑战性的科学任务(Swanson et al., 2024),最终目标是让科学更加普惠大众。