1.项目作用
tcmalloc,Thread Caching Malloc,线程缓存malloc,主要使用场景:多线程

2.内存池主要解决问题
主要解决问题:1)效率问题,池化技术解决 2)解决内存碎片问题
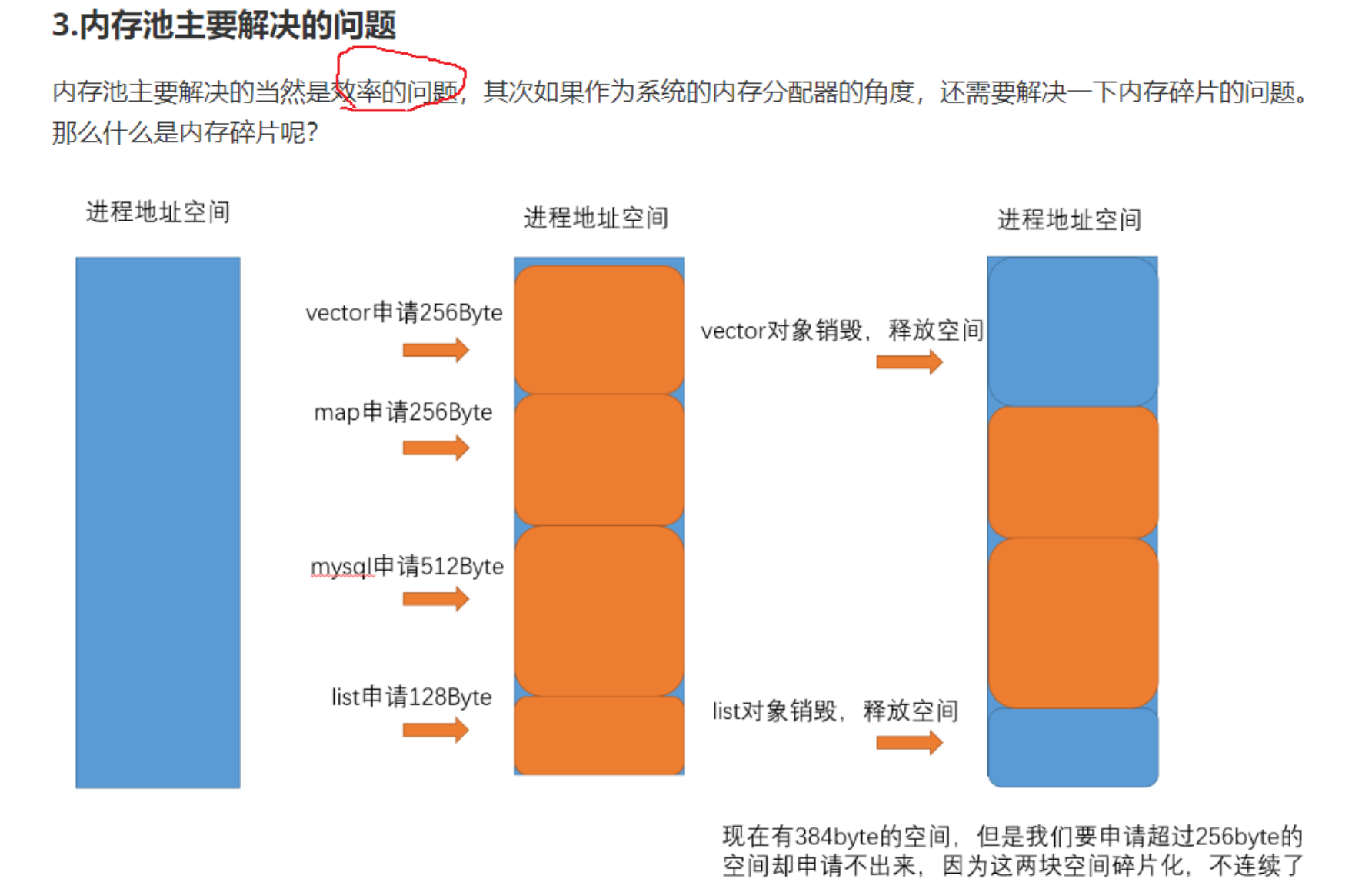
内存碎片问题:
1)外碎片:剩余空间足够,但由于碎片化问题,申请大块连续内存块申请不出来。
2)内碎片:由于对齐和方便管理等原因,业务调用内存池接口申请内存,实际给的内存比业务要的多,造成了浪费问题
3.malloc工作原理理解
流程:malloc调用,转而执行glibc封装的系统调用brk/mmap,向OS申请内存。返回带回结果,malloc维护大块内存块(malloc实际就是一个内存池)

4.定长内存池实现(申请的内存定长)
特别注意:.h头文件不要放全局函数定义,除非用static修饰,不然会有链接错误。
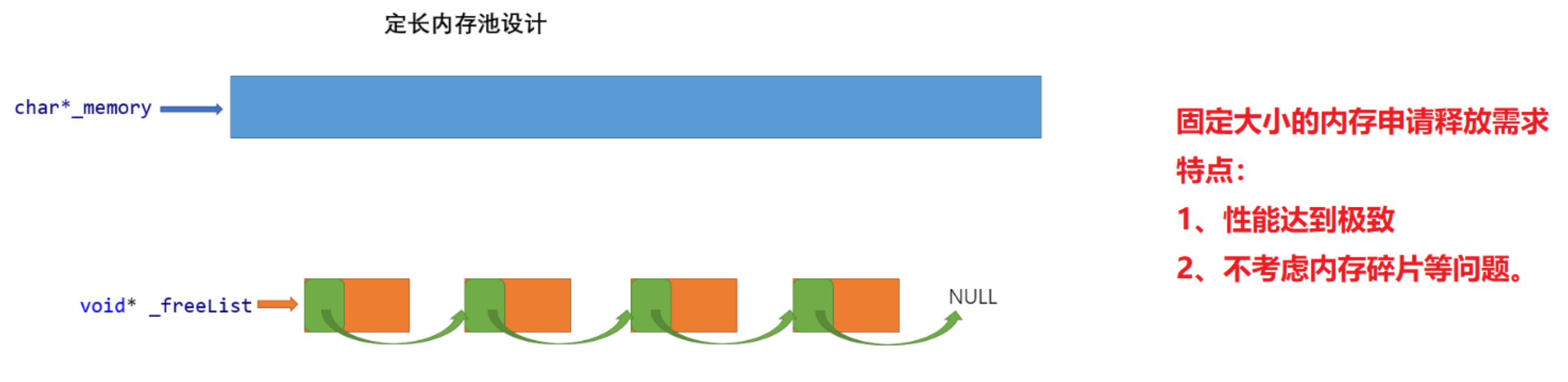
_memory:大块内存当前起始地址
_freeList:自由链表,存放delete归还的内存块,内存块前指针大小个字节存放下一个内存块起始地址。
New:优先从自由链表中拿,自由链表没有,从大块内存中切,大块内存空间不足去申请。
Delete:将要释放的内存块头插到自由链表
细节1:由于32位和64位下指针大小不同,不能指定用 int* 或 long long* 这种只能拿到固定长度的指针来拿到 前指针大小的内存(用来存放下一个内存块地址)
细节2:如何取一个指针大小的空间来存放下一块内存起始地址?
