
🔥个人主页:************************************************************************************************************************************************************************************************************************************************************胡萝卜3.0****************************************************************************************************************************************************************************************************************************************************************
📖个人专栏:
⭐️人生格言:不试试怎么知道自己行不行
🎥胡萝卜3.0🌸的简介:


目录
[一、 别再停留在"会用"!深挖string底层,真正理解字符串](#一、 别再停留在“会用”!深挖string底层,真正理解字符串)
[1.1 只会调用string接口,够用吗?](#1.1 只会调用string接口,够用吗?)
[1.2 理解string底层,究竟有什么价值?](#1.2 理解string底层,究竟有什么价值?)
[二. 0基础手撕:从0搭建string核心底层逻辑(附实现代码)](#二. 0基础手撕:从0搭建string核心底层逻辑(附实现代码))
[2.1 底层构造逻辑:string类的成员变量与构造逻辑](#2.1 底层构造逻辑:string类的成员变量与构造逻辑)
[2.1.1 构造与析构:对象的 "创建" 与 "销毁"](#2.1.1 构造与析构:对象的 “创建” 与 “销毁”)
[2.1.1.1 打印](#2.1.1.1 打印)
[2.1.1.2 构造:对象的"创建"](#2.1.1.2 构造:对象的“创建”)
[2.1.1.3 析构:对象的"销毁"](#2.1.1.3 析构:对象的“销毁”)
[2.2 迭代器与下标:string遍历的"两大高效工具"](#2.2 迭代器与下标:string遍历的"两大高效工具")
[2.2.1 operator\[\] 的底层逻辑与实现](#2.2.1 operator[] 的底层逻辑与实现)
[2.2.2 迭代器的基本框架和实现](#2.2.2 迭代器的基本框架和实现)
[2、const 对象](#2、const 对象)
[2.2.3 遍历+修改](#2.2.3 遍历+修改)
[1、下标+ ](#1、下标+[ ])
[2.3 字符串修改:push_back,append,insert与+=的实现](#2.3 字符串修改:push_back,append,insert与+=的实现)
[2.3.0 容量管理:resize和reserve的协同使用](#2.3.0 容量管理:resize和reserve的协同使用)
[2.3.0.1 reserve](#2.3.0.1 reserve)
[2.3.0.2 resize](#2.3.0.2 resize)
[2.3.1 尾插单个字符:push_back的实现](#2.3.1 尾插单个字符:push_back的实现)
[2.3.2 追加字符串:append的实现](#2.3.2 追加字符串:append的实现)
[2.3.3 运算符重载:+=实现字符 / 字符串追加](#2.3.3 运算符重载:+=实现字符 / 字符串追加)
[2.3.4 任意位置插入:insert的实现(插入字符/字符串)](#2.3.4 任意位置插入:insert的实现(插入字符/字符串))
[2.4 字符串删减与截取:erase,clear与substr的实现](#2.4 字符串删减与截取:erase,clear与substr的实现)
[2.4.1 任意位置删除:erase的实现(删字符/删区间)](#2.4.1 任意位置删除:erase的实现(删字符/删区间))
[2.4.2 清空字符串:clear的实现](#2.4.2 清空字符串:clear的实现)
[2.4.3 截取子串:substr的实现](#2.4.3 截取子串:substr的实现)
[2.5 拷贝构造和赋值重载](#2.5 拷贝构造和赋值重载)
[2.5.1 拷贝构造](#2.5.1 拷贝构造)
[2.5.2 赋值重载](#2.5.2 赋值重载)
[2.6 流插入<<、流提取>>和getline](#2.6 流插入<<、流提取>>和getline)
[2.6.1 流插入<<](#2.6.1 流插入<<)
[2.6.2 流提取>>](#2.6.2 流提取>>)
[2.6.3 getline](#2.6.3 getline)
[2.7 字符串查找:find的实现(找字符/子串)](#2.7 字符串查找:find的实现(找字符/子串))
[2.7.1 查找单个字符:find(char)的实现](#2.7.1 查找单个字符:find(char)的实现)
[2.7.2 查找字符串:find(const char*)的实现](#2.7.2 查找字符串:find(const char*)的实现)
[2.8 字符串交换探秘:深入理解 swap 的底层机制](#2.8 字符串交换探秘:深入理解 swap 的底层机制)
一、 别再停留在"会用"!深挖string底层,真正理解字符串
1.1 只会调用string接口,够用吗?
在日常编码中,很多人对 string 的理解往往停留在"知道怎么用"的层面------调用几个接口,完成功能,便以为足够。然而,一旦面试中被要求"手动实现一个 string 类",不少人就陷入困境。更常见的是,代码在把 string 对象作为参数传递或返回值之后,程序莫名崩溃,其根源往往在于对"浅拷贝"所造成的内存问题缺乏认知。
1.2 理解string底层,究竟有什么价值?
