一次投放事故让我彻底意识到监控的重要性
我们公司有一个社交类 App 项目由我负责接手,上线后就开始投放广告买量。
日常的增长主要依靠在抖音、快手等平台投放广告。
当时项目正处于大力推广阶段,每天 的投放预算加起来大概在 50 万到 70 万之间 。
这种体量下,ROI(投产比)和 ARPPU(付费用户平均收入)几乎就是项目的生命线。
只要 ROI 稳定,我们就能持续投放滚量;
但只要 ROI 掉得太多,就得立刻停投,否则亏损非常明显。
直到有一次,我们突然发现当天的 ROI 异常地低。
所有的代理商都紧急卡量、不再放量,一下子整个投放数据都不对劲。
一开始大家都在分析广告素材、投放人群,怀疑是流量质量出了问题。
但奇怪的是,连平时表现最稳定的几家优质代理商数据也异常,转化率几乎腰斩,那基本上就是项目出了问题。
我们由于经验不足,一开始摸不着头脑,不知道到底是哪环出了问题,到处在排查异常。
直到客服反馈说,很多用户来找客服反馈无法充值,我们才终于意识到,问题根本不在投放,而是出在支付环节。
排查之后发现,微信支付商户号被风控拦截,所有支付请求都失败了。
而微信支付又占了用户付费方式的绝大部分,再加上后台没有任何监控和告警机制,接口虽然在跑,但所有请求其实都在报错。
那一天的广告投放几乎全白烧,ROI 直接腰斩,用户流失严重,后续付费率也明显下滑。
当时整个团队都很受打击。那天光广告费用就烧掉了五六十万,
而这个项目是由我和项目负责人全权负责。
每次到了月底要把项目数据报给老板,
ROI 掉下去或者收入异常,老板的第一反应就是质问我们:
"为什么系统出问题没人发现?你们每天都在忙什么呢?!"
几次下来,不仅挨骂,还会直接扣绩效。
所以在项目稳定性这件事上,我们真的是绷着一根弦。
但再怎么谨慎、再怎么加班排查,仍然会有各种突发问题。
有时候代码没问题,系统却早已"失联"------它出问题了,但没人知道。
不仅是支付问题,系统层面也在频繁"掉链子"
其实,这种"太晚发现"的情况在系统层面也经常发生。
除了支付风控,我们还遇到过不少类似的坑:
- 某次 MQ 队列堆积,导致异步任务延迟了几个小时才执行;
- MySQL 连接池耗尽,部分接口直接超时;
- Redis 主从延迟,读取到了旧数据,触发了一连串逻辑错误;
- 某个核心接口因为一次上线 bug,错误率暴涨,但没人报警;
- CPU 负载飙高 或 线程池阻塞,系统卡死但表面一切正常。
这些问题的共同点是:
服务还在跑,但业务已经"不正常"了。
每次出问题,基本都是:
用户先投诉 → 客服汇总 → 运营转技术 → 技术查日志 → 最后才发现问题。
等我们修好,损失已经无法挽回。
那段时间我们几乎天天被各种问题追着跑:
ROI 一掉就查支付,延迟一高就翻日志,凌晨被叫醒是常态。
没有一套系统能主动告诉我们"哪里出了问题",
一切都是等出了事再救火,靠经验去猜。
决定搭建监控系统,让系统自己报警
后来项目负责人找我聊了聊,
他觉得这样下去不是办法。
既然项目事故不可能百分之百避免,那就得想办法尽可能第一时间发现问题 。
项目流程的完善性他来负责,
而系统层面的监控就交给我来想办法解决。
没办法,我也清楚这是个必须得补的坑。
要想真正减少损失,就得让系统学会"自己报警"。
看来只能部署一套监控系统来实时监听各项指标------
不仅要能看机器层面的指标(CPU、内存、磁盘),
还要能看业务层面的运行情况:接口成功率、支付成功率、MQ 堆积、数据库连接数、Redis 命中率等等。
出了问题,系统能第一时间发出告警,
而不是等用户投诉、ROI 掉下去、或者老板发火了才知道。
所以我打算先搭建一套 Prometheus + Grafana 系统监控,
从系统到底层、从资源到业务,
让整个项目的运行状态都能"看得见、测得到、提前发现问题",及时止损。
Prometheus 是怎么监控应用的
在开始搭建之前,我们先简单回顾一下 Prometheus 的监控原理。
其实它的工作方式非常简单。
Prometheus 并不会主动"插"进我们的系统去收集数据,而是通过一种"探针"的方式来采集。
也就是说,只要我们的服务能提供一个 HTTP 接口,把监控数据暴露出来,Prometheus 就能定期访问这个接口,拉取数据。
在 Prometheus 的体系里,这种暴露监控数据的程序被称为 Exporter 。
比如想监控 MySQL,就用 mysql_exporter;
监控 Linux 主机,就用 node_exporter;
如果是我们自己的业务系统,就在项目中暴露一个 /actuator/prometheus 接口,让 Prometheus 定期来访问。
Prometheus 会按照配置的时间间隔,不停地去这些 Exporter(也叫 Target)拉取数据。
拿到的数据会以统一的格式(称为 Metrics 格式)保存下来,比如:
json
http_server_requests_seconds_count{status="200",uri="/api/order"} 152
http_server_requests_seconds_sum{status="200",uri="/api/order"} 3.24这些内容看起来像日志,其实就是系统上报的监控样本,
比如接口调用次数、耗时、成功率等指标。
Prometheus 会把这些数据定期拉取保存,
再通过 Grafana 将它们以图表的形式展示出来。
所以简单理解就是:
Prometheus 不去"监听",而是主动"拉取";
它通过探针(Exporter)定时访问各个服务的监控接口来获取指标数据。
结合 Spring Boot 与 Prometheus 搭建监控服务
前面我们已经了解了 Prometheus 是如何通过"探针"的方式去采集应用数据的,
接下来就该进入搭建环节------我们要自己把它跑起来。
这里我打算结合 Spring Boot 应用 与 Prometheus 来搭建一套简单的监控服务,
把我们项目的业务指标、系统指标都统一纳入可观测范围。
这里关于 Prometheus 和 Grafana 的基础原理我就不展开讲了,
相信很多同学都已经听过甚至用过这两个工具。
Prometheus 负责采集和存储监控数据,Grafana 用来做可视化展示------
这一套在大多数公司里都是标配。
不过我们公司的情况比较特别,
没有专职运维团队,也没有专门的监控平台,
所以这些事只能由我这个技术负责人亲自来搞。
从环境部署到指标配置再到告警通知,全都得自己一步步搭起来。
