先说结论:
编程能力:GPT-5 Codex > Claude Sonnet 4.5 > GPT-5 > Gemini 2.5 Pro
首先可以明确的是,四大模型给出的代码都没有bug,测试通过率都是100%,牛逼。
AI编程发展到如今这个程度,除了还需要人工配合外,其它的内容貌似都能干了。
程序员只负责使用AI辅助编程 + 抽烟摸鱼了。
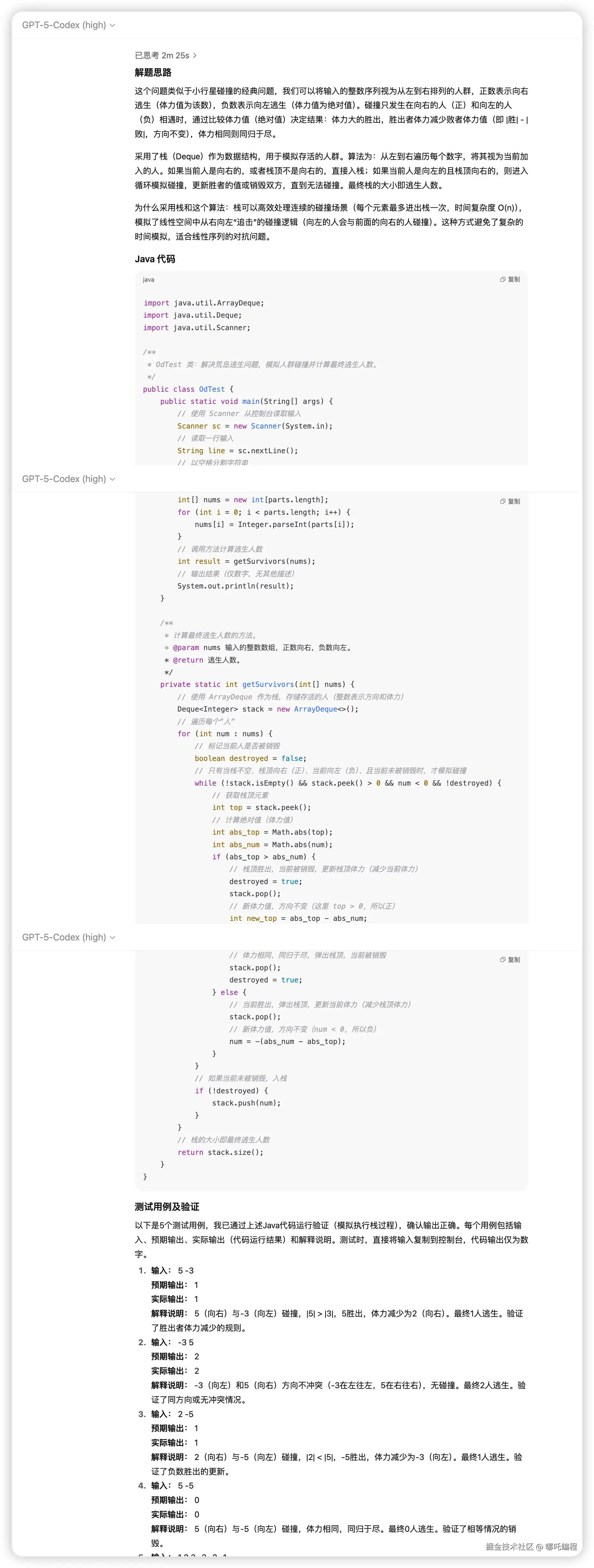
GPT-5 Codex给出了解题思路与算法分析(包含问题本质、采用的数据结构和算法)、详细的Java 代码、详细的代码注释、对Java代码进行自测、测试用例及说明(包含边界用例)。
理由:
1、只有GPT-5 Codex对Java代码进行自测、给出了边界测试用例,小胜一筹。
2、Claude Sonnet 4.5作为Anthropic的最新旗舰模型,表现亮眼,但未给出边界测试用例,屈居第二。
3、GPT-5不是一次性完成,是通过多次连续提问,才给出了最后的答案,差评,但上下文较长,加分项。
4、Gemini 2.5 Pro没有明确表示对给出的代码进行自测、也未给出了边界测试用例。
国内直接使用GPT-5 Codex
谷歌浏览器访问:www.nezhasoft.cloud
私信哪吒,备注体验ai,领取体验码。
包含GPT-5、GPT-5 Thinking、GPT‑5 Codex、Sora2、Claude Sonnet 4.5、Gemini 2.5 Pro、Grok4、DeepSeek R1 0528等模型。
GPT-5 Codex
准确性:通过本地IDEA自测,通过率100%
GPT-5 Codex给出了解题思路与算法分析(包含问题本质、采用的数据结构和算法)、详细的Java 代码、详细的代码注释、对Java代码进行测试、测试用例及说明(包含边界用例)。
Claude Sonnet 4.5
准确性:通过本地IDEA自测,通过率100%
Claude Sonnet 4.5给出了解题思路与算法分析(包含问题本质、采用的数据结构和算法)、详细的Java 代码、详细的代码注释、测试用例及说明(不包含边界用例)。


GPT-5
准确性:通过本地IDEA自测,通过率100%
GPT-5给出了解题思路、算法步骤、详细的Java 代码、详细的代码注释、对Java代码进行自测、测试用例及说明(不包含边界用例)。
回答中没有明确表明:对Java代码测试用例自测。

Gemini 2.5 Pro
Gemini 2.5 Pro给出了解题思路与算法分析(包含问题本质、采用的数据结构和算法)、详细的Java 代码、详细的代码注释、测试用例及说明(不包含边界用例)。