采用二级指针强转的方式,拿到指针大小内存,将其赋值为下一个内存块地址。
细节3:获取下一个内存地址函数返回值要写成void*&,因为在Delete头插_freeList时,要修改这个指针的值(这个指针的值代表就是前指针大小的内容)
细节4:
- 大内存块开辟的空间不一定是对象T的倍数,需要记录_left剩余字节数来判断,如果不够就继续扩容;
- 不够一个指针大小,就给一个指针大小,即使浪费,为了存下_freelist链表的next指针;
- 仿照new 和 delete,定位new和显示调用析构;
- 不管释放,进程结束自己回收
代码:
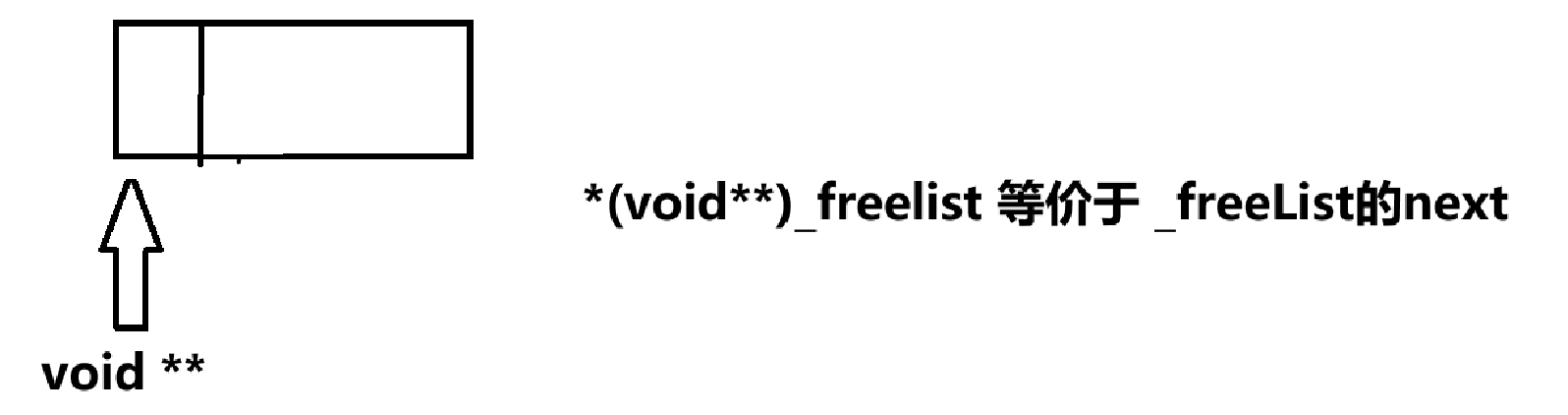

5.高并发内存池整体框架设计
考虑的几个问题:
1)性能问题
2)多线程环境下,锁竞争问题
3)内存碎片问题
concurrent memory pool三层:
1)thread cache:每个线程独享一个thread cache,申请内存优先在thread cache中申请,并发效率高。如果内存块不足了,就向central cache要;如果内存块有很多用不完,就反给central cache
2)central cache:thread cache中内存块是从central cache来的。central cache也会做类似负载均衡地给各个thread cache合理分配内存块。特别地,用的是桶锁,相比锁表,多线程访问临界资源的竞争小。
