一、前言:从图像识别到通用感知的时代转折
如果要给深度学习画一条时间轴,那么 2012 年的 AlexNet 无疑是分水岭。那一年,ImageNet 图像识别比赛中,AlexNet 以巨大优势击败传统算法,深度学习这个在学术角落里沉睡多年的概念,一夜之间成为主角。
但这场革命其实早在更久之前就埋下了种子。
在 1998 年,LeCun 提出了 LeNet-5 ------ 一个看起来平平无奇的小型卷积网络,却第一次真正实现了端到端的数字识别任务。那时没有 GPU,没有大规模数据,但思想已经在那里:让机器自己学到特征,而不是人去定义特征。
从 LeNet 到 Transformer,跨度 20 余年。期间我们见证了从"局部感受野"到"全局注意力"的思想变迁,也见证了深度学习从计算机视觉的一角,走向语言、语音、生成模型的全面胜利。
这篇文章,我们从头开始,不仅讲网络结构,更讲清楚每个模型背后的动机------
每一次架构的诞生,都是为了解决上一个架构的局限。
二、LeNet:卷积神经网络的原初形态
在 LeNet 出现之前,图像识别通常依赖手工特征:边缘检测、HOG、SIFT 等。这些特征固然有效,但通用性差,且无法捕捉复杂的模式。
LeNet 的关键思想,是让神经网络自动学习"空间层次结构":
低层感受边缘,高层感受形状,再高层理解语义。
LeNet-5 的架构如下(简化版):
Input (32x32)
→ Conv1 (6@28x28)
→ AvgPool1 (6@14x14)
→ Conv2 (16@10x10)
→ AvgPool2 (16@5x5)
→ FC1 (120)
→ FC2 (84)
→ Output (10)核心理念有三:
-
局部连接 :神经元不再与所有输入相连,只关注邻域像素。
→ 模拟人类视觉皮层的"感受野"概念。
-
权值共享:同一卷积核在图像不同位置滑动,意味着参数数量大幅减少。
-
下采样(Pooling):通过空间压缩,获得平移不变性。
伪代码如下:
for each filter in conv_layer:
for each patch in image:
output[x][y] = sum(filter * patch)在今天看来这稀松平常,但在上世纪 90 年代,这种"共享参数"的思想几乎颠覆了传统神经网络。
LeNet 的意义:
让神经网络第一次真正"看见"了图像。
三、AlexNet:GPU、ReLU 与大规模数据的爆炸
LeNet 的思想是正确的,但在当时无法规模化:CPU太慢、数据太少、网络太深会梯度消失。
直到 2012 年,Hinton 的学生 Alex Krizhevsky 用 GPU 把这个问题彻底解决了。
AlexNet 的创新主要有四点:
-
GPU 计算:两块 GTX 580 显卡,把训练时间从几周缩短到几天;
-
ReLU 激活 :用
max(0, x)代替 Sigmoid,有效解决梯度消失; -
Dropout:随机"丢弃"部分神经元,防止过拟合;
-
数据增强:旋转、翻转、裁剪,让网络见到更多"样本变化"。
结构大体如下:
Input → Conv → ReLU → Pool → Conv → ReLU → Pool → FC → Dropout → FC → Softmax训练效果直接把传统机器学习打成废墟------Top-5 错误率从 26% 降到 16%。
但更重要的是,AlexNet 证明了"深度"确实有意义 :
层数越多,网络的抽象能力越强。
四、VGG:用简单堆叠追求极致
AlexNet 虽强,但结构杂乱。2014 年的 VGG 提出了极其简单的思想:
"我们不搞花样,只用 3x3 卷积,一个接一个堆。"
VGG 的典型结构是:
[Conv3-64, Conv3-64] → Pool → [Conv3-128, Conv3-128] → Pool → [Conv3-256, Conv3-256, Conv3-256] → Pool → FC这种"纯净堆叠"的策略,让网络在 ImageNet 上性能进一步提升,也为后来的模块化结构奠定了基础。
伪代码:
def vgg_block(in_channels, out_channels, num_convs):
for i in range(num_convs):
x = conv3x3(x)
x = relu(x)
x = max_pool(x)
return xVGG 的价值 在于:它把网络结构从"艺术"变成了"工程",
让后人有了标准化的构建方式。
五、ResNet:解决"深了反而更差"的悖论
随着层数继续增加,人们发现一个怪现象:
网络越深,反而训练误差更高。
不是过拟合,而是优化失败。梯度在层间传播时会逐渐衰减或放大,导致训练困难。
ResNet(2015)提出了突破性的方案:残差连接(Residual Connection)。
核心思想:
不要让每一层都去学习"完整映射",只学习相对于输入的"残差":
y=F(x)+xy = F(x) + xy=F(x)+x
伪代码如下:
def residual_block(x):
out = conv_bn_relu(x)
out = conv_bn(out)
return relu(out + x)这一条简单的"捷径"让 152 层的网络成功训练,并刷新所有指标。
更重要的是,ResNet 的结构让优化更可控,也启发了后来的 Transformer:
"让信息可以跨层流动,避免被阻断。"
六、Transformer:从局部卷积到全局建模
2017 年,Vaswani 等人提出 Transformer。
这不是对卷积的改进,而是一次范式转变。
卷积善于提取局部模式,但难以建模远距离依赖。Transformer 则完全放弃卷积,用**自注意力(Self-Attention)**机制实现全局建模。
核心思想:
每个位置都能根据内容,自主决定"关注谁"。
公式如下:
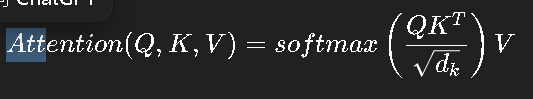
伪代码:
for each token i:
for each token j:
score[i][j] = dot(Q[i], K[j]) / sqrt(dk)
attention[i] = softmax(score[i]) @ V相比卷积:
-
没有固定感受野;
-
可以动态关注全局;
-
参数更少,泛化更强。
起初它服务于 NLP,但后来人们发现它对图像、语音、视频同样有效。
于是有了 ViT(Vision Transformer)------用注意力机制处理图像块(Patch)。
七、从 LeNet 到 Transformer:思想的递进
我们可以这样理解整个脉络:
| 时代 | 代表模型 | 关键思想 | 解决的问题 |
|---|---|---|---|
| 1998 | LeNet | 局部连接、权值共享 | 自动特征提取 |
| 2012 | AlexNet | 深层结构、GPU、ReLU | 梯度消失与性能瓶颈 |
| 2014 | VGG | 模块化堆叠 | 架构规范化 |
| 2015 | ResNet | 残差学习 | 深层退化问题 |
| 2017 | Transformer | 全局注意力 | 长依赖与信息瓶颈 |
可以看到,这是一条非常自然的演化线:
每一步都在解决上一步的缺陷,而不是取代它。
八、现代趋势:轻量化、多模态与统一架构
随着模型越来越大,算力成本成为主要矛盾。
于是 MobileNet、EfficientNet 等"轻量化模型"出现,用深度可分离卷积、自动架构搜索(NAS)等手段降低复杂度。
另一方面,Transformer 在语言和视觉上的成功,也催生了"统一架构"理念:
无论是文字、图像、语音,都可以用相似的注意力机制建模。
现在的 GPT、Gemini、Claude、LLaVA 等多模态模型,
其实都是 Transformer 思想的延伸:输入变了,核心机制没变。
九、结语:从模仿到抽象,从局部到全局
深度学习的演进,不是一连串模型的更替,而是一种思维的递进。
从 LeNet 的局部感受野,到 Transformer 的全局注意力,
我们看到的,是人类在不断逼近"通用表示"的过程。
未来的模型可能会回归简洁,也可能更复杂;
但可以肯定的是------
每一代架构的成功,都源于工程理性与数学洞察的平衡。