深入理解 string 的底层机制,其意义远不止于应对面试。它直接关系到我们日常开发的效率与代码的健壮性。比如:
-
了解
reserve预分配容量的机制,能够有效减少字符串动态扩容带来的性能开销; -
理解深拷贝的实现逻辑,可以避免因传参、赋值所引发的内存错误;
-
明白为什么 string 可以使用多种
swap函数,有助于我们写出更高效、更安全的代码。
更重要的是,string 的底层设计是 C++ 容器实现思想的一个"缩影"------吃透 string,再学习 vector、list 等其他容器,将会事半功倍。
二. 0基础手撕:从0搭建string核心底层逻辑(附实现代码)
2.1 底层构造逻辑:string类的成员变量与构造逻辑
通过对string类中接口的学习,我们不难发现,string类的私有成员变量应该包括以下三个:
- 数组:用来存储字符;
- size:有效字符的个数;
- capacity:空间大小
既然知道了这些,我们就可以很快的写出相对应的代码:
string.h
cpp
namespace carrot
{
class string
{
private:
char* _str;//数组用来存储字符串
size_t _size;//有效字符个数
size_t _capacity;//空间大小
};
}也许这时候,会有小伙伴会感到疑惑,**为什么这里要加上命名空间?**其实这是为了和库中的string做区分。
2.1.1 构造与析构:对象的 "创建" 与 "销毁"
构造函数为string对象分配初始内存,初始化状态;析构函数则在对象生命周期结束时,回收动态分配的内存,避免内存泄露。
2.1.1.1 打印
在看相应的构造之前,我们先来看看如何进行打印操作。
通过上面的学习,我们知道string类的底层中有一个_str的数组,我们是将数据存储在这个数组中,既然是这样的话,那我们打印的操作就是对这个数组进行了,只要我们知道数组的地址,我们就可以很轻松的打印出相应的数据。
在string类的接口中,有一个成员函数------c_str,这个函数就是可以返回底层的字符串,所谓返回底层的字符串就是返回底层中指向数组的指针,ok,既然已经这么清晰了,直接上代码:
cpp
const char* c_str() const
{
return _str;
}2.1.1.2 构造:对象的"创建"
对于使用来说,频率较高的应该是无参构造和有参构造,我们一一来看:
1、无参构造

测试代码:
- string.h
cpp
#include<iostream>
using namespace std;
namespace carrot
{
class string
{
public:
//无参构造
string()
:_str(nullptr)
,_size(0)
,_capacity(0)
{}
const char* c_str() const
{
return _str;
}
private:
char* _str;//数组用来存储字符串
size_t _size;//有效字符个数
size_t _capacity;//空间大小
};
}- test.cpp
cpp
#include"string.h"
namespace carrot
{
void testString1()
{
string s1;
cout << s1.c_str() << endl;
}
}
int main()
{
carrot::testString1();
return 0;
}我们构造一个对象,使用上面的c_str,运行一下,会出现什么意想不到的事情发生:

嗯?这是为什么?为什么运行的结果不正确?
ok,其实这是因为cout进行输出的时候,输出的是const char* 类型的一个指针,const char*的指针,cout在自动识别类型的时候,const char* 不会按指针进行输出,而是按照字符串进行输出,会对指针指向的字符串进行解引用操作,只有遇到'\0'才结束。
简单来说,就是当cout遇到const char* 类型时,他会将其视为C风格的字符串,并输出该指针指向的字符串内容,若const char* 指向的是nullptr,则cout是未定义的行为,通常会导致程序崩溃。
所以,我们不能给_str初始化为nullptr,而是应该加上'\0'。
正确代码:
cpp
//无参构造
string()
:_str(new char[1]{'\0'})
, _size(0)
, _capacity(0)
{}我们再运行测试一下:

此时就没有什么问题了~
2、有参构造

这~代码有没有什么问题?
ok,我们知道strlen 是一个时间复杂度为O(n)的接口,如果按照上图中的写法,这里会算三遍,效率会有点子低。
那我们可以改成下面这种写法吗?

其实是不行的,这时候就有UU想问了,为什么不能这么写?
在前面的学习中,我们学到过这么一个知识------
初始化的顺序要跟声明的顺序是一致的,先初始化_str,再_size,最后_capacity,如果按照上面的写法在初始化_str时,_str中的_size是一个随机值,会有问题。
那我们该怎么写这个代码呢?
我们知道私有成员变量初始化时是最好走初始化列表的,但是这并没有说必须走初始化列表,在下面的括号中进行初始化也是可以的。
正确代码:
cpp
//有参构造
string(const char* str)
:_size(strlen(str))//可以走初始化的尽量走初始化
{
_str = new char[_size + 1];//多开的一个空间给\0
_capacity = _size;
//strcpy(_str, str);//再将str中的数据拷贝到_str中
memcpy(_str, str, _size + 1);//再将str中的数据拷贝到_str中
}通过前面的学习,我们知道,无参构造和有参构造可以合并成一个带有缺省值的构造函数
代码演示:
cpp
string(const char* str = "")
:_size(strlen(str))//可以走初始化的尽量走初始化
{
_str = new char[_size + 1];//多开的一个空间给\0
_capacity = _size;
//strcpy(_str, str);//再将str中的数据拷贝到_str中
memcpy(_str, str,_size+1);//再将str中的数据拷贝到_str中
}
str=""要比str="\0" 的要好,这是因为常量字符串中的末尾默认有\0
2.1.1.3 析构:对象的"销毁"
cpp
//析构
~string()
{
delete[] _str;//释放_str的空间
_str = nullptr;
_size = 0;
_capacity = 0;
}2.2 迭代器与下标:string遍历的"两大高效工具"
2.2.1 operator\[\] 的底层逻辑与实现
下标访问是string最常用的操作之一,通过重载operator ,可以像访问数组一样操作string中的字符,底层本质是对 _str 指针的索引访问,同时也需要确保访问不会越界(这个可以加断言)
1、普通对象(可以修改)
cpp
//普通对象
char& operator[](size_t pos)
{
assert(pos<=_size);
return _str[pos];
}2、const对象(不能被修改)
cpp
//const 对象
const char& operator[](size_t pos) const
{
assert(pos<=_size);
return _str[pos];
}2.2.2 迭代器的基本框架和实现
迭代器是遍历容器元素的抽象机制,对于string,可以通过封装指针来实现简单迭代器,结合下标访问可以覆盖不同遍历场景。
1、普通对象
cpp
//普通对象
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}2、const 对象
cpp
//const对象
typedef const char* const_iterator;
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}2.2.3 遍历+修改
1、下标+
通过上面的重载 运算符,我们就可以通过下标返回数组上对应数组元素的引用,从而修改相应的值(这里的修改是对于普通对象,const对象只能读,不能被修改)
在进行上面的操作前,我们先来看一个简单的算法:求数组的长度,也就是string 类中size
代码演示:
cpp
//size
size_t size() const
{
return _size;
}ok,我们接着来看如何使用下标+ 进行遍历+修改的操作
代码演示:
cpp
string s2("hello bit");
for (size_t i = 0; i < s2.size(); i++)
{
s2[i]++;
cout << s2[i] << " ";
}s2是一个普通对象,可以进行读和写的操作。
如果是一个const对象,那只能进行读的操作------
cpp
const string s3("hello world");
for (size_t i = 0; i < s3.size(); i++)
{
//s3[i]++;//const对象只能读,不能写
cout << s3[i] << " ";
}2、迭代器
cpp
void testString2()
{
//普通对象
string s1("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
(*it)++;
cout << *it << " ";
++it;
}
cout << endl;
//const 对象
const string s2("hello bit");
string::const_iterator it2 = s2.begin();
while (it2 != s2.end())
{
cout << *it2 << " ";
++it2;
}
}3、范围for
支持迭代器的都支持范围for!!!
通过前面的学习,我们知道范围for的底层其实就是迭代器!!!
cpp
void testString2()
{
//范围for
//普通对象(可以读,可以写)
string s3("hello world");
for (auto& ch : s3)
{
ch++;
cout << ch << " ";
}
cout << endl;
//const 对象(可以读,不可以修改)
const string s4("hello bit");
for (auto& ch : s4)
{
//ch++;
cout << ch << " ";
}
}2.3 字符串修改:push_back,append,insert与+=的实现
- 字符串的修改操作是string的核心功能,push_back用于尾插单个字符,append用于追加字符串,insert支持指定位置插入,但是三者的底层实现都需要处理内存扩容和数据迁移,+=运算符可以进行单个字符/字符串的追加。
在学习push_back,append,insert与+=之前,我们先来看看,我们该怎么对空间容量进行操作
2.3.0 容量管理:resize和reserve的协同使用
- reserve 用于提前预留内存空间,避免频繁扩容;resize 则用于调整字符串的有效长度,在需要时还会调用 resize 进行扩容,还可以指定填充字符。
2.3.0.1 reserve
- reserve是对capacity进行调整,当我们知道要插入数据的个数时,我们可以使用reserve进行提前开空间的操作,这样就可以减少扩容次数
ok,话不多说,直接上代码:
- string.h
cpp
public:
//扩容
void reserve(size_t n);- string.cpp
cpp
//扩容
void string::reserve(size_t n)
{
//一般情况下,reserve不缩容
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}2.3.0.2 resize
- string.h
cpp
public:
//resize
void resize(size_t n, char ch = '\0');- string.cpp
cpp
//resize
void string::resize(size_t n, char ch)
{
//n <= _size,删除数据,保留前n个
if (n <= _size)
{
_size = n;
_str[_size] = '\0';
}
else
{
reserve(n);
for (size_t i = _size; i < n; i++)
{
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}注意:resize用于删除数据的场景用的不多,用来一次性插入数据的场景较多!!!
2.3.1 尾插单个字符:push_back的实现
- push_back的作用是在字符串的末尾添加一个字符,核心逻辑是"先检查容量,不足就扩容",再插入字符并更新_size
cpp
void string::reserve(size_t n)
{
//一般情况下,reserve不缩容
if (n > _capacity)
{
char* tmp = new char[n+1];
//strcpy(tmp, _str);
memcpy(tmp,_str,_size+1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}ok,接下来我们来看一下push_back的代码:
string.h
cpp
public:
void push_back(char ch);string.cpp
cpp
void string::push_back(char ch)
{
//空间不够,需要扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
//空间足够,直接尾插
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}关键逻辑:
- 扩容策略采用 "2 倍增长"(空串特殊处理为 1),平衡内存利用率和扩容次数;
- 每次插入后强制补'\0',确保C_str()返回的字符串始终有效
2.3.2 追加字符串:append的实现
- append是实现在一个string对象的尾部在追加一个字符串。底层需要计算追加的字符串的长度,然后计算空间容量够不够,最后拷贝字符串
我们先来看看append的扩容机制,append在进行扩容时,就不能再延续push_back的2倍扩容的机制,可以进行下面操作中的一个:
- 需要多少空间,开多少空间
cpp
//需要多少空间,开多少空间
reserve(_size + len);- 比较_size + len和2 * _capacity的大小
cpp
reserve(max(_size + len, 2 * _capacity));这种扩容方式,可以防止空间开大了
扩容的大逻辑:开多了浪费。开少了不够用!!!
- string.h
cpp
public:
void append(const char* str);- string.cpp
cpp
//append
void string::append(const char* str)
{
//空间不够,需要扩容
size_t len = strlen(str);
if (_size + len > _capacity)
{
//需要多少空间,开多少空间
reserve(_size + len);
//reserve(max(_size + len, 2 * _capacity));
}
//空间足够,直接操作
//这里就不需要再手动添加\0了,strcpy会将str中的\0拷贝过去
//strcpy(_str + _size, str);
//字符串中间有\0,使用memcpy
memcpy(_str + _size, str, len + 1);
_size += len;
}2.3.3 运算符重载:+=实现字符 / 字符串追加
- +=是push_back和append的**"语法糖**",支持追加单个字符或者字符串,底层直接复用已有函数逻辑,简化代码的书写。
- string.h
cpp
public:
//+=
//单个字符
string& operator+=(char ch);
//字符串
string& operator+=(const char* str);- string.cpp
cpp
//+=
//单个字符
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
//字符串
string& string::operator+=(const char* str)
{
append(str);
return *this;
}优势:
- +=本质是对push_back和append的封装,避免重复编写扩容和字符拷贝逻辑;
- 返回*this(对象引用)是实现链式操作的核心,确保每次调用后仍能继续操作当前对象;
- 与append相比,+=更适合简单场景,代码可读性更高,两者底层效率一致。
2.3.4 任意位置插入:insert的实现(插入字符/字符串)
- insert支持在指定位置插入单个字符或者字符串,核心是"先挪到原有字符,再插入新内容",需要特别处理扩容和内存重叠问题。
1、插入字符
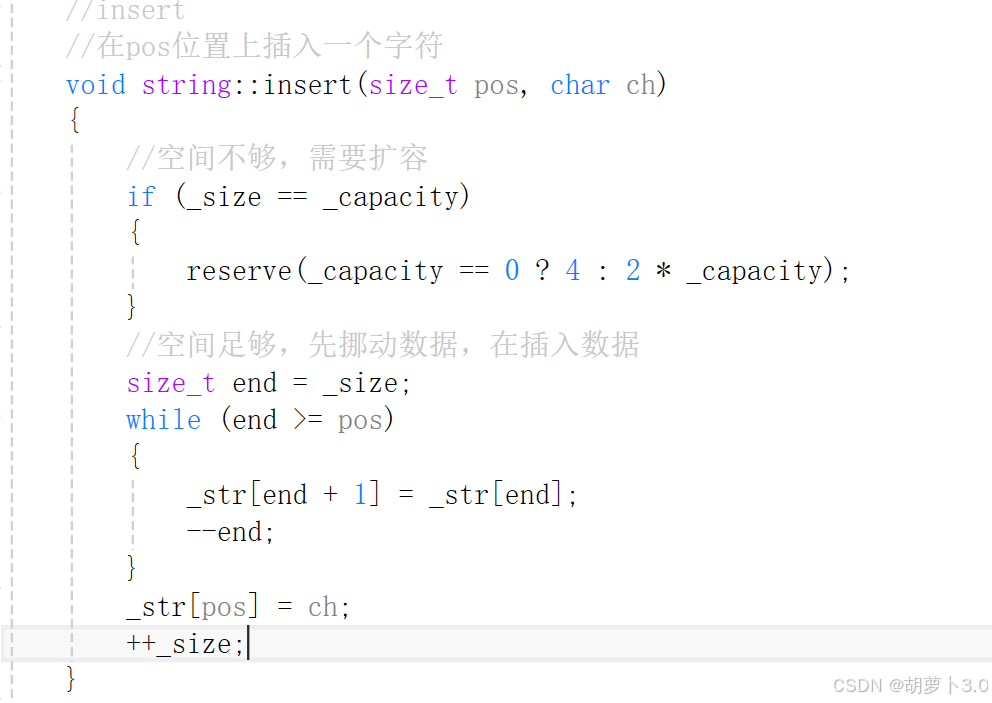
通过前面的学习,我们很快就可以写出相应的代码,但是,这个代码正确吗?
当我们执行头插时,会不会有啥问题呢?我们运行一下
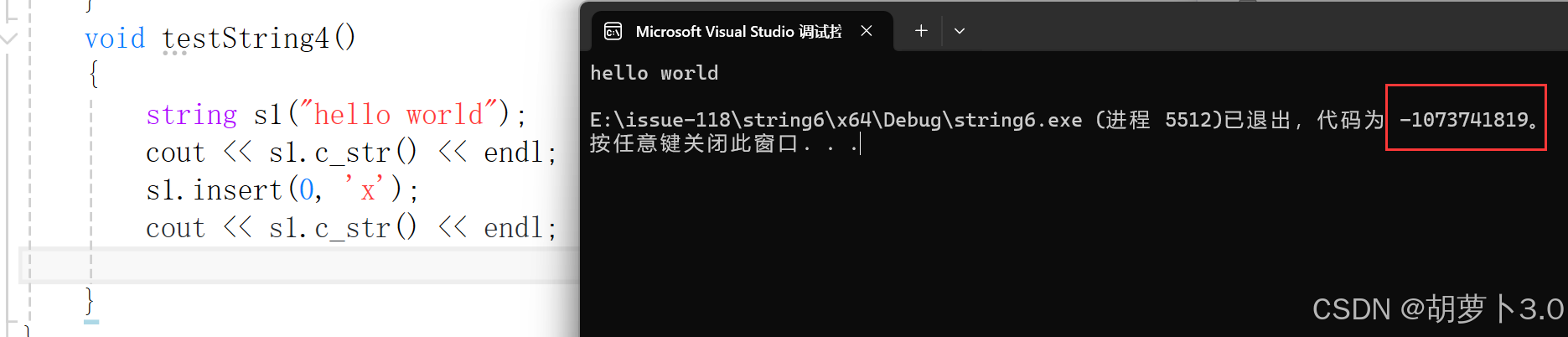
这是为什么?
这是因为end的类型是size_t,也就是无符号整型,永远不会小于0,这就导致end>pos恒成立。
那我们这样改?

这样还是不行,end是int ,pos是size_t ,在运算时,会进行算术转化,范围大的向范围小的转换,end>pos还是恒成立
我么应该这么改------

最终代码:
- string.h
cpp
public:
//在pos位置上插入一个字符
void insert(size_t pos, char ch);- string.cpp
cpp
//insert
//在pos位置上插入一个字符
void string::insert(size_t pos, char ch)
{
//代码改进
assert(pos < _size);
//空间不够,需要扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
//空间足够,先挪动数据,在插入数据
int end = _size;
while (end >= (int)pos)
{
_str[end + 1] = _str[end];
--end;
}
_str[pos] = ch;
++_size;
}移动示意图:
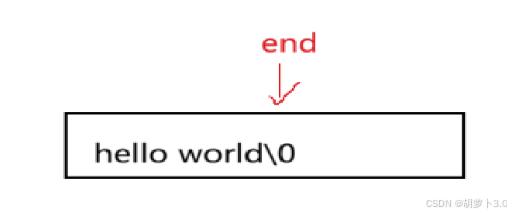
这时候就有UU想说了,上面的操作感觉有点麻烦,有没有比较简洁的方法?当然有
我们可以按照下图的方式进行移动:
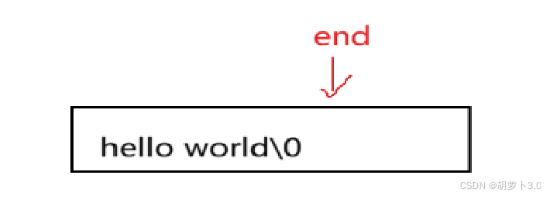
end为\0的下一个位置,然后我们将end-1位置上的数据移动到end位置上,这样就可以避免end==pos的情况的发生。
- string.cpp
cpp
void string::insert(size_t pos, char ch)
{
//代码改进
assert(pos < _size);
//空间不够,需要扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
//空间足够,先挪动数据,在插入数据
int end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
}2、插入字符串
数据移动方式一:
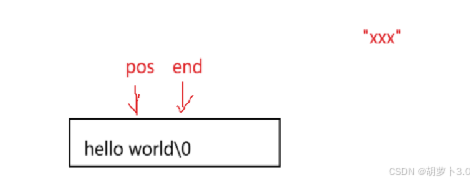
把end位置的数据挪动到end+len的位置上,直到end<pos,终止挪动
- string.h
cpp
public:
//在pos位置上插入一个字符串
void insert(size_t pos, const char* str);- string.cpp
cpp
//在pos位置上插入一个字符串
void string::insert(size_t pos, const char* str)
{
//代码改进
assert(pos < _size);
// 空间不够,需要扩容
size_t len = strlen(str);
if (_size + len > _capacity)
{
//需要多少空间,开多少空间
reserve(_size + len);
//reserve(max(_size + len, 2 * _capacity));
}
//空间足够,先挪动数据,在插入数据
int end = _size;
while (end >= (int)pos)
{
_str[end + len] = _str[end];
--end;
}
//strncpy(_str + pos, str, len);
//字符串中间有\0,用memcpy
memcpy(_str + pos, str, len);
_size += len;
}数据移动方式二:
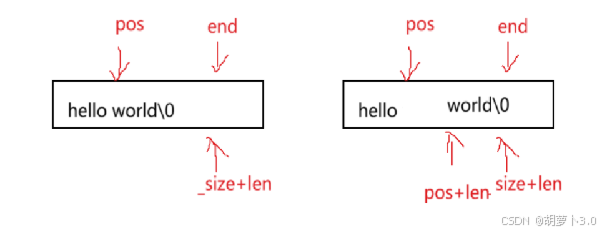
- string.cpp
cpp
//在pos位置上插入一个字符串
void string::insert(size_t pos, const char* str)
{
// 空间不够,需要扩容
size_t len = strlen(str);
if (_size + len > _capacity)
{
//需要多少空间,开多少空间
reserve(_size + len);
//reserve(max(_size + len, 2 * _capacity));
}
//空间足够,先挪动数据,在插入数据
int end = _size+len;
while (end >pos+len-1)
{
_str[end] = _str[end-len];
--end;
}
//strncpy(_str + pos, str, len);
memcpy(_str + pos, str, len);
_size += len;
}2.4 字符串删减与截取:erase,clear与substr的实现
2.4.1 任意位置删除:erase的实现(删字符/删区间)
erase是从pos位置开始,删除len个字符
- string.h
cpp
public:
//erase
void erase(size_t pos = 0, size_t len = npos);
const static size_t npos = -1;- string.cpp
cpp
//erase
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
if (len == npos || len >= _size - pos)
{
_size = pos;
_str[_size] = '\0';
}
else
{
//strcpy(_str + pos, _str + pos + len);
memcpy(_str + pos, _str + pos + len, _size - (pos + len) + 1);
_size -= len;
}
}2.4.2 清空字符串:clear的实现
clear是用来快速清空数据,但是不销毁空间,仅需重置_size和结束符
cpp
public:
//clear
void clear()
{
_str[0] = '\0';
_size = 0;
}2.4.3 截取子串:substr的实现
substr是拷贝从pos位置开始的len个字符,然后构造一个string对象返回
- string.h
cpp
public:
//substr
string substr(size_t pos = 0, size_t len = npos);
const static size_t npos = -1;- string.cpp
cpp
//substr
string string::substr(size_t pos, size_t len)
{
assert(pos <= _size);
if (len == npos || len > _size - pos)
{
len = _size - pos;
}
string tmp;
for (size_t i = 0; i < len; i++)
{
tmp += _str[pos + i];//从pos位置开始的len个字符
}
return tmp;
}2.5 拷贝构造和赋值重载
2.5.1 拷贝构造
通过前面的学习,我们知道,对于自定义类型中有资源的,编译器自动生成的默认拷贝构造是行不通的,这是因为自动生成的构造为浅拷贝,析构时会析构两次
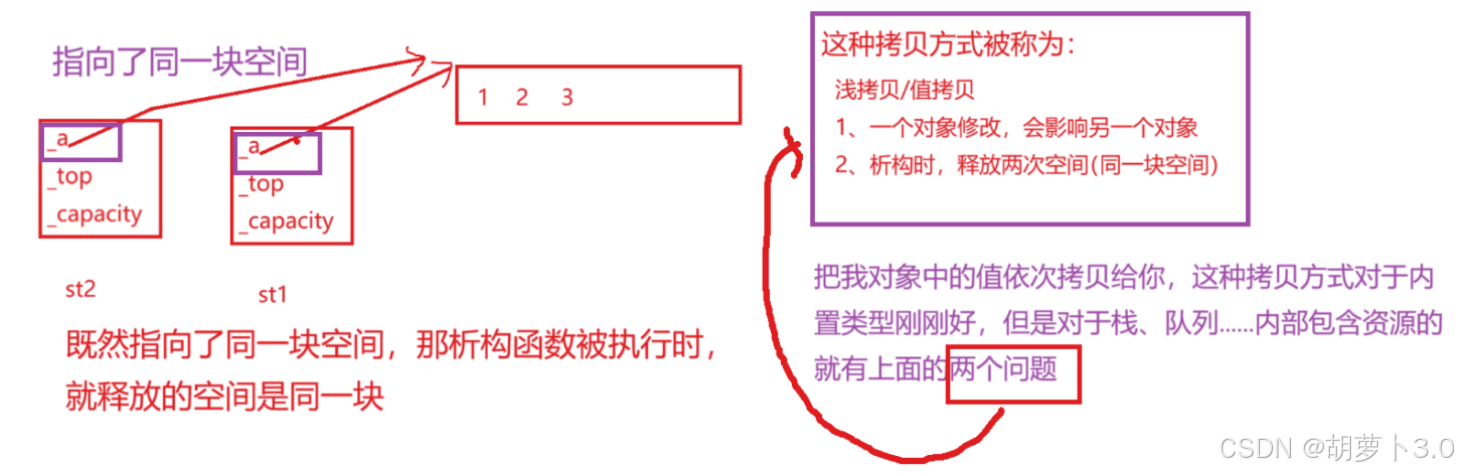
具体见:C++拷贝构造与运算符重载实战
所以我们需要自已写拷贝构造完成深拷贝,也就是新开一块空间将拷贝后的数据放入新开的空间中
- string.h
cpp
public:
//拷贝构造
string(string& str);- string.cpp
cpp
//拷贝构造
string::string(string& str)
{
_str = new char[str._capacity+1];
//多开的一个空间给\0,capacity中不包含\0
//strcpy(_str, str._str);//完成的是深拷贝
memcpy(_str,str._str,str._size+1);
_size = str._size;
_capacity = str._capacity;
}2.5.2 赋值重载
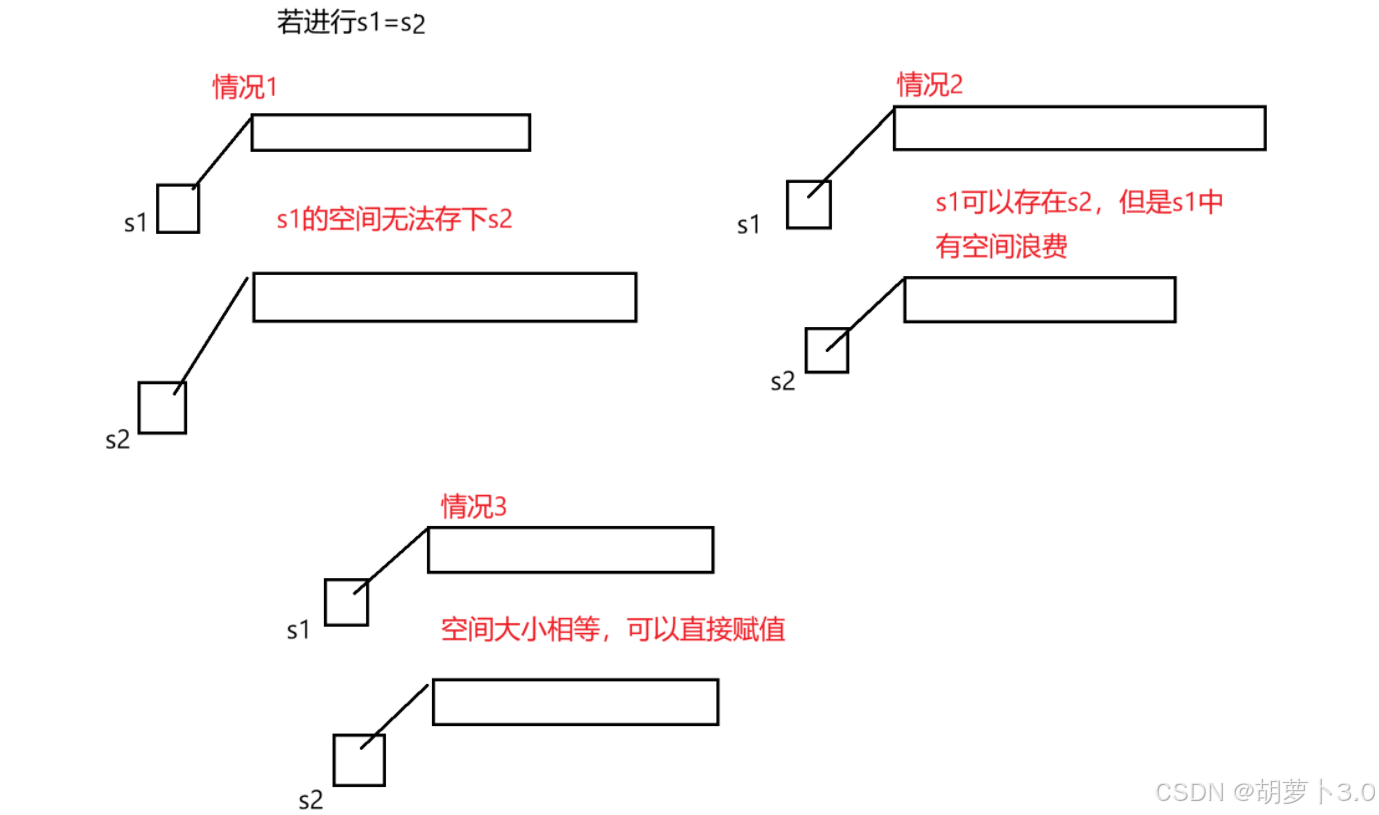
在进行赋值操作前,我们总结出有三种情况,如果我直接进行赋值操作,会有些问题,那我们该如何做呢?
执行步骤
- 内存准备阶段
cpp
char* tmp = new char[str._size + 1];-
首先为新的字符串数据分配内存空间
-
分配的大小根据源字符串的长度
_size确定,额外+1用于存放字符串结束符\0 -
创建临时指针
tmp来管理这块新内存
- 数据拷贝阶段
cpp
//strcpy(tmp, str._str);
memcpy(tmp, s._str, s._size + 1);-
将源字符串
str中的实际字符数据(包括结束符)完整复制到新分配的内存中 -
此时系统中存在两份相同字符串数据的副本
- 资源清理与更新阶段
cpp
delete[] _str;
_str = tmp;-
释放当前对象原来持有的字符串内存,避免内存泄漏
-
将新分配的内存地址赋给当前对象的
_str指针,完成所有权的转移
- 元数据同步阶段
cpp
_size = str._size;
_capacity = str._capacity;-
更新当前对象的长度信息
_size,使其与源字符串保持一致 -
更新当前对象的容量信息
_capacity,反映新的内存分配情况 -
string.h
cpp
public:
//赋值重载
string& operator=(string& str);- string.cpp
cpp
//赋值重载
string& string::operator=(string& str)
{
if (this != &str)
{
char* tmp = new char[str._size + 1];//和str中的数组开一样的大小
delete[] _str;
//strcpy(tmp, str._str);
memcpy(tmp, s._str, s._size + 1);
_str = tmp;
_size = str._size;
_capacity = str._capacity;
}
return *this;
}写到这里,我们稍微暂停一下~~~
我们来想一个问题,通过对上面代码的学习,发现了一个问题:上面的代码中的字符串好像没有中间有\0的情况,那如果我们在中间插入一个\0,并打印这个字符串,还会是正确的吗?
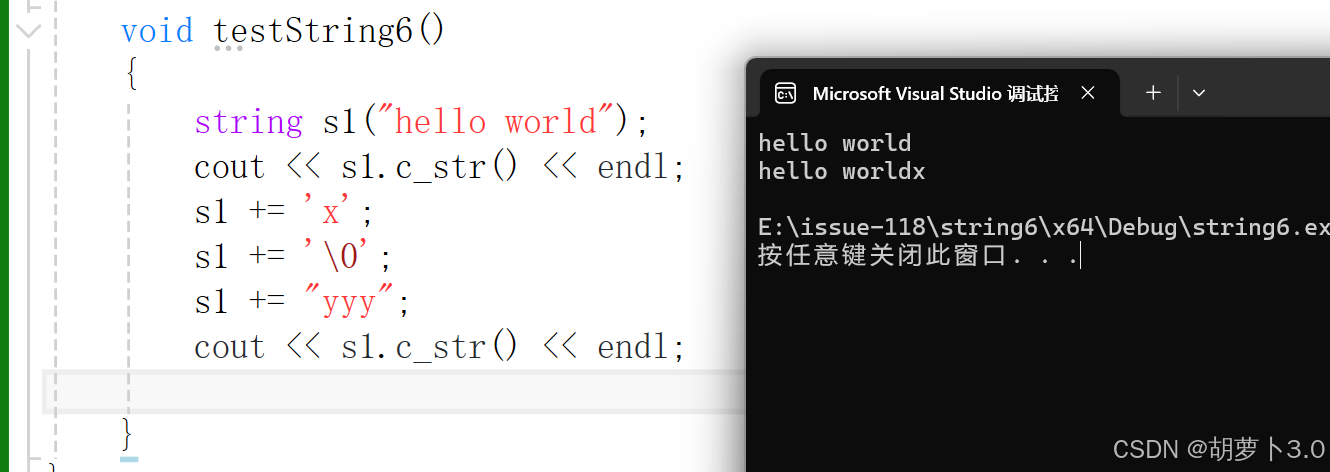
嗯?为什么会是上面的结果?打印的结果不应该是hello worldxyyy吗?为什么是hello worldx?
很奇怪,其实这是因为c_str,c_str在打印的过程中遇到\0就终止了,如果中间有\0,并且还是用c_str打印,\0后面的数据就无法打印。
这就要求我们不得不自己实现流插入以及顺便实现一下流提取、getline
2.6 流插入<<、流提取>>和getline
流插入<<、流提取>>和getline 这三个都是非成员函数
2.6.1 流插入<<
- string.h
位于string类的外面
cpp
std::ostream& operator<<(std::ostream& out, const string& str);- string.cpp
cpp
std::ostream& operator<<(std::ostream& out, const string& str)
{
for (auto ch : str)
{
out << ch;
}
return out;
}2.6.2 流提取>>
- string.h
位于string类的外面
cpp
std::istream& operator>>(std::istream& in, string& str);- string.cpp
cpp
std::istream& operator>>(std::istream& in, string& str)
{
str.clear();
char ch;
ch = in.get();
while (ch != ' ' && ch != '\n')
{
str += ch;
ch = in.get();
}
return in;
}也许会有uu看见上面的代码,会想问:为什么不使用>>,而是使用get呢?
这是因为"operator>>"会跳过空白字符(空格和换行),如果使用它,就永远无法检测到空格和换行,而get函数是一个字符一个字符的获取,这样就可以检测到空格和换行
为什么会有str.clear();的操作呢?
当我们不加str.clear();会出现下面的情况:

ok,我么原本是想给s2初始化为"hello",s3为"bit",结果成了上面的样子,这是因为s3中原本就有数据,">>"会在原有的数据后面继续追加,导致结果的错误,所以我们一不做二不休直接将数据清空(并没有销毁空间)
这里面还有一个问题:若有一个很长的字符串,会进行多次扩容,会很麻烦,此时我们该怎么做?
我们可以这样做:
cpp
std::istream& operator>>(std::istream& in, string& str)
{
str.clear();
char ch;
ch = in.get();
char buff[256];
int index = 0;
while (ch != ' ' && ch != '\n')
{
buff[index++] = ch;
if (index == 255)
{
buff[index] = '\0';
str += buff;
index = 0;
}
ch = in.get();
}
if (index > 0)
{
buff[index] = '\0';
str += buff;
}
return in;
}创建一个buff数组,大小为256(任何大小都可以),数据一开始先放到buff数组中,若数组满了,再拼接到str中,index置为0,重新往数组中插入数据。这样就可以减少扩容的次数,提高效率
2.6.3 getline
- string.h
位于string类的外面
cpp
std::istream& getline(std::istream& in, string& str,char delim='\n');- string.cpp
cpp
std::istream& getline(std::istream& in, string& str, char delim)
{
str.clear();
char ch;
ch = in.get();
while (ch !=delim)
{
str += ch;
ch = in.get();
}
return in;
}注意:getline默认是以\n为间隔,也可以指定其他间隔符!!!
改进代码:
cpp
std::istream& getling(std::istream& in, string& s, char delim)
{
s.clear();
char ch;
ch = in.get();
char buff[256];
int index = 0;
while (ch !=delim)
{
buff[index++] = ch;
if (index == 255)
{
buff[index] = '\0';
s += buff;
index = 0;
}
ch = in.get();
}
if (index != 0)
{
buff[index] = '\0';
s += buff;
}
return in;
}ok,实现完流插入、流提取以及getline,我们继续来看中间有\0的情况:
如果字符串中间有\0,那就不能再继续使用strcpy,strcpy遇到\0就停止拷贝,也会出现和c_str一样的问题,那我们可以将strcpy换成memcpy,这样就可以解决问题~~~
2.7 字符串查找:find的实现(找字符/子串)
- find是字符串查找的核心接口,支持从指定位置开始查找单个字符或子串,返回首次出现的位置(未找到就返回npos),底层通过遍历比对实现,逻辑清晰使用场景广。
2.7.1 查找单个字符:find(char)的实现
查找单个字符时,是从指定pos位置开始通过遍历字符串,逐个比较字符,若匹配成功,则返回该下标;若没有,则返回npos
- string.h
cpp
public:
//查找单个字符
size_t find(char ch, size_t pos = 0);默认是从头开始查找,也可以指定位置开始查找
- string.cpp
cpp
//查找单个字符
//从pos位置开始查找
size_t string::find(char ch, size_t pos)
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch) {
return i;
}
}
return npos;
}关键逻辑:
- 起始位置pos默认从0开始(整个字符串查找),也可以指定位置开始。
- 遍历范围限制在[pos,_size),避免越界。
2.7.2 查找字符串:find(const char*)的实现
- string.h
cpp
public:
//查找子字符串
size_t find(const char* str, size_t pos = 0);- string.cpp
cpp
//从pos位置开始查找
size_t string::find(const char* str, size_t pos)
{
const char* ptr = strstr(_str+pos, str);
if (ptr)
{
return ptr - _str;
}
else
{
return npos;
}
}2.8 字符串交换探秘:深入理解 swap 的底层机制
ok,我们先来看一下下面的这张图:
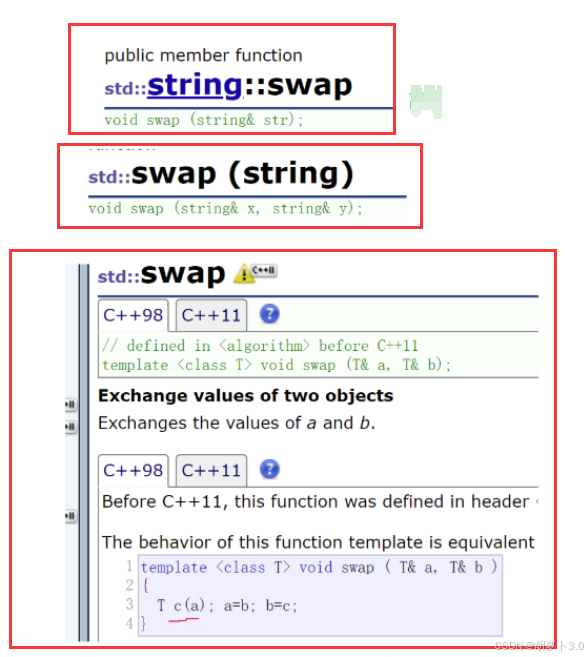
嗯?为什么这里会有三个交换算法?一个是算法库中的swap,另外两个是string 类中的swap。
在前面的学习中,我们会经常使用算法库中的swap,感觉它比较好用。那这里就有个问题:既然算法库中的swap已经很好用了,string 类中为什么还要自己搞个swap呢?
其实这是因为算法库中的swap有巨大问题:算法库中的swap对于内置类型的交换肯定是可以的,但是对于string类这种,并且内部有资源的自定义类型,算法库中的swap会进行3次拷贝,代价很大,所以string类就自己搞了swap
对于string类型没有必要这么做,对于两个string类的交换,仅仅只需要交换内部资源,_size和_capacity即可~
- string.h
cpp
public:
void swap(string& s);- string.cpp
cpp
//交换
void string::swap(string& s)
{
std::swap(_str, s._str);//直接调用算法库中的swap,直接调换其中资源地址
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}内部有资源,浅拷贝有问题,只能进行深拷贝,对于深拷贝的类型,内部都会实现一个自己的swap函数,仅仅交换内部资源即可
那如果我们想调用像算法库中的swap,这该怎么实现呢?
这时候我们就可以直接复用上面的代码,并搞成inline就可以了
- string.h
cpp
inline void swap(string& s1, string& s2)
{
s1.swap(s2);
}这样的话,以后要交换string就都可以用了~
完整模拟代码+测试代码:
- string类的实现代码Gitee仓库: string类的实现代码
结尾
各位UU们,你们感觉string类模拟实现这块哪里比较难呢?评论区可以聊聊哦~~~