3)page cache:页缓存,存储的内存是以页为单位存储和分配的。当一个span的几个跨度也的对象都被回收后,page cache会回收central cache符合条件的内存块,用来合并相邻页,组成更大的页,减少内存碎片问题。

6.thread cache模块
6.1 thread cache结构分析
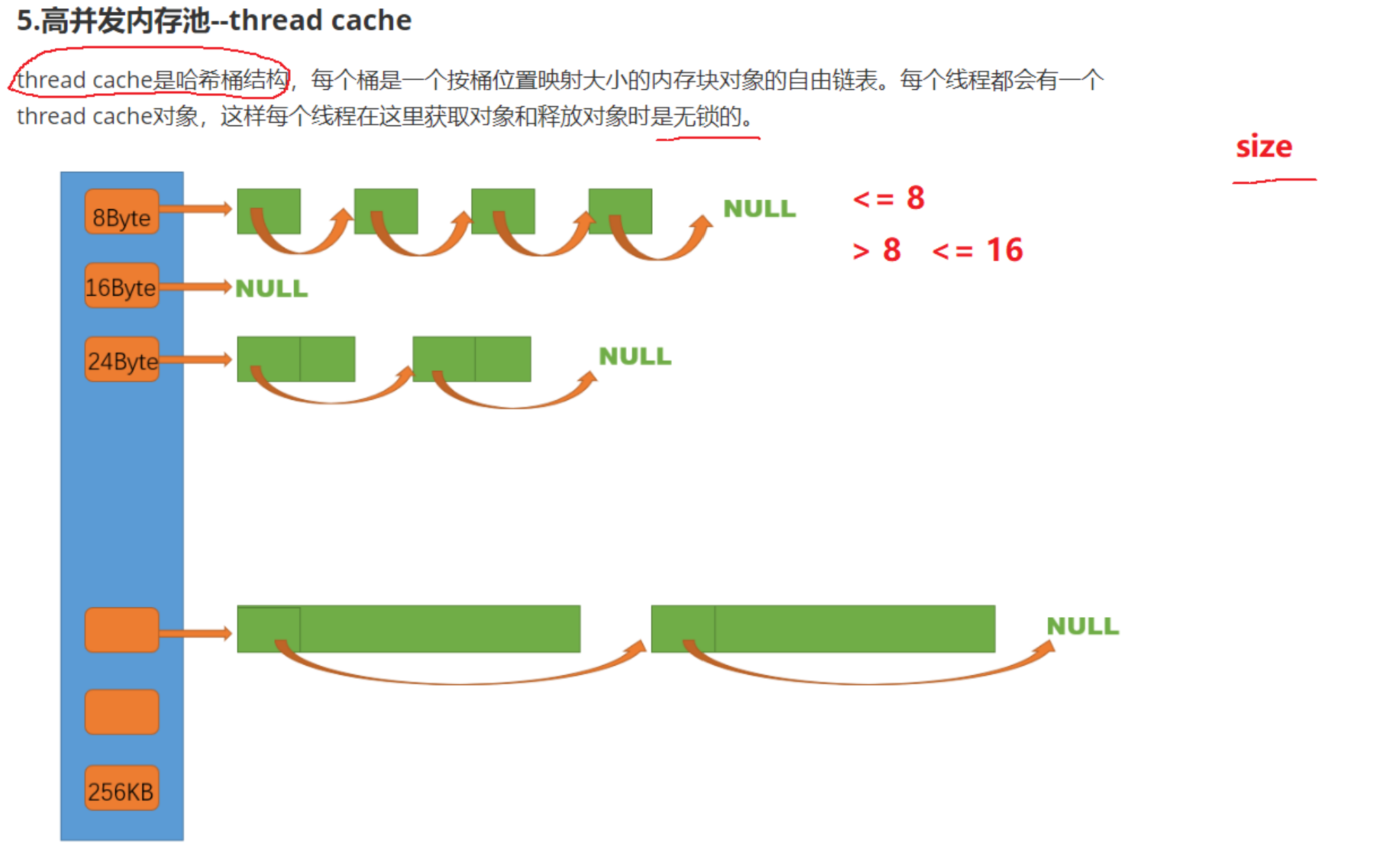
分析:thread cache是哈希桶结构,实现时用数组来记录每个桶的起始指针。其中每个桶是定长字节数的自由链表。每个线程都会有一个thread cache对象。
为了保证每个线程都有一个独立的thread cache对象,ThreadCache.h中全局定义:
static __declspec(thread) ThreadCache* pTLSThreadCache=nullptr;线程局部存储,存储ThreadCache指针(静态线程局部存储只能定义内置类型,指针是内置类型),保证每个线程都有独立的一份。
每个自由链表中内存块长度是固定的,如何进行划分?

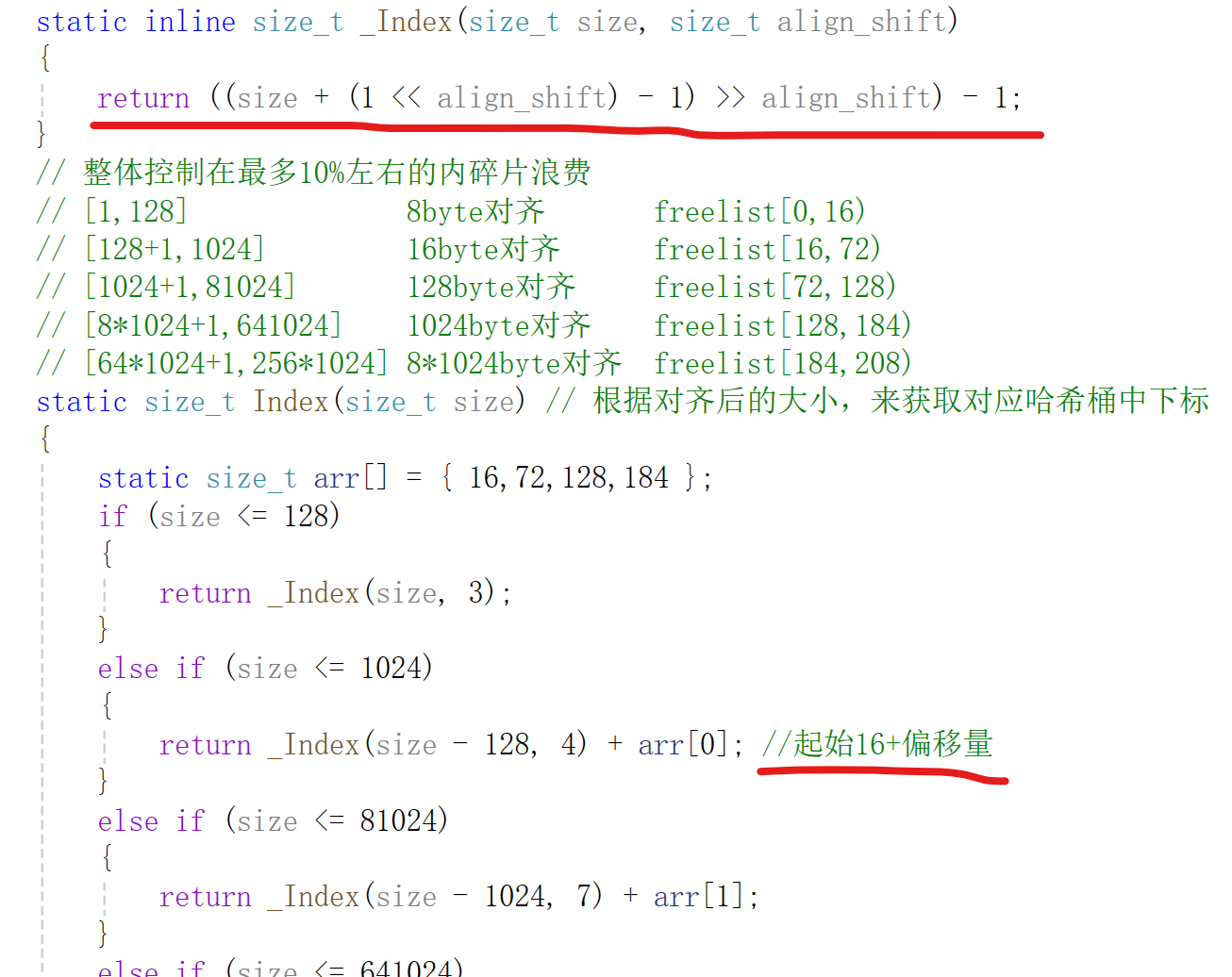
6.2 Allocate逻辑
1)计算对齐大小思路:判断size落到哪个区间,在用该区间对齐数进行对齐
2)计算对应FreeList下标思路:起始桶位置+区间内桶偏移量,每个区间桶起始位置不一样,对齐数也不一样。
3)Allocate逻辑:



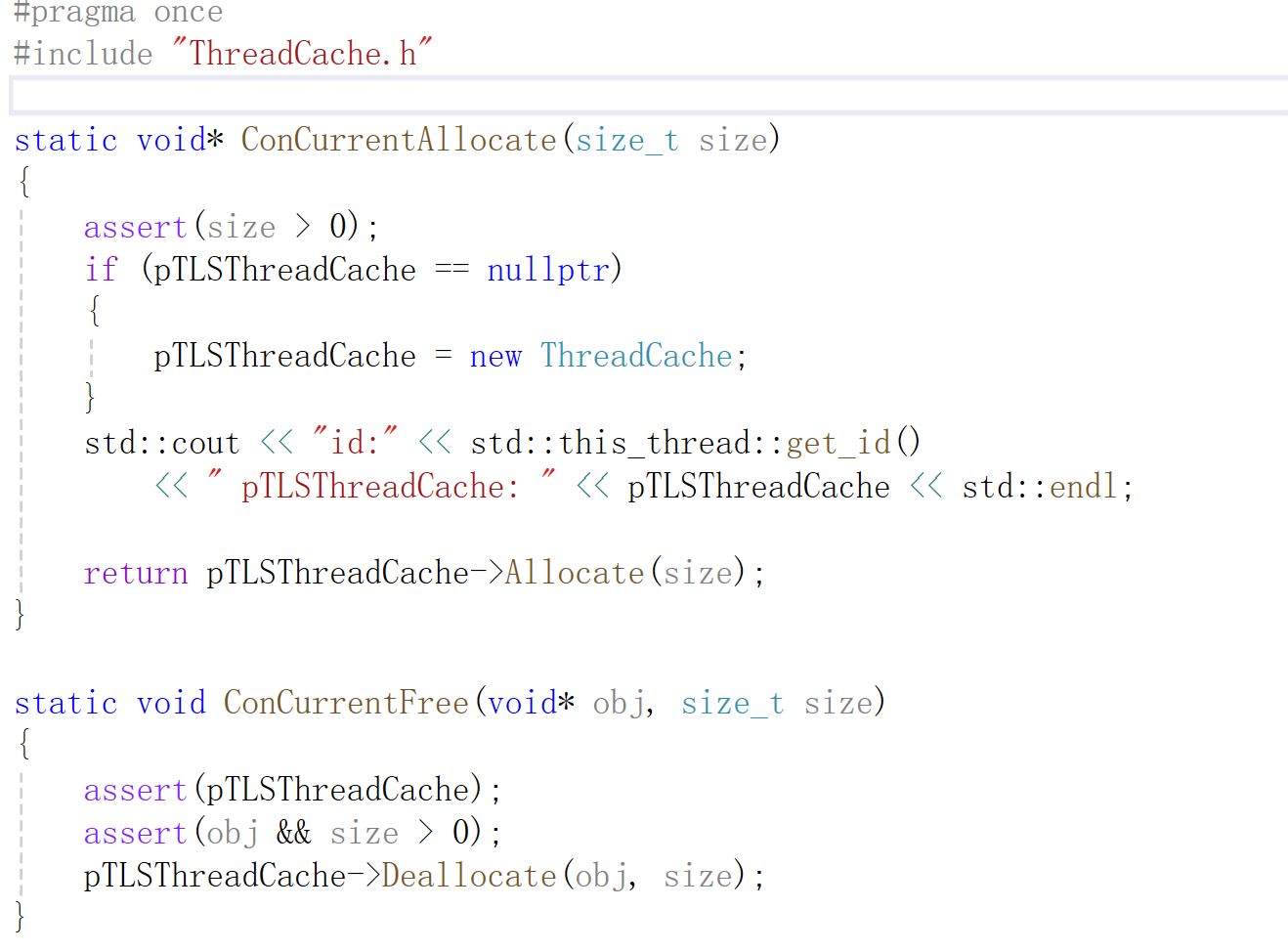
6.3 ConcurrentAllocate调用逻辑(业务获取逻辑)
如果为空,先创建pTLSThreadCache对象,然后调用其对应的Allocate方法。
7.Central Cache模块
7.1 central cache结构
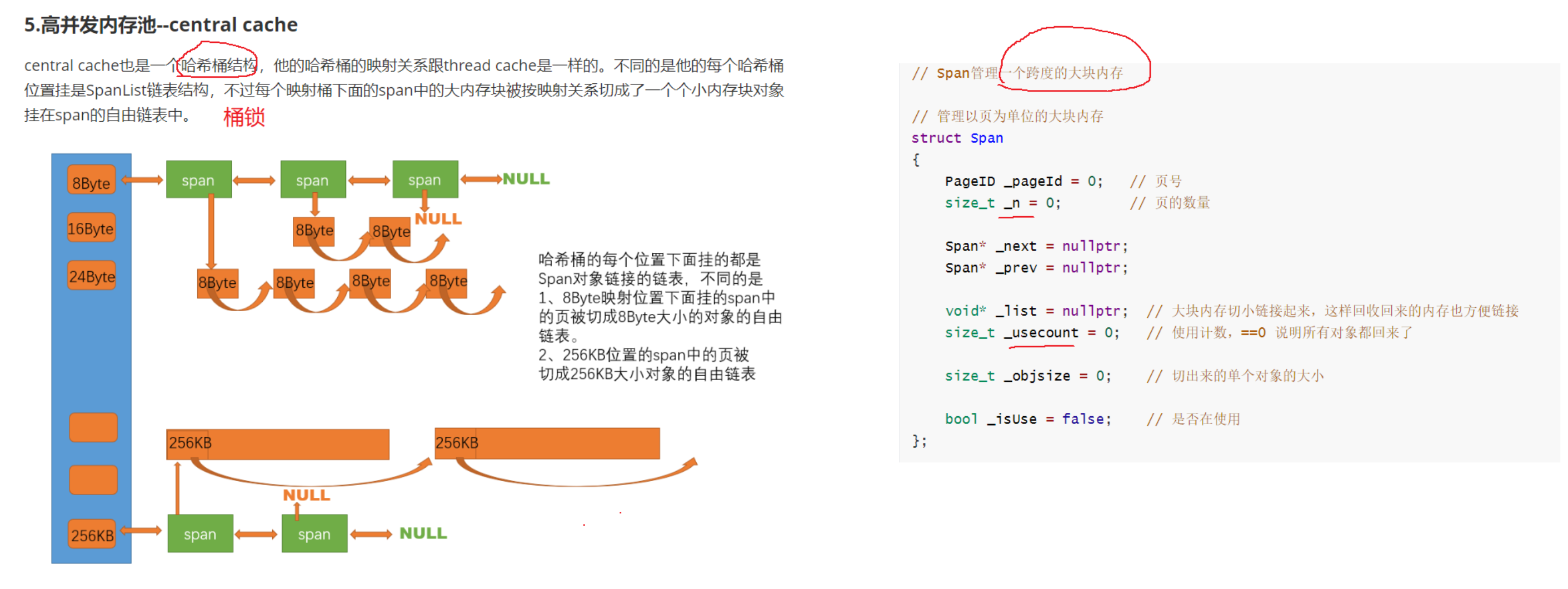
central cache也是一个哈希桶结构,并且映射关系和thread cache完全一样。只不过桶是一个双向带头链表,里面每个节点是一个struct span,每个span里存放这一条自由链表。
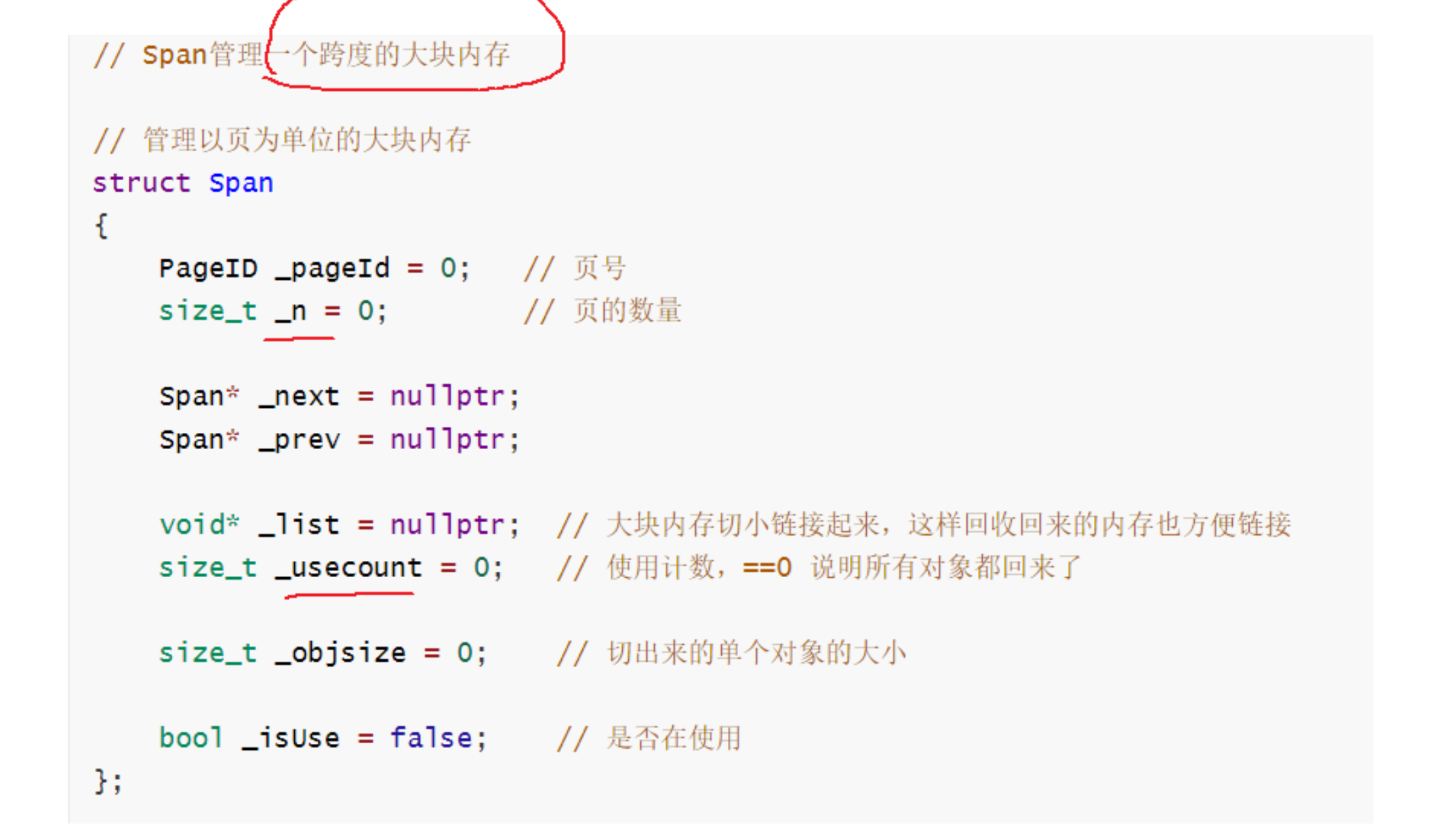
pageId:物理内存页页号,以8KB为一页来计算,32位下页号max = 2^32 / 2^13 = 2^19,64位下页号max=2^64 / 2^13 = 2^51,如果仅仅用unsigned int来存,64位页号存不下,用unsigned long long来存,对于32位又太多了。采用条件编译的方法,来实现不同架构存不同类型。
注意:windows的x64定义了_WIN64和_WIN32,x86只定义了_WIN32,开始判断时应先拿_WIN64作为条件。
span为什么要双向链结构?为了ThreadCache还回来的时候,use_count减到到0了,再还给下层,用于合并相邻页,一定程度解决外碎片问题,这个过程需要删除span,双向链好删除。
