拆解Paris:零通信训练是否能成为AI去中心化的下一个热点?
简介
最近,一篇名为《Paris: A Decentralized Trained Open-Weight Diffusion Model》的论文在引起了我的关注。我在简单研读其代码和关联工作(DDM, DiT)后,想以开发者的视角,与各位一同拆解Paris论文,分享我们从中学到的经验。技术的进步始于敏锐的观察与开放的交流,希望本文能成为一块引玉之砖。
我为何关注Paris?
与现有去中心化基线相比,Paris 展示了卓越的资源效率。该模型仅使用 1100 万张 LAION-Aesthetic 图像就实现了具有竞争力的生成质量,比 DDM 基线所需的 1.58 亿张图像减少了 14.4 倍。计算需求同样令人印象深刻,仅需 120 个 A40 GPU-天(相当于约 72 个 A100 GPU-天),而 DDM 则需要约 1176 个 A100 GPU-天,计算量减少了 16.3 倍。
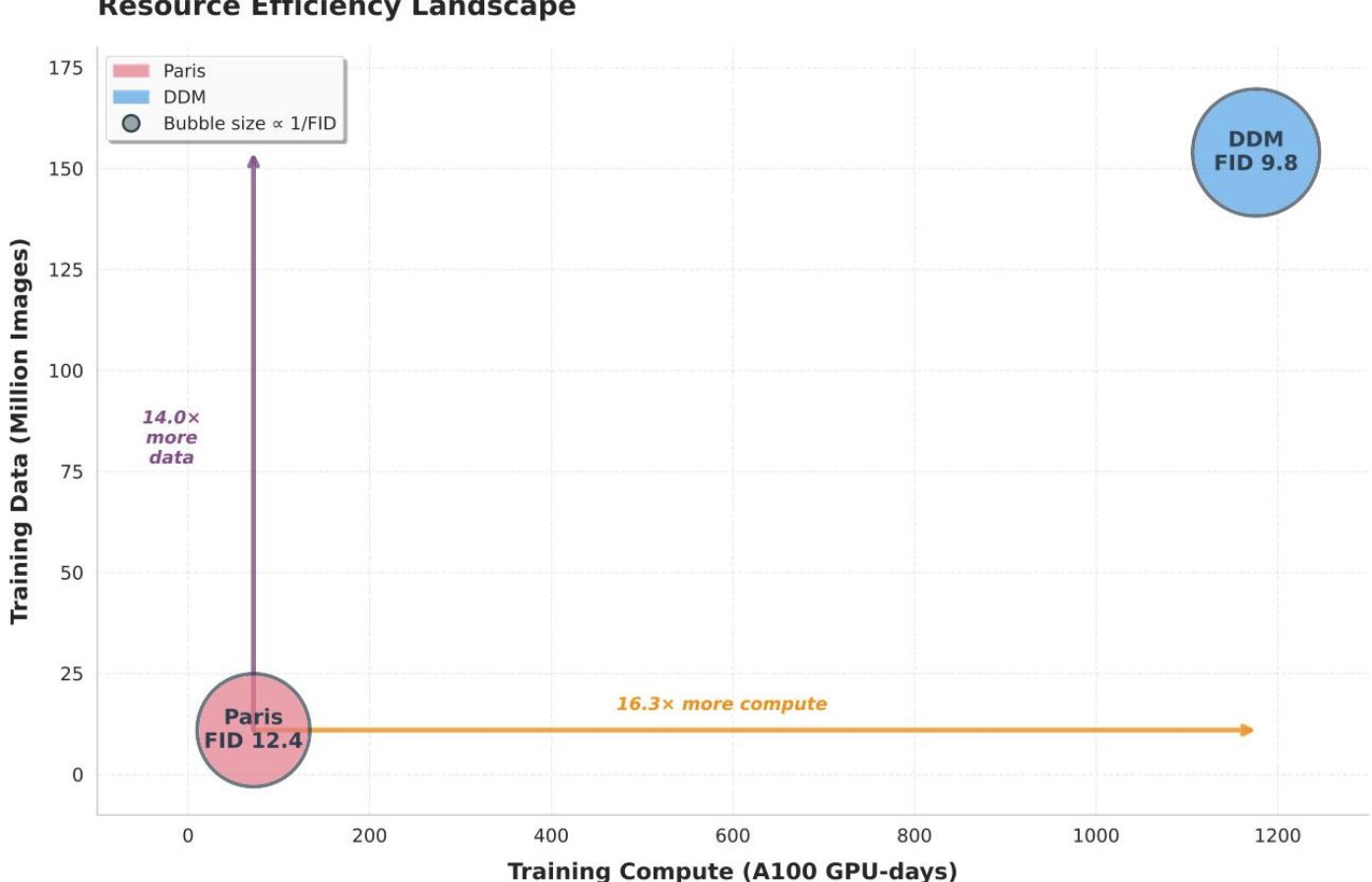
尽管使用了显著更少的资源,Paris(DiT-XL/2,Top-1)的 FID 达到了 12.45,而 DDM 为 9.84------仅高出 1.27 倍的 FID,同时计算量减少了 16.3 倍。对于 DiT-B/2 架构,Top-2 加权集成策略在 Laion-art 上取得了最佳 FID-50K 分数 22.60,比单一基线提高了 7.04 分。
技术溯源:从DiT、DDM到Paris的演进
参考李沐学AI中提到的"好的论文会让你想看一下它的reference",我这里看了下Paris的两篇重要的Reference paper,DIT和DMM。
DiT,基于Transformer的可扩展扩散模型
扩散 Transformer (DiT) 架构,它作为 Paris 框架中每个专家模型的骨干。Paris 论文明确选择 DiT 是因为它与 U-Net 相比具有卓越的扩展性能,这使得此引用对其架构设计和实现至关重要。