本篇的实践环境基于 CentOS 系统 ,
我们会以一个 Spring Boot 应用 为例,
讲解如何与 Prometheus 集成、暴露监控指标,并完成 Prometheus + Grafana 的整体搭建。
在 Spring Boot 中暴露监控指标
接下来我们先从 Spring Boot 这边开始。
要让 Prometheus 能够抓取到我们应用的运行数据,
首先需要在项目中引入一个专门的依赖,用来暴露应用的指标接口。
在 pom.xml 中添加以下依赖:
xml
<!-- 暴露 /actuator/prometheus 指标接口 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>加上这段依赖之后,Spring Boot 会自动帮我们把 Prometheus 所需的监控组件配置好。
简单来说,它会自动创建一个 PrometheusMeterRegistry 和一个 CollectorRegistry,
用来把项目中的各种运行指标(比如接口耗时、请求数量、JVM 状态等)
转换成 Prometheus 能识别的 Metrics 格式。
配置完成后,我们的 Spring Boot 应用就会在 Actuator 模块下
自动暴露一个 /actuator/prometheus 接口。
这个接口就是给 Prometheus 定期拉取数据用的"探针端点"。
换句话说,只要我们的服务启动了,访问这个地址------
bash
http://localhost:8080/actuator/prometheus就能看到系统实时输出的监控指标数据。
后面我们只要在 Prometheus 的配置文件里把这个地址加进去,
Prometheus 就会定时来拉取数据,把应用的运行情况同步过去。
配置 Actuator 暴露 Prometheus 端点
依赖加好之后,我们还需要在 application.yml 中做一些简单的配置,
让 Spring Boot 把监控端点真正暴露出来,方便 Prometheus 去抓取。
json
spring:
application:
name: monitor-demo
server:
port: 8888
address: 0.0.0.0
management:
endpoints:
web:
exposure:
include: health,info,prometheus # 暴露 prometheus 端点
endpoint:
health:
show-details: always
metrics:
tags:
application: ${spring.application.name} # 给所有指标加上应用名标签这里我们主要做了三件事:
- 暴露监控端点 :
management.endpoints.web.exposure.include指定要开放的端点列表,
默认情况下/actuator/prometheus并不会自动暴露,
所以必须手动加上。 - 显示健康详情 :
management.endpoint.health.show-details: always
可以让/actuator/health端点显示更多服务健康信息。 - 为指标统一打标签 :
通过metrics.tags.application配置,
可以给每一条监控数据自动带上应用名。
在 Grafana 仪表盘中查看多个服务指标时,这个标签会非常有用。
配置完成后,我们启动应用并访问:
bash
http://localhost:8888/actuator/prometheus如果我们能成功看到类似下面这样的页面输出:
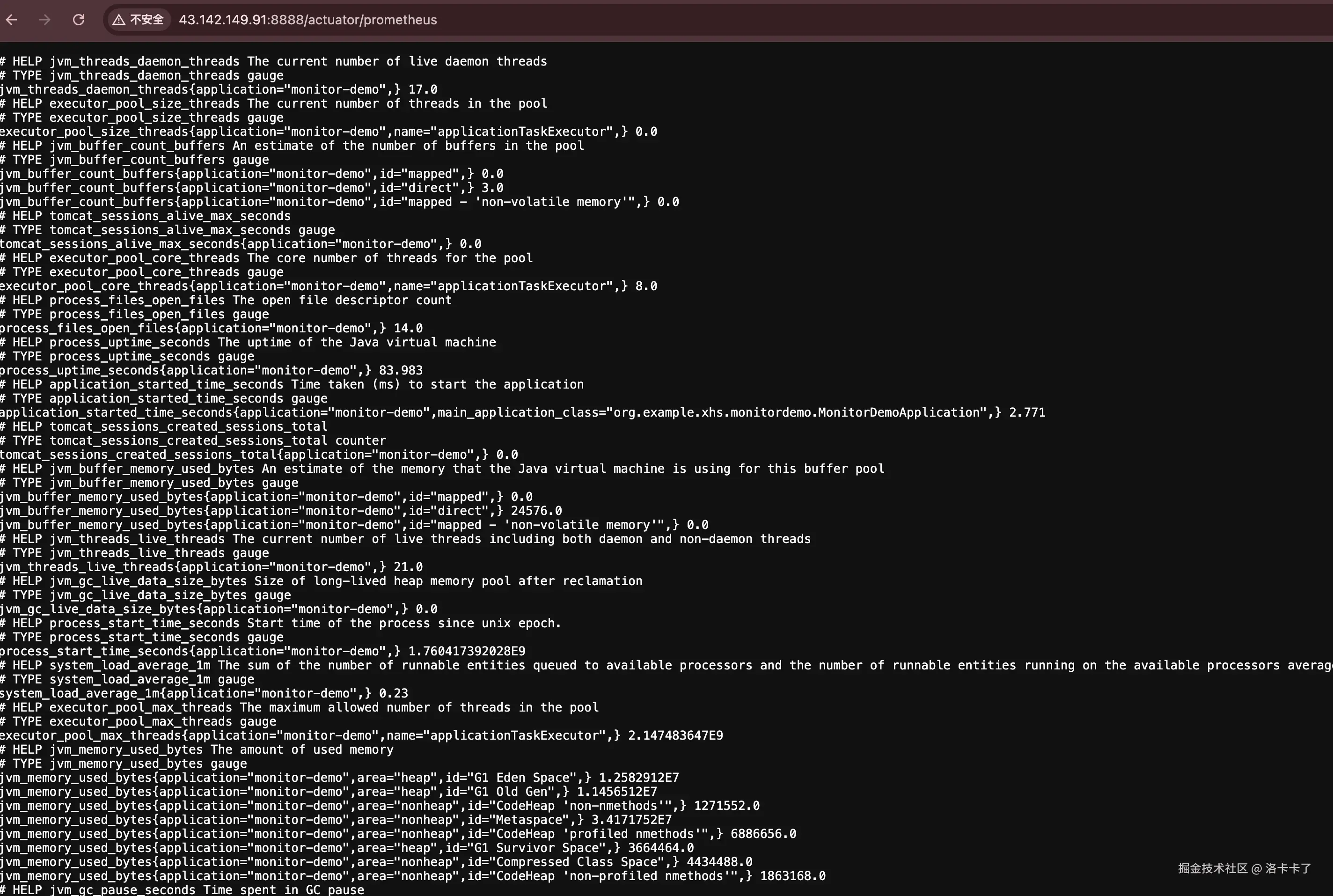 说明应用端的监控指标已经暴露成功。
说明应用端的监控指标已经暴露成功。
上面的内容就是 Spring Boot 应用实时暴露的监控指标数据。
虽然看起来像一堆文本,但其实每一行都是一个指标样本。
比如:
jvm_memory_committed_bytes表示 JVM 当前提交的内存大小;process_files_max_files表示系统允许的最大文件句柄数;system_load_average_1m表示系统 1 分钟的平均负载;http_server_requests_seconds_count表示 HTTP 请求的总次数;http_server_requests_seconds_sum表示请求总耗时。
这些指标都遵循 Prometheus 的标准格式(Metrics 格式),
Prometheus 服务会定期来访问这个端点,把这些数据拉取回去存储。
接下来我们只需要在 Prometheus 的配置文件里把这个地址加进去,
它就能自动完成采集。
使用 Docker 搭建 Prometheus 与 Grafana
前面我们已经让 Spring Boot 应用成功暴露了监控指标,
接下来就是搭建 Prometheus 和 Grafana,用来采集数据并展示可视化监控。
我们这里的目标很简单:
在一台服务器上,通过 Docker 快速运行 Prometheus 与 Grafana 两个容器,
让 Prometheus 去抓取 Spring Boot 的指标数据,再在 Grafana 中展示出来。
这里我们默认服务器上已经安装好了 Docker 和 Docker Compose,
安装部分就不再展开说明。
如果还没有安装,可以参考官方文档或者执行一键安装脚本。
1. 创建工作目录
首先在服务器上创建一个独立目录来存放配置文件和数据:
bash
mkdir -p /opt/monitor/prometheus
mkdir -p /opt/monitor/grafana
cd /opt/monitor目录结构大致如下:
bash
/opt/monitor/
├── prometheus/
│ └── prometheus.yml # Prometheus 配置文件
├── grafana/
│ └── data/ # Grafana 数据持久化目录
└── docker-compose.yml # Docker 启动文件2. 编写 Prometheus 配置文件
在 /opt/monitor/prometheus/ 目录下新建 prometheus.yml 文件,内容如下:
yaml
global:
scrape_interval: 5s # 每 5 秒抓取一次指标
scrape_configs:
- job_name: 'monitor-demo'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['host.docker.internal:8888'] # 这里是 Spring Boot 的访问地址说明:
scrape_interval表示 Prometheus 拉取数据的时间间隔;job_name是任务名称,可以自定义;metrics_path就是我们在 Spring Boot 中暴露的/actuator/prometheus;targets指明目标应用地址,如果 Prometheus 与应用在同一台服务器上,可以写成主机 IP + 端口。
3. 编写 docker-compose.yml
在 /opt/monitor 目录下创建 docker-compose.yml:
yaml
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
restart: always
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
volumes:
- ./grafana/data:/var/lib/grafana
restart: always4. 启动容器
执行:
docker compose up -d
 启动成功后,我们可以访问以下地址:
启动成功后,我们可以访问以下地址:
- Prometheus 控制台:http://服务器IP:9090
- Grafana 控制台:http://服务器IP:3000
登录并验证 Prometheus 是否采集到数据
首先我们先打开 Prometheus 控制台地址。
和 Grafana 不同,Prometheus 默认是没有登录界面 的,
访问后会直接进入主页面,也就是一个名为 "Expression(或 Query)" 的查询界面。
注意,这种情况并不是异常,而是不同版本的 Prometheus 默认行为不同。
部分较新的镜像版本(尤其是最近几个月更新的 latest)会默认开启 Web 安全配置,
因此访问时会出现登录页面并要求修改密码;
而我们这里使用的镜像版本没有启用该配置,所以访问时会直接进入主页面。
这种设计并不是 bug。Prometheus 本身是为内部监控环境 设计的系统,
默认假设运行环境是可信的,因此不会自带复杂的用户认证机制。
在需要安全访问控制的场景下,通常会在外层通过 Nginx 反向代理 、
或仅开放给 内网访问 的方式来保护监控服务。
在这个查询页面的上方,我们会看到一个输入框,我们可以在这里输入查询表达式。
我们先输入一个最简单的指标名称来验证数据是否被成功采集:
up输入后点击 "Execute" 按钮。
执行查询后,我们可以看到类似这样的结果输出:
ini
up{instance="43.142.149.91:8888", job="monitor-demo"} 1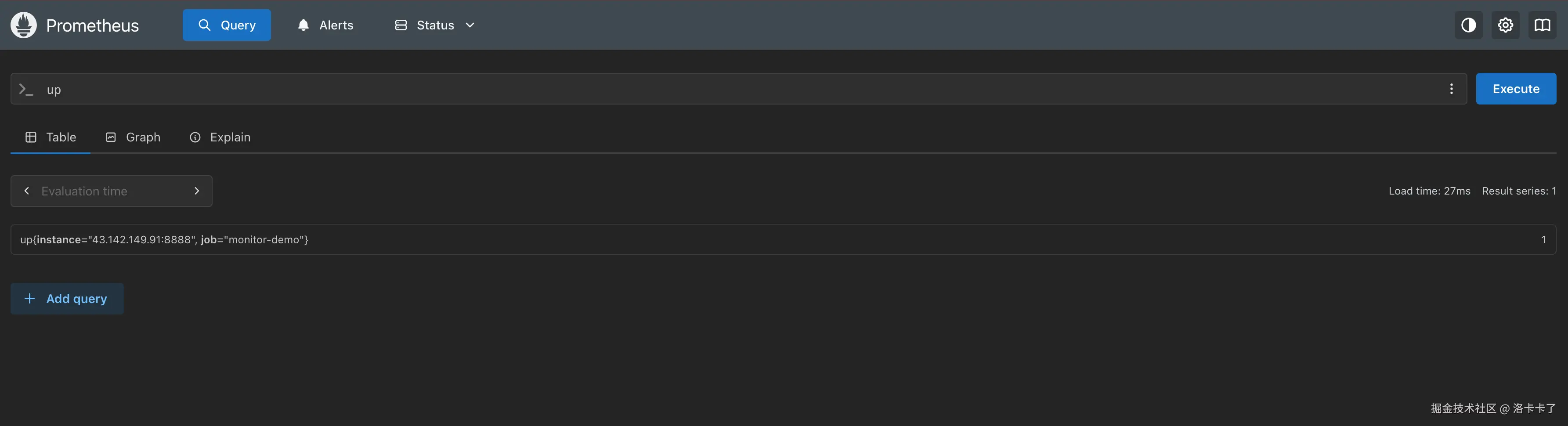 这里的字段含义如下:
这里的字段含义如下:
up:这是 Prometheus 内置的一个健康状态指标,用来判断目标实例是否"在线";instance:表示被监控应用的地址和端口,这里是我们的 Spring Boot 服务43.142.149.91:8888;job:对应我们在prometheus.yml里配置的任务名(这里是monitor-demo);- 数值
1:表示当前实例处于 存活(UP)状态 ;
如果显示为0,就说明 Prometheus 无法访问该目标(例如应用未启动或端口配置错误)。
看到这条数据说明 Prometheus 已经成功拉取到了 Spring Boot 应用的监控指标,
接下来我们就可以在 Grafana 里把这些数据可视化展示出来了。
除了验证服务是否在线外,我们还可以在 Prometheus 控制台中查看更具体的接口级指标。
比如在查询框中输入以下指标名称:
http_server_requests_seconds_count这个指标由 Spring Boot Actuator + Micrometer 自动提供,
表示 HTTP 接口的请求总次数 。
它会按照不同的请求维度(方法、状态码、URI 等)进行统计,
帮助我们分析接口的调用频率和分布情况。
执行查询后,我们可以看到类似下面的结果:
ini
http_server_requests_seconds_count{
application="monitor-demo",
exception="None",
instance="43.142.149.91:8888",
job="monitor-demo",
method="GET",
outcome="SUCCESS",
status="200",
uri="/actuator/prometheus"
} 3各字段的含义如下:
application:当前应用名称,也就是我们在application.yml里配置的spring.application.name;instance:应用实例的地址与端口;job:Prometheus 抓取任务的名称;method:HTTP 请求方法(如 GET、POST 等);status:HTTP 状态码;uri:请求的接口路径;outcome/exception:请求结果及是否出现异常;- 右侧的数字:表示该接口被调用的累计次数。
从上面的输出可以看到,/actuator/prometheus 接口被访问了几次(例如 3 次),
说明 Prometheus 正在定期抓取我们的指标数据。
在后续步骤中,这些指标就会被 Grafana 可视化展示,
让我们能更直观地看到接口调用情况和系统运行状态。
接入 Grafana:让监控指标更直观
到这里,我们的 Prometheus 已经可以正常从 Spring Boot 应用中抓取指标数据了。
但光看到一堆文本指标还不够直观,
如果能把这些数据以图表的方式实时展示出来,就能更方便地观察系统状态。
这时候就轮到 Grafana 登场了。
Grafana 是一个功能非常强大的数据可视化平台,
它可以把 Prometheus 中的监控数据通过图表、仪表盘等方式展示出来,
让我们更直观地看到 CPU、内存、请求耗时、接口成功率等指标的变化趋势。
1. 打开 Grafana 控制台
在前面我们用 Docker 启动过 Grafana,现在直接访问:
arduino
http://服务器IP:3000Grafana 默认账号密码为:
用户名:admin
密码:admin第一次登录后系统会提示我们修改密码(建议立刻修改为新的密码)。
登录后,我们就能看到 Grafana 的主界面。
接下来我们要做的第一步,就是把 Prometheus 加入为一个数据源。
2. 添加 Prometheus 数据源
登录成功后,我们会看到 Grafana 的主界面,如下图所示:
在左侧菜单中找到 Connections(连接) ,
点击下方的 Data sources(数据源) 进入数据源管理页面。
此时页面会显示 "No data sources defined",
点击中间的 Add data source 按钮开始添加新的数据源:
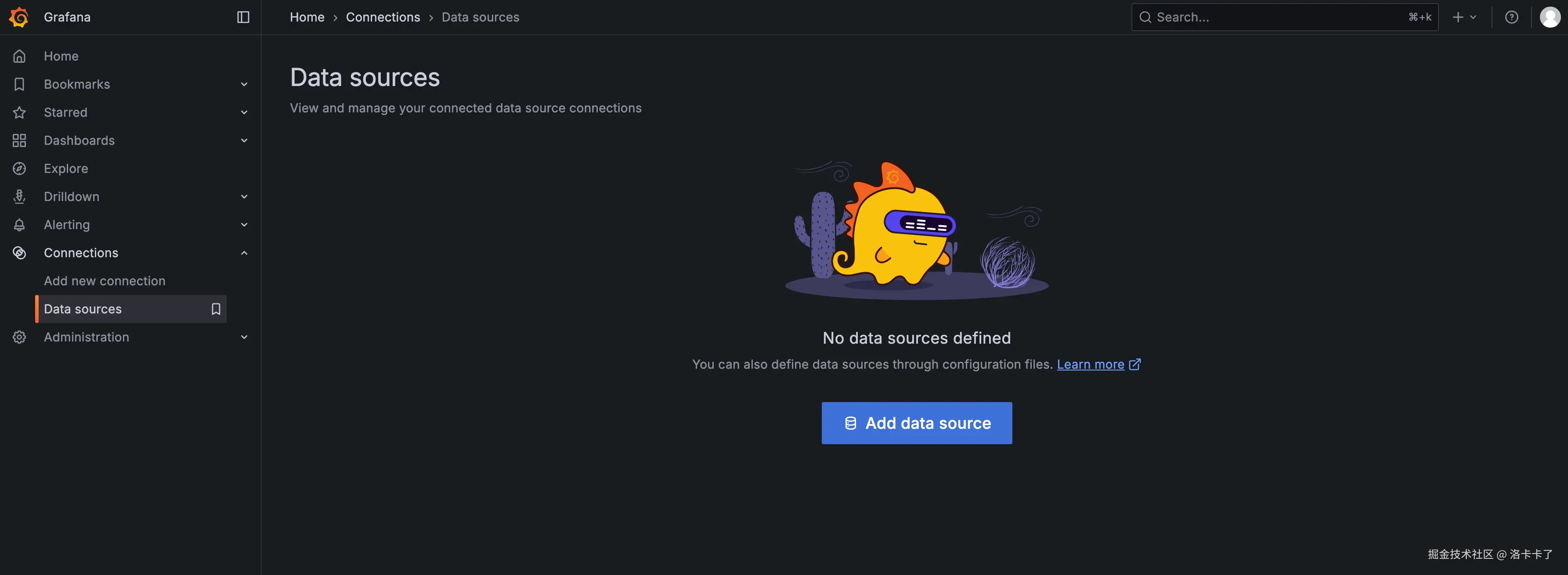
在弹出的数据源类型列表中,选择 Prometheus。
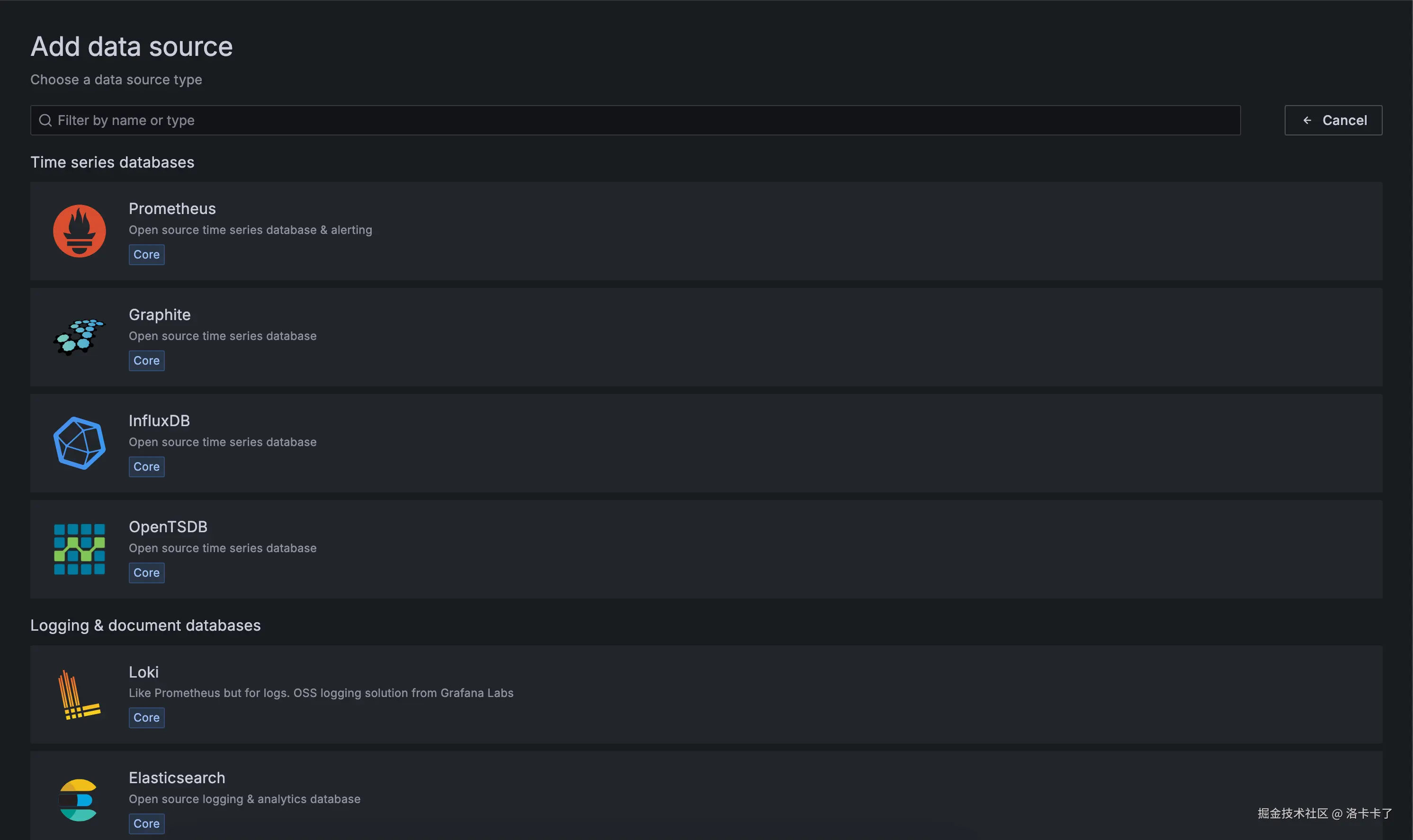
接下来在配置页面中填写 Prometheus 的访问地址,例如:
arduino
http://prometheus:9090如果 Prometheus 和 Grafana 不在同一个 Docker 网络中(比如分开部署在不同服务器),
可以直接填写宿主机的 IP 地址,例如:
arduino
http://43.142.149.91:9090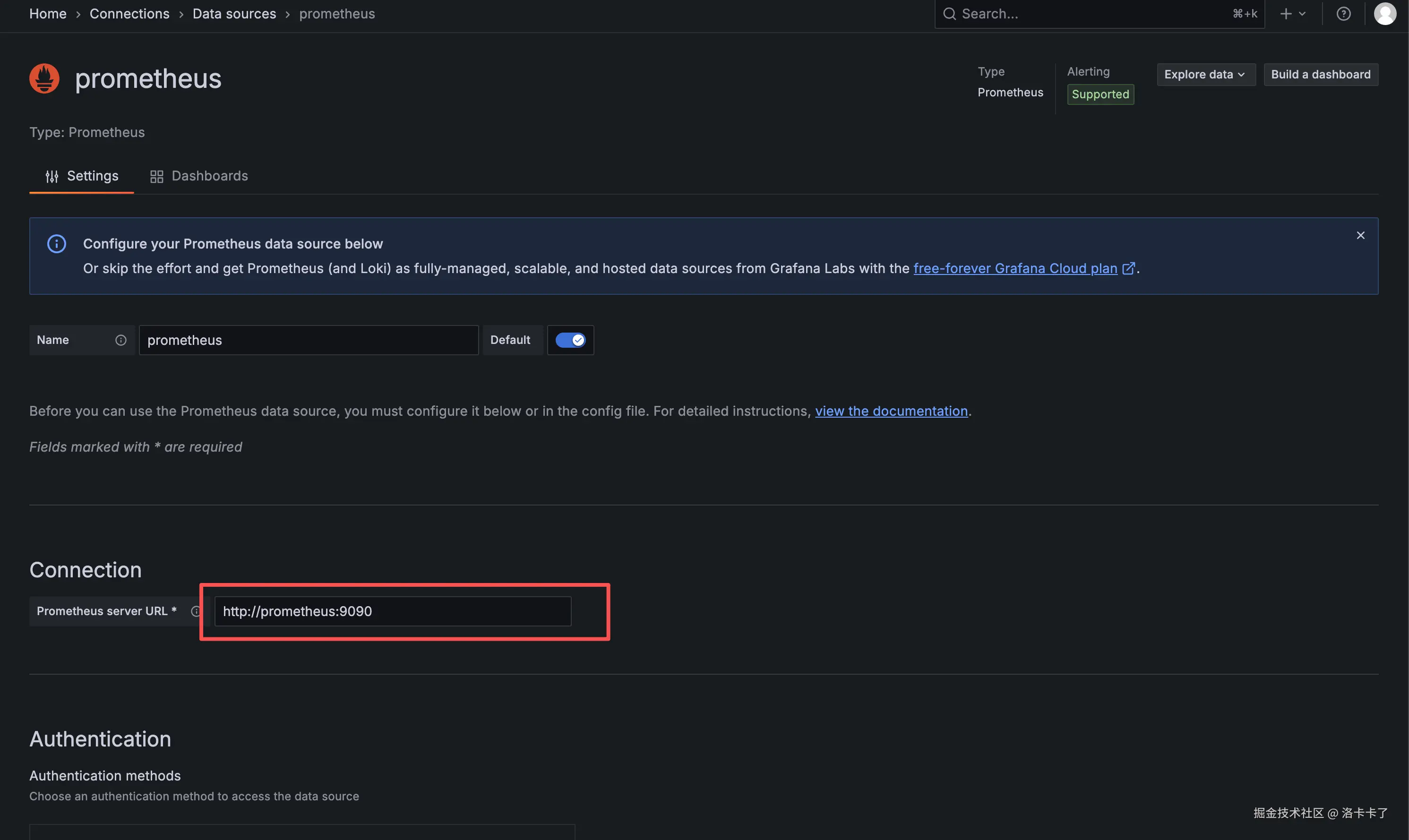
保持其他配置项默认即可,然后点击页面底部的 Save & Test 按钮。
如果看到提示 Data source is working,就说明 Grafana 已经成功连接到 Prometheus。

3. 导入 Spring Boot 监控仪表盘模板
数据源配置好之后,Grafana 已经能从 Prometheus 拿到数据了。
接下来我们要做的,就是让这些数据能"看得见"。
Grafana 本身提供了很多现成的监控模板,我们可以直接导入一个 Spring Boot 相关的仪表盘,
就能快速看到 JVM、CPU、请求耗时等监控图表。
首先,在左侧菜单中点击 Dashboards → Import 。
如果我们用的是新版 Grafana,也可以在左侧菜单的 Dashboards → New → Import 里找到入口。
点击进去后,会看到一个 "Import dashboard" 的页面。
在页面上有一个输入框,用来填写模板编号。
Grafana 社区里有很多别人做好的模板,我们可以直接使用。
比如比较常用的几个:
4701:JVM(Micrometer)监控模板,能看到内存、GC、线程等系统指标;11378:Spring Boot Statistics 模板,包含完整的应用级监控;12900:Micrometer JVM Dashboard 模板,专门针对 Micrometer 框架。
我们这里以 4701 为例,在输入框中填入编号后点击 "Load"。
加载完成后,Grafana 会让我们选择一个数据源。
这里就选刚刚创建的 Prometheus,然后点击 "Import"。
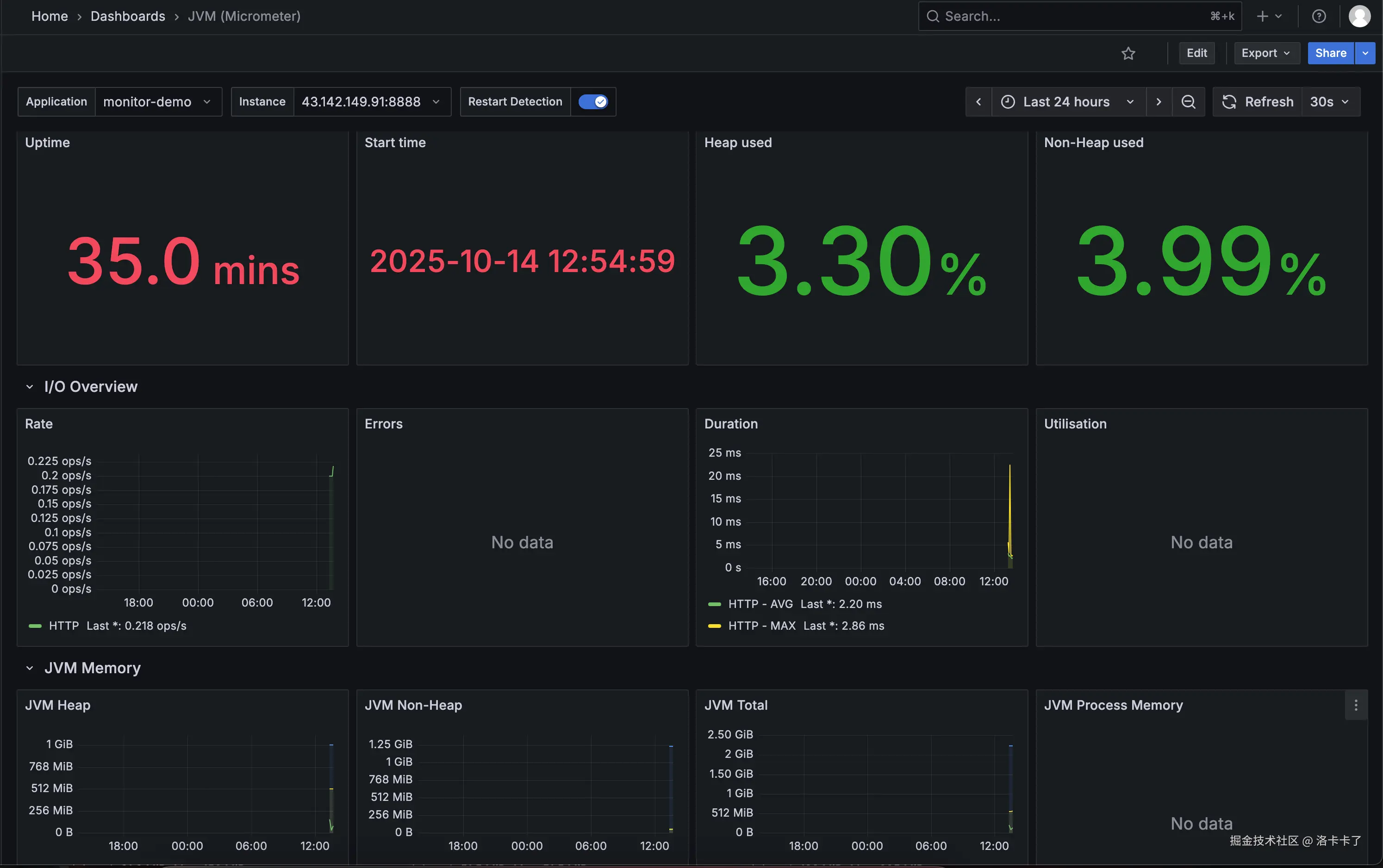
 几秒钟后,就能看到一个完整的监控仪表盘。
几秒钟后,就能看到一个完整的监控仪表盘。
在这个仪表盘里,我们可以看到 JVM 内存占用、GC 次数、线程池数量、
系统 CPU 和负载、接口请求数量和平均耗时等数据,
而且所有图表都是实时更新的,不需要我们再去写任何配置。
4.验证监控是否生效(通过压测接口)
搭建完监控之后,最关键的一步就是验证它是否真的"活着"。
Prometheus 默认会采集应用的 HTTP 请求次数、耗时、状态码 等指标,
所以只要我们持续访问接口,就能在 Grafana 的面板上看到实时变化。
这里我用的是一个非常轻量的压测工具 ------ hey (类似 ab、wrk)。
假设我们的 Spring Boot 应用里有一个简单接口:
arduino
http://43.142.149.91:8888/hello执行以下命令,对接口进行并发压测:
arduino
hey -n 20 -c 5 http://43.142.149.91:8888/hello参数解释:
-n 20:总共发起 20 次请求;-c 5:每次并发 5 个请求同时执行。
压测完成后,回到 Grafana 的仪表盘页面(例如模板 ID 4701 ),
查看与 HTTP 请求相关的图表,如:
- HTTP Server Requests Count(请求总数)
- HTTP Response Time(响应时间)
- Request Rate (req/s) (每秒请求数)
此时建议把 Grafana 的时间范围 调整为 "Last 5 minutes ",
刷新间隔 设置为 "1s",这样数据变化会更直观。
过几秒钟后,我们就能看到请求速率(Rate)、请求耗时(Duration)
以及 JVM 内存等图表开始出现波动。
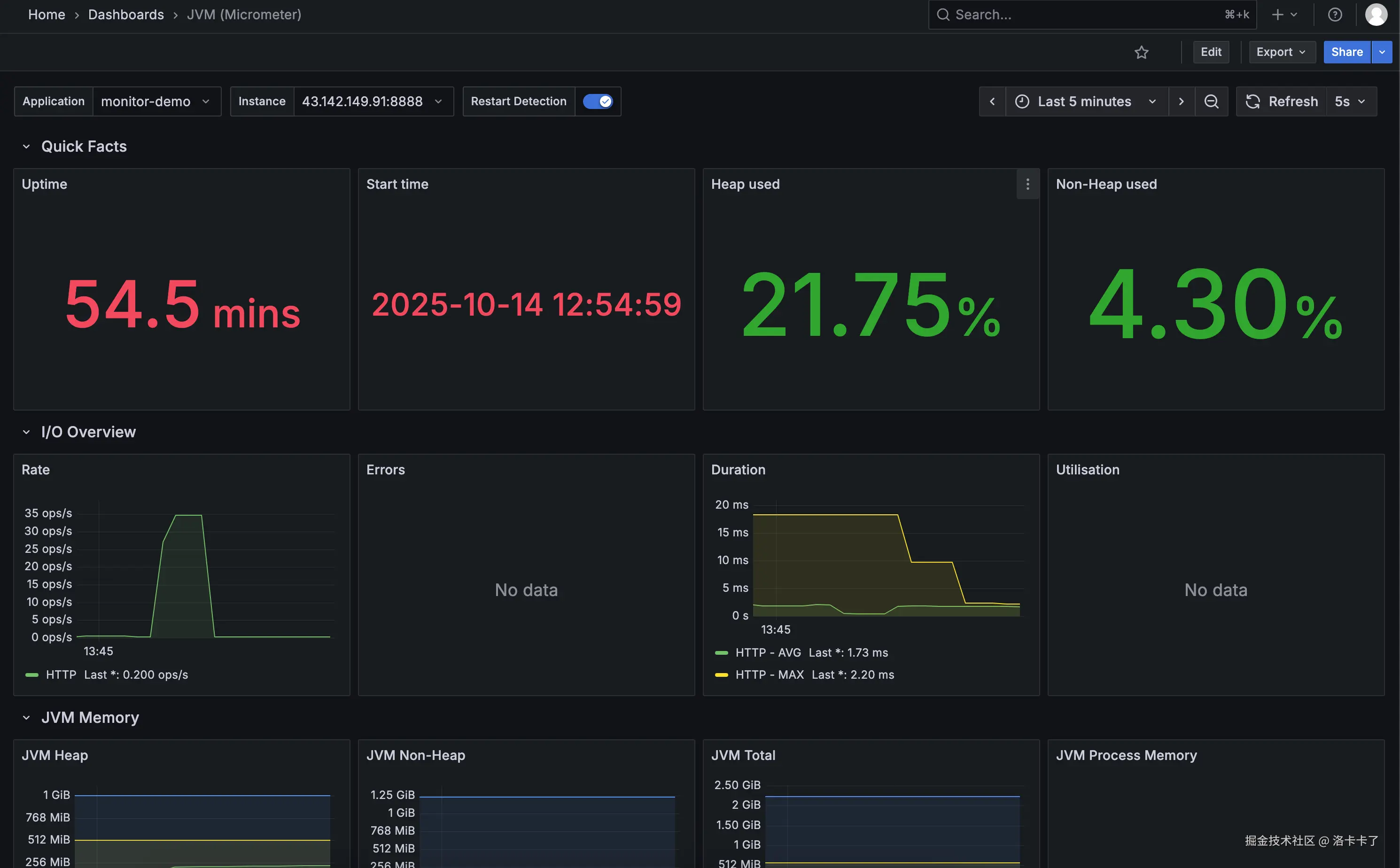
这说明 Prometheus 已经在持续抓取 /actuator/prometheus 的最新指标数据,
而 Grafana 也在实时展示这些变化 ------ 监控链路已经完全打通。
举例:如何监控 Redis 指标
在我们的项目里,Redis 几乎是最关键的中间件之一。
不管是接口缓存、分布式锁、还是排行榜、限流、会话管理,
基本都离不开它。
也正因为 Redis 用得太广,一旦出问题,影响往往是"全局性的"------
页面卡顿、接口超时、服务雪崩,全都可能跟 Redis 有关。
比如:
- 连接数太多,Redis 直接拒绝新连接,接口瞬间超时;
- 内存打满,开始自动淘汰 key,业务数据莫名丢失;
- 主从延迟大,读取到的还是旧数据,导致逻辑混乱;
- 命中率变低,缓存几乎失效,数据库压力暴增。
这些问题单靠日志根本发现不了,
等用户反馈"系统卡了""接口报错"再查,
往往已经晚了。
所以在搭好 Prometheus 基础环境之后,
我做的第一件事就是------把 Redis 纳入监控体系。
我希望能实时看到它的连接数、内存占用、命中率变化,
出了异常能立刻报警,而不是等到系统崩了才知道。
一、安装 Redis Exporter
Prometheus 自身并不会直接监控 Redis,
而是通过一个专门的"探针"------Redis Exporter 来收集 Redis 的运行数据。
Redis Exporter 会定期访问 Redis,并通过一个 HTTP 接口暴露监控指标,
比如连接数、命中率、内存占用、命令执行速率等,
Prometheus 只需要定时抓取这个接口就能获取完整的监控数据。
Docker 启动方式如下:
我们在 docker-compose.yml 中添加 Redis 与 Redis Exporter:
yaml
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
restart: always
networks:
- monitor-net
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
volumes:
- ./grafana/data:/var/lib/grafana
restart: always
networks:
- monitor-net
redis:
image: redis:latest
container_name: redis
ports:
- "6379:6379"
restart: always
networks:
- monitor-net
redis_exporter:
image: oliver006/redis_exporter:latest
container_name: redis_exporter
ports:
- "9121:9121"
environment:
- REDIS_ADDR=redis://redis:6379
restart: always
networks:
- monitor-net
networks:
monitor-net:
driver: bridge这里我们做了几件事:
- 创建了一个公共网络
monitor-net,让各个容器可以互相访问; - Redis 与 Redis Exporter 在同一个网络中;
REDIS_ADDR=redis://redis:6379使用的是容器名redis,不需要写 IP 地址;- Redis Exporter 会自动连接到 Redis 并暴露监控接口(默认端口
9121)。
如果我们的 Redis 是本地或云端实例(比如腾讯云、阿里云 Redis),
那只需要在 Redis Exporter 的环境变量中填上真实地址即可,例如:
yaml
redis_exporter:
image: oliver006/redis_exporter:latest
container_name: redis_exporter
ports:
- "9121:9121"
environment:
- REDIS_ADDR=redis://43.142.149.91:6379
# 如果有密码:
# - REDIS_ADDR=redis://:密码@43.142.149.91:6379
restart: alwaysRedis Exporter 会通过这个地址去连接目标 Redis 服务。
只要能访问成功,就会在 /metrics 页面暴露完整的监控指标。
我们可以通过以下命令验证:
bash
curl http://localhost:9121/metrics | grep redis_connected_clients如果能返回类似:
redis_connected_clients 3说明 Exporter 已经成功连接 Redis。
启动整个监控环境:
docker compose up -d执行后,我们就可以同时启动:
- Prometheus(9090)
- Grafana(3000)
- Redis(6379)
- Redis Exporter(9121)
启动成功后,访问:
arduino
http://服务器IP:9121/metrics如果能看到类似以下内容,就表示 Redis Exporter 工作正常:
bash
# HELP redis_connected_clients Number of client connections
redis_connected_clients 12
# HELP redis_used_memory_bytes Total number of bytes allocated by Redis
redis_used_memory_bytes 12345678
# HELP redis_keyspace_hits_total Number of successful lookup of keys
redis_keyspace_hits_total 98765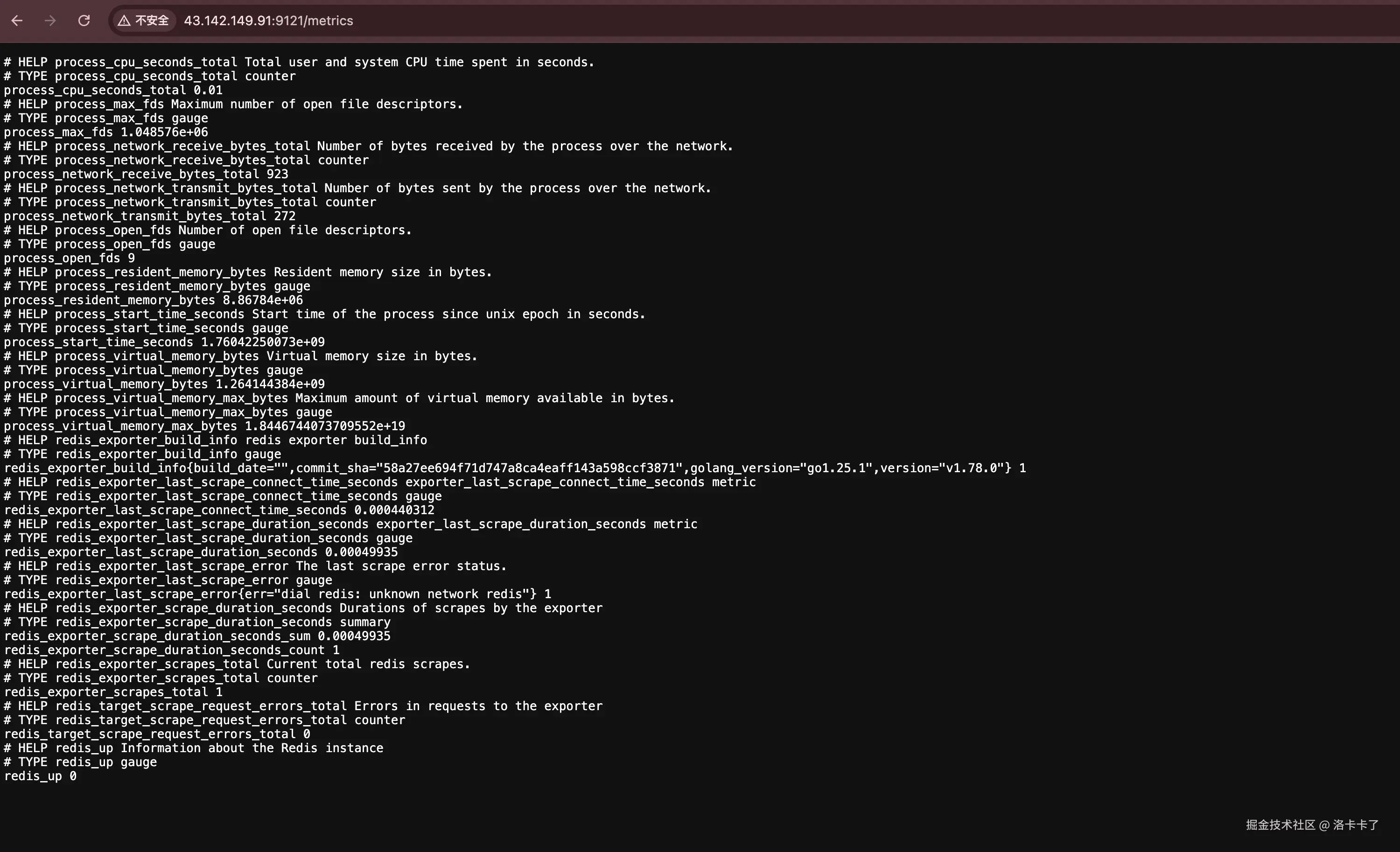
二、在 Prometheus 中添加 Redis 抓取配置
我们修改 Prometheus 的配置文件 prometheus.yml,
在 scrape_configs 下新增一个 job:
yaml
scrape_configs:
- job_name: 'redis-exporter'
static_configs:
- targets: ['43.142.149.91:9121']保存后重新加载 Prometheus 配置(或重启容器):
docker restart prometheus然后访问:
arduino
http://43.142.149.91:9090/targets可以看到一个新的 target:
scss
redis-exporter (UP)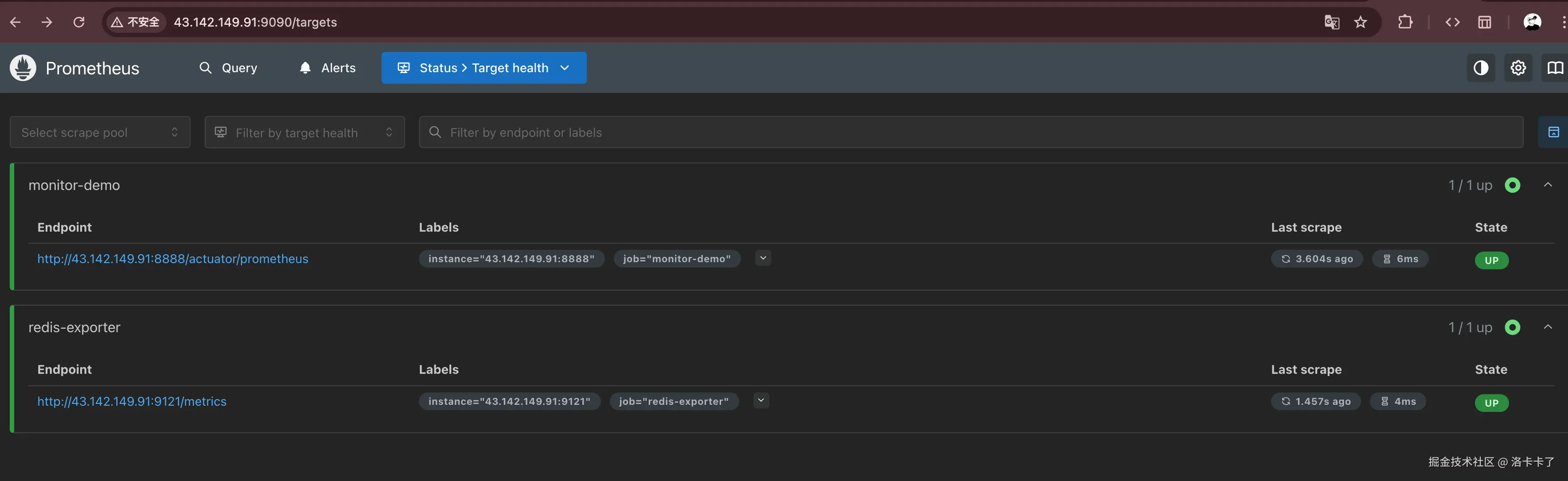 说明 Prometheus 已经开始定期抓取 Redis 指标。
说明 Prometheus 已经开始定期抓取 Redis 指标。
三、在 Grafana 导入 Redis Dashboard
Grafana 官方社区已经提供了多个 Redis 监控模板,
推荐使用模板 ID:763 或 ID:11835 ,
可以直接在 Grafana 中导入使用。
导入方式:
- 打开 Grafana 左侧菜单 → "Dashboards" → "Import";
- 输入模板 ID(如
11835),点击 "Load"; - 数据源选择刚才配置的 Prometheus;
- 点击 "Import" 即可。
导入成功后,我们就会看到完整的 Redis 可视化面板,
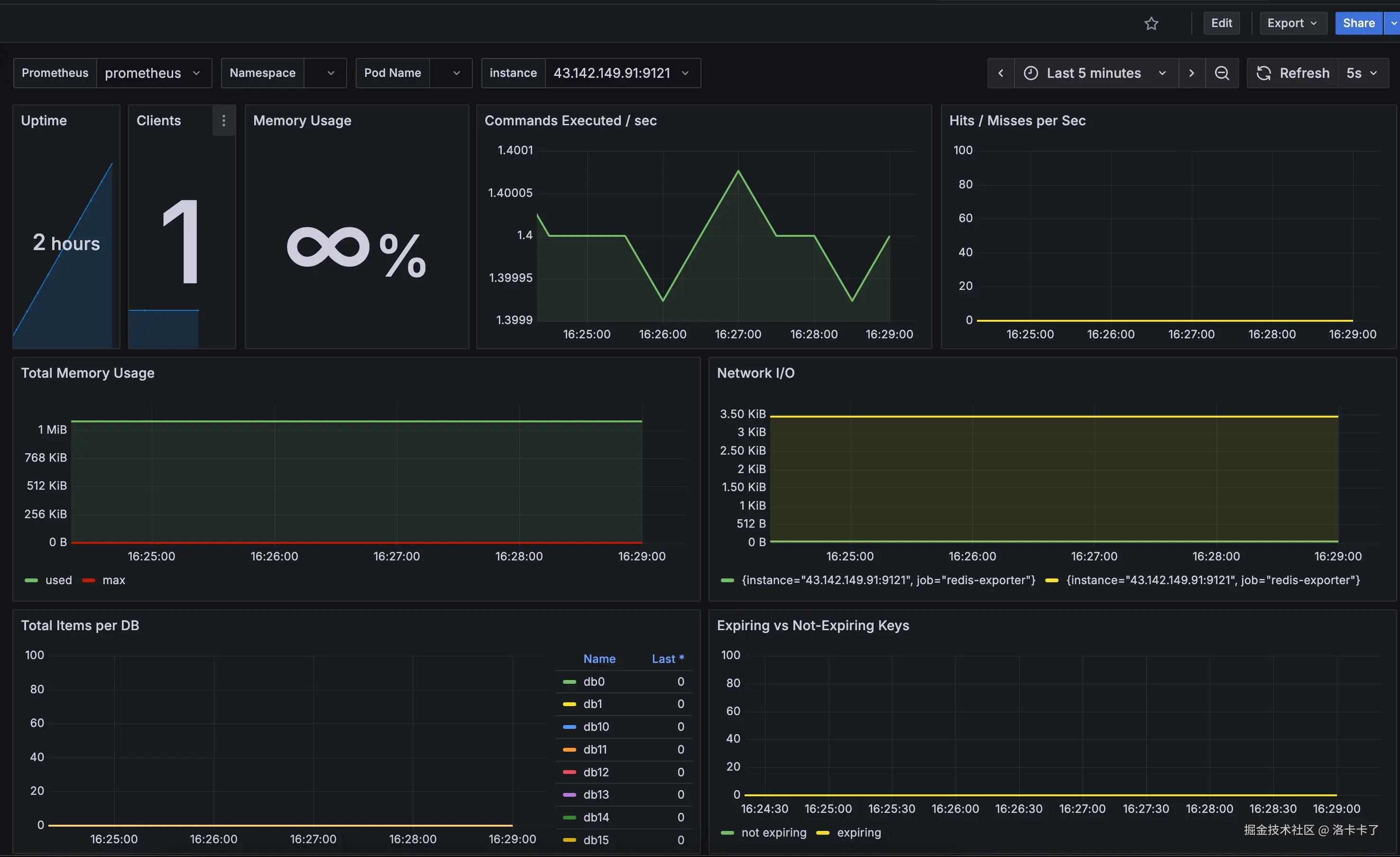 整个面板会实时展示 Redis 的运行状态,包括:
整个面板会实时展示 Redis 的运行状态,包括:
- Uptime:Redis 已运行的时长;
- Clients:当前活跃的客户端连接数;
- Memory Usage:Redis 当前内存使用率;
- Commands Executed / sec:每秒执行的命令数量;
- Hits / Misses per Sec:缓存命中与未命中速率;
- Total Memory Usage:内存总量及使用曲线;
- Network I/O:网络输入输出流量情况;
- Total Items per DB:各个数据库中存储的键数量;
- Expiring vs Not-Expiring Keys:带过期时间与永久存在的 Key 数量对比。
当 Redis 在持续被访问(例如有接口在频繁调用缓存时),
这些曲线会动态波动,命令速率、网络 I/O、内存曲线都会不断变化。
如果图表数据持续刷新,就说明 Prometheus 正在成功采集 Redis Exporter 的指标,
Grafana 也在实时展示这些数据。
其他常见组件的监控思路
除了 Redis,我们项目里还有很多关键模块都可以纳入 Prometheus 的监控体系。
它们的原理几乎都是一样的:
组件通过探针(Exporter)暴露指标 → Prometheus 定期抓取 → Grafana 可视化展示。
1. 系统层监控(Node Exporter)
系统层是所有服务的基础,CPU、内存、磁盘、网络等资源的健康状态,
直接影响整个平台的稳定性。
Prometheus 官方提供的 Node Exporter 可以采集宿主机的系统指标:
- CPU 使用率、负载
- 内存占用、Swap
- 磁盘读写速率、IOPS
- 网络吞吐量、TCP 连接数
安装方式非常简单,一条命令即可:
css
docker run -d \
--name node_exporter \
-p 9100:9100 \
prom/node-exporter启动后访问:
arduino
http://服务器IP:9100/metrics就能看到所有系统指标。
在 prometheus.yml 里增加一个 job,即可开始采集:
yaml
- job_name: 'node-exporter'
static_configs:
- targets: ['43.142.149.91:9100']Grafana 官方有现成模板(ID:1860),导入即可看到完整系统监控面板。
2. Ingress-Nginx 监控
如果我们的项目部署在 K8s 或通过 Nginx 做网关层,
那么入口流量、请求速率、状态码分布、延迟等数据同样非常关键。
K8s 自带的 Ingress-Nginx 已经内置了 Prometheus 格式的 metrics,
只要开启参数:
yaml
controller:
metrics:
enabled: true
service:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "10254"Prometheus 会自动采集 nginx-ingress-controller 暴露的指标。
Grafana 官方模板 ID 9614 或 13637 可以直接使用,
能够展示请求 QPS、响应时间、错误率、入口流量等关键指标。
3. MySQL 监控
数据库层推荐使用 mysqld_exporter:
css
docker run -d \
--name mysqld_exporter \
-p 9104:9104 \
-e DATA_SOURCE_NAME="root:密码@(mysql:3306)/" \
prom/mysqld-exporter可采集连接数、查询速率、慢查询数量、InnoDB 读写、缓存命中率等指标。
Grafana 模板 ID:7362 或 14057。
4. MQ(消息队列)监控
不同消息中间件都有各自的 Exporter:
| 消息中间件 | 对应 Exporter | 主要指标 |
|---|---|---|
| RabbitMQ | rabbitmq_exporter | 队列堆积、消费者数量、消息速率 |
| Kafka | kafka_exporter | Topic 消息速率、延迟、分区状态 |
| RocketMQ | rocketmq-exporter | 消费延迟、积压量、集群健康度 |
这些探针同样通过 /metrics 暴露指标,
配置到 Prometheus 后就能实时监控消费情况。
至此,我们的监控体系就从单一应用层扩展到了全栈可观测体系:
| 层级 | 工具 | 说明 |
|---|---|---|
| 系统层 | Node Exporter | 监控 CPU、内存、磁盘、网络等资源 |
| 网关层 | Ingress-Nginx | 监控流量入口、请求量、响应延迟 |
| 应用层 | Spring Boot + Micrometer | 监控接口成功率、耗时、错误率 |
| 缓存层 | Redis Exporter | 监控内存、命中率、连接数、命令速率 |
| 数据库层 | MySQL Exporter | 监控连接、查询速率、慢查询 |
| 消息队列层 | RabbitMQ / Kafka Exporter | 监控消息堆积与消费情况 |
通过 Prometheus + Grafana,我们几乎能在任何层面上第一时间发现异常,
从系统瓶颈到业务错误,都能做到提前预警、快速定位、主动止损。
如何自定义业务监控指标
前面我们已经用 Prometheus + Grafana 搭建好了系统层面的监控。CPU、内存、磁盘、Redis、接口请求这些指标都能实时看到。
但很多时候,系统没挂不代表业务没问题。
举个例子。
我们这个项目是一个社交类 App,用户可以充值购买会员、抽奖、买道具。某一天,我们的投放数据突然异常,ROI 一下子掉得很厉害。一开始看监控:CPU、内存都正常,接口请求量也没少,看起来一切运行良好。但业务端的数据却在持续下滑。
我们后来才发现,微信支付的成功率几乎为零,而支付宝渠道还正常。由于我们的 Prometheus 当时只监控了系统层面,没有任何业务指标,所以 Grafana 上根本看不出问题在哪。只能靠客服和运营反映"用户充值不到账""支付不成功",才发现微信那边的超时率早就暴涨了。
这件事之后我们就意识到:系统层的监控告诉我们"服务活着",但业务层的监控才能告诉我们"业务好不好"。
那我们要监控什么?
在我们的业务里,下单和支付是最关键的环节。
所以我们希望 Prometheus 能实时看到这些核心数据:
- 每个渠道(微信 / 支付宝)的下单总数
- 成功数、失败数、异常数
- 下单金额分布(比如平均金额、总金额)
- 成功率趋势
这样一旦哪个渠道异常,比如失败率飙升或平均金额突降,
我们就能第一时间发现问题,而不是等 ROI 掉下去、用户投诉了才知道。
统一管理业务指标
为了方便维护,我们新增了一个专门的类来统一管理这些指标:
java
@Component
public class MetricsManager {
private final MeterRegistry registry;
public MetricsManager(MeterRegistry registry) {
this.registry = registry;
}
// 记录订单总数
public void recordOrderTotal(String channel) {
Counter.builder("order_total_count")
.description("Total number of orders created by channel")
.tag("channel", channel)
.register(registry)
.increment();
}
// 记录下单成功
public void recordOrderSuccess(String channel) {
Counter.builder("order_success_total")
.description("Total number of successful orders by channel")
.tag("channel", channel)
.register(registry)
.increment();
}
// 记录下单失败
public void recordOrderFail(String channel) {
Counter.builder("order_fail_total")
.description("Total number of failed orders by channel")
.tag("channel", channel)
.register(registry)
.increment();
}
// 记录下单金额
public void recordOrderAmount(String channel, double amount) {
DistributionSummary.builder("order_amount_sum")
.description("Order amount distribution by channel")
.baseUnit("CNY")
.tag("channel", channel)
.register(registry)
.record(amount);
}
}这样所有的业务指标都集中在一个类里,不管是新增、修改还是规范命名,都能统一管理,不容易乱。
模拟下单接口
接着我们来写一个测试接口,用来模拟下单:
java
/**
* 用于验证 Prometheus 自定义指标的测试控制器
*/
@RestController
@RequestMapping("/test")
public class TestController {
private final MetricsManager metricsManager;
public TestController(MetricsManager metricsManager) {
this.metricsManager = metricsManager;
}
/**
* 模拟下单请求
* 示例:
* http://localhost:8888/test/order?channel=wechat&type=success&amount=88.8
*/
@GetMapping("/order")
public String testOrderMetrics(
@RequestParam(defaultValue = "wechat") String channel,
@RequestParam(defaultValue = "success") String type,
@RequestParam(defaultValue = "0") double amount
) {
// 记录订单总数
metricsManager.recordOrderTotal(channel);
// 记录订单金额(如果有)
if (amount > 0) {
metricsManager.recordOrderAmount(channel, amount);
}
// 根据下单类型更新对应指标
switch (type) {
case "success":
metricsManager.recordOrderSuccess(channel);
break;
case "fail":
metricsManager.recordOrderFail(channel);
break;
default:
return "未知订单类型:" + type;
}
return String.format("Recorded order: channel=%s, type=%s, amount=%.2f", channel, type, amount);
}
}上面的写法只是我们测试为了快速验证监控是否生效 。
但在真实业务中,我们是绝不建议在每个接口里手动调用这些 recordXxx() 方法。
原因很简单:
- 一是太"侵入式",每个接口都写一堆统计逻辑,会让业务代码变得臃肿;
- 二是一旦指标多起来,很容易遗漏或维护混乱。
在实际项目中,我们更推荐的做法是使用 AOP(切面编程)来埋点监控 。
比如我们可以在订单服务的核心方法上加一个注解 @MonitorOrder,
然后通过切面自动拦截方法调用,统一上报 Prometheus 指标。
这样做有三个好处:
- 非侵入式 ------ 业务逻辑完全不需要关心指标上报;
- 统一维护 ------ 只在一个地方维护埋点逻辑;
- 扩展性强 ------ 以后要新增业务指标,也不用改 Controller。
后续我们会在"自定义指标与告警配置"章节里详细讲解这种 AOP 埋点实现方式。
启动项目后访问:
bash
http://43.142.149.91:8888/test/order?channel=wechat&type=success&amount=88.8
http://43.142.149.91:8888/test/order?channel=wechat&type=success&amount=10
http://43.142.149.91:8888/test/order?channel=alipay&type=fail&amount=23.5再打开
arduino
http://43.142.149.91:8888/actuator/prometheus就能看到我们定义的这些自定义指标已经被 Prometheus 采集到了,比如:
ini
order_success_total{channel="wechat"} 2.0
order_fail_total{channel="alipay"} 1.0
order_amount_sum_CNY_sum{channel="wechat"} 98.8
order_amount_sum_CNY_sum{channel="alipay"} 23.5每一行其实都代表一个业务指标的实时统计数据:
order_success_total:下单成功的次数,这里wechat渠道成功了 2 次;order_fail_total:下单失败的次数,这里alipay渠道失败了 1 次;order_amount_sum_CNY_sum:订单金额的累计总和(单位是人民币 CNY),表示所有订单加起来的成交金额;- 如果我们看到还有
order_amount_sum_CNY_count或order_amount_sum_CNY_max,那分别代表订单的总笔数和单笔最大交易金额。
这些指标后缀并不是我们手动写的,而是 Micrometer 框架自动生成的。不同后缀代表不同类型的数据含义:
_total:表示这是一个计数器(Counter),用来统计累计次数,比如成功数、失败数等,数值只增不减;_sum:代表总和(Summary 类型指标的累计值),比如订单金额总数;_count:代表观测次数,也就是统计了多少笔交易;_max:代表观测到的最大值,比如单笔订单的最高金额。
因为我们在代码里给金额类指标设置了 baseUnit("CNY"),
Micrometer 会自动把单位拼进指标名中,于是我们会看到类似 order_amount_sum_CNY_sum 这样的名字。
简单来说,
- 用 Counter 记录的次数类指标会以
_total结尾; - 用 DistributionSummary 记录的分布类指标会生成
_sum、_count、_max三种数据项; - 如果设置了单位(baseUnit),也会体现在指标名中。
这些指标会被 Prometheus 定期抓取,
接下来我们就可以在 Grafana 上把它们可视化成各种业务图表,比如支付成功率、订单金额趋势、渠道对比等,
实时观察每个渠道的业务波动情况。
在 Grafana 中可视化自定义业务指标
有了自定义的指标数据,Prometheus 只是负责采集和存储,
真正能帮我们"看懂业务"的,其实是 Grafana。
Grafana 就像一个"数据可视化面板",能把枯燥的监控指标变成可读的趋势图、曲线图。
我们可以通过它直观看到每个支付渠道的下单量、成功率、金额波动等等。
1、创建仪表盘并添加面板
打开 Grafana 控制台,在左侧菜单中选择:
"Dashboard → New -> New Dashboard -> Add Visualization 。
进入编辑界面后:
- 先把 Data source 选择为 "Prometheus";
进入面板编辑页后,页面分为两个区域:
- 下方 Queries:用于输入 PromQL 查询语句;
- 右侧 Panel options:用于设置标题、单位、样式等信息。
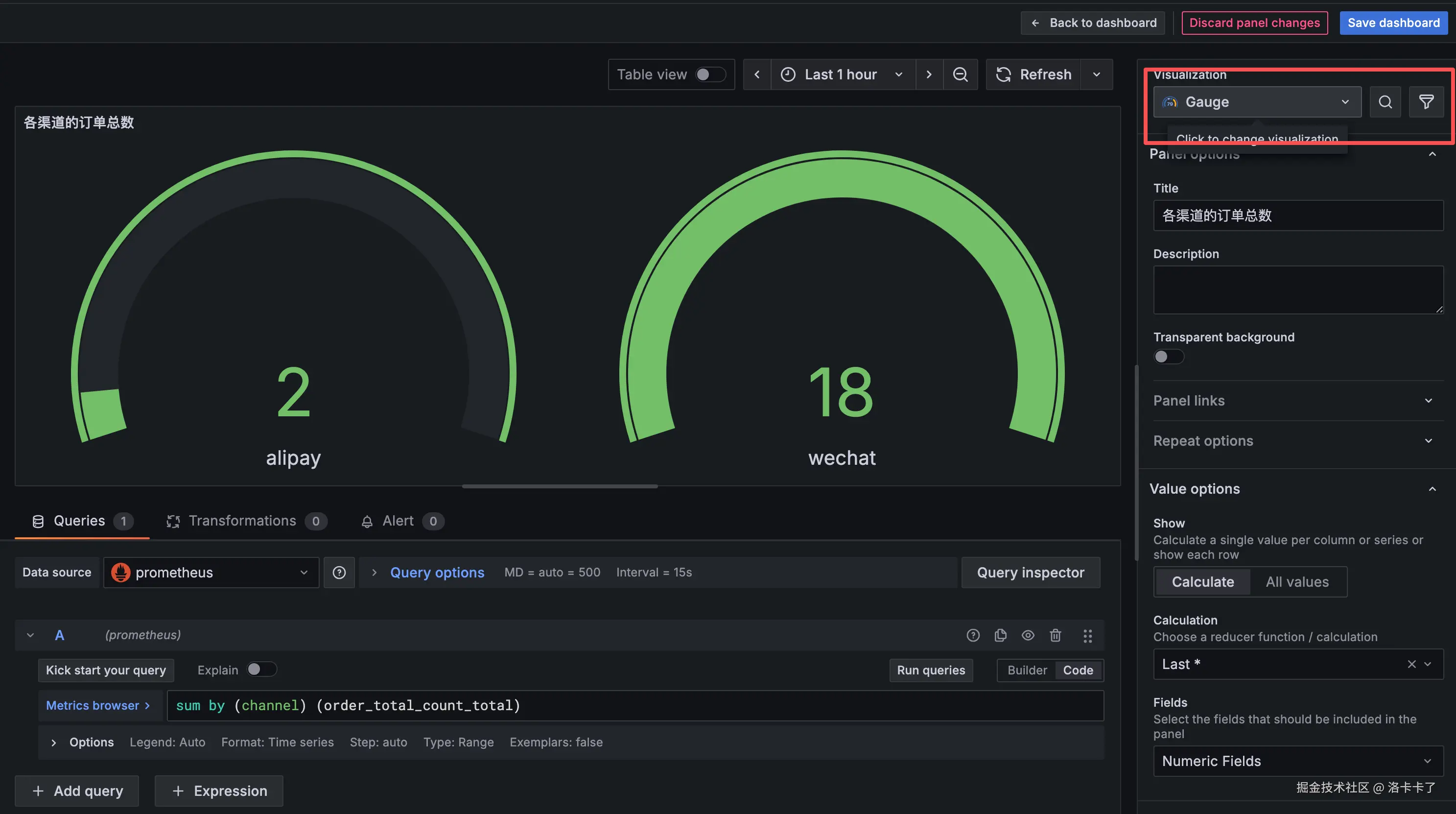
2. 添加第一个指标:各渠道的订单总数
在下方 Queries 区域输入查询语句:
scss
sum by (channel) (order_total_count_total)然后在右侧 Panel options 中设置标题:
各渠道的订单总数点击页面下方的 "Run queries" ,
Grafana 就会实时绘制出每个渠道(如 wechat、alipay)的订单总数。
3. 回到仪表盘并添加下一个面板
点击右上角 "Back to dashboard" 返回主界面;
再点击右上角 "Add → Visualization" ,创建新的面板。
例如创建一个"最近 10 分钟的支付成功率"的面板:
在 Queries 区域输入:
scss
(
sum by (channel) (rate(order_success_total[10m]))
)
/
(
sum by (channel) (rate(order_total_count_total[10m]))
)在 Panel options 中输入标题:
最近 10 分钟的支付成功率点击 "Run queries" 预览效果。
同样的我们可以重复此操作添加其他指标
4. 优化显示样式
在右侧的 "Visualization" 区域:
- 想看趋势变化 → 选 "Time series";
- 想看实时数值 → 选 "Gauge";
- "Legend" 设置为
{{channel}},方便区分不同支付渠道; - "Unit" 选择 "currency(CNY)" 或 "percent(%)";
- "Refresh interval" 调整为 5s~10s,便于观察实时变化。
我们添加完后点击右上角的Save dashboard后创建一个名字,最终结果如下:
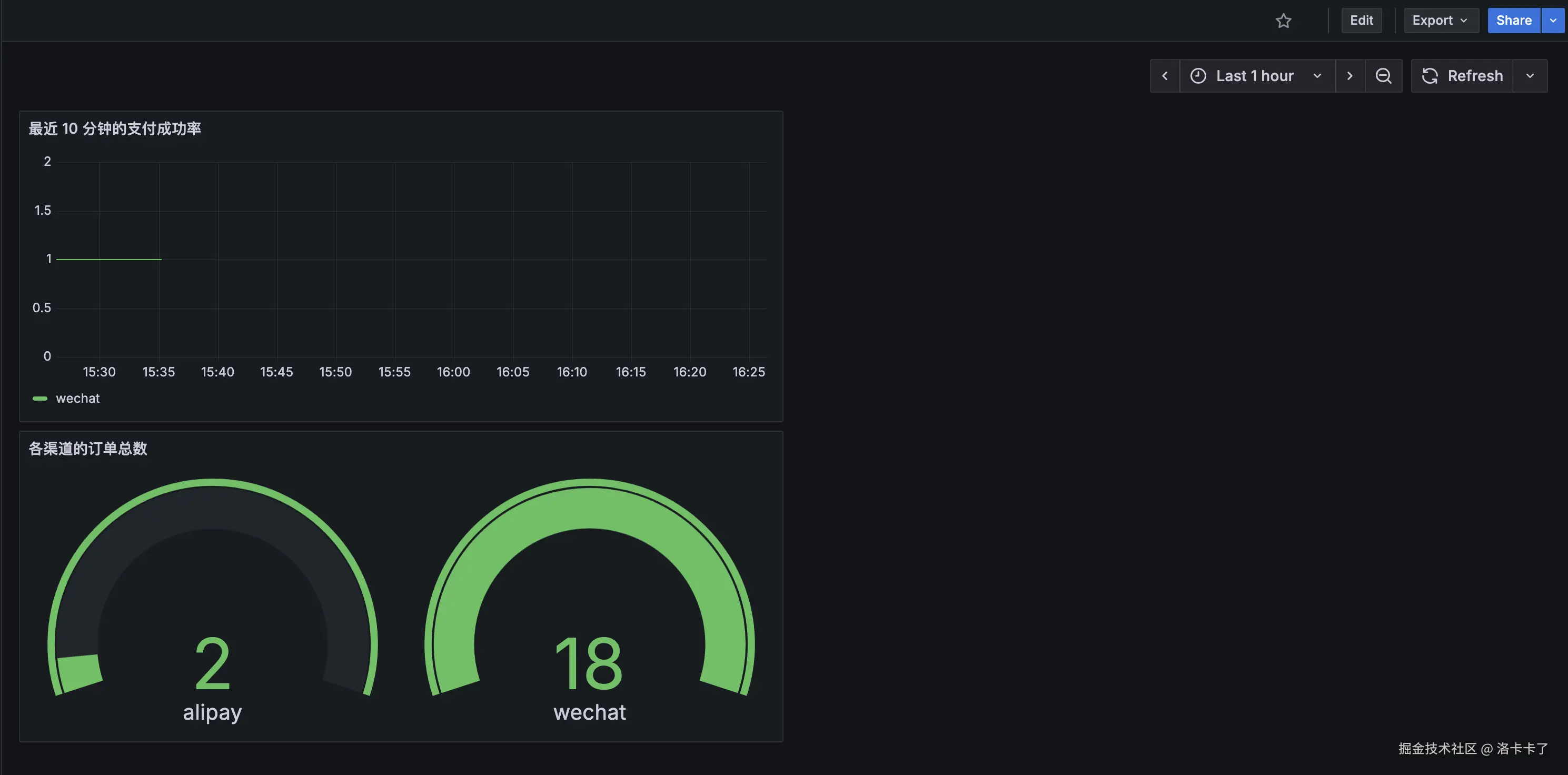
我们就能在一屏中实时看到:各渠道的订单笔数、支付成功率、总金额、客单价等关键业务指标。
为什么监控系统虽然"非必需",却格外重要
到这里,我们其实已经搭建好了一个完整的监控系统。
虽然说这套系统在项目中并不是"必需品",但它绝对是"非常重要的东西"。
最主要的原因,就是出问题太被动了 。
当业务出故障时,如果还得靠客服反馈、用户投诉才能发现,
那往往说明损失已经发生。
尤其像我们这种 To C 项目 ,投放广告、买量、跑活动,
每一分钟都在烧钱。
只要监控慢半拍,ROI 就可能直接掉一半。
所以我们必须有一套属于自己的监控体系,
它要能在第一时间告诉我们"哪里出了问题",而不是等出事再补救。
更关键的是,这种监控体系是我们能完全掌控的 。
它不依赖云厂商自带的告警,也不受别人配置的约束。
我们可以根据自己的业务逻辑去定制规则,比如:
- 统计最近 10 分钟的支付成功率;
- 监控下单失败率、渠道转化对比;
- 记录异常次数并触发告警。
这样,监控系统不仅能"看数",还能主动"提醒"我们系统异常。
虽然我们现在导入的 Grafana 模板(例如官方模板 ID:4701)已经能展示很多基础指标,
但这些图表大多是英文缩写、指标太多,第一次看会觉得信息量太大、太"硬核"。
很多时候,我们只想快速看到几个关键指标:
CPU 使用率、内存占用、接口耗时、磁盘空间、网络流量......
这些才是能帮我们第一时间判断系统健康的核心数据。
其实 Grafana 的仪表盘本质上就是一个 JSON 文件,
我们完全可以自己动手改,
把真正重要的指标挑出来,做成一个轻量化、中文化的看板 。
这样不但更直观,也更贴合我们自己的业务习惯。
当然,光有指标还不够。
要让监控真正发挥作用,还需要报警机制 来兜底
当系统出现异常时,第一时间就能通过钉钉、企业微信或邮件通知我们。
这一篇确实写得有点啰嗦咯,为了让思路更清晰,后面关于 自定义整合业务指标 和 监控告警机制 的部分,我就放到后面再来详细讲解一下咯。
后面我们再详细讲解一下这个:
- 如何把 系统指标 、业务指标 、服务指标 、自定义业务指标 等集中在同一个大盘中统一展示;
- 以及如何设置 告警规则,让系统在出问题的第一时间主动提醒我们。
这样一来,我们的整套监控体系就能从"能看见",变成"能预警、能止损"。