central cache的哈希桶存放一条存span的双向带头循环链表(先描述,在组织),因为哈希桶采用的是桶锁,所以双链表内还要带一个锁成员。
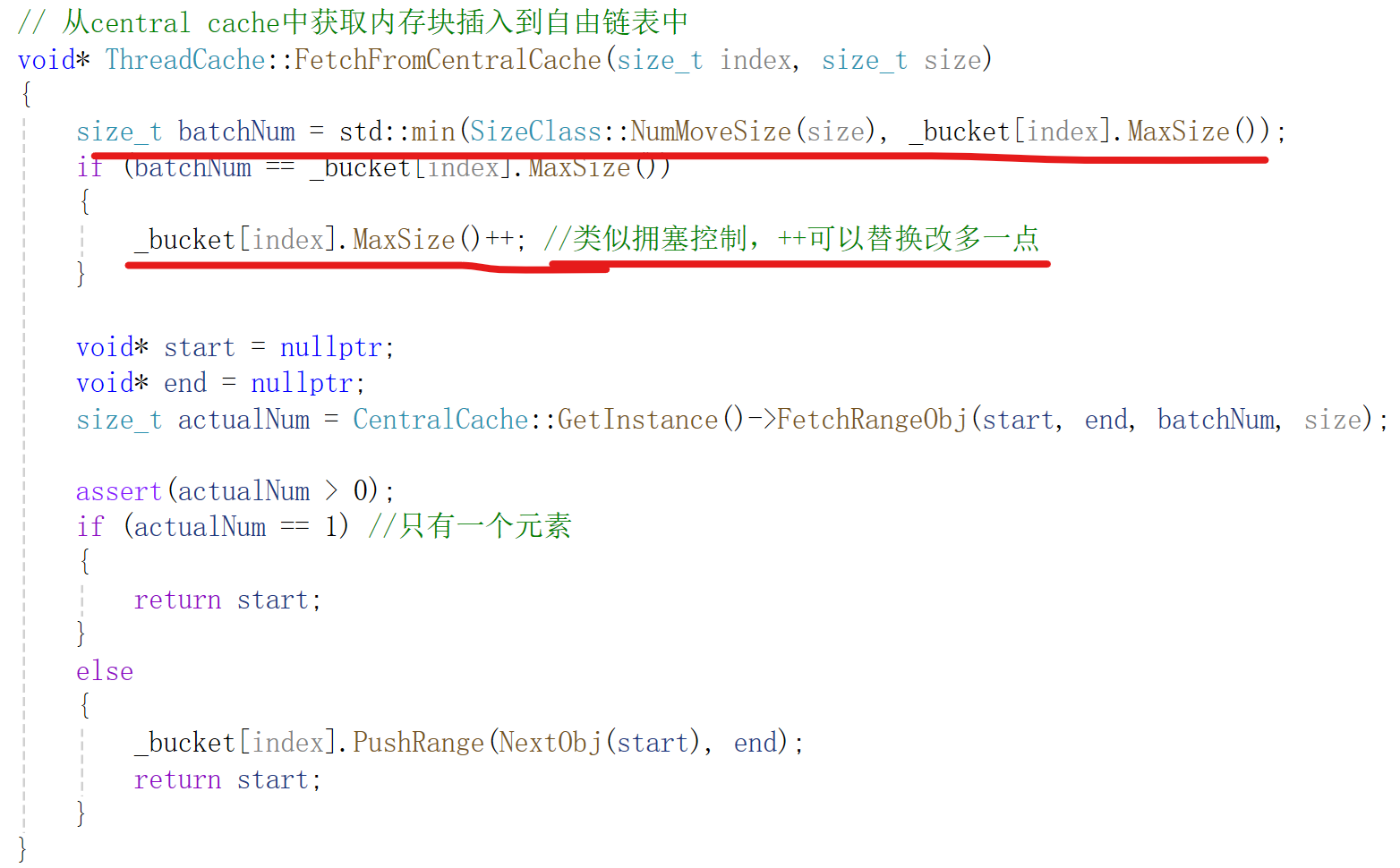
7.2 thread cache的FetchFromCentralCache实现
FectchFromCentralCache逻辑分析:
由于当前FreeLsit没有内存块了,要问central cache要,要多少合适?
1)一个?太少了,要的会很频繁2)固定个数?有的内存块大,有的小,大的要不了那么多,小的要少了要频繁要;没有考虑实际使用情况,有可能当前FreeList要内存块很频繁,却给的很少;
思路:既要根据内存块大小来要,大内存给少,小内存给多;又要根据实际要内存频率来要,频繁要的就给多,不频繁的给少。
实现:取min(按内存块大小分,按当前FreeList向central cache要内存块频率分)
NumMoveSize函数实现(根据内存块大小计算要的内存块数量):


7.3 central cache的FetchRangeObj实现
FetchRangeObj:用来给thread cache提供一批相同对齐数的内存块。
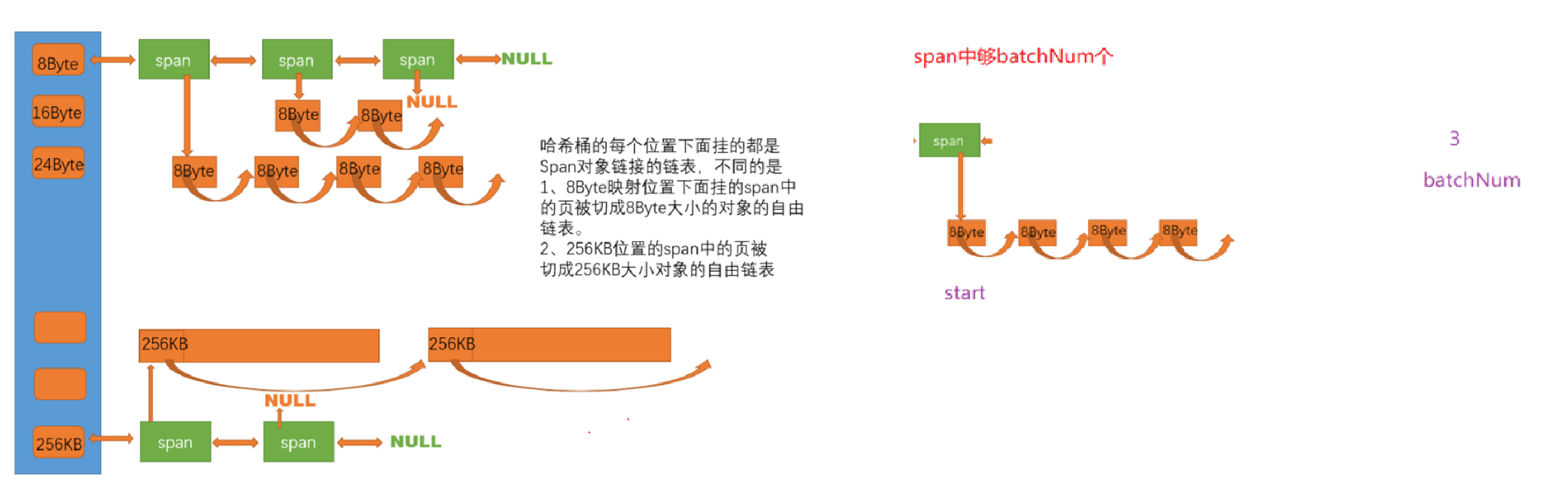
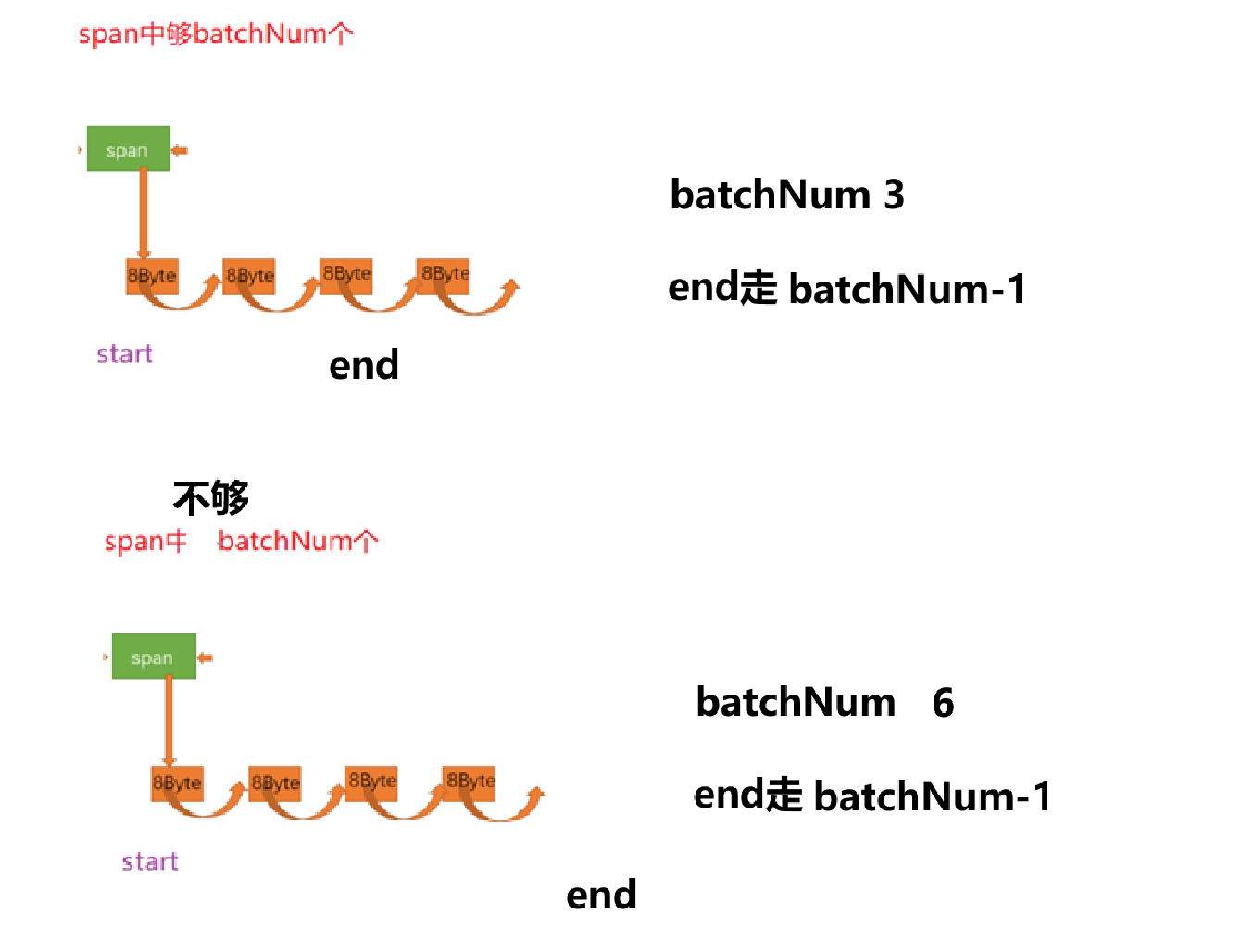