核心架构与方法
DiT架构在潜在扩散模型(LDM)框架内,用标准的视觉Transformer(ViT)设计取代了扩散模型中传统的U-Net骨干网络。这一选择使得模型能够在压缩的潜在空间而非直接在像素上工作,从而显著降低了计算要求,同时保持了生成质量。
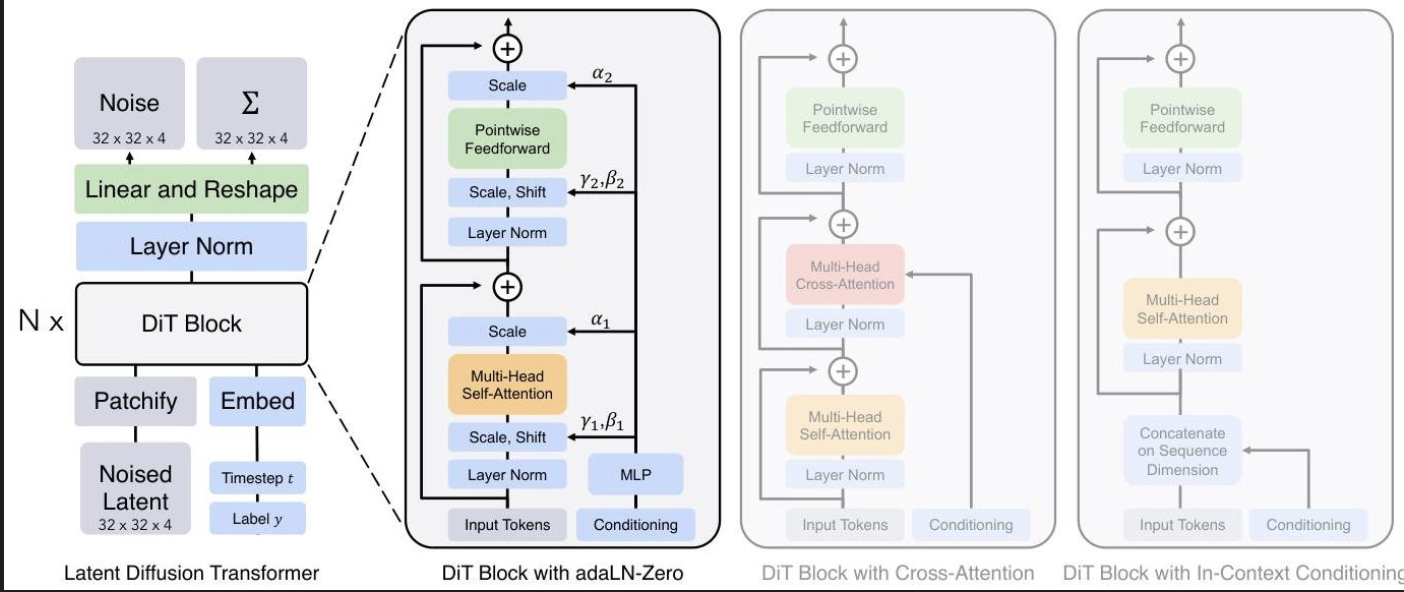
核心创新在于DiT块设计,它将图像块作为token进行处理,同时整合了扩散时间步和类别标签的条件信息。
DiT 模型在类别条件 ImageNet 生成方面取得了新的最先进成果:
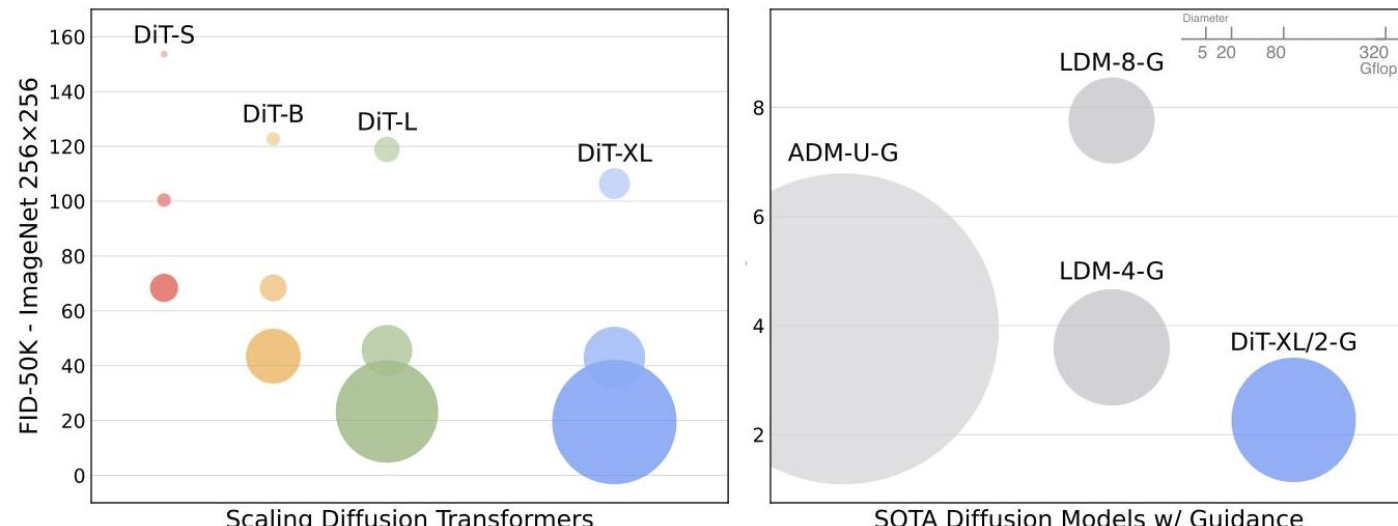
- ImageNet 256×256:DiT-XL/2 实现了 2.27 的 FID 分数,超越了之前扩散模型 (LDM-4: 3.60) 和 GANs (StyleGAN-XL: 2.30) 的最佳结果。
- ImageNet 512×512 :实现了 3.04 的 FID 分数,显著优于 ADM (3.85)。
