文件操作
- 打开文件
-
- read()函数
- readlines()函数
- readline()函数
- for循环读取文件
- [with open读取文件](#with open读取文件)
- write()写入文件
- 实践操作
打开文件
在python中,可以用open()打开或者新建一个文件,用法如下:
python
open('文件名',打开文件模式,编码格式(一般使用"UTF-8"))read()函数
现在我在桌面新建了一个文本,用文件操作打开并读取,代码如下:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
print(f.read())运行结果如下:

这段代码中,"D:/桌面/test.txt"为文本的路径和名称,open函数按照这个路径找到文本打开,"r"是表示只读模式,只读取文本内容,最后是编码,读取完成后返回一个文件,定义f来接受
在输出过程当中,可以用f.read()来读取文件当中的所有内容,当然f.read()括号中也可以传入参数,如下:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
print(f.read(5))这里传入参数为5,表示只读取文件当中的前五个字节,所以输出如下:

readlines()函数
readlines()函数是读取文件的所有行,代码运行如下:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
print(f.readlines())
由运行结果可以看出,输出的是一个列表,是因为readlines()函数将文本内容读取为列表,每一行变成列表的一个元素
readline()函数
readline()表示读取该文件中的一行,运行如下:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
print(f.readline())
如图所示,文件只读取了一行
for循环读取文件
除上面的函数外,可以直接用for循环来读取文件。代码如下:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
for line in f:
print(line)输出如下:
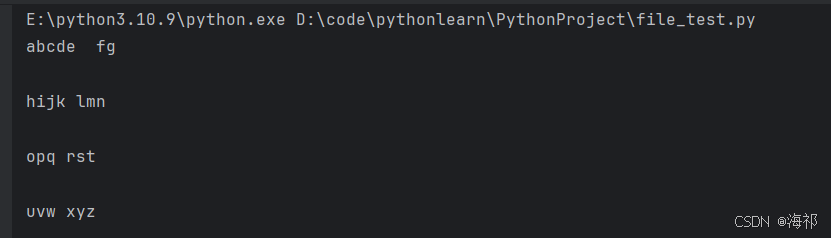
刚开始我还不太理解为什么for line in f,这样怎么读取,但是换一种形式,就好理解得多:
python
for line in open("D:/桌面/test.txt","r",encoding="UTF-8"):
print(line)这样就很容易理解这个逻辑了,就是在读取这个该文件,line表示读取的每一行
with open读取文件
一般情况下,打开文件读取完成后需要关闭文件流,否则文件会一直被python程序占用,即采用f.close()方式
为避免遗漏关闭文件流,可以采用with open的方式:
python
with open("D:/桌面/test.txt","r",encoding="UTF-8") as f:
print(f.readlines())这样在读取完成后,会自动关闭文件流,避免遗忘
write()写入文件
类比读取文件,就可得出,写入文件的代码:
python
f=open("D:/桌面/test.txt","w",encoding="UTF-8")
f.write('hello world')
f.flush()在这里"w"表示写入模式,调取write()函数来进行写入'hello world',查看现在文档内容:
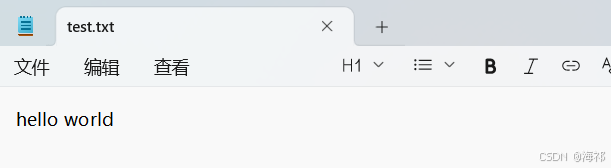
write写入时,会将文件内的内容清空,再将传入的字符串写入
直接调用write时,内容并未真正写入,而是存入缓冲区
调取flush,内容才算真正写入
如果打开文件的路径中不存在这个文件,将新建文件进行写入
在写入模式中,每次写入都会把文件清空,如果想直接在文件后加入内容,则需要采用添加模式,代码如下:
python
f=open("D:/桌面/test.txt","a",encoding="UTF-8")
f.write('hello world')
f.flush()运行结果如图:
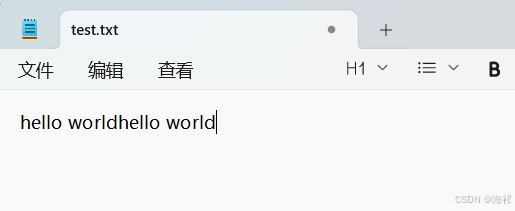
这次写入不把文件清空,而是直接在原文件后加入要写入的内容
添加模式中,如果不存在该文件,也会新建文件
实践操作
【实践一】读取test,txt文件,统计当中itheima出现的次数
方法一:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
print(f.read().count('itheima'))
f.close()这里读取文件,读取出来是一个字符串,就相当于f.read()是一个字符串,这是最简单的一种方法,直接使用"字符串.count('统计内容')"来统计这个字符串在文本当中出现的次数
方法二:
python
f=open("D:/桌面/test.txt","r",encoding="UTF-8")
count=0
for line in f:
line=line.strip()
words=line.split(" ")
for str in words:
if str=="itheima":
count+=1
print(count)
f.close()在这里,对因为不同字符串之间都是空格范围内开的,所以想着把每一行以空格为间隔分割成一个列表,每个字符串为一个元素
这里 line=line.strip()是将每行最后的换行符去掉
words=line.split(" ")是将每行分割成列表
再循环列表,如果有目标字符串,数量就加一