思路:先根据对齐数size计算出桶下标,在根据桶去调用GetOneSpan获取一个span对象(span的freeList非空),然后再去截取batchNum个内存块,如果不够,有多少给多少。返回值为真实截取了多少给内存块。
情况分析:哈希桶有节点span
a.span中FreeList节点数不足batchNum(上层thread cache要的)
b.span中FreeList节点数够batchNum
代码逻辑:

8.整体设计
9.需要注意的细节
NewSpan有一个递归锁问题:
1)分出子函数
2)C++递归锁
解决:干脆直接放到上层去加锁,直接放到GetOneSpan去加锁
从tread cache中回收的内存块可能属于同一个central cache桶内的多个span对象,归还时要注意。
归还时,可以类比虚拟地址转化成页表,虚拟地址后13(内存页大小2的指数)为页内偏移,通过取前32-13 = 19位就得到页起始地址。页起始地址/页大小 = 页的编号,就可以实现精准到页的归还了。
不能通过判断use_count来判断span在page cache还是central cache,有间隙,central cache问page cache要完了,切分的时候use_count是0;通过是否使用标志位_use。
- 特别注意1:central cache的FetchRangeObj取start,end范围时,一定要给NextObj(end)置nullptr,断开来,否则就和后面的黏在一起了。而且截取完后,需要修改span->_freeList的值。
- 特别注意2:将Span按大页进行切分,尾插时需要注意将最后一块的NextObj()置为nullptr。
- 特别注意3:page cache中进行合并后,原cur建立的映射关系需要进行删除,建立的映射关系(pageId,Span*)的头尾删除
解决不穿对象大小free:
Span内部加一个切分属性,表示按多大的size切的
10.基数树优化unordered_map读时需要加锁
经过性能分析发现,大部分的消耗都在锁上,为了突破瓶颈,要解决锁的问题。
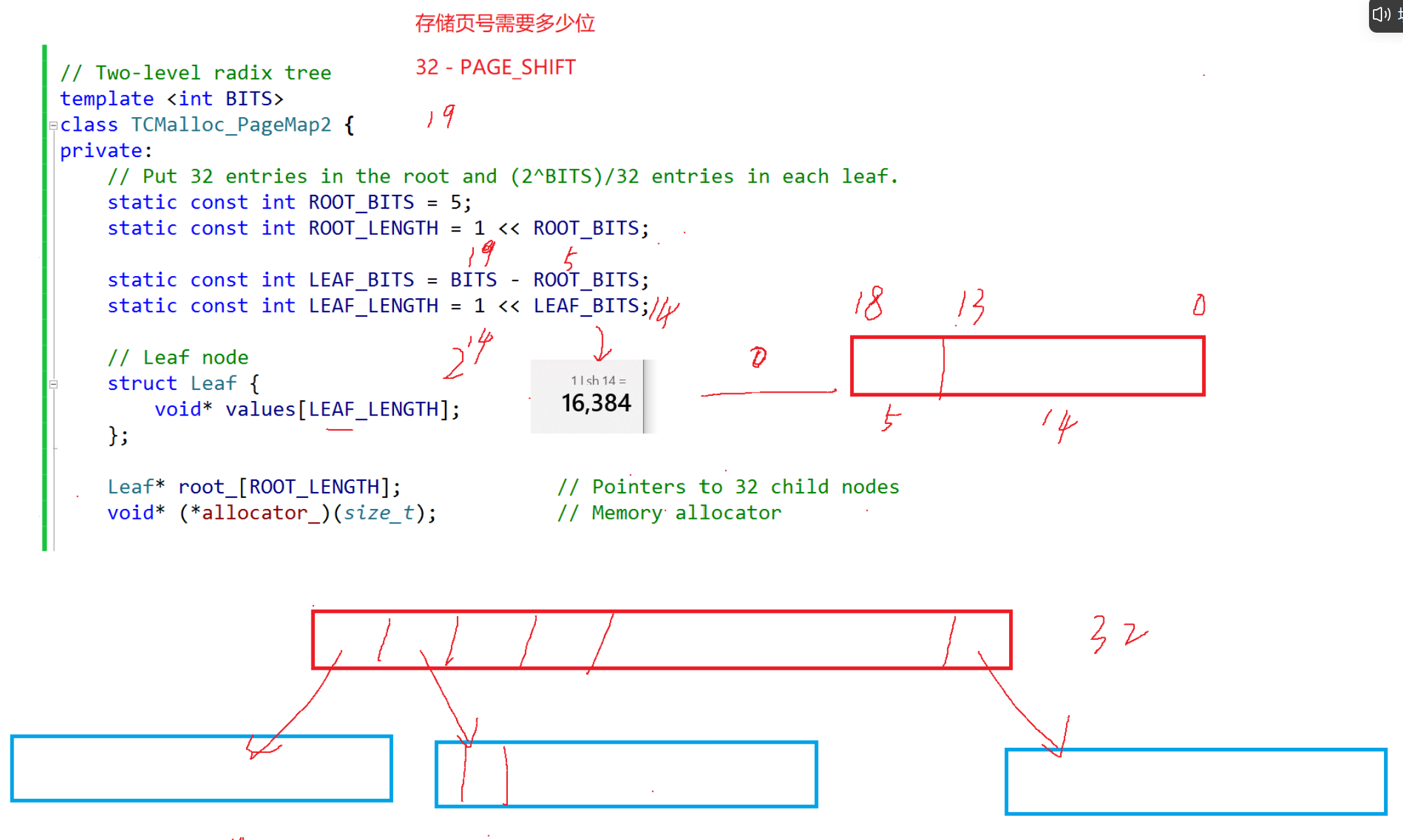
基数树的结构理解(类似进程地址空间的页表):
一阶基数树是直接映射,pageId直接映射对应的指针(pageid, Span*)。BITS非类型模版参数指的是存储页号需要多少位。
优点:直接映射效率高
缺点:直接映射代表一个数组要一次性就全部开好,不管这个位置将来会不会映射。浪费空间,32位下占用内存2M,64位下需要2^51 * 8 = 2^54,没那么多内存。
二阶基数树加了一层数组,通过2次映射来查找。例如32位,一页是8KB情况下,根据最高5位确定第一层数组对应下标,根据次高14位确定第二层数组对应下标,找到对应的映射。
优点:可以用的时候再进行开数组,节省了空间
缺点:2次映射效率比直接映射更低