考虑到计算效率,这些结果尤其令人印象深刻:DiT-XL/2 使用的 Gflops 显著少于像素空间 U-Net 模型,同时达到了卓越的质量。
DDM,Decentralized Diffusion Models
本文为去中心化扩散模型训练奠定了基础框架,Paris模型在此基础上进行了直接的扩展和改进。Paris模型采纳了其在分区数据上训练独立专家模型的核心方法,并提供了一种比该基线更资源高效的实现。
理解范式转变
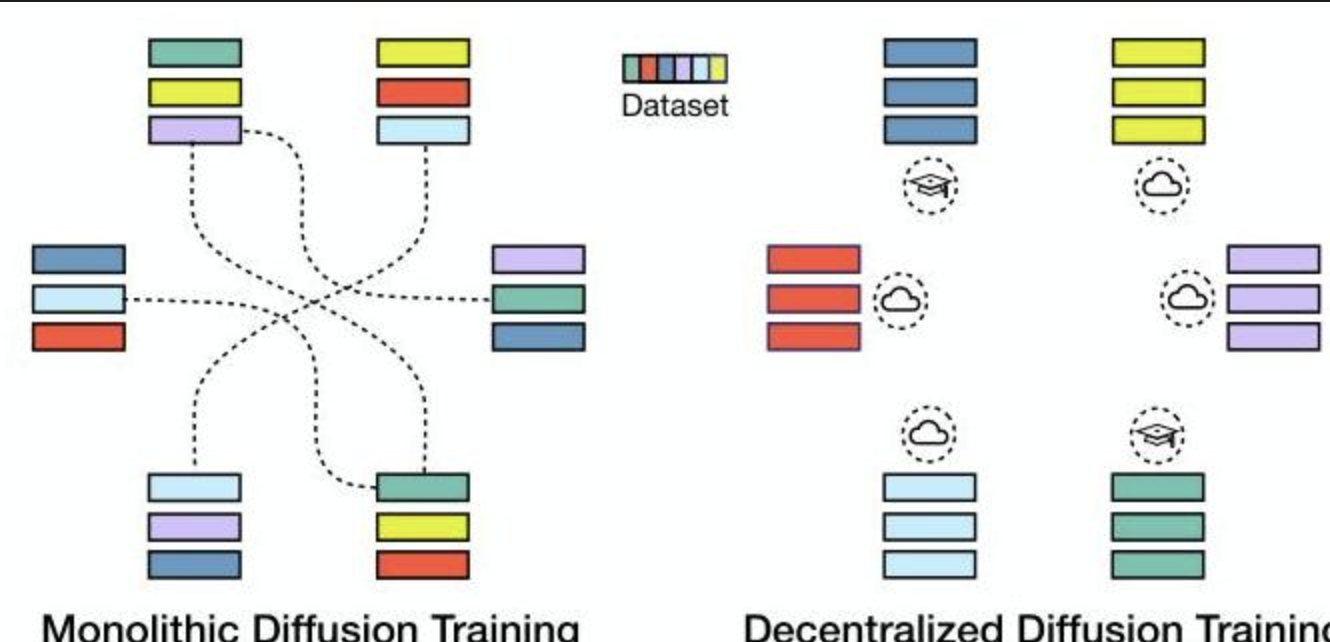
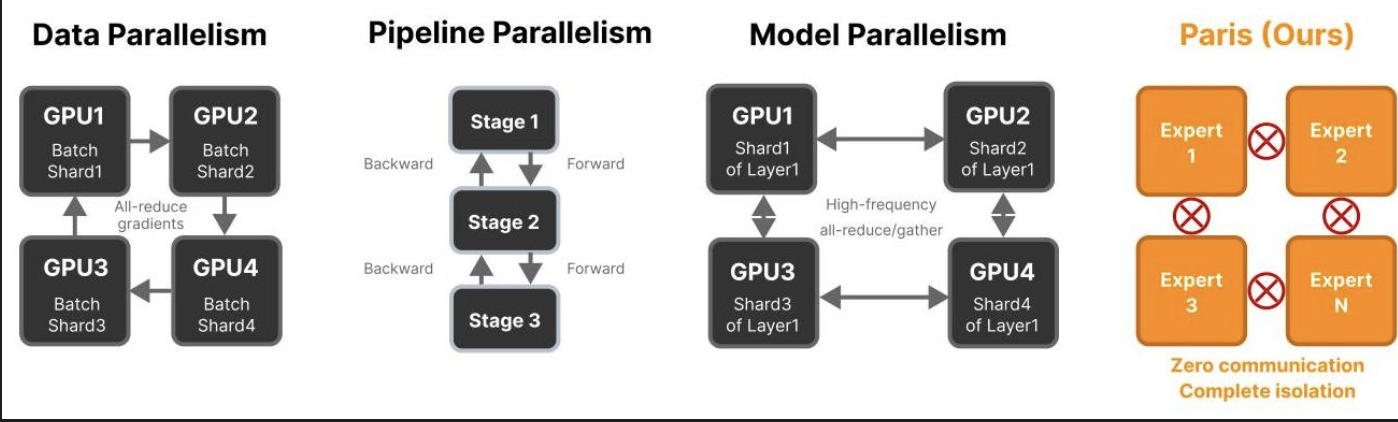
去中心化扩散模型(DDM)代表了大型生成式AI模型训练方式的根本性转变。传统的扩散模型训练需要跨数千个通过高带宽网络连接的GPU进行同步计算,这带来了巨大的基础设施障碍。上图左侧展示了这种单体方法,其中所有组件必须持续通信。相比之下,DDM将训练过程分解为独立的"计算孤岛",它们可以独立运行,如右侧所示。
该论文解决了现代AI发展中的一个关键瓶颈:最先进扩散模型的计算需求呈指数级增长。训练像Stable Diffusion或Meta的Movie Gen这样的模型需要具有专用网络基础设施的中心化集群,这使得只有大型公司才能获得此类能力。这种中心化对创新造成了显著障碍,特别是对于学术研究人员和小型组织而言。
为了解决加载多个专家模型造成的内存开销,作者展示了成功的知识蒸馏。一个单一的密集学生模型从分布式专家集合中学习,在仅使用四分之一批次大小和三分之一训练FLOPs的情况下,实现了与单一基线模型(monolithic baselines)相当的性能。
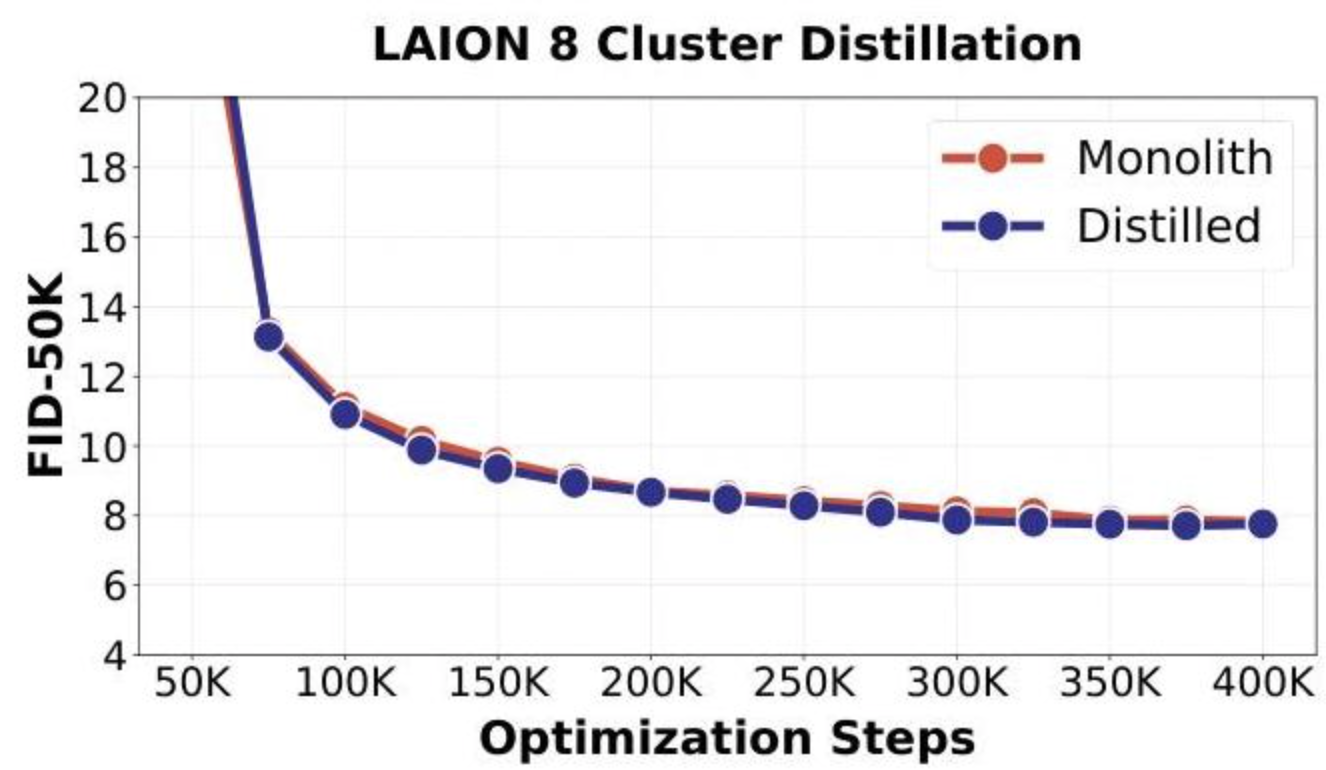
蒸馏过程包括在相同数据集上训练学生模型,但使用来自适当专家(由聚类标签确定)的预测而非原始数据对其进行监督。这种方法成功地将专家集合的集体知识转移到一个可部署的单一模型中。
Paris:我们能从中学到什么?
"零通信"的勇气:
Paris 框架与传统分布式训练范式有着根本性的不同。与数据并行、模型并行或流水线并行不同------所有这些都需要同步和专用硬件互连------Paris 采用零通信方法。
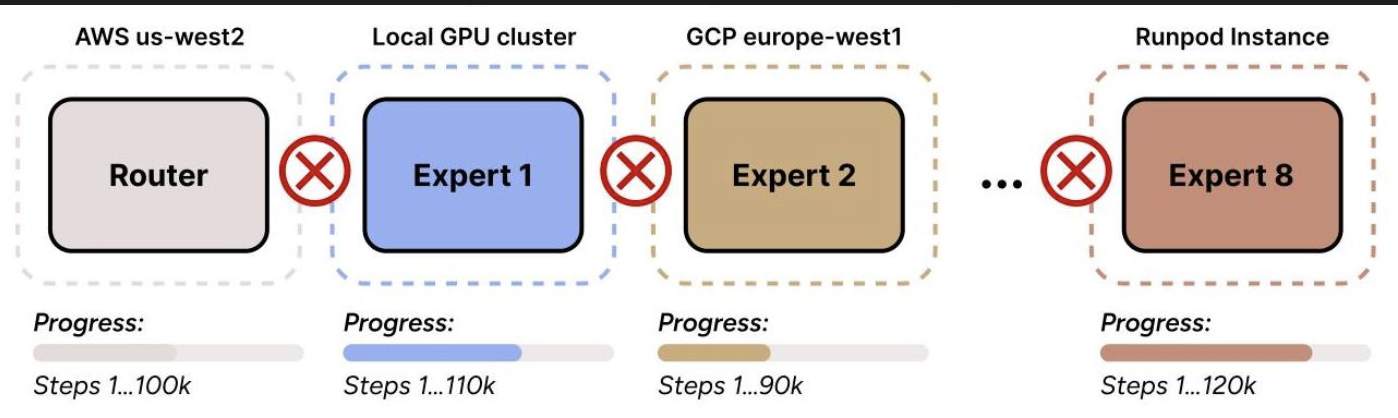
训练基础设施跨越异构的、地理上分布的资源,包括 AWS、GCP、本地 GPU 集群和 Runpod 实例。每个专家以不同的速度异步训练,无需任何协调,消除了困扰传统方法的瓶颈和硬件限制。
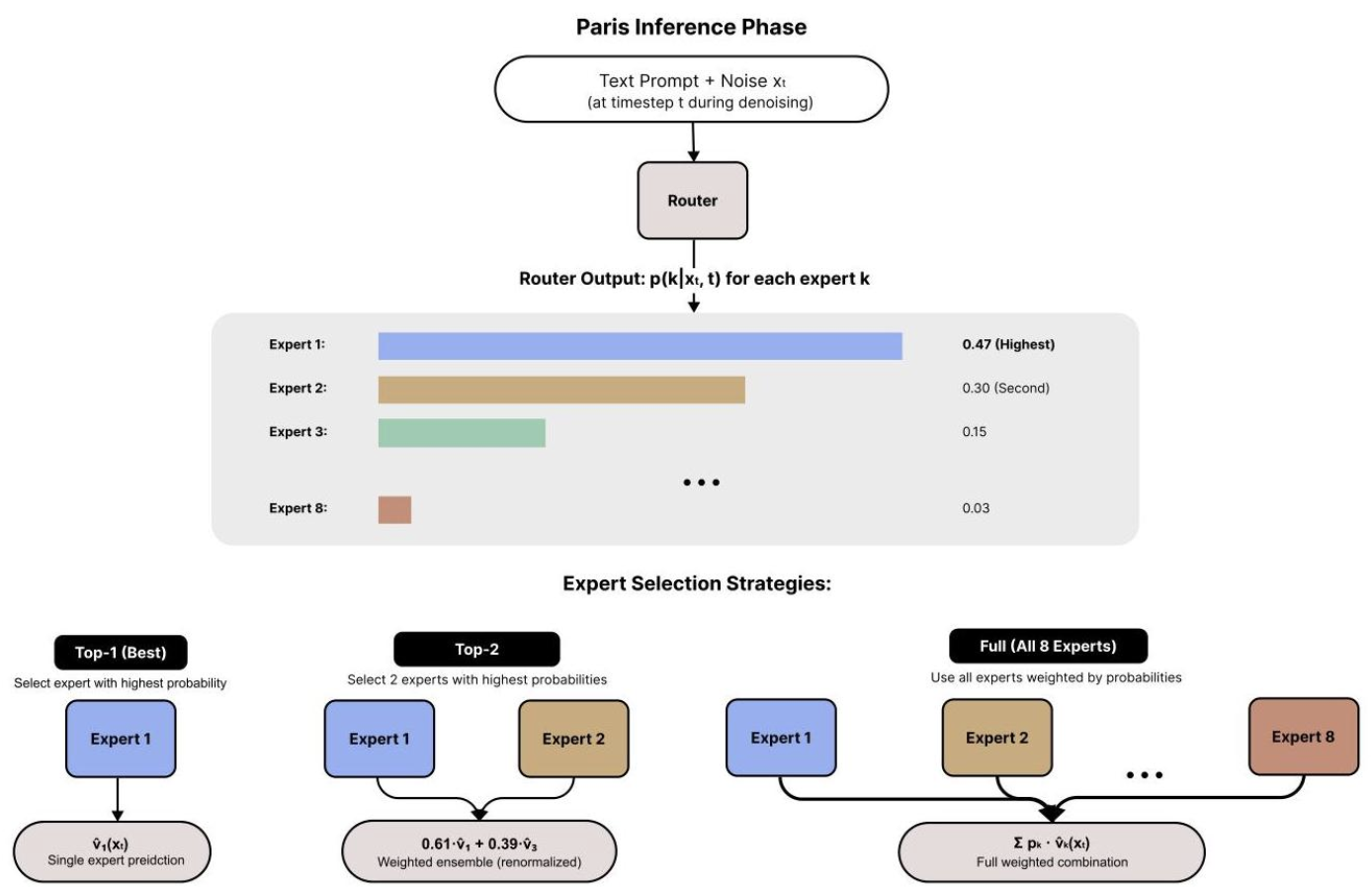
一个独立的路由器网络,作为轻量级 DiT 变体实现,在完整数据集上独立训练。路由器学习预测给定噪声潜在 x t x_t xt 在时间步 t 时,专家 k 最相关的概率 p ( k ∣ x t , t ) p(k|x_t, t) p(k∣xt,t)。这种时间步感知的处理允许路由器根据去噪阶段调整其分类策略。
推理与专家协调
在推理过程中,路由器通过三种策略动态协调专家协作。"Top-1"方法选择置信度最高的单个专家,提供最大的计算效率。"Top-K 加权集成"结合了来自 K' 个最相关专家的预测,并根据重新归一化的路由器概率进行加权。"完全集成"整合了所有专家,但由于不那么相关的专家的噪声,其性能通常不佳。
结语
可以畅想,我训练/微调一个本地的,懂我的专家,而云上存在其他几位公共领域的专家这样的场景以后会成为可能。
你对Paris的"零通信"设计怎么看?它是未来趋势还是一个有趣的工程特例?欢迎在评论区分享你的观点,让我们一同碰撞出更多火花。
资源链接(请根据实际情况替换):