三阶基数树与二阶同理,就是又多加了一层。可以存64位页号。
可以发现,基数树这个实现思路和页表几乎一样,数组用的时候再申请 vs 缺页中断。
基数树可以取代unordered_map 和 map的原因:
1)基数树增删查改O(1)
2)读写位置是分离的,逻辑上有同步
3)基数树的写不会改变结构,而unordered_map和map的写会改变结构(扩容、旋转等)(根本原因)
因为基数树的写不会改变结构,所以不需要加锁;而哈希表和红黑树会,需要加锁。

11.项目总结
项目亮点:
1)central cache桶锁
2)page cache使用基数树存(pageid,Span*)优化成读无需加锁
3)在central cache调用NewSpan过程到切分好这个过程是把桶锁释放了的;central cache调用RecycleOneSpan到这个函数返回,桶锁是释放了的。
细节:
读是在用的时候,central cache里的Span已经被开好了,跟page cache无关,逻辑上page cache不可能动到这个已经申请好的Span;还有就是ConcurrentFree不传size,反查size时,也是已经在用了,跟page cache无关,page cache申请和释放都动不到这个位置(准确来说是写不到这个位置上,读还是能读,因为合并的原因,但读读不影响)
读写分离本质原因:在page cache和不在page cache两块的使用上面是分离的
项目源码和思路: